When Robots Sleep: Offline Skill Consolidation for Shared-Policy Robot Learning
Pith reviewed 2026-06-27 01:01 UTC · model grok-4.3
The pith
Sleeping Robots consolidates a shared policy offline using frozen skill memories and Nash bargaining to prevent skill-coupling collapse during sequential learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
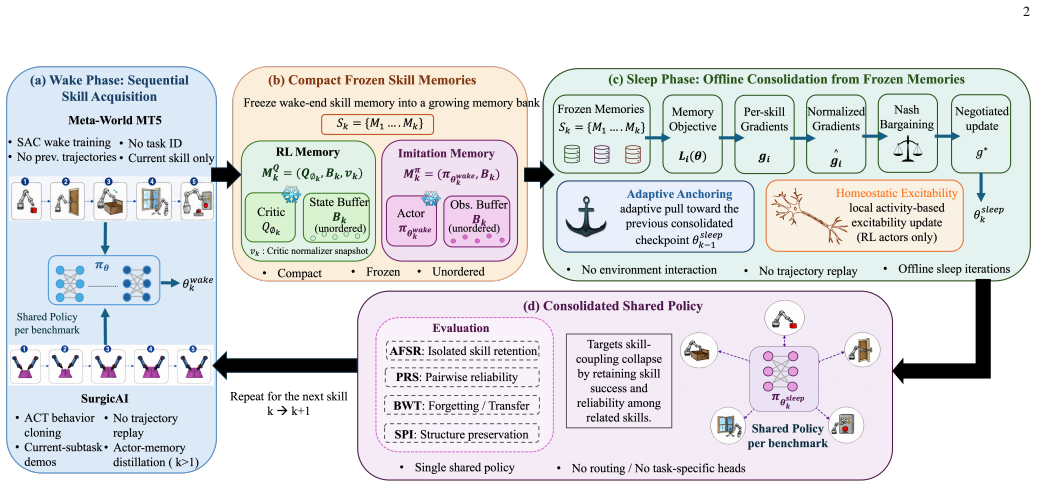
Sleeping Robots learns each new skill during wake and consolidates the shared policy offline during sleep using compact frozen skill memories: frozen critics with unordered state buffers for reinforcement learning and frozen actor snapshots with unordered observation buffers for imitation learning. These memories define differentiable surrogate objectives whose gradients are combined through Nash bargaining, with adaptive anchoring and local excitability for stable consolidation.
What carries the argument
Nash bargaining over gradients from frozen skill memories that serve as surrogate objectives for offline consolidation of a single shared policy.
If this is right
- The deployed policy remains one shared controller without task-specific heads or adapters.
- Sequential skill addition occurs without storing or replaying earlier trajectories.
- Skill-coupling collapse is reduced while individual skill success is maintained or improved.
- Backward transfer improves relative to continual imitation baselines on surgical task suites.
Where Pith is reading between the lines
- The framework could support extended robot deployments where skills accumulate over months without periodic resets.
- Similar frozen-memory consolidation might apply to non-robot continual learning domains that require a single model.
- The method's stability under varying buffer sizes or bargaining weights remains open for direct testing.
Load-bearing premise
Compact frozen skill memories can define differentiable surrogate objectives whose gradients combine stably through Nash bargaining without previous trajectories or task losses.
What would settle it
A trial in which the Nash-bargained gradients from the frozen memories produce policy updates that increase skill-coupling collapse or reduce average success compared to a non-consolidation baseline.
Figures
read the original abstract
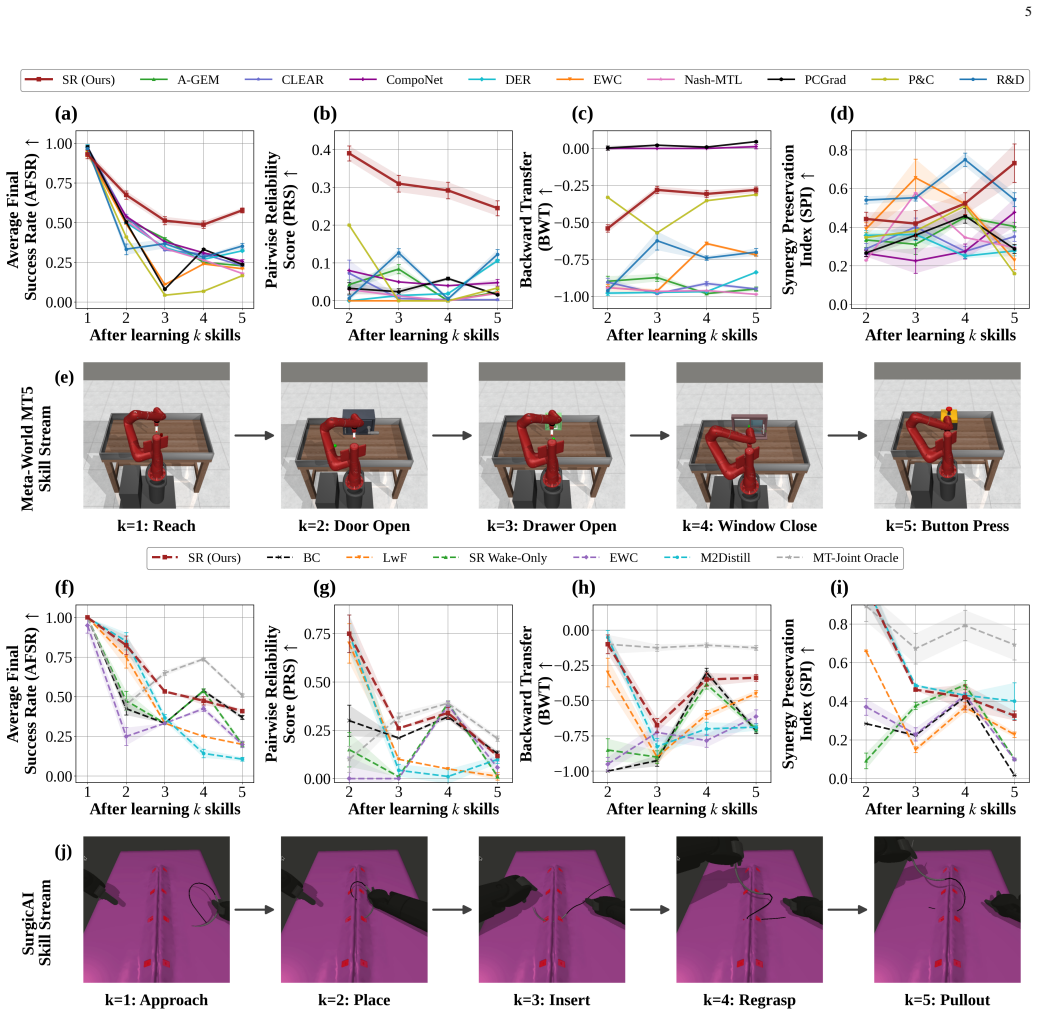
Robots that learn over long deployments must add new skills without losing the shared policy structure that makes earlier skills reusable. We study sequential robot skill learning, where previous trajectories and task losses may be unavailable, and the deployed policy must remain a single shared controller without task-specific heads, routing, or adapters. We identify skill-coupling collapse, a failure mode in which individual skill success remains non-trivial while reliability among related skills deteriorates. We propose Sleeping Robots, a wake-sleep framework that learns each new skill during wake and consolidates the shared policy offline during sleep using compact frozen skill memories: frozen critics with unordered state buffers for reinforcement learning and frozen actor snapshots with unordered observation buffers for imitation learning. During sleep, these memories define differentiable surrogate objectives whose gradients are combined through Nash bargaining, with adaptive anchoring and local excitability for stable consolidation. On Meta-World MT5, Sleeping Robots improves average success by 64 % and pairwise reliability by x 2.0 over the strongest non-oracle baseline, and on SurgicAI it improves average success and backward transfer relative to continual imitation baselines while remaining competitive on pairwise reliability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Sleeping Robots, a wake-sleep framework for sequential robot skill learning under a single shared policy. New skills are acquired during wake phases; offline sleep phases consolidate the policy using compact frozen skill memories (frozen critics with unordered state buffers for RL; frozen actor snapshots with unordered observation buffers for IL). These memories supply differentiable surrogate objectives whose gradients are combined via Nash bargaining augmented by adaptive anchoring and local excitability. The approach is evaluated on Meta-World MT5 (64% average success gain and 2x pairwise reliability over the strongest non-oracle baseline) and SurgicAI (improved average success and backward transfer relative to continual imitation baselines while remaining competitive on pairwise reliability).
Significance. If the consolidation mechanism proves stable, the result would be significant for long-horizon robot deployments that must incorporate new skills without access to prior trajectories or task losses while preserving a single reusable controller. The framing of skill-coupling collapse as a distinct failure mode and the use of Nash bargaining for gradient arbitration are conceptually novel contributions to continual robot learning.
major comments (2)
- [Abstract and §3] Abstract and §3 (method): The central claim requires that frozen critics/actors paired only with unordered buffers produce surrogate objectives whose gradients remain sufficiently aligned and non-conflicting for Nash bargaining + adaptive anchoring + local excitability to consolidate the shared policy. No derivation, stability analysis, or ablation is supplied showing that discarding temporal ordering and task-specific loss structure still yields informative, combinable gradients; this directly undermines verification of the reported gains.
- [Abstract and experimental sections] Abstract and experimental sections: Quantitative claims (64% success improvement and 2x reliability on Meta-World MT5; success and backward-transfer gains on SurgicAI) are stated without any description of the experimental protocol, baseline implementations, statistical tests, number of seeds, or definition of the Nash bargaining step. This absence makes it impossible to assess whether the numbers support the central claim that the proposed surrogates prevent skill-coupling collapse.
minor comments (2)
- [§3] Notation for the surrogate objectives and the precise form of the Nash bargaining objective should be introduced with explicit equations rather than prose descriptions.
- [Experimental evaluation] The manuscript should clarify whether the reported pairwise reliability metric is computed on held-out task pairs or on the training distribution.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for identifying key areas where additional rigor and detail will strengthen the manuscript. We respond to each major comment below and will incorporate the suggested improvements in the revision.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (method): The central claim requires that frozen critics/actors paired only with unordered buffers produce surrogate objectives whose gradients remain sufficiently aligned and non-conflicting for Nash bargaining + adaptive anchoring + local excitability to consolidate the shared policy. No derivation, stability analysis, or ablation is supplied showing that discarding temporal ordering and task-specific loss structure still yields informative, combinable gradients; this directly undermines verification of the reported gains.
Authors: We agree that the current manuscript does not supply a formal derivation or stability analysis of gradient alignment when temporal ordering is discarded. The method is presented as an empirical framework whose effectiveness is demonstrated through the reported benchmark results. In the revised version we will add an ablation study comparing ordered versus unordered buffers, report gradient-norm statistics and conflict measures during sleep phases, and expand the discussion in §3 to explain the design rationale for using compact unordered memories while preserving surrogate informativeness. revision: yes
-
Referee: [Abstract and experimental sections] Abstract and experimental sections: Quantitative claims (64% success improvement and 2x reliability on Meta-World MT5; success and backward-transfer gains on SurgicAI) are stated without any description of the experimental protocol, baseline implementations, statistical tests, number of seeds, or definition of the Nash bargaining step. This absence makes it impossible to assess whether the numbers support the central claim that the proposed surrogates prevent skill-coupling collapse.
Authors: We acknowledge that the submitted manuscript lacks a complete experimental protocol description. The revised version will add a dedicated experimental details section that specifies the number of random seeds (five), the precise baseline implementations and their hyper-parameters, the statistical tests used, and a full algorithmic description of the Nash bargaining procedure including the adaptive anchoring and local excitability mechanisms and their hyper-parameter values. These additions will enable reproduction and direct assessment of the reported gains. revision: yes
Circularity Check
No significant circularity; results framed as empirical benchmark outcomes
full rationale
The paper presents an empirical method (Sleeping Robots) for offline skill consolidation using frozen skill memories and Nash bargaining, with performance claims (64% success improvement, 2x reliability) derived from evaluations on Meta-World MT5 and SurgicAI benchmarks. No equations, derivations, or first-principles results are described that reduce reported metrics to fitted parameters or self-referential definitions. The central claims rest on experimental outcomes rather than any load-bearing self-citation chain or ansatz that collapses to inputs by construction. The reader's assessment of score 2.0 aligns with this, confirming the absence of circular reductions in the derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Efficient Lifelong Learning with A-GEM
A. Chaudhry, M. Ranzato, M. Rohrbach, and M. Elhoseiny, “Efficient lifelong learning with a-gem,”arXiv preprint arXiv:1812.00420,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Progress & compress: A scalable framework for continual learning,
J. Schwarz, W. Czarnecki, J. Luketina, A. Grabska-Barwinska, Y . W. Teh, R. Pascanu, and R. Hadsell, “Progress & compress: A scalable framework for continual learning,” inInternational conference on machine learning. PMLR, 2018, pp. 4528–4537. W. Wan, Y . Zhu, R. Shah, and Y . Zhu, “Lotus: Continual imitation learning for robot manipulation through unsupe...
2018
-
[3]
Self-composing policies for scalable continual reinforcement learning,
M. Malagon, J. Ceberio, and J. A. Lozano, “Self-composing policies for scalable continual reinforcement learning,”arXiv preprint arXiv:2506.14811,
-
[4]
Multi-task learning as a bargaining game,
A. Navon, A. Shamsian, I. Achituve, H. Maron, K. Kawaguchi, G. Chechik, and E. Fetaya, “Multi-task learning as a bargaining game,”arXiv preprint arXiv:2202.01017,
-
[5]
Continual learning through synaptic intelligence,
F. Zenke, B. Poole, and S. Ganguli, “Continual learning through synaptic intelligence,” inInternational conference on machine learning. Pmlr, 2017, pp. 3987–3995. R. Aljundi, F. Babiloni, M. Elhoseiny, M. Rohrbach, and T. Tuytelaars, “Memory aware synapses: Learning what (not) to forget,” inProceedings of the European conference on computer vision (ECCV),...
2017
-
[6]
Same state, different task: Continual reinforcement learning without interference,
8 S. Kessler, J. Parker-Holder, P. Ball, S. Zohren, and S. J. Roberts, “Same state, different task: Continual reinforcement learning without interference,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 36, no. 7, 2022, pp. 7143–7151. H. Ahn, J. Hyeon, Y . Oh, B. Hwang, and T. Moon, “Reset & distill: A recipe for overcoming negative...
2022
-
[7]
Packnet: Adding multiple tasks to a single network by iterative pruning,
A. Mallya and S. Lazebnik, “Packnet: Adding multiple tasks to a single network by iterative pruning,” inProceedings of the IEEE conference on Computer Vision and Pattern Recognition, 2018, pp. 7765–7773. J. Serra, D. Suris, M. Miron, and A. Karatzoglou, “Overcoming catastrophic forgetting with hard attention to the task,” in International conference on ma...
-
[8]
Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning,
T. Yu, D. Quillen, Z. He, R. Julian, K. Hausman, C. Finn, and S. Levine, “Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning,” inConference on robot learning. PMLR, 2020, pp. 1094–1100. T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stocha...
2020
-
[9]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn, “Learning fine-grained bimanual manipulation with low-cost hardware,”arXiv preprint arXiv:2304.13705,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
M2distill: Multi-modal distillation for lifelong imitation learning,
K. Roy, A. Dissanayake, B. Tidd, and P. Moghadam, “M2distill: Multi-modal distillation for lifelong imitation learning,” in 2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 1429–1435. 9 APPENDIX A. Meta-World MT5 Full procedure.Algorithm 1 summarizes the complete wake–sleep lifecycle used in both benchmarks. The algori...
2025
-
[11]
Table V summarizes the training hyperparameters used for MT5
with automatic entropy tuning. Table V summarizes the training hyperparameters used for MT5. TABLE V:SAC hyperparameters for Meta-World MT5 wake training. Setting Value Actor/critic optimizer Adam, learning rate3×10 −4 Entropy coefficient Automatically tuned Entropy optimizer Adam, learning rate3×10 −4 logαclamp[−10,4] Target entropy−2.0 Reward scale1.0 R...
2024
-
[12]
We use early stopping based on anℓ 1 validation-loss plateau after a minimum of 30 epochs, and restore the best-ℓ 1 checkpoint at the end of wake training. For Sleeping Robots, wake training on skillk≥2also includes output-space distillation from the frozen actor memories of previous skills: Lwake =L BC +γ k X i<k Eo∼Bi πθ(o)−π θwake i (o) 2 2 .(6) We use...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.