YawDD+: Frame-level Annotations for Accurate Yawn Prediction
Pith reviewed 2026-05-21 16:43 UTC · model grok-4.3
The pith
Frame-level yawn annotations improve detection accuracy by up to 6% over video-level labels on edge devices
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors develop a semi-automated labeling pipeline with human-in-the-loop verification to create frame-level annotations for the YawDD dataset, resulting in YawDD+. When training MNasNet for classification and YOLOv11 for detection on this new data, they observe improvements of up to 6% in frame accuracy and 5% in mAP compared to video-level supervision. This yields 99.34% classification accuracy and 95.69% detection mAP, with efficient training and inference speeds on Jetson NANO and AGX hardware, showing that better data quality enables on-device fatigue monitoring without cloud computing.
What carries the argument
The semi-automated labeling pipeline with human-in-the-loop verification for producing frame-level ground truth annotations.
If this is right
- Up to 6% higher frame accuracy for yawn classification using MNasNet.
- 5% higher mAP for yawn detection using YOLOv11.
- Real-time inference up to 115 FPS and fast training of 8.69 minutes per epoch on Jetson AGX.
- On-device operation for driver fatigue monitoring without reliance on server-side computation.
Where Pith is reading between the lines
- Similar annotation improvements could enhance other video-based safety detection tasks beyond yawning.
- The efficiency gains suggest these models could be deployed in a wider range of vehicles with limited computing power.
- Future work might explore automating the human verification step further while maintaining label quality.
Load-bearing premise
The reported performance gains result from the quality of the frame-level annotations produced by the pipeline rather than from differences in how the models were trained or the data was split.
What would settle it
Training the MNasNet and YOLOv11 models on the original YawDD dataset using the exact same procedures, splits, and hyperparameters as for YawDD+ and observing whether the accuracy and mAP remain lower.
Figures

read the original abstract
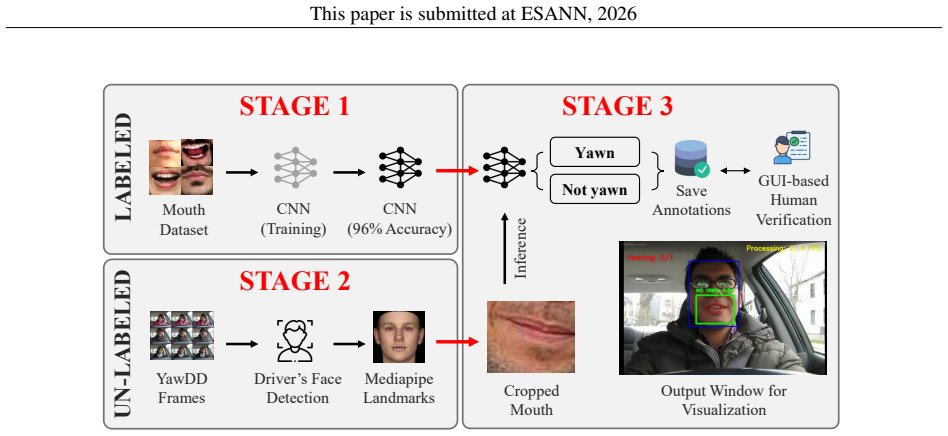
Driver fatigue remains a leading cause of road accidents, responsible for 24% of crashes. While yawning serves as an early behavioral indicator of fatigue, existing approaches face significant challenges due to the presence of systematic noise in video-annotated datasets arising from coarse temporal annotations. Training robust machine learning (ML) models requires rich supervisory labels that help learn salient features from the training data. Moreover, efficient on-device training and inference of models on edge devices is crucial in driver fatigue detection tasks to enable accurate real-time decisions on vehicles without reliance on cloud infrastructure. To address this issue, we develop a semi-automated labeling pipeline with human-in-the-loop verification to annotate YawDD videos to YawDD+ frame-level annotations, enabling more accurate model training on edge platforms such as NVIDIA Jetson NANO. Training the established MNasNet classifier and YOLOv11 detector architectures on YawDD+ improves frame accuracy by up to 6% and mAP by 5% over video-level supervision, achieving 99.34% classification accuracy and 95.69% detection mAP on Jetson NANO and AGX. Moreover, MNasNet completed the epoch time in just 8.69 min/epoch while delivering up to 115 frames-per-second (FPS) inference time on AGX, confirming that enhanced data quality alone supports on-device driver fatigue monitoring systems without server-side computation. The YawDD+ dataset and trained models are available online.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces YawDD+, a frame-level annotated extension of the YawDD dataset for yawn detection, created via a semi-automated labeling pipeline with human-in-the-loop verification. It reports that training MNasNet (classification) and YOLOv11 (detection) on YawDD+ yields up to 6% higher frame accuracy and 5% higher mAP than video-level supervision, reaching 99.34% accuracy and 95.69% mAP on Jetson NANO/AGX, with training times of 8.69 min/epoch and inference up to 115 FPS on AGX, supporting on-device driver fatigue monitoring.
Significance. If the performance gains are shown to stem specifically from the frame-level annotations, the work would offer practical value for real-time edge-based fatigue detection in vehicles by demonstrating that annotation quality improvements can enable accurate on-device models without cloud dependency. The public release of the YawDD+ dataset and trained models strengthens reproducibility.
major comments (2)
- [Abstract] Abstract: The reported gains of up to 6% frame accuracy and 5% mAP from YawDD+ frame-level labels over video-level supervision do not state that data splits, augmentations, optimizer schedules, batch sizes, and random seeds were held identical across the two settings. Without explicit confirmation of these matched controls, the attribution of improvements to annotation granularity alone cannot be substantiated.
- [Methods] Labeling pipeline description: No quantitative metrics are provided for the accuracy or bias of the semi-automated frame-level annotations (e.g., inter-annotator agreement on a held-out subset or estimated label error rates). This information is necessary to establish that the new ground truth is free of systematic bias and is the primary cause of the observed performance differences rather than other experimental factors.
minor comments (1)
- [Abstract] Abstract: The phrasing 'enhanced data quality alone supports...' implies a causal conclusion that would be better supported after the controlled experiments requested in the major comments.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review of our manuscript on YawDD+. The comments highlight important aspects of experimental controls and annotation validation that we address point by point below. We have revised the manuscript to incorporate clarifications and additional discussion where feasible.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported gains of up to 6% frame accuracy and 5% mAP from YawDD+ frame-level labels over video-level supervision do not state that data splits, augmentations, optimizer schedules, batch sizes, and random seeds were held identical across the two settings. Without explicit confirmation of these matched controls, the attribution of improvements to annotation granularity alone cannot be substantiated.
Authors: We agree that explicit confirmation of matched experimental controls is essential to attribute performance differences to annotation quality. All experiments used identical data splits (same train/validation/test partitions), augmentations, optimizer schedules, batch sizes, and random seeds for both video-level and frame-level supervision settings. This was done to isolate the effect of label granularity. We have now added an explicit statement to this effect in the revised abstract and expanded the experimental setup section of the manuscript. revision: yes
-
Referee: [Methods] Labeling pipeline description: No quantitative metrics are provided for the accuracy or bias of the semi-automated frame-level annotations (e.g., inter-annotator agreement on a held-out subset or estimated label error rates). This information is necessary to establish that the new ground truth is free of systematic bias and is the primary cause of the observed performance differences rather than other experimental factors.
Authors: We acknowledge that quantitative metrics such as inter-annotator agreement or estimated label error rates on a held-out subset would provide stronger evidence for annotation quality. The semi-automated pipeline relied on human-in-the-loop verification by domain experts across all frames, and the consistent gains across two distinct architectures (MNasNet and YOLOv11) support that the improvements stem from finer-grained labels. However, computing additional agreement metrics would have required a separate multi-annotator study beyond the scope of the current work. We have added a limitations paragraph discussing potential residual label noise and the reliance on expert verification. revision: partial
Circularity Check
No circularity: empirical gains reported from standard training on new annotations
full rationale
The paper presents an empirical study: a semi-automated pipeline creates frame-level YawDD+ annotations, after which established models (MNasNet, YOLOv11) are trained and evaluated on held-out data, yielding reported accuracy/mAP numbers. No equations, fitted parameters, or derivations are shown that reduce the claimed 6% / 5% improvements to self-referential definitions, renamed inputs, or self-citation chains. The central claim rests on external benchmarks (standard supervised training and test-set metrics) rather than any construction that makes the output equivalent to the input by definition. This is the normal, non-circular outcome for an annotation-and-evaluation paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human-in-the-loop verification produces reliable frame-level ground truth superior to video-level labels.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We develop a semi-automated labeling pipeline with human-in-the-loop verification to annotate YawDD videos to YawDD+ frame-level annotations... Training the established MNasNet classifier and YOLOv11 detector architectures on YawDD+ improves frame accuracy by up to 6% and mAP by 5% over video-level supervision
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
Sheila G Klauer, Thomas A Dingus, Vicki L Neale, Jeremy D Sudweeks, David J Ramsey, et al. The impact of driver inattention on near-crash/crash risk: An analysis using the 100-car naturalistic driving study data. Technical report, United States. Department of Transportation. National Highway Traffic Safety . . . , 2006
work page 2006
-
[3]
Yawdd: A yawning detection dataset
Shabnam Abtahi, Mona Omidyeganeh, Shervin Shirmohammadi, and Behnoosh Hariri. Yawdd: A yawning detection dataset. InProceedings of the 5th ACM multimedia systems conference, pages 24–28, 2014
work page 2014
-
[4]
Mnasnet: Platform-aware neural architecture search for mobile
Mingxing Tan, Bo Chen, Ruoming Pang, Vijay Vasudevan, Mark Sandler, Andrew Howard, and Quoc V Le. Mnasnet: Platform-aware neural architecture search for mobile. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2820–2828, 2019
work page 2019
-
[5]
YOLOv11: An Overview of the Key Architectural Enhancements
Rahima Khanam and Muhammad Hussain. Yolov11: An overview of the key architectural enhancements.arXiv preprint arXiv:2410.17725, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Jing Bai, Wentao Yu, Zhu Xiao, Vincent Havyarimana, Amelia C Regan, Hongbo Jiang, and Licheng Jiao. Two-stream spatial–temporal graph convolutional networks for driver drowsiness detection.IEEE Transactions on Cybernetics, 52(12):13821–13833, 2021
work page 2021
-
[7]
Fiaz Majeed, Umair Shafique, Mejdl Safran, Sultan Alfarhood, and Imran Ashraf. Detection of drowsiness among drivers using novel deep convolutional neural network model.Sensors, 23(21):8741, 2023
work page 2023
-
[8]
Mingyang XU, Ao ZHAN, Chengyu WU, and Zhengqiang W ANG. A novel driver fatigue detection method based on dual-stream swin-transformer.IEICE Transactions on Information and Systems, page 2024EDL8094, 2025
work page 2025
-
[9]
Esra Civik and Ugur Yuzgec. Real-time driver fatigue detection system with deep learning on a low-cost embedded system.Microprocessors and Microsystems, 99:104851, 2023
work page 2023
-
[10]
Hu He, Xiaoyong Zhang, Fu Jiang, Chenglong Wang, Yingze Yang, Weirong Liu, and Jun Peng. A real-time driver fatigue detection method based on two-stage convolutional neural network.IF AC-PapersOnLine, 53(2):15374– 15379, 2020
work page 2020
- [11]
-
[12]
Yolov8: A novel object detection algorithm with enhanced performance and robustness
Rejin Varghese and M Sambath. Yolov8: A novel object detection algorithm with enhanced performance and robustness. In2024 International conference on advances in data engineering and intelligent computing systems (ADICS), pages 1–6. IEEE, 2024
work page 2024
- [13]
-
[14]
Siham Essahraui, Ismail Lamaakal, Ikhlas El Hamly, Yassine Maleh, Ibrahim Ouahbi, Khalid El Makkaoui, Mouncef Filali Bouami, Paweł Pławiak, Osama Alfarraj, and Ahmed A Abd El-Latif. Real-time driver drowsiness detection using facial analysis and machine learning techniques.Sensors, 25:812, 2025. 5
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.