Diffusion Models for Adaptive Sequential Data Generation
Pith reviewed 2026-06-28 02:52 UTC · model grok-4.3
The pith
A sequential forward-backward diffusion framework generates adapted time series by conditioning the reverse process only on prior history.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By running a forward diffusion that adds noise along the time index and a backward diffusion whose score is conditioned only on the previously generated segment, the procedure produces a measure that is adapted to the natural filtration of the sequence; the same conditioning yields a tractable score-matching loss whose minimizers recover the data distribution at a quantifiable rate when the score is represented by ReLU networks.
What carries the argument
The sequential forward-backward diffusion process whose reverse step is conditioned on the generated history, together with the associated history-conditioned score-matching objective.
If this is right
- The framework supplies explicit rates for score approximation, score estimation, and distribution estimation under a generic setting with ReLU networks as a concrete case.
- A novel score-matching loss enables parallel rather than sequential training of the network across the entire sequence.
- The generated series can be plugged directly into mean-variance portfolio optimization and other downstream decision tasks that require non-anticipative inputs.
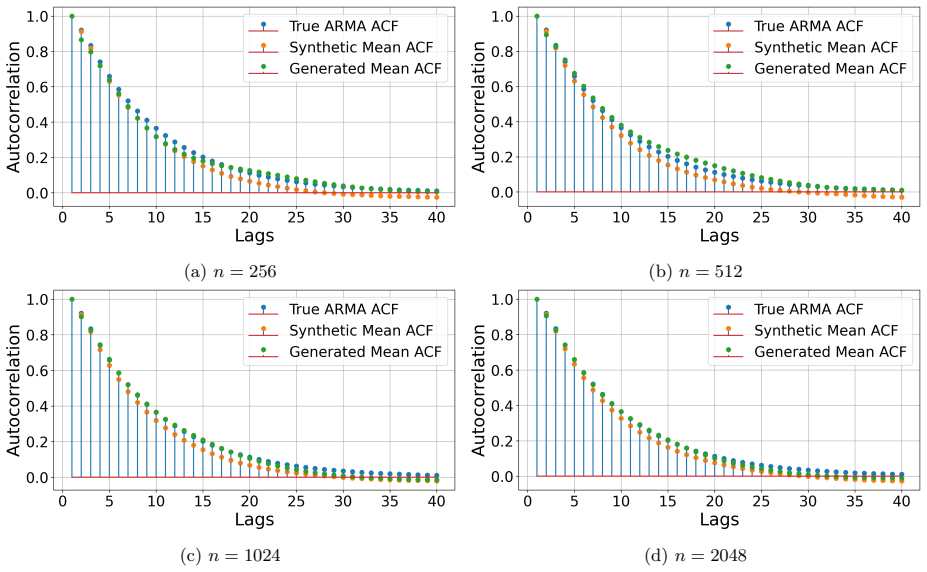
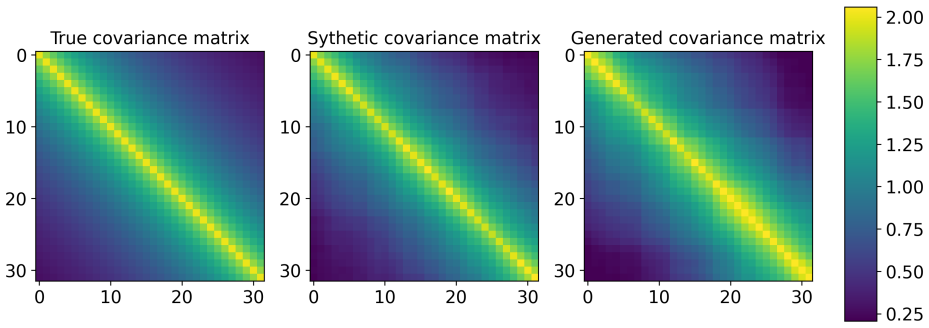
- The same construction applies to standard synthetic benchmarks such as ARMA models and Gaussian processes.
Where Pith is reading between the lines
- The same conditioning idea could be tested on real financial tick data or medical time series to check whether the generated paths respect regulatory non-anticipation constraints.
- If the statistical guarantees hold beyond the ReLU case, the method might serve as a building block for online simulation engines that feed into stochastic control or reinforcement-learning pipelines.
- The parallel training property suggests possible speed-ups when the sequence length is large, an aspect that could be quantified on longer synthetic or real traces.
Load-bearing premise
Conditioning the backward process solely on the finite generated history is enough to produce a genuinely adapted measure, which requires that the underlying data-generating process itself is adapted and that the score remains consistently estimable from that history.
What would settle it
Generated trajectories whose empirical law exhibits statistically significant dependence on observations that lie strictly after the current time index, or whose total variation distance to the target law fails to contract at the rate predicted by the distribution estimation theorem.
Figures
read the original abstract
Generating realistic synthetic sequential data is critical in real-world applications across operations research, finance, healthcare, energy systems, and scientific computing, where time-indexed observations are used for prediction, simulation, risk assessment, and data-driven decision-making. While diffusion models have achieved remarkable success in generating static data, their direct extensions to sequential settings often fail to capture temporal dependence and information structure. Designing diffusion models that can simulate sequential data in an adapted manner, and hence without anticipation of future information, therefore remains an open challenge. In this work, we propose a sequential forward-backward diffusion framework for adapted time series generation. Our approach progressively injects and removes noise along the sequence, conditioning on the previously generated history to ensure adaptiveness. A novel score-matching objective is introduced for efficient parallel training. We derive rigorous statistical guarantees under a generic framework, then establish score approximation, score estimation, and distribution estimation results with ReLU networks serving as a concrete instance. Empirically, we validate our method on synthetic data, including ARMA models and Gaussian processes, and demonstrate its effectiveness in constructing mean-variance optimal portfolios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a sequential forward-backward diffusion framework for adapted time series generation that conditions the backward process solely on previously generated history to enforce non-anticipative (adapted) measures. It introduces a novel score-matching objective enabling parallel training, derives statistical guarantees on score approximation/estimation and distribution estimation (instantiated with ReLU networks), and validates the approach empirically on ARMA processes, Gaussian processes, and a mean-variance portfolio task.
Significance. If the claimed statistical guarantees hold with a correct measurability argument, the work would address a genuine gap in applying diffusion models to sequential data under information constraints relevant to finance, operations research, and healthcare. The empirical component on synthetic data provides a concrete testbed, but the absence of any derivation outline or explicit assumptions in the central claims limits the assessed impact.
major comments (2)
- [Abstract] Abstract: the claim of deriving 'rigorous statistical guarantees' together with 'score approximation, score estimation, and distribution estimation results' is stated without any outline of assumptions, error bounds, or derivation steps; this is load-bearing for the paper's primary contribution and prevents verification of the central guarantee.
- [Abstract] Framework description (conditioning on history): the assertion that conditioning the backward process only on previously generated history 'ensures adaptiveness' lacks an explicit lemma or proposition establishing that the learned score remains measurable with respect to the filtration generated by the history; without this, the distribution estimation results do not automatically transfer to the adapted (non-anticipative) setting.
minor comments (1)
- [Abstract] Abstract: the empirical validation mentions ARMA models and Gaussian processes but provides no detail on the quantitative metrics, sample sizes, or baseline comparisons used.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help improve the clarity of our contributions. We address each point below and will incorporate revisions to enhance the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of deriving 'rigorous statistical guarantees' together with 'score approximation, score estimation, and distribution estimation results' is stated without any outline of assumptions, error bounds, or derivation steps; this is load-bearing for the paper's primary contribution and prevents verification of the central guarantee.
Authors: We agree that the abstract would benefit from a concise outline of the key results to facilitate verification. In the revision, we will modify the abstract to include: 'Under standard assumptions on the data-generating process and score function (detailed in Section 3), we establish score approximation bounds of order O(m^{-1/2}) for ReLU networks with m parameters, score estimation error O(n^{-1/2}) with n samples, and distribution estimation in total variation distance. Full proofs are provided in Sections 3-5.' This provides the necessary high-level information without exceeding abstract length constraints. revision: yes
-
Referee: [Abstract] Framework description (conditioning on history): the assertion that conditioning the backward process only on previously generated history 'ensures adaptiveness' lacks an explicit lemma or proposition establishing that the learned score remains measurable with respect to the filtration generated by the history; without this, the distribution estimation results do not automatically transfer to the adapted (non-anticipative) setting.
Authors: This is a valid point regarding the measurability. While the framework conditions the score on the history by construction (the network input is restricted to past timesteps), we will add an explicit proposition in Section 2.3 stating that the sequentially generated process is adapted to the filtration generated by the observed history. This proposition will show that the learned score is measurable w.r.t. the history sigma-algebra, ensuring the non-anticipative property and allowing the distribution estimation guarantees to apply directly to the adapted measures. We believe this addition will resolve the concern. revision: yes
Circularity Check
No circularity: generic framework and concrete ReLU instance remain independent
full rationale
The abstract describes deriving statistical guarantees under a generic framework followed by establishing approximation/estimation results with ReLU networks as a concrete instance. No equations, self-citations, fitted parameters renamed as predictions, or self-definitional steps are visible in the provided text. The adaptiveness claim is presented as following from conditioning on history, without reduction to its own inputs by construction. This is the common case of a self-contained derivation against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Time-causal VAE: Robust financial time series generator.SIAM Journal on Financial Mathematics, 17(1):245–279, 2026
Beatrice Acciaio, Stephan Eckstein, and Songyan Hou. Time-causal VAE: Robust financial time series generator.SIAM Journal on Financial Mathematics, 17(1):245–279, 2026
2026
-
[2]
Robust time series generation via Schr¨ odinger Bridge: a comprehensive evaluation
Alexandre Alouadi, Baptiste Barreau, Laurent Carlier, and Huyˆ en Pham. Robust time series generation via Schr¨ odinger Bridge: a comprehensive evaluation. InProceedings of the 6th ACM International Conference on AI in Finance, ICAIF 2025, Singapore, November 15–18, 2025, pages 906–914. ACM, 2025
2025
-
[3]
Tail-GAN: Learning to simulate tail risk scenarios.Management Science, 72(4):2917–2936, 2025
Rama Cont, Mihai Cucuringu, Renyuan Xu, and Chao Zhang. Tail-GAN: Learning to simulate tail risk scenarios.Management Science, 72(4):2917–2936, 2025
2025
-
[4]
Continuous-time mean-variance portfolio selection: A stochastic LQ frame- work.Applied Mathematics & Optimization, 42(1):19–33, 2000
Xun Yu Zhou and Duan Li. Continuous-time mean-variance portfolio selection: A stochastic LQ frame- work.Applied Mathematics & Optimization, 42(1):19–33, 2000
2000
-
[5]
Dynamic portfolio execution.Management Science, 65(5):2015–2040, 2019
Gerry Tsoukalas, Jiang Wang, and Kay Giesecke. Dynamic portfolio execution.Management Science, 65(5):2015–2040, 2019
2015
-
[6]
q-learning in continuous time.Journal of Machine Learning Research, 24(161):1–61, 2023
Yanwei Jia and Xun Yu Zhou. q-learning in continuous time.Journal of Machine Learning Research, 24(161):1–61, 2023
2023
-
[7]
Data-driven generative simulation of SDEs using diffusion models
Xuefeng Gao, Jiale Zha, and Xun Yu Zhou. Data-driven generative simulation of SDEs using diffusion models. InNeurIPS 2025 Workshop MLxOR: Mathematical Foundations and Operational Integration of Machine Learning for Uncertainty-Aware Decision-Making, 2025
2025
-
[8]
Towards realistic market simulations: a generative adversarial networks approach
Andrea Coletta, Matteo Prata, Michele Conti, Emanuele Mercanti, Novella Bartolini, Aymeric Moulin, Svitlana Vyetrenko, and Tucker Balch. Towards realistic market simulations: a generative adversarial networks approach. InProceedings of the Second ACM International Conference on AI in Finance, pages 1–9, 2021
2021
-
[9]
Yilie Huang, Yanwei Jia, and Xun Yu Zhou. Mean–variance portfolio selection by continuous-time rein- forcement learning: Algorithms, regret analysis, and empirical study.arXiv preprint arXiv:2412.16175, 2024
-
[10]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[11]
Taming transformers for high-resolution image synthesis
Patrick Esser, Robin Rombach, and Bjorn Ommer. Taming transformers for high-resolution image synthesis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12873–12883, 2021
2021
-
[12]
Offline reinforcement learning as one big sequence modeling problem.Advances in neural information processing systems, 34:1273–1286, 2021
Michael Janner, Qiyang Li, and Sergey Levine. Offline reinforcement learning as one big sequence modeling problem.Advances in neural information processing systems, 34:1273–1286, 2021
2021
-
[13]
AdaCat: Adaptive Categorical Discretization for Autore- gressive Models
Qiyang Li, Aravind Jain, and Pieter Abbeel. AdaCat: Adaptive Categorical Discretization for Autore- gressive Models. In James Cussens and Kun Zhang, editors,Proceedings of the Thirty-Eighth Conference on Uncertainty in Artificial Intelligence, volume 180 ofProceedings of Machine Learning Research, pages 1210–1219. PMLR, 2022. 26
2022
-
[14]
Autoregressive image generation using residual quantization
Doyup Lee, Chiheon Kim, Saehoon Kim, Minsu Cho, and Wook-Shin Han. Autoregressive image generation using residual quantization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11523–11532, 2022
2022
-
[15]
Autoregressive image generation without vector quantization
Tianhong Li, Yonglong Tian, He Li, Mingyang Deng, and Kaiming He. Autoregressive image generation without vector quantization. InAdvances in Neural Information Processing Systems, volume 37, pages 56424–56445, 2024
2024
-
[16]
Generative modeling by estimating gradients of the data distribution
Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution. Advances in neural information processing systems, 32, 2019
2019
-
[17]
Score-based generative modeling through stochastic differential equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. InInternational Conference on Learning Representations, 2021
2021
-
[18]
Denoising diffusion probabilistic models.Advances in Neural Information Processing Systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in Neural Information Processing Systems, 33:6840–6851, 2020
2020
-
[19]
Diffusion models beat GANs on image synthesis.Advances in neural information processing systems, 34:8780–8794, 2021
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat GANs on image synthesis.Advances in neural information processing systems, 34:8780–8794, 2021
2021
-
[20]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨ orn Ommer. High- resolution image synthesis with latent diffusion models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10684–10695, 2022
2022
-
[21]
Improving image generation with better captions.OpenAI technical report, 2023
James Betker, Gabriel Goh, Li Jing, Tim Brooks, Jianfeng Wang, Linjie Li, Long Ouyang, Juntang Zhuang, Joyce Lee, Yufei Guo, et al. Improving image generation with better captions.OpenAI technical report, 2023
2023
-
[22]
De novo design of protein structure and function with rfdiffusion.Nature, 620(7976):1089–1100, 2023
Joseph L Watson, David Juergens, Nathaniel R Bennett, Brian L Trippe, Jason Yim, Helen E Eisenach, Woody Ahern, Andrew J Borst, Robert J Ragotte, Lukas F Milles, et al. De novo design of protein structure and function with rfdiffusion.Nature, 620(7976):1089–1100, 2023
2023
-
[23]
Equivariant diffusion for molecule generation in 3D
Emiel Hoogeboom, Vıctor Garcia Satorras, Cl´ ement Vignac, and Max Welling. Equivariant diffusion for molecule generation in 3D. InInternational conference on machine learning, pages 8867–8887. PMLR, 2022
2022
-
[24]
Conditional Generative Adversarial Nets
Mehdi Mirza and Simon Osindero. Conditional generative adversarial nets.arXiv:1411.1784, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[25]
Real-valued (Medical) Time Series Generation with Recurrent Conditional GANs
Crist´ obal Esteban, Stephanie L Hyland, and Gunnar R¨ atsch. Real-valued (medical) time series gener- ation with recurrent conditional GANs.arXiv preprint arXiv:1706.02633, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[26]
Time series simulation by condi- tional generative adversarial net.International Journal of Neural Networks and Advanced Applications, 7:25–38, 2020
Rao Fu, Jie Chen, Shutian Zeng, Yiping Zhuang, and Agus Sudjianto. Time series simulation by condi- tional generative adversarial net.International Journal of Neural Networks and Advanced Applications, 7:25–38, 2020
2020
-
[27]
Time-series generative adversarial networks
Jinsung Yoon, Daniel Jarrett, and Mihaela van der Schaar. Time-series generative adversarial networks. Advances in Neural Information Processing Systems, 32:5508–5518, 2019
2019
-
[28]
Generative adversarial networks for financial trading strategies fine-tuning and combination.Quantitative Finance, 21(5):797–813, 2021
Adriano Koshiyama, Nick Firoozye, and Philip Treleaven. Generative adversarial networks for financial trading strategies fine-tuning and combination.Quantitative Finance, 21(5):797–813, 2021
2021
-
[29]
Sig- Wasserstein GANs for conditional time series generation.Mathematical Finance, 34(2):622–670, 2024
Shujian Liao, Hao Ni, Marc Sabate-Vidales, Lukasz Szpruch, Magnus Wiese, and Baoren Xiao. Sig- Wasserstein GANs for conditional time series generation.Mathematical Finance, 34(2):622–670, 2024
2024
-
[30]
Generating realistic stock market order streams.AAAI Conference on Artificial Intelligence, 34(01):727–734, 2020
Junyi Li, Xintong Wang, Yaoyang Lin, Arunesh Sinha, and Michael Wellman. Generating realistic stock market order streams.AAAI Conference on Artificial Intelligence, 34(01):727–734, 2020
2020
-
[31]
Fin-GAN: Forecasting and classifying financial time series via generative adversarial networks.Quantitative Finance, 24(2):175–199, 2024
Milena Vuleti´ c, Felix Prenzel, and Mihai Cucuringu. Fin-GAN: Forecasting and classifying financial time series via generative adversarial networks.Quantitative Finance, 24(2):175–199, 2024. 27
2024
-
[32]
VolGAN: A generative model for arbitrage-free implied volatility surfaces.Applied Mathematical Finance, 31(4):203–238, 2025
Milena Vuleti´ c and Rama Cont. VolGAN: A generative model for arbitrage-free implied volatility surfaces.Applied Mathematical Finance, 31(4):203–238, 2025
2025
-
[33]
Quant GANs: Deep generation of financial time series.Quantitative Finance, 20(9):1419–1440, 2020
Magnus Wiese, Robert Knobloch, Ralf Korn, and Peter Kretschmer. Quant GANs: Deep generation of financial time series.Quantitative Finance, 20(9):1419–1440, 2020
2020
-
[34]
PCF-GAN: generating sequential data via the characteristic function of measures on the path space
Hang Lou, Siran Li, and Hao Ni. PCF-GAN: generating sequential data via the characteristic function of measures on the path space. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 39755–39781. Curran Associates, Inc., 2023
2023
-
[35]
Generating financial markets with signatures.Available at SSRN 3657366, 2020
Hans Buehler, Blanka Horvath, Terry Lyons, Imanol Perez Arribas, and Ben Wood. Generating financial markets with signatures.Available at SSRN 3657366, 2020
2020
-
[36]
A data-driven market simulator for small data environments
Hans B¨ uhler, Blanka Horvath, Terry Lyons, Imanol Perez Arribas, and Ben Wood. A data-driven market simulator for small data environments. In Dan Crisan, Ilya Chevyrev, Thomas Cass, James Foster, Christian Litterer, and Cristopher Salvi, editors,Stochastic Analysis and Applications 2025: In Honour of Terry Lyons, pages 273–310. Springer Nature Switzerland, 2026
2025
-
[37]
Abhyuday Desai, Cynthia Freeman, Zuhui Wang, and Ian Beaver. TimeVAE: A variational auto-encoder for multivariate time series generation.arXiv preprint arXiv:2111.08095, 2021
-
[38]
Multi-asset spot and option market simulation.arXiv preprint arXiv:2112.06823, 2021
Magnus Wiese, Ben Wood, Alexandre Pachoud, Ralf Korn, Hans Buehler, Phillip Murray, and Lianjun Bai. Multi-asset spot and option market simulation.arXiv preprint arXiv:2112.06823, 2021
-
[39]
Hybrid variational autoencoder for time series forecasting.Knowledge-Based Systems, 281:111079, 2023
Borui Cai, Shuiqiao Yang, Longxiang Gao, and Yong Xiang. Hybrid variational autoencoder for time series forecasting.Knowledge-Based Systems, 281:111079, 2023
2023
-
[40]
Time-transformer: Integrating local and global features for better time series generation
Yuansan Liu, Sudanthi Wijewickrema, Ang Li, Christofer Bester, Stephen O’Leary, and James Bailey. Time-transformer: Integrating local and global features for better time series generation. InProceedings of the 2024 SIAM International Conference on Data Mining (SDM), pages 325–333. SIAM, 2024
2024
-
[41]
Generative learning for financial time series with irreg- ular and scale-invariant patterns
Hongbin Huang, Minghua Chen, and Xiao Qiao. Generative learning for financial time series with irreg- ular and scale-invariant patterns. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[42]
Autoregressive denoising diffusion models for multivariate probabilistic time series forecasting
Kashif Rasul, Calvin Seward, Ingmar Schuster, and Roland Vollgraf. Autoregressive denoising diffusion models for multivariate probabilistic time series forecasting. InInternational Conference on Machine Learning (ICML), 2021
2021
-
[43]
Regular time-series generation using SGM
Haksoo Lim, Minjung Kim, Sewon Park, and Noseong Park. Regular time-series generation using SGM. arXiv preprint arXiv:2301.08518, 2023
-
[44]
Haksoo Lim, Jaehoon Lee, Sewon Park, Minjung Kim, and Noseong Park. TSGM: Regular and irregular time-series generation using score-based generative models.arXiv preprint arXiv:2511.21335, 2025
-
[45]
Diffusion-TS: Interpretable diffusion for general time series generation
Xinyu Yuan and Yan Qiao. Diffusion-TS: Interpretable diffusion for general time series generation. In The Twelfth International Conference on Learning Representations, 2024
2024
-
[46]
Utilizing image transforms and diffusion models for generative modeling of short and long time series
Ilan Naiman, Nimrod Berman, Itai Pemper, Idan Arbiv, Gal Fadlon, and Omri Azencot. Utilizing image transforms and diffusion models for generative modeling of short and long time series. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Systems, volume 37, pages 121699–12...
2024
-
[47]
A survey on diffusion models for time series and spatio-temporal data.ACM Computing Surveys, 58(8):1–39, 2026
Yiyuan Yang, Ming Jin, Haomin Wen, Chaoli Zhang, Yuxuan Liang, Lintao Ma, Yi Wang, Chenghao Liu, Bin Yang, Zenglin Xu, Shirui Pan, and Qingsong Wen. A survey on diffusion models for time series and spatio-temporal data.ACM Computing Surveys, 58(8):1–39, 2026
2026
-
[48]
Ahmad Aghapour, Erhan Bayraktar, and Fengyi Yuan. Solving dynamic portfolio selection problems via score-based diffusion models.arXiv preprint arXiv:2507.09916, 2025. 28
-
[49]
Deep generative learning via Schr¨ odinger bridge
Gefei Wang, Yuling Jiao, Qian Xu, Yang Wang, and Can Yang. Deep generative learning via Schr¨ odinger bridge. InInternational Conference on Machine Learning (ICML), 2021
2021
-
[50]
Diffusion Schr¨ odinger bridge with applications to score-based generative modeling
Valentin De Bortoli, James Thornton, Jeremy Heng, and Arnaud Doucet. Diffusion Schr¨ odinger bridge with applications to score-based generative modeling. InAdvances in Neural Information Processing Systems, 2021
2021
-
[51]
Generative modeling for time series via Schr¨ odinger bridge.arXiv preprint arXiv:2304.05093, 2023
Mohamed Hamdouche, Pierre Henry-Labordere, and Huyˆ en Pham. Generative modeling for time series via Schr¨ odinger bridge.arXiv preprint arXiv:2304.05093, 2023
-
[52]
Sampling is as easy as learning the score: theory for diffusion models with minimal data assumptions
Sitan Chen, Sinho Chewi, Jerry Li, Yuanzhi Li, Adil Salim, and Anru R Zhang. Sampling is as easy as learning the score: theory for diffusion models with minimal data assumptions. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[53]
Convergence for score-based generative modeling with poly- nomial complexity.Advances in Neural Information Processing Systems, 35:22870–22882, 2022
Holden Lee, Jianfeng Lu, and Yixin Tan. Convergence for score-based generative modeling with poly- nomial complexity.Advances in Neural Information Processing Systems, 35:22870–22882, 2022
2022
-
[54]
Let us build bridges: Understanding and extending diffusion generative models
Xingchao Liu, Lemeng Wu, Mao Ye, and qiang liu. Let us build bridges: Understanding and extending diffusion generative models. InNeurIPS 2022 Workshop on Score-Based Methods, 2022
2022
-
[55]
Convergence of score-based generative modeling for general data distributions
Holden Lee, Jianfeng Lu, and Yixin Tan. Convergence of score-based generative modeling for general data distributions. InInternational Conference on Algorithmic Learning Theory, pages 946–985. PMLR, 2023
2023
-
[56]
Improved analysis of score-based generative modeling: User-friendly bounds under minimal smoothness assumptions
Hongrui Chen, Holden Lee, and Jianfeng Lu. Improved analysis of score-based generative modeling: User-friendly bounds under minimal smoothness assumptions. InInternational Conference on Machine Learning, pages 4735–4763. PMLR, 2023
2023
-
[57]
Nearlyd-linear convergence bounds for diffusion models via stochastic localization
Joe Benton, Valentin De Bortoli, Arnaud Doucet, and George Deligiannidis. Nearlyd-linear convergence bounds for diffusion models via stochastic localization. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[58]
Restoration-degradation beyond linear diffu- sions: A non-asymptotic analysis for DDIM-type samplers
Sitan Chen, Giannis Daras, and Alexandros G Dimakis. Restoration-degradation beyond linear diffu- sions: A non-asymptotic analysis for DDIM-type samplers. InInternational Conference on Machine Learning, pages 4462–4484. PMLR, 2023
2023
-
[59]
Towards non-asymptotic convergence for diffusion- based generative models
Gen Li, Yuting Wei, Yuxin Chen, and Yuejie Chi. Towards non-asymptotic convergence for diffusion- based generative models. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[60]
Improved convergence of score-based diffusion models via prediction-correction.Transactions on Machine Learning Research, 2024
Francesco Pedrotti, Jan Maas, and Marco Mondelli. Improved convergence of score-based diffusion models via prediction-correction.Transactions on Machine Learning Research, 2024. ISSN 2835-8856
2024
-
[61]
Convergence of flow-based generative models via proximal gradient descent in Wasserstein space.IEEE Transactions on Information Theory, 70(11): 8087–8106, 2024
Xiuyuan Cheng, Jianfeng Lu, Yixin Tan, and Yao Xie. Convergence of flow-based generative models via proximal gradient descent in Wasserstein space.IEEE Transactions on Information Theory, 70(11): 8087–8106, 2024
2024
-
[62]
Convergence analysis of probability flow ODE for score-based generative models.IEEE Transactions on Information Theory, 71(6):4581–4601, 2025
Daniel Zhengyu Huang, Jiaoyang Huang, and Zhengjiang Lin. Convergence analysis of probability flow ODE for score-based generative models.IEEE Transactions on Information Theory, 71(6):4581–4601, 2025
2025
-
[63]
Broadening target distributions for accel- erated diffusion models via a novel analysis approach
Yuchen Liang, Peizhong Ju, Yingbin Liang, and Ness Shroff. Broadening target distributions for accel- erated diffusion models via a novel analysis approach. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[64]
Gen Li and Yuling Yan.O(d/T) convergence theory for diffusion probabilistic models under minimal assumptions.Journal of Machine Learning Research, 26(292):1–55, 2025
2025
-
[65]
Contractive diffusion probabilistic models.arXiv preprint arXiv:2401.13115, 2024
Wenpin Tang and Hanyang Zhao. Contractive diffusion probabilistic models.arXiv preprint arXiv:2401.13115, 2024. 29
-
[66]
Unified convergence analysis for score-based diffusion models with deterministic samplers
Runjia Li, Qiwei Di, and Quanquan Gu. Unified convergence analysis for score-based diffusion models with deterministic samplers. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[67]
Rotskoff, and Lexing Ying
Yinuo Ren, Haoxuan Chen, Grant M. Rotskoff, and Lexing Ying. How discrete and continuous diffusion meet: Comprehensive analysis of discrete diffusion models via a stochastic integral framework. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[68]
Convergence analysis for general probability flow ODEs of diffusion models in Wasserstein distances
Xuefeng Gao and Lingjiong Zhu. Convergence analysis for general probability flow ODEs of diffusion models in Wasserstein distances. InProceedings of The 28th International Conference on Artificial Intelligence and Statistics, volume 258 ofProceedings of Machine Learning Research, pages 1009–1017. PMLR, 2025
2025
-
[69]
Beyond log-concavity and score regularity: Improved convergence bounds for score-based generative models in W2-distance
Marta Gentiloni-Silveri and Antonio Ocello. Beyond log-concavity and score regularity: Improved convergence bounds for score-based generative models in W2-distance. InProceedings of the 42nd In- ternational Conference on Machine Learning, volume 267 ofProceedings of Machine Learning Research, pages 55631–55656. PMLR, 2025
2025
-
[70]
On sta- tistical rates of conditional diffusion transformers: Approximation, estimation and minimax optimality
Jerry Yao-Chieh Hu, Weimin Wu, Yi-Chen Lee, Yu-Chao Huang, Minshuo Chen, and Han Liu. On sta- tistical rates of conditional diffusion transformers: Approximation, estimation and minimax optimality. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[71]
Low-dimensional adaptation of diffusion models: Convergence in total variation
Jiadong Liang, Zhihan Huang, and Yuxin Chen. Low-dimensional adaptation of diffusion models: Convergence in total variation. InProceedings of Thirty Eighth Conference on Learning Theory, volume 291 ofProceedings of Machine Learning Research, pages 3723–3729. PMLR, 2025
2025
-
[72]
Localized diffusion models.arXiv preprint arXiv:2505.04417, 2025
Georg A Gottwald, Shuigen Liu, Youssef Marzouk, Sebastian Reich, and Xin T Tong. Localized diffusion models.arXiv preprint arXiv:2505.04417, 2025
-
[73]
Song Mei and Yuchen Wu. Deep networks as denoising algorithms: Sample-efficient learning of diffusion models in high-dimensional graphical models.IEEE Transactions on Information Theory, 71(4):2930– 2954, 2025
2025
-
[74]
Diffusion Model for Manifold Data: Score Decomposition, Curvature, and Statistical Complexity
Zixuan Zhang, Kaixuan Huang, Tuo Zhao, Mengdi Wang, and Minshuo Chen. Diffusion model for mani- fold data: Score decomposition, curvature, and statistical complexity.arXiv preprint arXiv:2603.20645, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[75]
Diffusion models are minimax optimal distribution estimators
Kazusato Oko, Shunta Akiyama, and Taiji Suzuki. Diffusion models are minimax optimal distribution estimators. InProceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pages 26517–26582. PMLR, 2023
2023
-
[76]
Optimal score estimation via empirical Bayes smoothing
Andre Wibisono, Yihong Wu, and Kaylee Yingxi Yang. Optimal score estimation via empirical Bayes smoothing. InProceedings of Thirty Seventh Conference on Learning Theory, volume 247 ofProceedings of Machine Learning Research, pages 4958–4991. PMLR, 2024
2024
-
[77]
Minimax optimality of score-based diffusion models: Beyond the density lower bound assumptions
Kaihong Zhang, Heqi Yin, Feng Liang, and Jingbo Liu. Minimax optimality of score-based diffusion models: Beyond the density lower bound assumptions. InProceedings of the 41st International Confer- ence on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 60134–60178. PMLR, 2024
2024
-
[78]
Neural network-based score estimation in diffu- sion models: Optimization and generalization
Yinbin Han, Meisam Razaviyayn, and Renyuan Xu. Neural network-based score estimation in diffu- sion models: Optimization and generalization. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[79]
From optimal score matching to optimal sampling.arXiv preprint arXiv:2409.07032, 2024
Zehao Dou, Subhodh Kotekal, Zhehao Xu, and Harrison H Zhou. From optimal score matching to optimal sampling.arXiv preprint arXiv:2409.07032, 2024
-
[80]
Score approximation, estimation and distribution recovery of diffusion models on low-dimensional data
Minshuo Chen, Kaixuan Huang, Tuo Zhao, and Mengdi Wang. Score approximation, estimation and distribution recovery of diffusion models on low-dimensional data. InInternational Conference on Machine Learning, pages 4672–4712. PMLR, 2023. 30
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.