Mind the Gap: Bridging Behavioral Silos with LLMs in Multi-Vertical Recommendations
Pith reviewed 2026-06-27 23:02 UTC · model grok-4.3
The pith
LLMs with a hierarchical RAG pipeline generate synthetic features from restaurant data that improve personalization in grocery and retail verticals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A hierarchical RAG pipeline that uses LLMs to derive multi-level taxonomic features from user restaurant order histories and search queries produces representations of long-term cross-vertical preferences and short-term intent; when these representations are supplied as inputs to a production multi-task learning ranking model, they measurably raise personalization quality and user engagement in data-sparse verticals such as grocery and retail.
What carries the argument
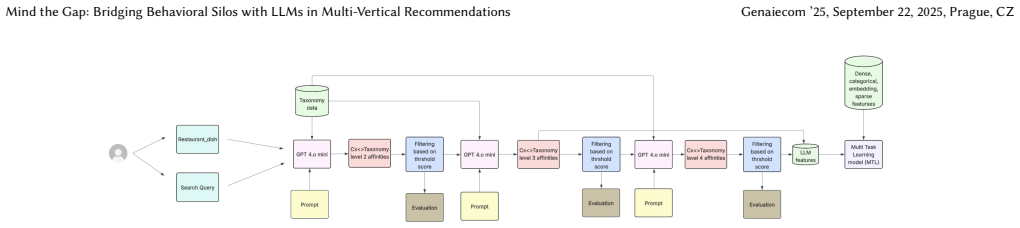
The hierarchical Retrieval-Augmented Generation (RAG) pipeline that extracts multi-level taxonomic features from restaurant histories and queries to encode latent cross-vertical user affinities.
If this is right
- The generated features supply both long-term preference signals and short-term intent signals to the ranking model.
- Integration of these features into the existing multi-task learning architecture raises recommendation quality in the target verticals.
- The same pipeline reduces the severity of the cold-start problem for users who have activity only in the source vertical.
- Offline metrics and live A/B tests both register gains in personalization and engagement once the features are deployed.
Where Pith is reading between the lines
- The same generative approach could be applied to any pair of verticals where one has dense behavioral logs and the other does not.
- If the taxonomic features prove stable across time, they might support lighter-weight retraining schedules for the ranking model.
- Platforms could test whether the same pipeline works when the source vertical is changed to the one with the next-highest data volume.
Load-bearing premise
The features produced by the hierarchical RAG pipeline reliably capture genuine cross-vertical user affinities rather than introducing noise or domain-specific mismatch between restaurant and grocery behaviors.
What would settle it
An A/B test in which the ranking model augmented with the RAG-derived features shows no statistically significant lift in click-through rate, order rate, or session engagement for grocery users relative to the unaugmented baseline would falsify the central claim.
Figures


read the original abstract
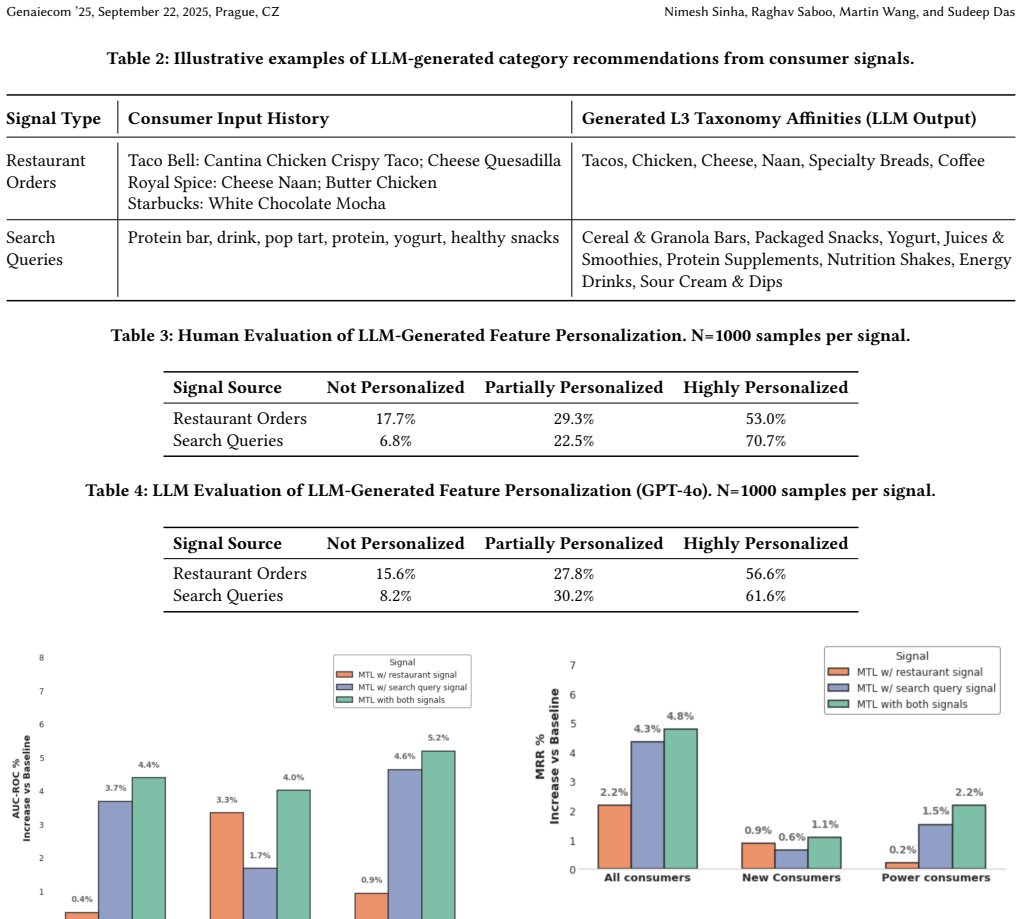
In multi-vertical e-commerce platforms like DoorDash, relatively newer product verticals such as grocery and retail present a significant opportunity for personalization innovation. A key challenge lies in solving the "cold start" problem for users. This paper introduces a novel framework for enhancing recommendation quality by transferring knowledge from data-rich verticals (e.g., restaurants at DoorDash) to data-sparse ones. We leverage Large Language Models (LLMs) to perform generative inference, synthesizing sparse, high-dimensional features that encapsulate latent user affinities. Specifically, we employ a hierarchical Retrieval-Augmented Generation (RAG) pipeline to derive multi-level taxonomic features from user restaurant order histories and search queries. These generated features, encoding both long-term cross-vertical preferences and short-term intent, are integrated into a production Multi-Task Learning (MTL) ranking model. We demonstrate through extensive offline and online evaluation that this approach significantly improves personalization and engagement in emerging business verticals, effectively bridging the behavioral data gap.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a framework for multi-vertical recommendation at platforms like DoorDash that uses LLMs to run a hierarchical RAG pipeline over restaurant order histories and search queries. The resulting multi-level taxonomic features, intended to capture long-term cross-vertical preferences and short-term intent, are injected into a production Multi-Task Learning (MTL) ranking model to improve personalization and engagement in data-sparse verticals such as grocery and retail. The central claim is that this transfer-learning approach measurably bridges the behavioral data gap, as demonstrated by extensive offline and online evaluations.
Significance. If the claimed gains are reproducible and statistically robust, the work would offer a practical route to cold-start mitigation in multi-vertical e-commerce by synthesizing transferable user-affinity signals from a data-rich vertical. The use of generative LLM features inside an MTL production model is a concrete engineering contribution that could be adopted by other platforms facing similar vertical imbalances.
major comments (2)
- [Abstract] Abstract: the assertion that 'extensive offline and online evaluation' demonstrates 'significant improvements' is load-bearing for the central claim, yet the abstract supplies no numerical metrics, baselines, effect sizes, statistical tests, or even the identity of the MTL model. Without these details the claim cannot be evaluated.
- [Abstract / Method description] The hierarchical RAG pipeline is described only at the level of 'multi-level taxonomic features'; no concrete taxonomy, retrieval corpus, prompt templates, or feature dimensionality is provided, preventing assessment of whether the generated features actually encode cross-vertical affinities rather than domain-specific noise.
minor comments (1)
- [Abstract] The phrase 'emerging business verticals' is used without defining which verticals are considered emerging versus mature.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will incorporate revisions to improve clarity and evaluability of the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that 'extensive offline and online evaluation' demonstrates 'significant improvements' is load-bearing for the central claim, yet the abstract supplies no numerical metrics, baselines, effect sizes, statistical tests, or even the identity of the MTL model. Without these details the claim cannot be evaluated.
Authors: We agree that the abstract would benefit from concrete quantitative support. In the revised version, we will expand the abstract to report key metrics (e.g., relative AUC lift and engagement improvements from offline experiments), the baseline (standard MTL ranking model without LLM features), effect sizes, and confirmation that online A/B tests showed statistically significant gains. The MTL model identity (the production multi-task learning ranker deployed at DoorDash) will also be stated explicitly. revision: yes
-
Referee: [Abstract / Method description] The hierarchical RAG pipeline is described only at the level of 'multi-level taxonomic features'; no concrete taxonomy, retrieval corpus, prompt templates, or feature dimensionality is provided, preventing assessment of whether the generated features actually encode cross-vertical affinities rather than domain-specific noise.
Authors: The full manuscript details the hierarchical RAG pipeline, taxonomy (multi-level categories derived from restaurant orders such as cuisine type and dietary tags), retrieval corpus (user restaurant histories and queries), and prompt structure in the Methods section. To address the concern directly, we will add a short paragraph summarizing the taxonomy levels, corpus construction, and resulting feature dimensionality to the abstract and introduction. This will better illustrate how the features transfer cross-vertical signals rather than domain-specific noise. revision: partial
Circularity Check
No significant circularity detected
full rationale
The manuscript describes an applied empirical system: LLM-based hierarchical RAG generates features from restaurant histories, which are then fed into an MTL ranking model whose performance is measured by offline and online metrics. No equations, derivations, fitted-parameter predictions, or self-citation chains appear in the text. The central claim rests on external evaluation results rather than any internal reduction of outputs to inputs by construction. This is a standard engineering paper whose validity is testable against held-out data and live traffic.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Olivier Chapelle, Pannagadatta Shivaswamy, Srinivas Vadrevu, Kilian Weinberger, Ya Zhang, and Belle Tseng. 2010. Multi-task Learning for Boosting with Applica- tion to Web Search Ranking. InProceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 1189–1198
2010
-
[2]
Harrison, Anton Dereventsov, and Anton Bibin
Rachel M. Harrison, Anton Dereventsov, and Anton Bibin. 2023. Zero-shot Rec- ommendations with Pre-trained Large Language Models for Multimodal Nudging. In2023 IEEE International Conference on Data Mining Workshops (ICDMW). IEEE, 1535–1542
2023
-
[3]
Feiran Huang, Yuanchen Bei, Zhenghang Yang, Junyi Jiang, Hao Chen, Qijie Shen, Senzhang Wang, Fakhri Karray, and Philip S. Yu. 2025. Large Language Model Simulator for Cold-Start Recommendation. InProceedings of the 18th ACM International Conference on Web Search and Data Mining (WSDM 2025). doi:10.48550/arXiv.2402.09176 arXiv:2402.09176, accepted by WSDM 2025
- [4]
-
[5]
Jui-Ting Huang, Ashish Sharma, Shuying Sun, Li Xia, David Zhang, Philip Pronin, Janani Padmanabhan, Giuseppe Ottaviano, and Linjun Yang. 2020. Embedding- based Retrieval in Facebook Search. InProceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2553–2561
2020
-
[6]
Jiaqi Ma, Zhe Zhao, Xinyang Yi, Jilin Chen, Lichan Hong, and Ed H. Chi. 2018. Modeling Task Relationships in Multi-Task Learning with Multi-Gate Mixture- of-Experts. InProceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 1930–1939
2018
-
[7]
Luyi Ma, Nimesh Sinha, Parth Vajge, Jason H. D. Cho, Sushant Kumar, and Kannan Achan. 2021. Event-based Product Carousel Recommendation with Query-Click Graph. In2021 IEEE International Conference on Big Data (Big Data). 1–7. doi:10.48550/arXiv.2402.03277 arXiv:2402.03277
-
[8]
Xiao Ma, Liqin Zhao, Guan Huang, Zhi Wang, Zelin Hu, Xiaoqiang Zhu, and Kun Gai. 2018. Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate. InProceedings of the 41st International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2018). doi:10.48550/arXiv.1804.07931 arXiv:1804.07931...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1804.07931 2018
-
[9]
Nimesh Sinha. 2020. SPIR: Some Practical Item-based Recommendations. In Proceedings of the Industry-Related Symposium (IRS 2020). https://irsworkshop. github.io/2020/publications/paper_13_%20Sinha_SPIR.pdf
2020
- [10]
- [11]
-
[12]
Shu Wang, Yixiang Fang, Yingli Zhou, Xilin Liu, and Yuchi Ma. 2025. ArchRAG: Attributed Community-based Hierarchical Retrieval-Augmented Generation. arXiv preprint arXiv:2502.09891(2025). doi:10.48550/arXiv.2502.09891
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.09891 2025
-
[13]
Wei Wei, Xubin Ren, Jiabin Tang, Qinyong Wang, Lixin Su, Suqi Cheng, Junfeng Wang, Dawei Yin, and Chao Huang. 2024. Llmrec: Large Language Models with Graph Augmentation for Recommendation. InProceedings of the 17th ACM International Conference on Web Search and Data Mining (WSDM 2024). 806–815
2024
-
[14]
Likang Wu, Zhi Zheng, Zhaopeng Qiu, Hao Wang, Hongchao Gu, Tingjia Shen, Chuan Qin, Chen Zhu, Hengshu Zhu, Qi Liu, et al . 2024. A Survey on Large Language Models for Recommendation.World Wide Web27, 5 (2024), 60
2024
-
[15]
Zihuai Zhao, Wenqi Fan, Jiatong Li, Yunqing Liu, Xiaowei Mei, Yiqi Wang, Zhen Wen, Fei Wang, Xiangyu Zhao, Jiliang Tang, et al. 2024. Recommender Systems in the Era of Large Language Models (LLMs).IEEE Transactions on Knowledge and Data Engineering(2024). to appear
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.