WiSP: A Working-Set View of Mixture-of-Experts Serving on Extremely Low-Resource Hardware
Pith reviewed 2026-06-26 12:39 UTC · model grok-4.3
The pith
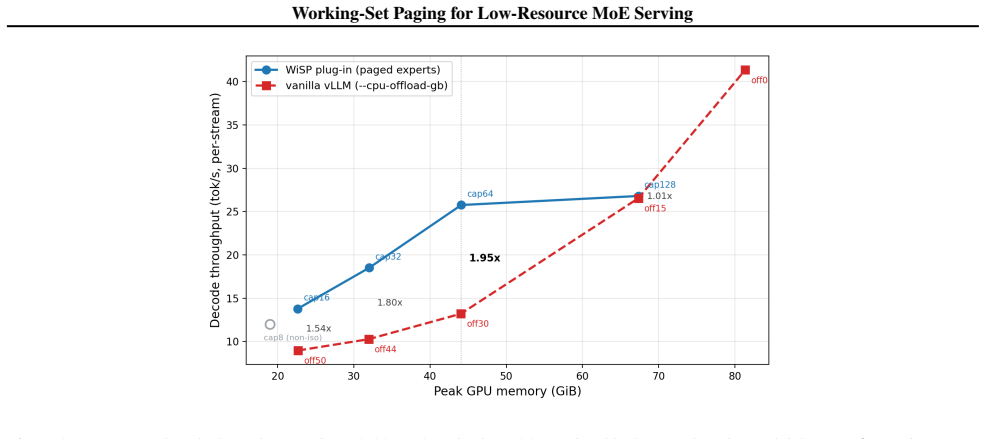
Managing MoE experts as a working set with routing-aware paging delivers up to 1.95 times higher decode throughput than static offload at fixed memory budget.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
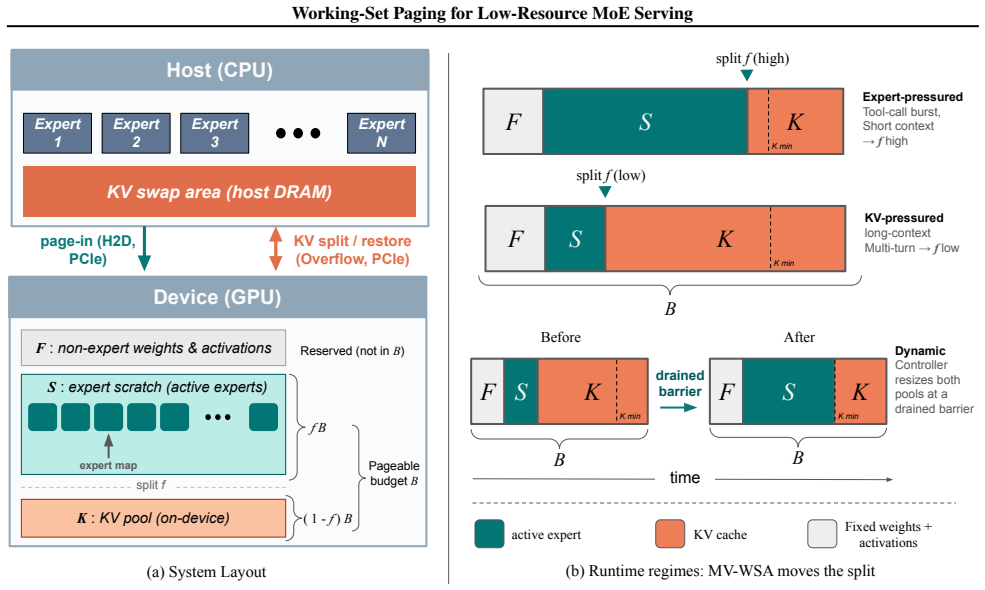
WiSP treats routed expert weights and the KV cache as two streams of memory demand competing for limited VRAM and realizes a routing-aware expert pager that keeps resident only the experts a workload reuses, reaching up to 1.95x the decode throughput of static offload at the same memory budget when the model does not fit. MV-WSA equalizes marginal latency benefit per byte subject to a KV admission floor and stays within a few percent of a per-workflow oracle while fixed splits are about 20 percent worse.
What carries the argument
WiSP, a routing-aware expert pager that plugs into an unmodified serving engine with byte-identical outputs, managing experts via working-set paging.
If this is right
- WiSP reaches up to 1.95x the decode throughput of static offload at the same memory budget.
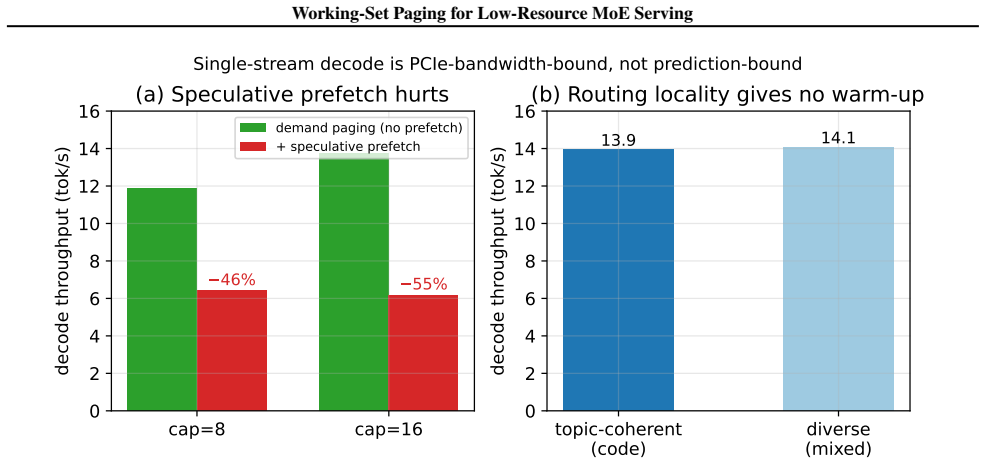
- Prefetching experts from predicted routing helps little in single-stream decode because the bottleneck is PCIe bandwidth.
- MV-WSA as offline configurator does well on both prefill and decode.
- The online controller adds a further 1.20x without changing model outputs.
Where Pith is reading between the lines
- If workloads show high expert reuse, similar paging could apply to other sparse models beyond MoE.
- Allocating VRAM based on marginal value could generalize to other memory-constrained inference settings like quantization tradeoffs.
- Testing on multi-stream serving might change the conclusion that prefetching adds little value.
- Integrating WiSP with existing engines without modification suggests it can be adopted quickly in production.
Load-bearing premise
Real serving workloads exhibit sufficient expert reuse locality for a working-set pager to deliver large gains without accuracy loss or excessive paging traffic.
What would settle it
Running WiSP on a synthetic workload that activates every expert equally often would produce throughput no better than static offload at the same memory budget.
Figures
read the original abstract
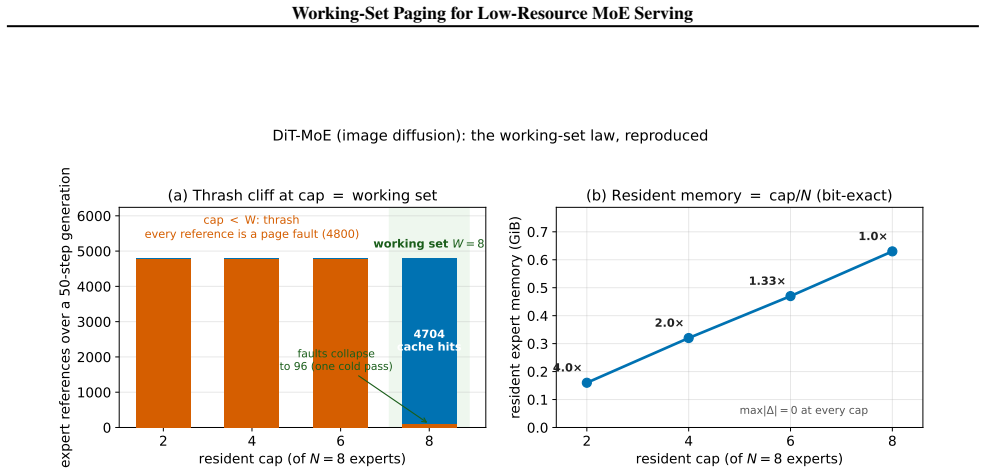
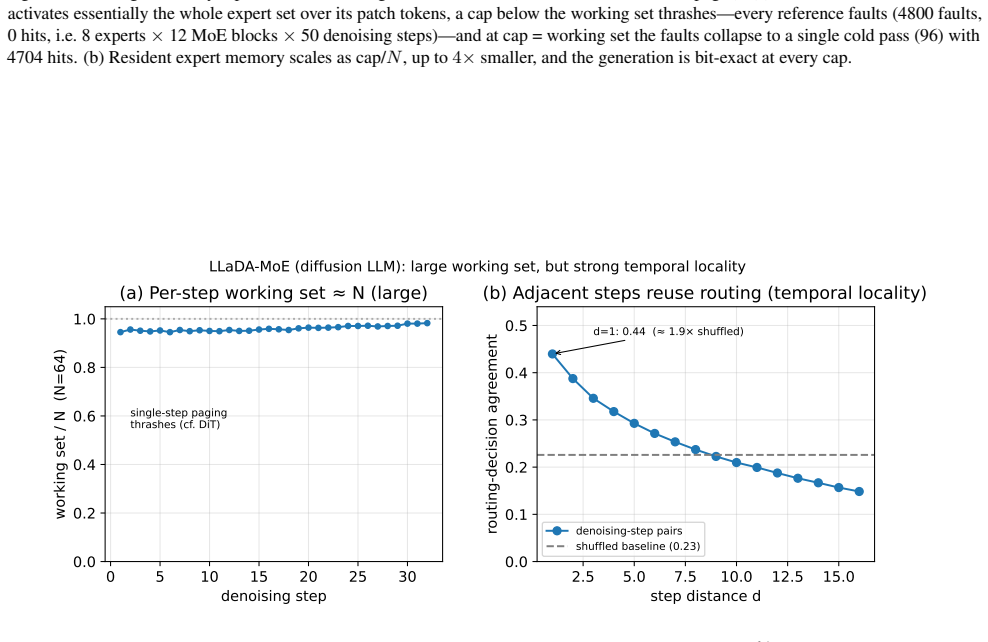
Modern Mixture-of-Experts (MoE) models place most of their parameters in expert layers, yet only a small fraction of those experts are used for any token. The unused weights must still be stored where the GPU can reach them. On commodity GPUs the common fix is layer-level CPU offloading, which keeps memory low but streams all of a layer's experts across PCIe on every forward pass, losing much of MoE's sparsity benefit. We cast low-resource MoE serving as a working-set management problem on the GPU: routed expert weights and the key-value (KV) cache are two streams of memory demand competing for limited VRAM. We realize this in WiSP (Working-Set Paging), a routing-aware expert pager that plugs into an unmodified serving engine with byte-identical outputs. Keeping resident only the experts a workload reuses, WiSP reaches up to 1.95x the decode throughput of static offload at the same memory budget when the model does not fit. We also find that prefetching experts from predicted routing helps little in single-stream decode: the bottleneck is PCIe bandwidth, not prediction accuracy. This shifts the question from prefetching to allocation: how should VRAM be split between experts and the KV cache? We answer with MV-WSA (Marginal-Value Working-Set Allocation), which equalizes marginal latency benefit per byte subject to a KV admission floor. MV-WSA runs either as an offline configurator or as an online controller that resizes both pools while serving. In real serving the offline configurator is the only policy we test that does well on both prefill and decode; in trace-driven simulation it stays within a few percent of a per-workflow oracle while fixed splits are about 20% worse. The online controller adds a further 1.20x without changing model outputs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents WiSP, a routing-aware expert pager for Mixture-of-Experts serving on low-resource GPUs that treats routed expert weights and the KV cache as competing memory streams. It claims that keeping only reused experts resident yields up to 1.95× decode throughput versus static offload at fixed memory budget when the model does not fit, that prefetching adds little because PCIe bandwidth is the bottleneck, and that MV-WSA allocation (offline or online) equalizes marginal latency benefit per byte while respecting a KV floor, staying close to an oracle in simulation and outperforming fixed splits in real serving.
Significance. If the locality-dependent gains are reproducible, the work offers a practical way to serve large MoE models on commodity hardware by replacing full-layer offloading with working-set management, while preserving byte-identical outputs and requiring no engine changes. The observation that prediction accuracy matters less than bandwidth, together with the MV-WSA policy that can run offline or online, supplies a concrete allocation heuristic that could be adopted by serving systems.
major comments (3)
- [Abstract] Abstract: the headline 1.95× decode throughput result is stated without any description of the serving traces, model sizes, batch sizes, error bars, or exact baseline implementations (static offload details, PCIe configuration). Because the result is purely empirical and the central claim rests on these measurements, the absence of this information prevents assessment of whether the speedup generalizes beyond the unreported conditions.
- [Abstract] Abstract and results sections: the performance advantage is predicated on workloads exhibiting high expert reuse locality so that the working-set pager incurs low paging traffic. No per-trace statistics (working-set size relative to total experts, hit rate, or paging volume under MV-WSA) are reported, nor is a low-locality counter-example workload evaluated. Without these data the 1.95× figure cannot be separated from the specific traces used.
- [MV-WSA description] The MV-WSA policy is described as equalizing marginal latency benefit per byte subject to a KV admission floor, yet the manuscript provides neither the precise marginal-value function nor the algorithm used to compute the split in the online controller. This makes it impossible to verify that the reported 1.20× additional gain is produced by the stated policy rather than by other implementation choices.
minor comments (1)
- [Abstract] The abstract states that WiSP 'plugs into an unmodified serving engine,' but the integration points (hooks for routing decisions, memory allocator overrides) are not enumerated, which would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline 1.95× decode throughput result is stated without any description of the serving traces, model sizes, batch sizes, error bars, or exact baseline implementations (static offload details, PCIe configuration). Because the result is purely empirical and the central claim rests on these measurements, the absence of this information prevents assessment of whether the speedup generalizes beyond the unreported conditions.
Authors: We agree that the abstract lacks sufficient experimental context. In the revised manuscript we will expand the abstract to include the model sizes (Mixtral 8x7B and 8x22B), the serving traces, batch sizes, error bars from repeated runs, and the precise static-offload baseline (including PCIe generation and bandwidth). revision: yes
-
Referee: [Abstract] Abstract and results sections: the performance advantage is predicated on workloads exhibiting high expert reuse locality so that the working-set pager incurs low paging traffic. No per-trace statistics (working-set size relative to total experts, hit rate, or paging volume under MV-WSA) are reported, nor is a low-locality counter-example workload evaluated. Without these data the 1.95× figure cannot be separated from the specific traces used.
Authors: We acknowledge the need for locality metrics. We will add per-trace statistics (working-set size relative to total experts, hit rate, and paging volume) to the results section. We will also include a low-locality synthetic trace to show the expected performance convergence to static offload, thereby clarifying the conditions under which the reported gains hold. revision: yes
-
Referee: [MV-WSA description] The MV-WSA policy is described as equalizing marginal latency benefit per byte subject to a KV admission floor, yet the manuscript provides neither the precise marginal-value function nor the algorithm used to compute the split in the online controller. This makes it impossible to verify that the reported 1.20× additional gain is produced by the stated policy rather than by other implementation choices.
Authors: We agree that the precise marginal-value function and online algorithm were omitted. The revised manuscript will include the exact marginal-value definition (latency derivative per allocated byte for each pool), the optimization procedure, and pseudocode for both offline and online MV-WSA controllers so that the 1.20× gain can be directly attributed to the policy. revision: yes
Circularity Check
No circularity; all central claims are empirical measurements
full rationale
The paper's core results (1.95x decode throughput, MV-WSA allocation policy) are obtained from direct runtime measurements on serving traces and trace-driven simulation. No equations, fitted parameters, or first-principles derivations are presented that reduce to their own inputs by construction. The working-set and marginal-value policies are defined and then evaluated; they are not claimed to be mathematically derived from prior results in a self-referential manner. Self-citation is absent from the provided text, and the evaluation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Expert routing patterns in serving workloads exhibit reuse locality sufficient for a working-set pager to reduce PCIe traffic substantially.
- domain assumption PCIe bandwidth, not routing prediction accuracy, is the primary bottleneck in single-stream decode.
invented entities (2)
-
WiSP expert pager
no independent evidence
-
MV-WSA allocator
no independent evidence
Reference graph
Works this paper leans on
-
[1]
BlackMamba: Mixture of experts for state-space models
Anthony, Q., Tokpanov, Y ., Glorioso, P., and Millidge, B. BlackMamba: Mixture of experts for state-space models. arXiv preprint arXiv:2402.01771,
-
[2]
DeepSeek-V3 technical report.arXiv preprint arXiv:2412.19437,
DeepSeek-AI. DeepSeek-V3 technical report.arXiv preprint arXiv:2412.19437,
-
[3]
Eliseev, A. and Mazur, D. Fast inference of Mixture-of- Experts language models with offloading.arXiv preprint arXiv:2312.17238,
-
[4]
Scaling dif- fusion transformers to 16 billion parameters (DiT-MoE)
Fei, Z., Fan, M., Yu, C., Li, D., and Huang, J. Scaling dif- fusion transformers to 16 billion parameters (DiT-MoE). arXiv preprint arXiv:2407.11633,
-
[5]
Huang, Y ., Fang, Z., Luo, W., Wu, R., Chen, W., and Zheng, Z. DyMoE: Dynamic expert orchestration with mixed- precision quantization for efficient MoE inference on edge.arXiv preprint arXiv:2603.19172,
-
[6]
Jiang, A. Q. et al. Mixtral of experts.arXiv preprint arXiv:2401.04088,
-
[7]
Kimi-VL technical report.arXiv preprint arXiv:2504.07491,
Kimi Team. Kimi-VL technical report.arXiv preprint arXiv:2504.07491,
-
[8]
Li, D. et al. Aria: An open multimodal native mixture-of- experts model.arXiv preprint arXiv:2410.05993,
-
[9]
Lieber, O. et al. Jamba: A hybrid transformer-Mamba language model.arXiv preprint arXiv:2403.19887,
-
[10]
Y ., Jiang, H., Wang, Z., Zhao, A., and Lee, P
Liu, Q., He, C. Y ., Jiang, H., Wang, Z., Zhao, A., and Lee, P. P. C. FluxMoE: Decoupling expert residency for high-performance MoE serving.arXiv preprint arXiv:2604.02715,
-
[11]
Nie, S. et al. Large language diffusion models (LLaDA). arXiv preprint arXiv:2502.09992,
-
[12]
Qwen3 technical report.arXiv preprint arXiv:2505.09388,
Qwen Team. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
-
[13]
Wu, Z. et al. DeepSeek-VL2: Mixture-of-experts vision- language models for advanced multimodal understanding. arXiv preprint arXiv:2412.10302,
-
[14]
Xue, L., Fu, Y ., Lu, Z., Mai, L., and Marina, M. MoE-Infinity: Efficient MoE inference on personal ma- chines with sparsity-aware expert cache.arXiv preprint arXiv:2401.14361,
-
[15]
LLaDA-MoE: A sparse MoE diffusion language model.arXiv preprint arXiv:2509.24389,
Zhu, F., You, Z., Xing, Y ., Huang, Z., et al. LLaDA-MoE: A sparse MoE diffusion language model.arXiv preprint arXiv:2509.24389,
-
[16]
On the systems side, PagedAttention in vLLM (Kwon et al.,
A RELATEDWORK WiSP’s conceptual basis is Denning’s working-set model and thrashing theory (Denning, 1968; 1970); our contri- bution is to recognize that low-resource MoE serving is a direct instance and to transplant the vocabulary wholesale. On the systems side, PagedAttention in vLLM (Kwon et al.,
1968
-
[17]
assigns experts mixed pre- cision (down to skipping) to shrink edge transfers. All share WiSP’s premise that expert residency is the bottleneck, but each spends the routing signal onprefetching for speed— which Section 4 shows is a net loss in single-stream decode, where no compute hides a transfer—and none allocates the freed expert budget against the KV...
2026
-
[18]
reduce the other side of the joint working set and compose with WiSP rather than competing with it. Finally, WiSP is evaluated across MoE LLMs (Shazeer et al., 2017; Fedus et al., 2022; Jiang et al., 2024; DeepSeek-AI, 2024; Qwen Team, 2025), MoE VLMs (Wu et al., 2024; Kimi Team, 2025; Li et al., 2024), a hybrid SSM-MoE (Lieber et al., 2024; Anthony et al...
2017
-
[19]
B MV-WSA ONLINECONTROLLER The online controller (Algorithm
and language (Nie et al., 2025; Zhu et al., 2025); we use these only as test subjects and change none of them. B MV-WSA ONLINECONTROLLER The online controller (Algorithm
2025
-
[20]
is a working proof of concept on real kernels: it runs the closed-form step-curve rule rather than the full equimarginal estimator, it is driven from the in-process v1 engine (not yet wired into the multi-process vllm serve loop), its byte-identity under a resize cycle is established by a dedicated resize-cycle check rather than a standing regression test...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.