Learning Burst-Aware Early Warning Models for Capacity Stress under AI Workload Surges in Hyperscale Data Centers
Pith reviewed 2026-06-26 14:39 UTC · model grok-4.3
The pith
An XGBoost model detects the majority of capacity stress periods from bursty AI workloads with 0.914 recall.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
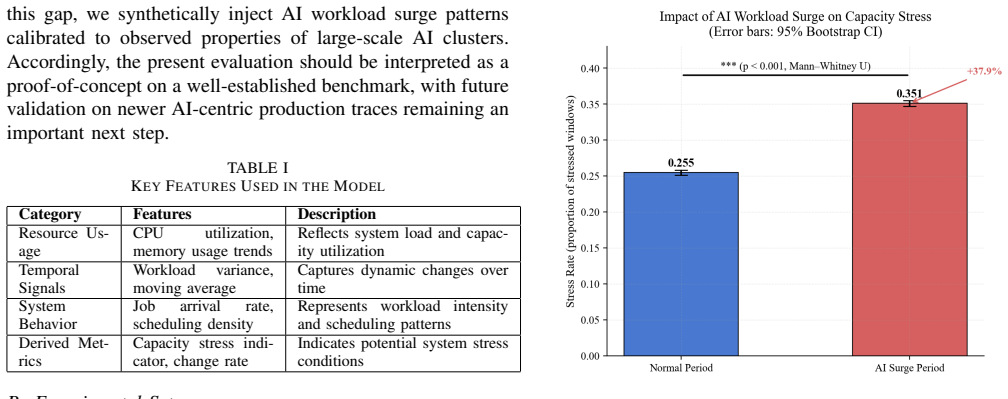
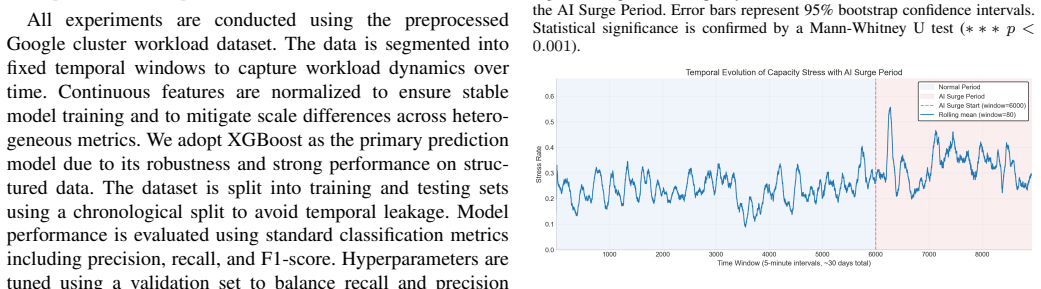
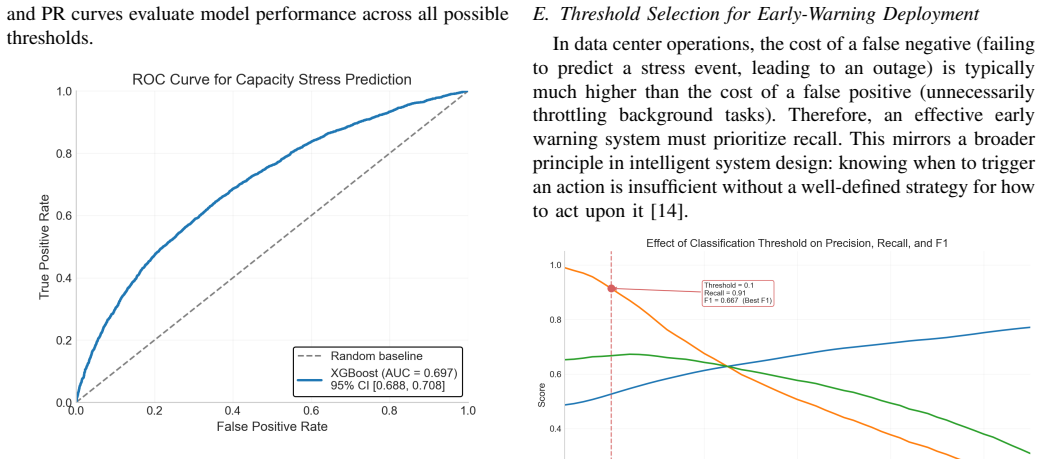
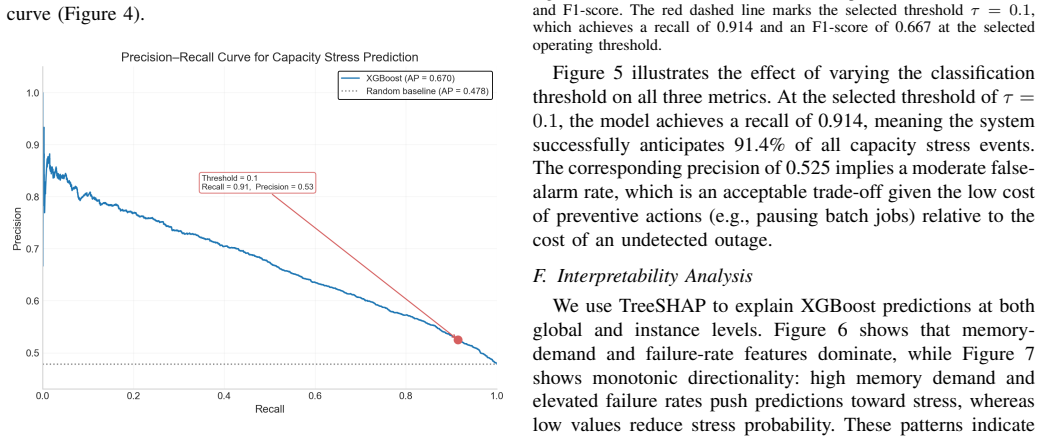
The burst-aware early warning framework integrates workload intensity, temporal variation, and system pressure signals into an XGBoost model for high-recall prediction of capacity stress. The model attains an ROC AUC of 0.697 and average precision of 0.670, outperforming baselines, and reaches 0.914 recall with acceptable false-alarm rates under deployment-oriented thresholds, supporting integration into control loops for actions like workload throttling and resource scaling.
What carries the argument
XGBoost classifier applied to multivariate telemetry windows capturing workload intensity, temporal variation, and system pressure for nonlinear interaction capture in imbalanced forecasting.
If this is right
- Proactive actions such as workload throttling and resource scaling become feasible before degradation occurs.
- The framework outperforms baseline methods significantly in predictive metrics.
- Realistic simulation of burst patterns allows evaluation under conditions mimicking large-scale AI systems.
- High-recall detection covers the majority of stress-prone periods.
Where Pith is reading between the lines
- The surge injection method enables testing under conditions not previously available for AI workloads.
- Integration into operational loops suggests potential for closed-loop control in data centers.
Load-bearing premise
The AI workload surge injection methodology accurately simulates burst-driven demand patterns observed in large-scale AI systems.
What would settle it
A direct comparison of the model's predictions against observed stress events in a production hyperscale data center running real AI workloads without simulated injection would confirm or refute the reported recall and AUC values.
Figures


read the original abstract
The rapid growth of large-scale AI workloads, particularly Large Language Model (LLM) training and inference, is fundamentally reshaping the operational dynamics of hyperscale data centers. Unlike traditional cloud workloads, AI-driven jobs exhibit bursty, high-intensity, and rapidly shifting resource demands, often leading to sudden capacity stress that cannot be effectively handled by reactive threshold-based mechanisms. In this paper, we propose a deployment-oriented, burst-aware early warning framework for proactive capacity stress prediction under AI workload surges. We formulate the problem as a high-recall forecasting task over multivariate telemetry windows, with the explicit goal of enabling operational intervention before system degradation occurs. The proposed framework integrates workload intensity, temporal variation, and system pressure signals, and employs a lightweight tree-based learning model to capture nonlinear interactions in highly imbalanced environments. To evaluate the system under realistic conditions, we introduce an AI workload surge injection methodology that simulates burst-driven demand patterns observed in large-scale AI systems. Our XGBoost-based model achieves an ROC AUC of 0.697 and an AP of 0.670, significantly outperforming baseline methods. Under deployment-oriented threshold selection, the framework achieves a Recall of 0.914, enabling the detection of the majority of stress-prone periods with acceptable false-alarm cost. Beyond predictive performance, we show how the proposed framework can be integrated into operational control loops to support proactive actions such as workload throttling and resource scaling. Our results highlight the practical value of high-recall, learning-based early warning systems in enabling resilient and adaptive data center operations in the era of AI-driven workloads.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a deployment-oriented burst-aware early warning framework for predicting capacity stress in hyperscale data centers under AI (LLM) workload surges. It formulates the task as high-recall forecasting over multivariate telemetry windows, employs an XGBoost model to handle nonlinear interactions in imbalanced settings, introduces a synthetic AI workload surge injection method to simulate bursty patterns, and reports ROC AUC of 0.697, AP of 0.670, and recall of 0.914 at a chosen threshold, with discussion of integration into operational control loops for actions such as throttling and scaling.
Significance. If the synthetic injection faithfully reproduces real AI-driven burst statistics, the high-recall operating point and operational integration discussion could support practical proactive capacity management in data centers. The emphasis on imbalanced data and deployment-oriented thresholds addresses a relevant operational gap. No machine-checked proofs or parameter-free derivations are present, but the framework's focus on actionable recall is a modest strength.
major comments (2)
- [Abstract] Abstract: The headline metrics (ROC AUC 0.697, AP 0.670, Recall 0.914) and the claim of outperforming baselines rest on telemetry windows that incorporate synthetically injected surges; the abstract asserts these 'simulate burst-driven demand patterns observed in large-scale AI systems' but supplies no quantitative validation (burst-length histograms, peak-to-average ratios, or cross-feature correlations) against production LLM traces. This is load-bearing for the central performance claim.
- [Evaluation section] Evaluation section: No dataset size, feature definitions, cross-validation procedure, baseline definitions, or statistical significance tests are reported for the quoted metrics, leaving the outperformance and high-recall results weakly supported even on the synthetic distribution.
minor comments (1)
- [Abstract] Abstract: The phrase 'significantly outperforming baseline methods' is used without naming the baselines or reporting their scores; this should be clarified with explicit numbers.
Simulated Author's Rebuttal
Thank you for the referee's insightful comments. We have carefully considered each point and provide our responses below, indicating where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline metrics (ROC AUC 0.697, AP 0.670, Recall 0.914) and the claim of outperforming baselines rest on telemetry windows that incorporate synthetically injected surges; the abstract asserts these 'simulate burst-driven demand patterns observed in large-scale AI systems' but supplies no quantitative validation (burst-length histograms, peak-to-average ratios, or cross-feature correlations) against production LLM traces. This is load-bearing for the central performance claim.
Authors: We agree that providing quantitative validation of the synthetic injection method against real production traces would strengthen the claims. However, due to the proprietary nature of hyperscale data center telemetry, we do not have access to such traces for direct comparison. In the revision, we will update the abstract to tone down the claim to 'designed to emulate key burst characteristics observed in AI systems' and add a dedicated subsection detailing the injection parameters along with histograms of burst lengths, peak-to-average ratios, and correlation analyses within the synthetic data. We will also discuss the limitations of synthetic data explicitly. revision: partial
-
Referee: [Evaluation section] Evaluation section: No dataset size, feature definitions, cross-validation procedure, baseline definitions, or statistical significance tests are reported for the quoted metrics, leaving the outperformance and high-recall results weakly supported even on the synthetic distribution.
Authors: This is a fair criticism. The revised manuscript will expand the Evaluation section to include: the total number of telemetry windows and class distribution; detailed definitions of all input features; the cross-validation strategy (time-series aware splits to avoid leakage); explicit descriptions of the baseline methods (e.g., logistic regression, random forest, threshold-based); and results of statistical significance testing (e.g., McNemar's test or bootstrap confidence intervals) for the performance differences. revision: yes
- Direct quantitative validation of synthetic surges against production LLM traces, as access to such proprietary data is not available.
Circularity Check
No significant circularity; standard ML evaluation on held-out simulated traces
full rationale
The paper trains an XGBoost classifier on multivariate telemetry windows that incorporate synthetically injected AI workload surges and reports ROC AUC, AP, and recall on (presumably held-out) evaluation data. This is a conventional supervised learning pipeline with no equations or steps that reduce the reported performance metrics to the model's own fitted parameters by construction. No self-citations are invoked as load-bearing uniqueness theorems, no ansatz is smuggled, and no renaming of known results occurs. The synthetic injection method is presented as an evaluation tool rather than a derivation step whose outputs are presupposed by the model. The central claim therefore remains independent of its inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- XGBoost hyperparameters and decision threshold
axioms (1)
- domain assumption Surge injection methodology produces representative burst patterns
Reference graph
Works this paper leans on
-
[1]
Managing energy and server resources in hosting centers,
J. S. Chase, D. C. Anderson, P. N. Thakar, A. M. Vahdat, and R. P. Doyle, “Managing energy and server resources in hosting centers,”ACM SIGOPS Operating Systems Review, vol. 35, no. 5, pp. 103–116, 2001
2001
-
[2]
On global electricity usage of communication technology: trends to 2030,
A. S. G. Andrae and T. Edler, “On global electricity usage of communication technology: trends to 2030,”Challenges, vol. 6, no. 1, pp. 117–157, 2015
2030
-
[3]
Zhang,Eliminating the Capacity V ariation Penalty for Cloud Resource Management
C. Zhang,Eliminating the Capacity V ariation Penalty for Cloud Resource Management. Ph.D. dissertation, The University of Chicago, UChicago CS Tech Report TR-2023-02, 2023
2023
-
[4]
XGBoost: A scalable tree boosting system,
T. Chen and C. Guestrin, “XGBoost: A scalable tree boosting system,” inProc. 22nd ACM SIGKDD Int. Conf. Knowledge Discovery and Data Mining, 2016, pp. 785–794
2016
-
[5]
FIRM: An intelligent fine-grained resource management framework for SLO- oriented microservices,
H. Qiuet al., “FIRM: An intelligent fine-grained resource management framework for SLO- oriented microservices,” in14th USENIX Symposium on Operating Systems Design and Imple- mentation (OSDI 20), 2020, pp. 805–825
2020
-
[6]
Optimizing resource allocation in hyperscale datacenters: Scalability, usability, and experiences,
N. Kumaret al., “Optimizing resource allocation in hyperscale datacenters: Scalability, usability, and experiences,” in18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), 2024, pp. 507–528
2024
-
[7]
Statistical techniques for online anomaly detection in data centers,
C. Wanget al., “Statistical techniques for online anomaly detection in data centers,” inProc. 12th IFIP/IEEE Int. Symp. Integrated Network Management, 2011, pp. 385–392
2011
-
[8]
Resource management with deep reinforce- ment learning,
H. Mao, M. Alizadeh, I. Menache, and S. Kandula, “Resource management with deep reinforce- ment learning,” inProc. 15th ACM Workshop on Hot Topics in Networks, 2016, pp. 50–56
2016
-
[9]
Trumpet: Timely and precise triggers in data centers,
M. Moshref, M. Yu, R. Govindan, and A. Vahdat, “Trumpet: Timely and precise triggers in data centers,” inProc. ACM SIGCOMM Conf., 2016, pp. 129–141
2016
-
[10]
Regime-dependent volatility dynamics: Evidence from time-series analysis,
K. Cheng, X. Qi, Z. Cheng, L. Lai, and X. Liu, “Regime-dependent volatility dynamics: Evidence from time-series analysis,” inIEEE Int. Conf. Data Science and Advanced Analytics, 2025
2025
-
[11]
AutoNeural: Co-designing vision-language models for NPU inference,
W. Chenet al., “AutoNeural: Co-designing vision-language models for NPU inference,”arXiv preprint arXiv:2512.02942, 2025
arXiv 2025
-
[12]
Filter-And-Refine: A MLLM based cascade system for industrial-scale video content moderation,
Z. Wanget al., “Filter-And-Refine: A MLLM based cascade system for industrial-scale video content moderation,”arXiv preprint arXiv:2507.17040, 2025
arXiv 2025
-
[13]
Beyond math: Stories as a testbed for memorization-constrained reasoning in LLMs,
Y . Jiang and F. Ferraro, “Beyond math: Stories as a testbed for memorization-constrained reasoning in LLMs,” inProc. 19th Conf. European Chapter of the Association for Computational Linguistics (EACL 2026), V olume 1: Long Papers, 2026, pp. 5590–5607
2026
-
[14]
Learning how to use tools, not just when: Pattern- aware tool-integrated reasoning,
N. Xu, Y . Jiang, S. Roy Dipta, and H. Zhang, “Learning how to use tools, not just when: Pattern- aware tool-integrated reasoning,” inProc. 39th Conf. Neural Information Processing Systems (NeurIPS 2025) Workshop: MATH-AI, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.