Contextual Scalarisation Thompson Sampling for multi-objective decisions in public media
Pith reviewed 2026-06-28 20:54 UTC · model grok-4.3
The pith
A contextual bandit learns to weight competing objectives based on observed context for public media recommendations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Contextual Scalarisation Thompson Sampling conditions the scalarisation weights inside a Thompson sampling bandit on observed context, allowing the algorithm to adapt the relative importance of multiple objectives to each decision situation rather than using static or context-independent combinations.
What carries the argument
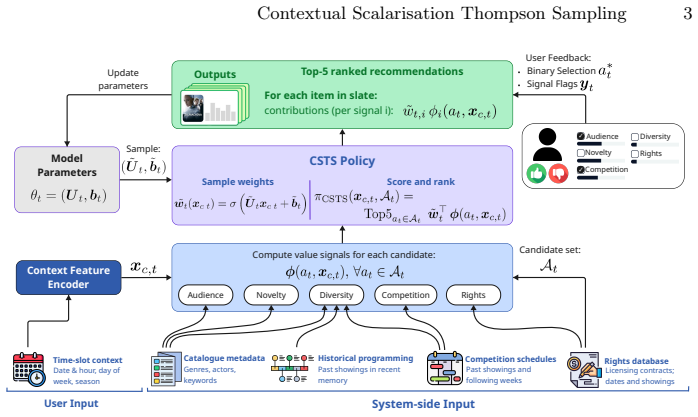
Contextual Scalarisation Thompson Sampler (CSTS), which samples from a posterior over context-dependent weights that combine the objectives before selecting the action.
If this is right
- Objective trade-offs can shift automatically with context without requiring manual retuning of weights for each new scenario.
- Recommendations become more likely to match the choices made by human curators who already account for situational factors.
- The method reduces reliance on pre-computed Pareto fronts by embedding the weighting decision inside the online learning loop.
Where Pith is reading between the lines
- The same structure could be applied to other multi-objective sequential decisions where context changes the relative priority of goals, such as resource allocation under varying demand.
- If context features prove insufficient in new domains, the performance gain would shrink to that of a standard contextual bandit.
- Live deployment would require monitoring whether the learned weights remain stable when the underlying audience or editorial policy drifts.
Load-bearing premise
The context features recorded in the data are rich enough to support learning of stable objective weights that generalize to new situations.
What would settle it
A test in which CSTS trained on one period of Swiss broadcaster data fails to show higher alignment with expert choices than fixed-weight baselines on a later disjoint period from the same broadcaster.
Figures
read the original abstract
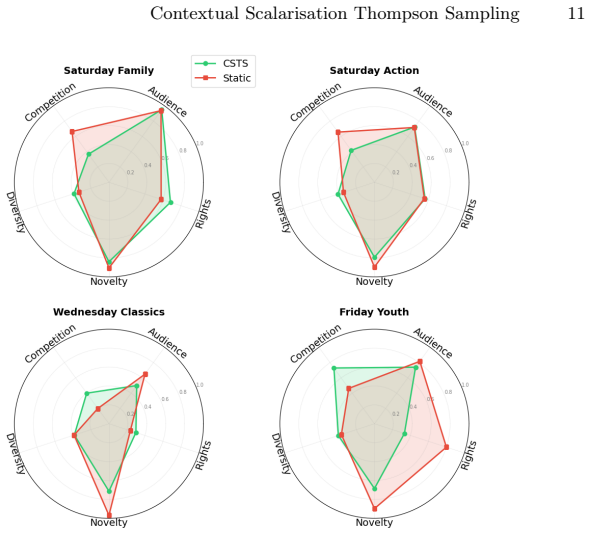
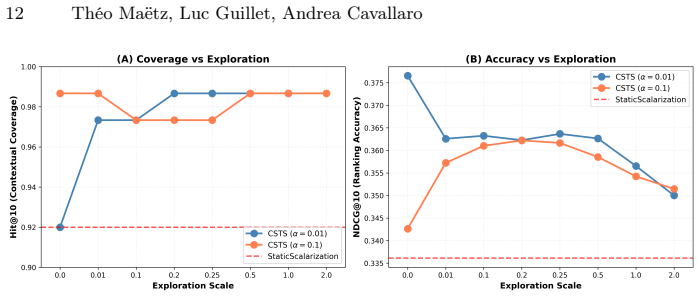
Recommender systems may operate under multiple, competing objectives. For example, audience reach, cultural values, public service mandate, and operational constraints must be balanced in editorial decisions of public service media. Existing approaches relying on fixed combinations of objectives or Pareto-based optimisation do not adapt to changing priorities across situations. In this paper, we propose Contextual Scalarisation Thompson Sampler (CSTS), a multi-objective contextual bandit method that learns to weight objectives as a function of the observed context. We evaluate CSTS on real programming data from Radio T\'el\'evision Suisse, the Swiss national broadcaster, showing improved contextual relevance and better alignment with expert curation practices compared to fixed weight and standard contextual bandit approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Contextual Scalarisation Thompson Sampling (CSTS), a multi-objective contextual bandit method that learns to weight objectives (audience reach, cultural values, public service mandate) as a function of observed context. It evaluates the approach on historical programming data from Radio Télévision Suisse and claims improved contextual relevance and better alignment with expert curation practices relative to fixed-weight and standard contextual bandit baselines.
Significance. If the results hold under stronger validation, the method could advance adaptive multi-objective decision-making in public-service recommender systems by moving beyond fixed scalarisation or Pareto fronts. The work does not ship machine-checked proofs, reproducible code, or parameter-free derivations.
major comments (2)
- [Abstract] Abstract: the claim of 'improved contextual relevance' and 'better alignment with expert curation' is stated without any equations, algorithm pseudocode, statistical tests, or error bars, rendering the performance claims impossible to assess.
- [Evaluation] Evaluation section: performance is reported only on offline historical data from a single broadcaster (RTS) with no temporal hold-out, cross-broadcaster validation, or stability analysis of the learned scalarisation function across regimes; this directly undermines the central claim that observed context features suffice to learn stable, generalizable objective weights.
minor comments (1)
- [Abstract] Abstract: 'Radio Télèvision Suisse' contains a typesetting error in the accent mark.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback. We address each major comment below, proposing revisions where the concerns are valid and explaining our position on the evaluation scope.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'improved contextual relevance' and 'better alignment with expert curation' is stated without any equations, algorithm pseudocode, statistical tests, or error bars, rendering the performance claims impossible to assess.
Authors: Abstracts are high-level summaries by design and do not contain equations or pseudocode. The full CSTS algorithm, including the contextual scalarisation mechanism and Thompson sampling update, is detailed in Section 3 with pseudocode in Algorithm 1. Section 4 reports offline performance with statistical tests (paired t-tests) and error bars across multiple runs. We agree the abstract could better signal the presence of these elements and will revise it to include a brief clause noting 'with statistical validation on historical RTS data'. revision: yes
-
Referee: [Evaluation] Evaluation section: performance is reported only on offline historical data from a single broadcaster (RTS) with no temporal hold-out, cross-broadcaster validation, or stability analysis of the learned scalarisation function across regimes; this directly undermines the central claim that observed context features suffice to learn stable, generalizable objective weights.
Authors: We acknowledge the evaluation uses a single real-world dataset from RTS without explicit temporal hold-out or cross-broadcaster testing. This is a genuine limitation for broad generalizability claims. We will add a limitations subsection discussing these points, including why stability analysis of the scalarisation weights was not performed and noting that context features showed consistent weighting patterns within the RTS regime. We disagree that this fully undermines the central claim, as the results demonstrate context-dependent weighting improves alignment within the available data; however, we will tone down language asserting generalizability beyond the studied setting. revision: partial
- Cross-broadcaster validation, as the authors have access only to the RTS dataset and cannot obtain equivalent data from other public broadcasters.
Circularity Check
No circularity in derivation chain
full rationale
The provided abstract and description introduce CSTS as a contextual bandit algorithm that learns context-dependent objective weights, with evaluation on RTS historical data. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains are present in the text. The central claim rests on empirical comparison to baselines rather than any self-referential reduction. This is a standard algorithmic proposal with offline evaluation and is self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The Movie Database (TMDB), https://www.themoviedb.org/, Last accessed: Jan 2026
2026
-
[2]
AI Magazine32, 67–80 (Sep 2011)
Adomavicius, G., Mobasher, B., Ricci, F., Tuzhilin, A.: Context- aware recommender systems. AI Magazine32, 67–80 (Sep 2011). https://doi.org/10.1609/aimag.v32i3.2364
-
[3]
Thompson Sampling for Contextual Bandits with Linear Payoffs
Agrawal, S., Goyal, N.: Thompson sampling for contextual bandits with linear pay- offs (Feb 2014). https://doi.org/10.48550/arXiv.1209.3352, arXiv:1209.3352 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1209.3352 2014
-
[4]
Information science and statistics, Springer, New York (2006) 14 Théo Maëtz, Luc Guillet, Andrea Cavallaro
Bishop, C.M.: Pattern recognition and machine learning. Information science and statistics, Springer, New York (2006) 14 Théo Maëtz, Luc Guillet, Andrea Cavallaro
2006
-
[5]
Chap- man and Hall/CRC (Dec 2011)
Bottou, L.: Large-scale machine learning with stochastic gradient descent. Chap- man and Hall/CRC (Dec 2011). https://doi.org/10.1201/b11429-6
-
[6]
https://doi.org/10.1007/978-3-319-08786-3_6
Chen, G., Chen, L.: Recommendation based on contextual opinions (Jul 2015). https://doi.org/10.1007/978-3-319-08786-3_6
-
[7]
Corrigan, M.: Mediagenix powers business integration across France Télévisions’ portfolio, https://www.tvbeurope.com/media-management/mediagenix-powers- business-integration-across-france-televisions-portfolio, Last accessed: May 2026
2026
-
[8]
He, X., Liao, L., Zhang, H., Nie, L., Hu, X., Chua, T.S.: Neural collaborative fil- tering(arXiv:1708.05031)(Aug2017).https://doi.org/10.48550/arXiv.1708.05031, arXiv:1708.05031 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1708.05031
-
[9]
Frontiers in Big Data6(Mar 2023)
Jannach, D., Abdollahpouri, H.: A survey on multi-objective recommender systems. Frontiers in Big Data6(Mar 2023). https://doi.org/10.3389/fdata.2023.1157899
-
[10]
https://doi.org/10.48550/arXiv.2312.16868, arXiv:2312.16868 [cs]
Jin, J., Zhang, Z., Li, Z., Gao, X., Yang, X., Xiao, L., Jiang, J.: Pareto- based multi-objective recommender system with forgetting curve (Feb 2024). https://doi.org/10.48550/arXiv.2312.16868, arXiv:2312.16868 [cs]
-
[11]
In: Advances in Neural Information Processing Systems
Kawale, J., Bui, H.H., Kveton, B., Tran-Thanh, L., Chawla, S.: Efficient Thompson sampling for online matrix-factorization recommendation. In: Advances in Neural Information Processing Systems. vol. 28. Curran Associates, Inc. (2015)
2015
-
[12]
Cambridge University Press, 1 edn
Lattimore, T., Szepesvári, C.: Bandit Algorithms. Cambridge University Press, 1 edn. (Jul 2020). https://doi.org/10.1017/9781108571401
-
[13]
In: Proceedings of the 19th international conference on World Wide Web
Li, L., Chu, W., Langford, J., Schapire, R.E.: A Contextual-bandit ap- proach to personalized news article recommendation. In: Proceedings of the 19th international conference on World Wide Web. pp. 661–670 (Apr 2010). https://doi.org/10.1145/1772690.1772758
-
[14]
In: Proceedings of the 12th ACM Conference on Recommender Sys- tems
McInerney,J.,Lacker,B.,Hansen,S.,Higley,K.,Bouchard,H.,Gruson,A.,Mehro- tra, R.: Explore, exploit, and explain: personalizing explainable recommendations with bandits. In: Proceedings of the 12th ACM Conference on Recommender Sys- tems. pp. 31–39. ACM (Sep 2018). https://doi.org/10.1145/3240323.3240354
-
[15]
WWW 2014 - Proceedings of the 23rd International Conference on World Wide Web p
Nguyen, T.T., Hui, P.M., Harper, F.M., Terveen, L., Konstan, J.A.: Exploring the filter bubble: the effect of using recommender systems on content diversity. WWW 2014 - Proceedings of the 23rd International Conference on World Wide Web p. 677–686 (Apr 2014). https://doi.org/10.1145/2566486.2568012
-
[16]
Penguin Books, London (2012)
Pariser, E.: The Filter Bubble: What the Internet is Hiding from You. Penguin Books, London (2012)
2012
-
[17]
Scientific Reports15(1), 13669 (Apr 2025)
Qassimi, S., Rakrak, S.: Multi-objective contextual bandits in recommenda- tion systems for smart tourism. Scientific Reports15(1), 13669 (Apr 2025). https://doi.org/10.1038/s41598-025-89920-2
-
[18]
Information Fusion112, 102559 (Dec 2024)
Riabchuk, V., Hagel, L., Germaine, F., Zharova, A.: Utility-based context-aware multi-agent recommendation system for energy efficiency in residential buildings. Information Fusion112, 102559 (Dec 2024). https://doi.org/10.1016/j.inffus.2024.102559
-
[19]
Ribeiro, M.T., Lacerda, A., Veloso, A., Ziviani, N.: Pareto-efficient hybridization for multi-objective recommender systems. In: Proceedings of the sixth ACM con- ference on Recommender systems. pp. 19–26. ACM, Dublin Ireland (Sep 2012). https://doi.org/10.1145/2365952.2365962
-
[20]
Rodriguez, M., Posse, C., Zhang, E.: Multiple objective optimization in recom- mender systems. ACM (Sep 2012). https://doi.org/10.1145/2365952.2365961
-
[21]
Russo, D., Roy, B.V., Kazerouni, A., Osband, I., Wen, Z.: A tutorial on Thompson Sampling (arXiv:1707.02038) (Jul 2020), arXiv:1707.02038 [cs] Contextual Scalarisation Thompson Sampling 15
arXiv 2020
-
[22]
https://doi.org/10.48550/arXiv.2308.08497, arXiv:2308.08497 [cs]
Shen, C., Zhang, X., Wei, W., Xu, J.: HyperBandit: Contextual bandit with hy- pernetwork for time-varying user preferences in streaming recommendation (Aug 2023). https://doi.org/10.48550/arXiv.2308.08497, arXiv:2308.08497 [cs]
-
[23]
SRG SSR: https://www.srgssr.ch/en/what-we-do/quality/journalism-charter, Last accessed: Dec 2025
2025
-
[24]
Neural Networks for Machine Learning (Coursera), University of Toronto (2012), Last accessed: Jan 2026
Tieleman,T.,Hinton,G.:Lecture6.5—RMSProp:Dividethegradientbyarunning average of its recent magnitude. Neural Networks for Machine Learning (Coursera), University of Toronto (2012), Last accessed: Jan 2026
2012
-
[25]
https://doi.org/10.48550/arXiv.2003.00359, arXiv:2003.00359 [cs]
Xu, X., Dong, F., Li, Y., He, S., Li, X.: Contextual-Bandit based personalized recommendation with time-varying user interests (Feb 2020). https://doi.org/10.48550/arXiv.2003.00359, arXiv:2003.00359 [cs]
-
[26]
Scientific Re- ports15(1), 35002 (Oct 2025)
Zhou, J., Shen, D., Guo, Y., Wu, Y., Ma, J.: Recommendation of deep reinforce- ment learning based on value function considering error reduction. Scientific Re- ports15(1), 35002 (Oct 2025). https://doi.org/10.1038/s41598-025-18926-7
-
[27]
https://doi.org/10.48550/arXiv.2306.14834, arXiv:2306.14834 [cs]
Zhu, Z., Roy, B.V.: Scalable neural contextual bandit for recommender systems (Aug 2023). https://doi.org/10.48550/arXiv.2306.14834, arXiv:2306.14834 [cs]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.