Quantum vs. Classical Machine Learning: A Unified Empirical Comparison
Pith reviewed 2026-07-02 15:07 UTC · model grok-4.3
The pith
Quantum machine learning models do not surpass classical baselines in prediction performance, policy stability, or training time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The evaluated quantum machine learning models do not yet surpass the classical baselines in overall prediction performance, policy stability, or training time. Nevertheless, QML remains a promising approach for filtering noise and controlling false positives.
What carries the argument
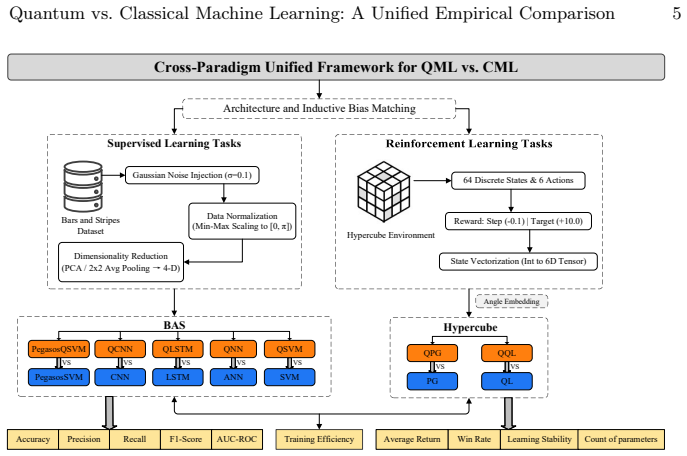
The unified empirical comparison across seven model pairs in supervised learning and reinforcement learning tasks.
If this is right
- QML development must address hardware limitations, training efficiency, and convergence stability.
- Parameter optimization and robustness improvements are required before quantum models can compete on standard metrics.
- QML may be most useful in domains where noise filtering or false-positive reduction is the dominant requirement.
Where Pith is reading between the lines
- The results suggest prioritizing hybrid quantum-classical pipelines that use quantum components only for the noise-filtering sub-task.
- Extending the comparison to unsupervised learning or generative tasks would test whether the performance gap is task-dependent.
Load-bearing premise
The seven chosen model pairs and the specific supervised and reinforcement learning tasks are representative enough to support the general conclusion that QML does not yet surpass classical methods.
What would settle it
A replication on a broader set of tasks or datasets in which the quantum models show both higher accuracy and faster training than the classical baselines would falsify the main claim.
Figures
read the original abstract
Quantum computing has emerged as a promising computational paradigm for machine learning (ML), with the potential to offer computational advantages over classical approaches. At this stage, the evidence supporting the performance and advantages of quantum machine learning (QML) models relative to classical models is insufficient. To address this gap, this paper presents an empirical study on the performance of QML models and their classical counterparts. We compare seven model pairs spanning supervised learning and reinforcement learning. Our results indicate that the evaluated quantum machine learning models do not yet surpass the classical baselines in overall prediction performance, policy stability, or training time. Nevertheless, QML remains a promising approach for filtering noise and controlling false positives. Our research findings summarize the challenges facing quantum machine learning across hardware environments, training efficiency, and convergence stability, providing a foundation for research into the robustness and parameter optimization of QML. This work is publicly available at https://github.com/Z-537-437/QML.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents an empirical comparison of seven quantum machine learning (QML) model pairs against classical baselines across supervised learning and reinforcement learning tasks. It concludes that the tested QML models do not surpass classical methods in prediction performance, policy stability, or training time, while noting potential advantages in noise filtering and false-positive control. The work identifies challenges in hardware environments, training efficiency, and convergence stability, and releases code at a public GitHub repository.
Significance. If the seven model pairs are representative, the study supplies a useful benchmark documenting the current absence of clear QML advantages on standard tasks and supplies reproducible code, which strengthens its utility for the community. The negative result on overall performance combined with the positive note on noise handling could usefully guide subsequent work on ansatz design and optimization. The limited scope of the evaluation, however, restricts how far the general claim can be taken.
major comments (1)
- [Abstract and model-selection/results section] Abstract and the section describing the seven model pairs: the headline claim that 'the evaluated quantum machine learning models do not yet surpass the classical baselines in overall prediction performance, policy stability, or training time' rests on comparisons of only seven specific pairs. No selection criteria, coverage argument, or sensitivity analysis is supplied to show these pairs adequately represent the broader space of recent variational circuits, hardware-aware implementations, or alternative ansätze. This representativeness issue is load-bearing for the general conclusion.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comment below and will revise the manuscript accordingly to improve clarity on scope and limitations.
read point-by-point responses
-
Referee: [Abstract and model-selection/results section] Abstract and the section describing the seven model pairs: the headline claim that 'the evaluated quantum machine learning models do not yet surpass the classical baselines in overall prediction performance, policy stability, or training time' rests on comparisons of only seven specific pairs. No selection criteria, coverage argument, or sensitivity analysis is supplied to show these pairs adequately represent the broader space of recent variational circuits, hardware-aware implementations, or alternative ansätze. This representativeness issue is load-bearing for the general conclusion.
Authors: We agree that the manuscript would benefit from greater transparency on model selection. The abstract and results explicitly qualify conclusions as applying to 'the evaluated quantum machine learning models,' and the seven pairs were chosen to span common variational approaches in supervised and reinforcement learning tasks with publicly available implementations. However, no explicit selection criteria or sensitivity discussion appears in the current text. We will revise the abstract, add a dedicated subsection on model selection rationale (including coverage of ansatz families and hardware considerations), and include a limitations paragraph on generalizability. A limited sensitivity check on hyperparameter variations will also be added where data permits. revision: yes
Circularity Check
No circularity: direct empirical benchmark comparison
full rationale
The paper reports results from running seven specific QML-classical model pairs on chosen supervised and RL tasks. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. Conclusions rest on external benchmark executions rather than internal definitions or reductions to inputs. The representativeness concern is a question of scope, not circularity.
Axiom & Free-Parameter Ledger
free parameters (1)
- model hyperparameters and training settings
axioms (1)
- domain assumption The seven model pairs and chosen tasks sufficiently represent the current state of QML versus classical ML.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.