Seeing Before Colliding: Anticipatory Safe RL with Frozen Vision-Language Models
Pith reviewed 2026-06-27 14:04 UTC · model grok-4.3
The pith
A frozen vision-language model supplies anticipatory cost signals that let constrained RL avoid collisions before they start in high-speed tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
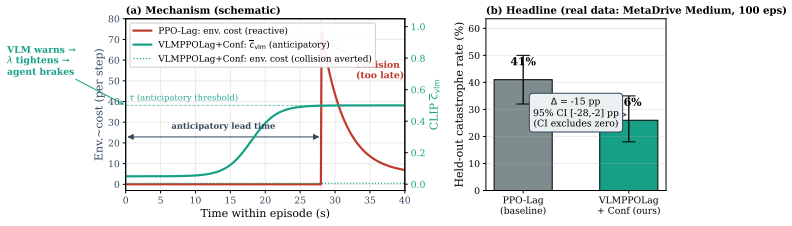
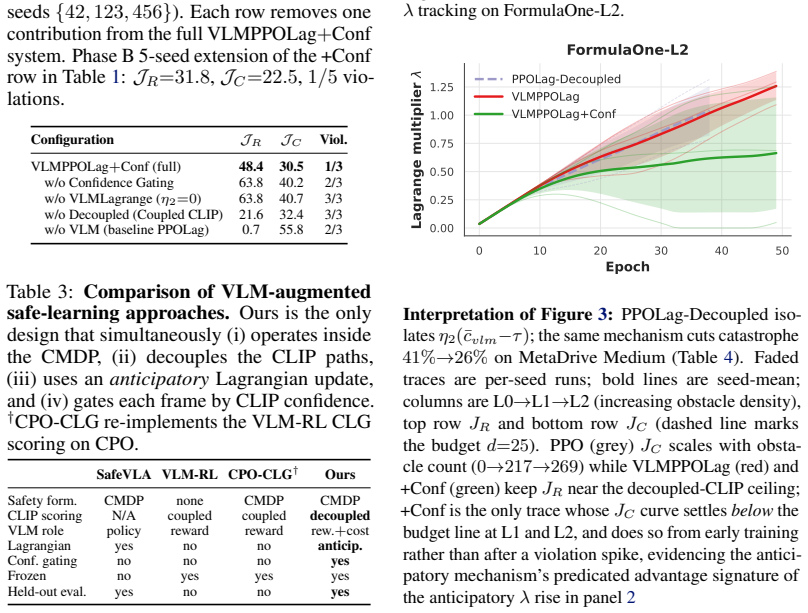
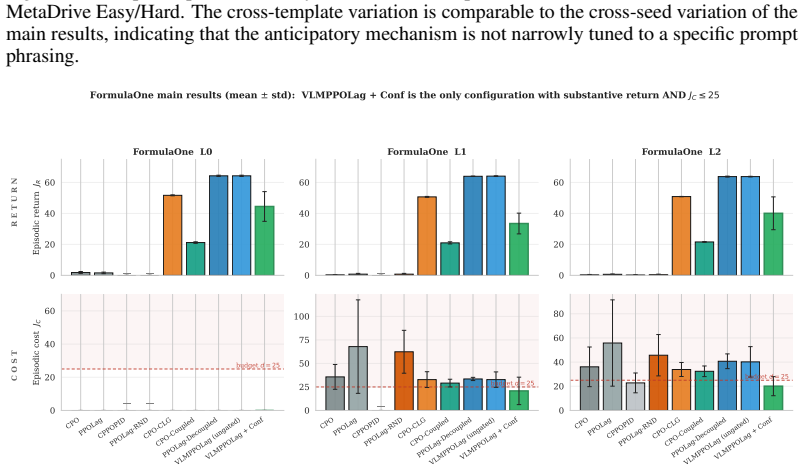
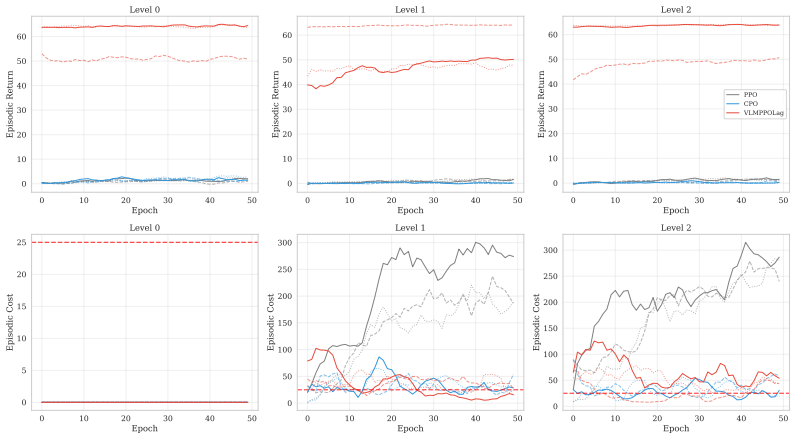
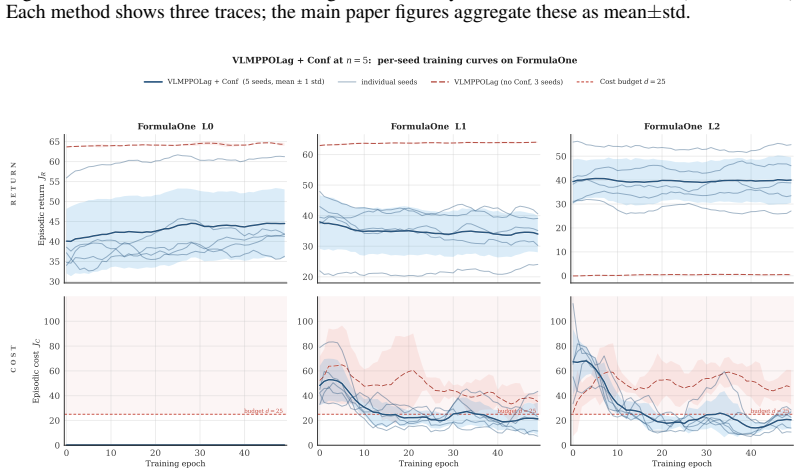
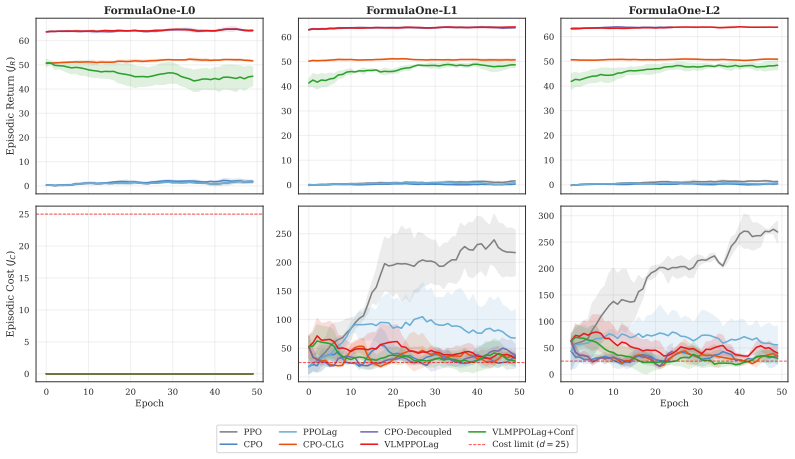
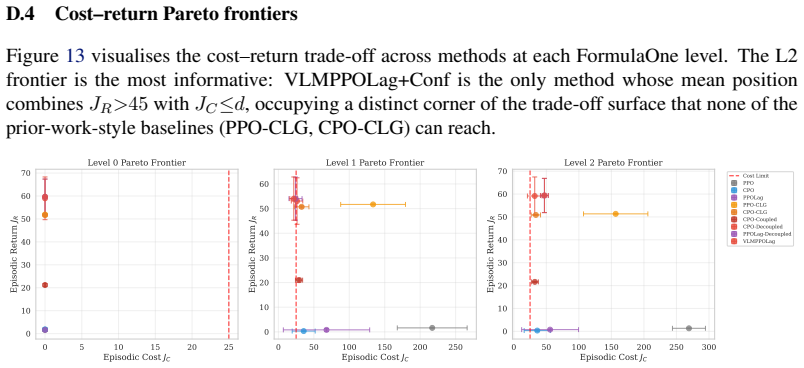
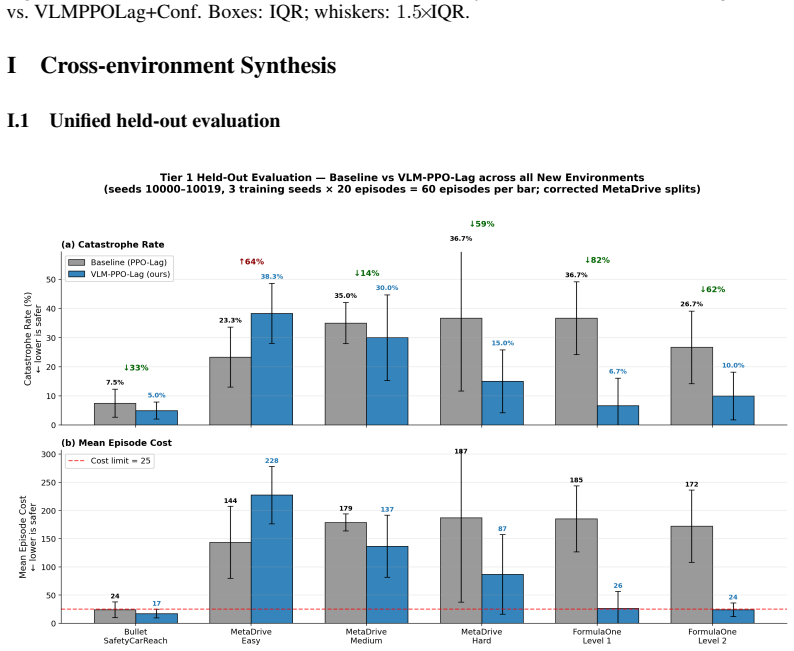
The paper establishes that a frozen VLM can be integrated as an anticipatory cost term inside the CMDP Lagrangian update through the VLM-Lagrange mechanism together with confidence gating, producing the VLMPPOLag+Conf algorithm that simultaneously retains substantive return (Jr≈40) and holds cost within budget on a majority of seeds in Safety-Gymnasium FormulaOne L2, where five constraint-aware baselines each fail at least one requirement.
What carries the argument
VLM-Lagrange, the augmented multiplier update that adds a per-step VLM cost as an anticipatory term, together with Decoupled Dual-Path CLIP and Confidence Gating derived from a logistic noise model on the CLIP margin.
If this is right
- Only the VLM-augmented method satisfies both return and cost criteria simultaneously on the main racing benchmark.
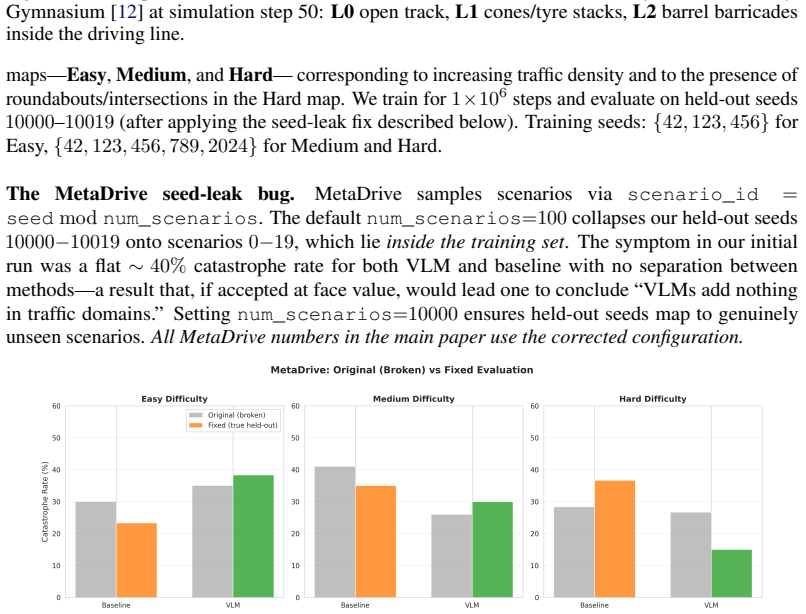
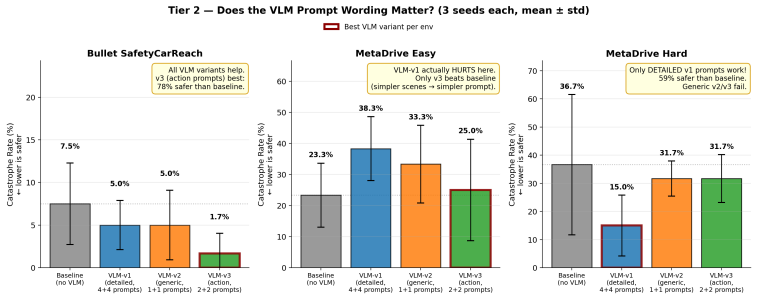
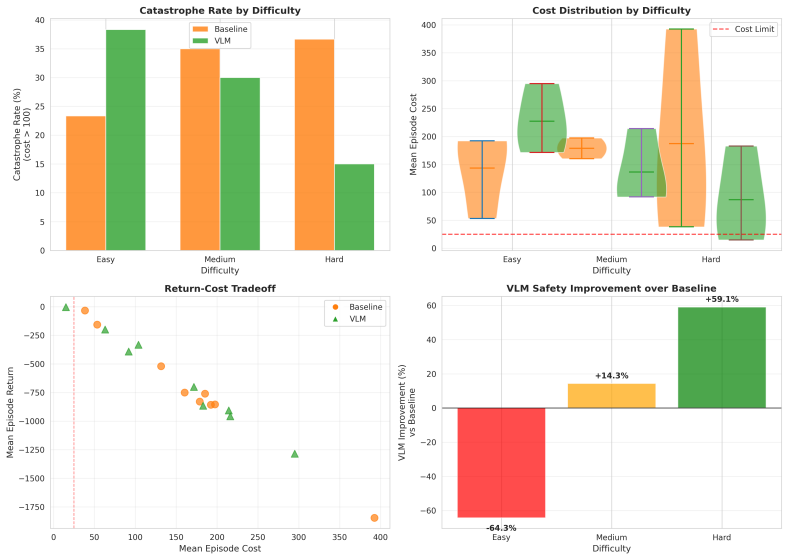
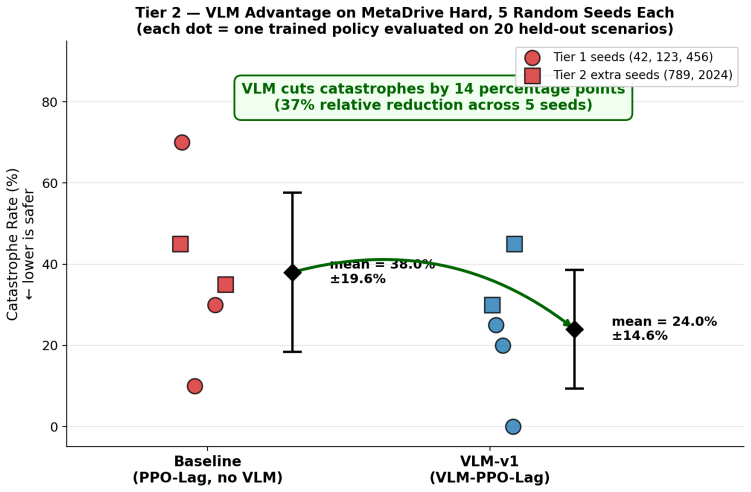
- The approach reduces catastrophe rate from 41% to 26% on held-out MetaDrive Medium.
- Directionally consistent safety gains appear when transferred to Bullet Safety-Gym.
- Observed failures on certain MetaDrive difficulties trace to Lagrangian regulation pathology rather than the VLM cost signal itself.
Where Pith is reading between the lines
- Anticipatory VLM signals could be paired with other sensor modalities to improve cost prediction without retraining the language model.
- The confidence-gating construction offers a template for incorporating any noisy external predictor into constrained optimization loops.
- Because the VLM remains frozen, the method may transfer to physical robots whose visual input differs from simulation without additional VLM fine-tuning.
Load-bearing premise
The frozen VLM produces per-step cost signals that are sufficiently accurate and low-noise to serve as a useful anticipatory term inside the Lagrangian multiplier update without requiring fine-tuning or introducing systematic bias that the confidence gate cannot correct.
What would settle it
Re-running VLMPPOLag+Conf on Safety-Gymnasium FormulaOne L2 under the stated protocol and observing that it fails to retain Jr≈40 while holding cost within budget on a majority of the five seeds would falsify the central performance claim.
Figures


read the original abstract
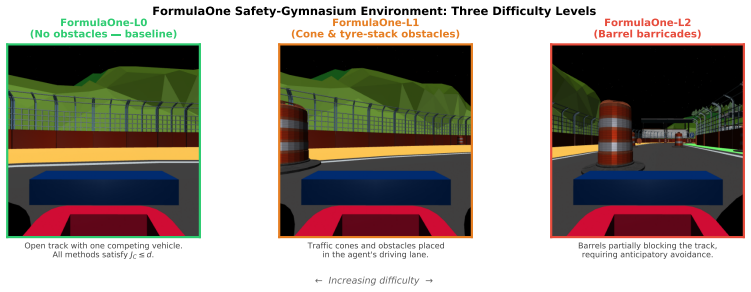
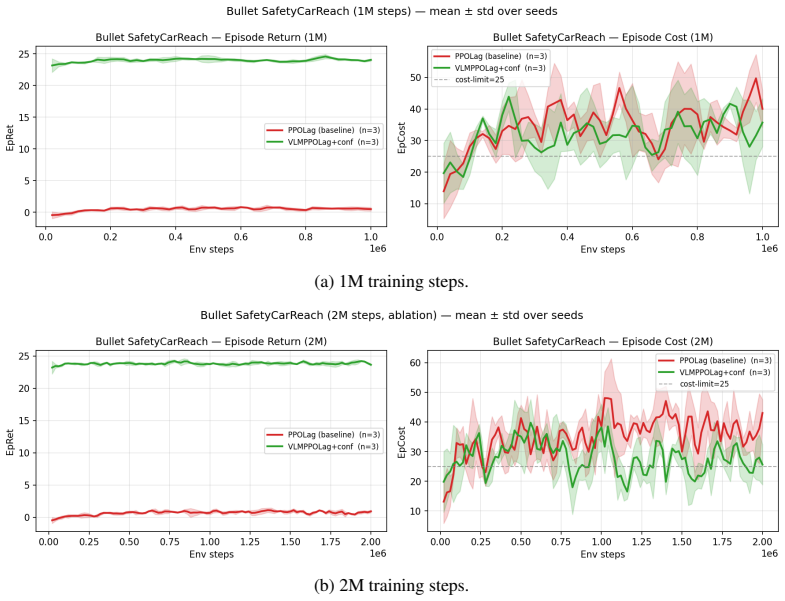
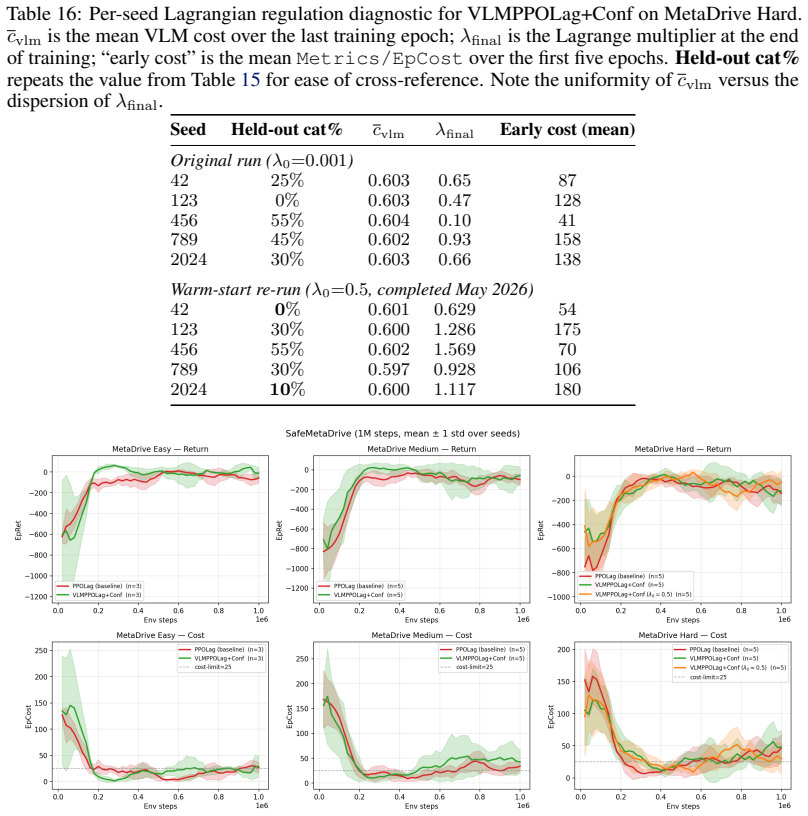
The cost signal that constrained-RL algorithms optimize against is almost always reactive: the simulator emits a non-zero cost only after a collision has begun, and the Lagrange multiplier of PPO-Lagrangian grows only after the episode budget has been exceeded. At race speeds, where collisions are instantaneous and irreversible, any safety mechanism that waits for cost to accumulate is structurally too late. We present VLM-Safe-RL, a framework that integrates a frozen vision-language model into the CMDP Lagrangian update as an anticipatory cost term. The framework comprises four contributions: (i) Decoupled Dual-Path CLIP, independent reward/cost paths that respect the CMDP's factorization; (ii) VLM-Lagrange, an augmented multiplier update that incorporates a per-step VLM cost as an anticipatory term; (iii) Confidence Gating, a Bayes-optimal weight derived from a logistic noise model on the CLIP margin; and (iv) VLMPPOLag, the composed algorithm. On Safety-Gymnasium FormulaOne L2, our principal evaluation ($n{=}5$ seeds, $10^{6}$ steps, budget $d_{\text{lim}}{=}25$) VLMPPOLag$+$Conf is the only configuration in our default budget comparison that simultaneously retains substantive return ($J_r{\approx}40$) and holds cost within budget on a majority of seeds; the five constraint-aware baselines (PPOLag, CPO, CPPOPID, CPO-CLG, PPOLag-RND) each fail at least one requirement. The mechanism generalizes to held-out MetaDrive Medium (catastrophe rate $41\%{\to}26\%$, 95\% bootstrap CI $[-26,-5]$\,pp) and shows directionally consistent transfer to Bullet Safety-Gym; we report honestly where it does not (MetaDrive Easy/Hard, Qwen2-VL backbone) and trace the Hard failure to a Lagrangian-regulation pathology rather than the VLM signal itself. To our knowledge, this is the first work to use frozen VLM signals as an anticipatory cost term inside the CMDP Lagrangian update.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes VLM-Safe-RL, a framework that augments constrained RL (specifically PPO-Lagrangian) with a frozen vision-language model to provide anticipatory per-step cost signals inside the CMDP Lagrangian multiplier update. Key components are Decoupled Dual-Path CLIP (separate reward/cost paths), VLM-Lagrange (augmented multiplier update), a Bayes-optimal Confidence Gate derived from a logistic noise model on the CLIP margin, and the composed VLMPPOLag+Conf algorithm. On the principal benchmark (Safety-Gymnasium FormulaOne L2, n=5 seeds, 10^6 steps, d_lim=25), VLMPPOLag+Conf is reported as the only method that simultaneously achieves substantive return (Jr≈40) and stays within cost budget on a majority of seeds, while five baselines fail at least one criterion; directional transfer is shown on MetaDrive Medium and Bullet Safety-Gym with honest reporting of failures on other settings.
Significance. If the VLM-derived anticipatory costs prove reliable, the approach offers a practical route to proactive safety in high-speed continuous-control tasks where reactive simulator costs arrive too late. Strengths include the use of an external frozen VLM (no fine-tuning required), explicit factorization respecting CMDP structure, multiple baseline comparisons with 5 seeds, bootstrap CIs on transfer results, and transparent reporting of negative results (e.g., MetaDrive Easy/Hard, Qwen2-VL). These elements make the empirical claims more falsifiable than typical safe-RL papers that rely solely on end-to-end success.
major comments (2)
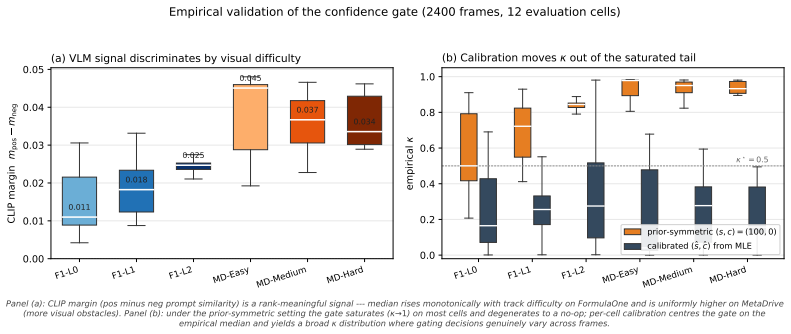
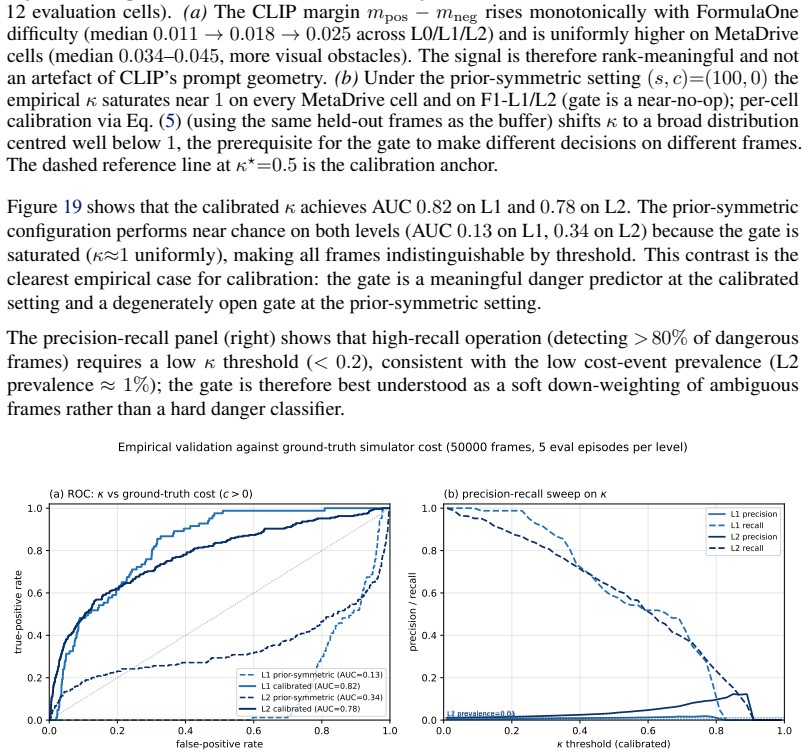
- [Evaluation / principal benchmark results] The headline claim on FormulaOne L2 (that VLMPPOLag+Conf is the sole method satisfying both return and cost-budget criteria) is load-bearing on the assumption that the frozen VLM produces per-step costs that are genuinely anticipatory and low-bias. No separate calibration or validation is provided that measures VLM margin against ground-truth future collision events (e.g., collision within the next 5–10 simulator steps) on the same trajectories, independent of the full RL training loop. Without this, end-to-end improvement cannot isolate the contribution of the anticipatory term from other algorithmic changes (Lagrange augmentation, gating).
- [Method / Confidence Gating] The logistic noise model used to derive the Bayes-optimal weight for the confidence gate (contribution iii) is presented as producing the gating weight, yet the manuscript does not report an ablation that removes the VLM cost entirely while retaining the gate structure, nor does it show that the gate actually corrects systematic bias in the VLM signal rather than acting as a generic regularizer.
minor comments (2)
- [Method] Notation for the VLM cost term and its integration into the multiplier update should be made fully explicit with an equation number in the main text rather than only in the appendix.
- [Evaluation] The bootstrap CI reported for MetaDrive Medium transfer is useful; the same style of uncertainty quantification should be added for the FormulaOne L2 seed-level results.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and for highlighting both the potential of the approach and areas for strengthening the empirical claims. We respond to each major comment below and commit to revisions that address the concerns raised.
read point-by-point responses
-
Referee: [Evaluation / principal benchmark results] The headline claim on FormulaOne L2 (that VLMPPOLag+Conf is the sole method satisfying both return and cost-budget criteria) is load-bearing on the assumption that the frozen VLM produces per-step costs that are genuinely anticipatory and low-bias. No separate calibration or validation is provided that measures VLM margin against ground-truth future collision events (e.g., collision within the next 5–10 simulator steps) on the same trajectories, independent of the full RL training loop. Without this, end-to-end improvement cannot isolate the contribution of the anticipatory term from other algorithmic changes (Lagrange augmentation, gating).
Authors: We agree that an independent calibration of the VLM signal would better isolate its anticipatory contribution. In the revised manuscript, we will add a new experiment section that evaluates the VLM margin on held-out trajectories collected from a converged policy. We will report the correlation between the VLM cost signal and actual future collisions (within 5-10 steps) using metrics such as precision-recall or AUC, separate from the RL training. This addresses the concern about isolating the VLM's role. revision: yes
-
Referee: [Method / Confidence Gating] The logistic noise model used to derive the Bayes-optimal weight for the confidence gate (contribution iii) is presented as producing the gating weight, yet the manuscript does not report an ablation that removes the VLM cost entirely while retaining the gate structure, nor does it show that the gate actually corrects systematic bias in the VLM signal rather than acting as a generic regularizer.
Authors: We will incorporate the suggested ablation in the revised version. Specifically, we will compare the full model against a variant where the VLM cost is set to zero (or replaced with a non-informative signal) but the gating weight is still computed (perhaps from a fixed distribution or zero margin). This will demonstrate whether the gate provides benefit beyond a generic regularizer. Additionally, we will include analysis showing the gate's effect on reducing variance or bias in the cost estimates. revision: yes
Circularity Check
No circularity; empirical results use external frozen VLM with direct benchmark comparisons
full rationale
The paper's core contribution is an empirical framework (VLM-Safe-RL) that augments CMDP Lagrangian updates with per-step signals from a frozen external VLM. Principal claims rest on reported performance metrics (return, cost within budget) across Safety-Gymnasium FormulaOne L2, MetaDrive, and Bullet Safety-Gym, with explicit seed counts, bootstrap CIs, and comparisons to five independent baselines. No equations, derivations, or fitted parameters are presented that reduce the claimed improvements to quantities defined by construction from the inputs. The VLM is treated as an off-the-shelf black-box source; no self-citation chain or ansatz is invoked to justify uniqueness or force the outcome. The method is self-contained against external benchmarks and does not rename known results or smuggle assumptions via prior author work.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A frozen VLM can extract per-step visual features that correlate with future collision risk without task-specific fine-tuning
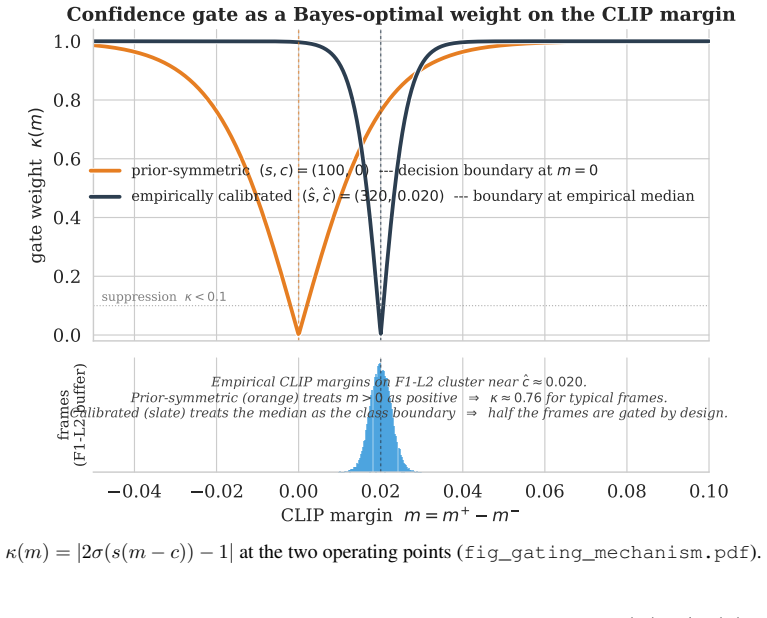
- ad hoc to paper The logistic noise model on the CLIP margin produces a Bayes-optimal weight for gating the VLM cost
Reference graph
Works this paper leans on
-
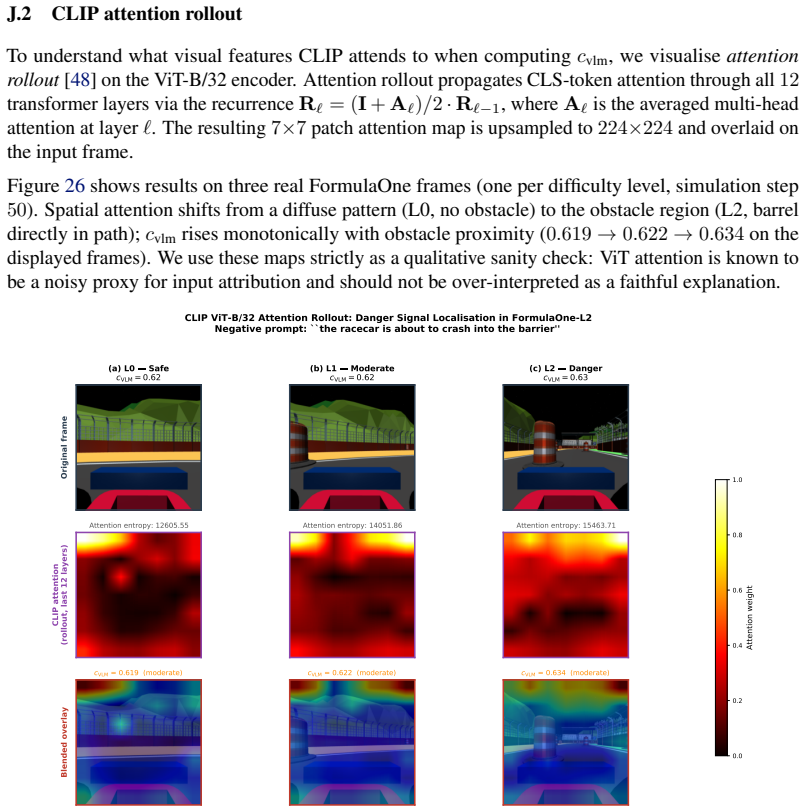
[1]
Altman.Constrained Markov Decision Processes
E. Altman.Constrained Markov Decision Processes. CRC Press, 1999
1999
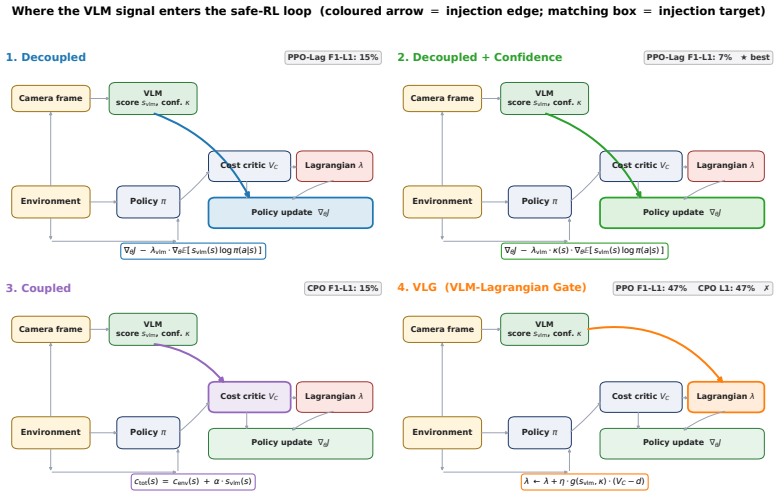
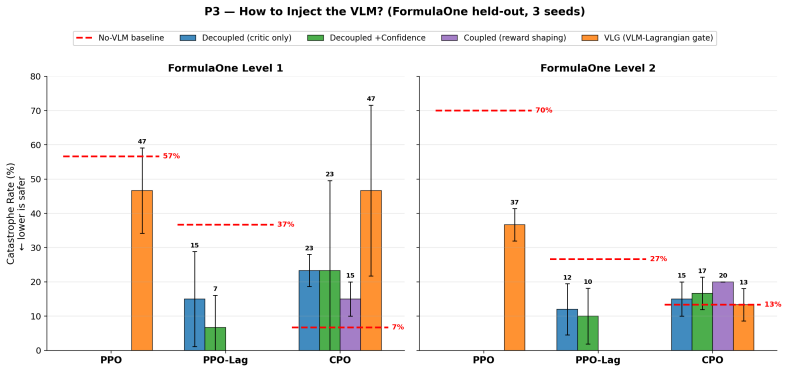
-
[2]
Stooke, J
A. Stooke, J. Achiam, and P. Abbeel. Responsive safety in reinforcement learning by PID Lagrangian methods. InInternational Conference on Machine Learning (ICML), 2020
2020
-
[3]
Radford, J
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever. Learning transferable visual models from natural language supervision. InInternational Conference on Machine Learning (ICML), 2021
2021
-
[4]
Brohan, N
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, X. Chen, K. Choromanski, T. Ding, D. Driess, A. Dubey, C. Finn, et al. RT-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning (CoRL), 2023
2023
-
[5]
Driess, F
D. Driess, F. Xia, M. S. M. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu, et al. PaLM-E: An embodied multimodal language model. InInternational Conference on Machine Learning (ICML), 2023
2023
-
[6]
B. Zhang, Y . Zhang, J. Ji, Y . Lei, J. Dai, Y . Chen, and Y . Yang. SafeVLA: Towards safety alignment of vision-language-action models via constrained learning.arXiv preprint arXiv:2503.03480, 2025
Pith/arXiv arXiv 2025
-
[7]
L. Fan, G. Wang, Y . Jiang, A. Mandlekar, Y . Yang, H. Zhu, A. Tang, D.-A. Huang, Y . Zhu, and A. Anandkumar. MineDojo: Building open-ended embodied agents with internet-scale knowledge. InAdvances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks, 2022
2022
-
[8]
M. Kwon, S. M. Xie, K. Bullard, and D. Sadigh. Reward design with language models. In International Conference on Learning Representations (ICLR), 2023
2023
-
[9]
Rocamonde, V
J. Rocamonde, V . Montesinos, E. Nava, E. Perez, and D. Lindner. Vision-language models are zero-shot reward models for reinforcement learning. InInternational Conference on Learning Representations (ICLR), 2024
2024
- [10]
-
[11]
J. Ji, J. Zhou, B. Zhang, J. Dai, X. Pan, R. Sun, W. Huang, Y . Geng, M. Liu, and Y . Yang. OmniSafe: An infrastructure for accelerating safe reinforcement learning research.arXiv preprint arXiv:2305.09304, 2023
arXiv 2023
-
[12]
J. Ji, B. Zhang, J. Zhou, X. Pan, W. Huang, R. Sun, Y . Geng, Y . Zhong, J. Dai, and Y . Yang. Safety Gymnasium: A unified safe reinforcement learning benchmark. InAdvances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks, 2023
2023
-
[13]
Q. Li, Z. Peng, L. Feng, Q. Zhang, Z. Xue, and B. Zhou. MetaDrive: Composing diverse driving scenarios for generalizable reinforcement learning.IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 45(3):3461–3475, 2023
2023
-
[14]
M. Ahn, A. Brohan, N. Brown, Y . Chebotar, O. Cortes, B. David, C. Finn, C. Fu, K. Gopalakr- ishnan, K. Hausman, A. Herzog, D. Ho, et al. Do as i can, not as i say: Grounding language in robotic affordances. InConference on Robot Learning (CoRL), 2022
2022
-
[15]
Huang, C
W. Huang, C. Wang, R. Zhang, Y . Li, J. Wu, and L. Fei-Fei. V oxPoser: Composable 3D value maps for robotic manipulation with language models. InConference on Robot Learning (CoRL), 2023. 9
2023
-
[16]
H. Liu, C. Li, Q. Wu, and Y . J. Lee. Visual instruction tuning. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[17]
P. Wang, S. Bai, S. Tan, S. Wang, Z. Fan, J. Bai, K. Chen, X. Liu, J. Wang, W. Ge, Y . Fan, K. Dang, M. Du, X. Ren, R. Men, D. Liu, C. Zhou, J. Zhou, and J. Lin. Qwen2-VL: En- hancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
Pith/arXiv arXiv 2024
-
[18]
A. Y . Ng, D. Harada, and S. Russell. Policy invariance under reward transformations: Theory and application to reward shaping. InInternational Conference on Machine Learning (ICML), 1999
1999
-
[19]
T. Xie, S. Zhao, C. H. Wu, Y . Liu, Q. Luo, V . Zhong, Y . Yang, and T. Yu. Text2Reward: Reward shaping with language models for reinforcement learning. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[20]
Y . J. Ma, W. Liang, G. Wang, D.-A. Huang, O. Bastani, D. Jayaraman, Y . Zhu, L. Fan, and A. Anandkumar. Eureka: Human-level reward design via coding large language models. In International Conference on Learning Representations (ICLR), 2024
2024
-
[21]
Haarnoja, A
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. InInternational Conference on Machine Learning (ICML), 2018
2018
-
[22]
D. Amodei, C. Olah, J. Steinhardt, P. Christiano, J. Schulman, and D. Mané. Concrete problems in AI safety.arXiv preprint arXiv:1606.06565, 2016
Pith/arXiv arXiv 2016
-
[23]
S. Shalev-Shwartz, S. Shammah, and A. Shashua. Safe, multi-agent, reinforcement learning for autonomous driving.arXiv preprint arXiv:1610.03295, 2016
Pith/arXiv arXiv 2016
-
[24]
García and F
J. García and F. Fernández. A comprehensive survey on safe reinforcement learning.Journal of Machine Learning Research, 16(1):1437–1480, 2015
2015
-
[25]
Brunke, M
L. Brunke, M. Greeff, A. W. Hall, Z. Yuan, S. Zhou, J. Panerati, and A. P. Schoellig. Safe learning in robotics: From learning-based control to safe reinforcement learning.Annual Review of Control, Robotics, and Autonomous Systems, 5:411–444, 2022
2022
-
[26]
Achiam, D
J. Achiam, D. Held, A. Tamar, and P. Abbeel. Constrained policy optimization. InInternational Conference on Machine Learning (ICML), 2017
2017
-
[27]
Zhang, Q
Y . Zhang, Q. Vuong, and K. W. Ross. FOCOPS: First order constrained optimization in policy space. InAdvances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[28]
T.-Y . Yang, J. Rosca, K. Narasimhan, and P. J. Ramadge. Projection-based constrained policy optimization. InInternational Conference on Learning Representations (ICLR), 2020
2020
-
[29]
L. Yang, J. Ji, J. Dai, L. Zhang, B. Zhou, P. Li, Y . Yang, and G. Pan. Constrained update projection approach to safe policy optimization. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[30]
Todorov, T
E. Todorov, T. Erez, and Y . Tassa. MuJoCo: A physics engine for model-based control. In 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 5026–5033. IEEE, 2012
2012
-
[31]
T. Xu, Y . Liang, and G. Lan. Crpo: A new approach for safe reinforcement learning with convergence guarantee. InInternational Conference on Machine Learning (ICML), 2021
2021
-
[32]
Sootla, A
A. Sootla, A. I. Cowen-Rivers, T. Jafferjee, Z. Wang, D. H. Mguni, J. Wang, and H. Ammar. Sauté RL: Almost surely safe reinforcement learning using state augmentation. InInternational Conference on Machine Learning (ICML), 2022. 10
2022
-
[33]
Henderson, R
P. Henderson, R. Islam, P. Bachman, J. Pineau, D. Precup, and D. Meger. Deep reinforcement learning that matters.AAAI Conference on Artificial Intelligence, 2018
2018
-
[34]
Agarwal, M
R. Agarwal, M. Schwarzer, P. S. Castro, A. Courville, and M. G. Bellemare. Deep reinforcement learning at the edge of the statistical precipice. InAdvances in Neural Information Processing Systems (NeurIPS), 2021
2021
-
[35]
J. Chen and R. Chandra. Dynamic control barrier function regulation with vision-language models for safe, adaptive, and realtime visual navigation.arXiv preprint arXiv:2603.21142, 2026
arXiv 2026
-
[36]
Jeong, Y
J. Jeong, Y . Zou, T. Kim, D. Zhang, A. Ravichandran, and O. Dabeer. WinCLIP: Zero-/few-shot anomaly classification and segmentation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[37]
K. P. Murphy.Machine Learning: A Probabilistic Perspective. MIT Press, 2012
2012
- [38]
-
[39]
Dosovitskiy, L
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations (ICLR), 2021
2021
-
[40]
J. Platt. Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods. InAdvances in Large Margin Classifiers, volume 10, pages 61–74. MIT Press, 1999
1999
-
[41]
C. Guo, G. Pleiss, Y . Sun, and K. Q. Weinberger. On calibration of modern neural networks. InProceedings of the 34th International Conference on Machine Learning (ICML), pages 1321–1330, 2017
2017
-
[42]
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[43]
Efron and R
B. Efron and R. Tibshirani. Bootstrap methods for standard errors, confidence intervals, and other measures of statistical accuracy.Statistical Science, 1:54–75, 1986
1986
-
[44]
Gronauer
S. Gronauer. Bullet-safety-gym: A framework for constrained reinforcement learning. Technical report, Technical University of Munich, 2022. URL https://github.com/ SvenGronauer/Bullet-Safety-Gym
2022
-
[45]
Y . Burda, H. Edwards, A. Storkey, and O. Klimov. Exploration by random network distillation. arXiv preprint arXiv:1810.12894, 2018
Pith/arXiv arXiv 2018
-
[46]
Coumans and Y
E. Coumans and Y . Bai. PyBullet: A python module for physics simulation for games, robotics and machine learning. InGitHub repository, 2016.http://pybullet.org
2016
- [47]
-
[48]
Abnar and W
S. Abnar and W. Zuidema. Quantifying attention flow in transformers. InAnnual Meeting of the Association for Computational Linguistics (ACL), 2020
2020
-
[49]
H. Liu, C. Li, Y . Li, and Y . J. Lee. LLaV A-NeXT: Improved reasoning, OCR, and world knowledge.arXiv preprint arXiv:2408.03326, 2024
Pith/arXiv arXiv 2024
-
[50]
V . S. Borkar.Stochastic Approximation: A Dynamical Systems Viewpoint. Cambridge University Press, 2009
2009
-
[51]
Steps/sec
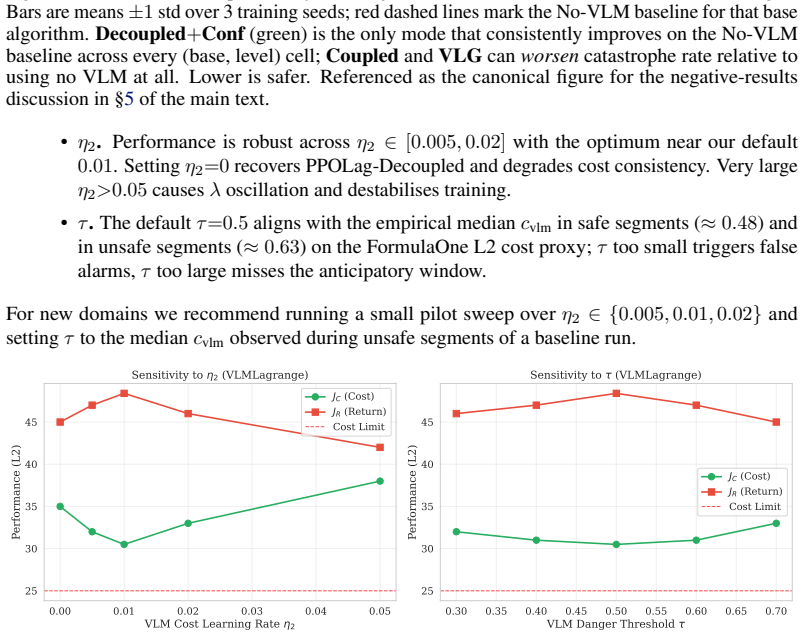
H. J. Kushner and G. G. Yin.Stochastic Approximation and Recursive Algorithms and Applica- tions. Springer, 2nd edition, 2003. 11 A Appendix A.1 Hyperparameters Table 5 provides a complete specification of the hyperparameters shared across all environments and methods. All algorithms use identical optimisation, PPO/CPO, and Lagrange settings; only the VLM...
2003
-
[52]
the racecar is centred on the track and driving safely
“the racecar is centred on the track and driving safely”
-
[53]
the racecar is following the racing line smoothly
“the racecar is following the racing line smoothly”
-
[54]
the racecar is making steady forward progress
“the racecar is making steady forward progress”
-
[55]
the car is driving efficiently without collisions
“the car is driving efficiently without collisions” 14 Negative prompts (L=4, cost shaping):
-
[56]
the racecar is about to crash into the barrier
“the racecar is about to crash into the barrier”
-
[57]
the racecar is off the track and unsafe
“the racecar is off the track and unsafe”
-
[58]
the car is colliding with an obstacle
“the car is colliding with an obstacle”
-
[59]
the car is driving in the wrong direction
“the car is driving in the wrong direction” C.2 Design principles We followed four principles in writing the prompts: • Action-oriented language.Prompts describebehaviours(“driving safely”, “about to crash”) rather than static states. This aligns the VLM signal with the CMDP objective of shaping action selection rather than scoring frames. • Semantic dive...
arXiv 2040
-
[60]
Decoupled (critic only).The VLM score cvlm is consumed only by an auxiliary cost critic VC; the policy update receives the standard environment cost
-
[61]
(4)), down-weighting frames the VLM is uncertain about
Decoupled + Confidence.As Decoupled, but the auxiliary contribution is gated by the per-frame confidenceκ(s)(Eq. (4)), down-weighting frames the VLM is uncertain about
-
[62]
cvlm is mixed into theenvironment costthat the critic regresses on, ctot(s)=cenv(s)+α cvlm(s); the policy then trades VLM and env signals through a single Lagrangian
Coupled (reward shaping). cvlm is mixed into theenvironment costthat the critic regresses on, ctot(s)=cenv(s)+α cvlm(s); the policy then trades VLM and env signals through a single Lagrangian
-
[63]
VLM-as-reward
VLG (VLM-Lagrangian Gate). cvlm enters via the Lagrange-multiplier update, λ←λ+ η g(cvlm, κ) (VC −d) , matching the Rocamonde-style “VLM-as-reward” usage from [ 9] but adapted to the constraint side. Each mode is paired with all three base safe-RL algorithms (PPO, PPO-Lag, CPO) on FormulaOne L1 and L2, evaluated on the held-out seeds 10000–10019 (20 deter...
-
[64]
κ Policy π Cost critic VC Lagrangian λ Policy update ∇θJ
Decoupled ∇θJ − λvlm ⋅ ∇θ[ svlm(s) log π(a|s) ] PPO-Lag F1-L1: 15% Environment Camera frame VLM score svlm, conf. κ Policy π Cost critic VC Lagrangian λ Policy update ∇θJ
-
[65]
κ Policy π Cost critic VC Lagrangian λ Policy update ∇θJ
Decoupled + Confidence ∇θJ − λvlm ⋅ κ(s) ⋅ ∇θ[ svlm(s) log π(a|s) ] PPO-Lag F1-L1: 7% ★ best Environment Camera frame VLM score svlm, conf. κ Policy π Cost critic VC Lagrangian λ Policy update ∇θJ
-
[66]
κ Policy π Cost critic VC Lagrangian λ Policy update ∇θJ
Coupled ctot(s) = cenv(s) + α ⋅ svlm(s) CPO F1-L1: 15% Environment Camera frame VLM score svlm, conf. κ Policy π Cost critic VC Lagrangian λ Policy update ∇θJ
-
[67]
VLG” (VLM-Lagrangian Gate) is distinct from “CLG
VLG (VLM-Lagrangian Gate) λ ← λ + η ⋅ g(svlm, κ) ⋅ (VC − d) PPO F1-L1: 47% CPO L1: 47% ✗ Where the VLM signal enters the safe-RL loop (coloured arrow = injection edge; matching box = injection target) Figure 14:Where the VLM signal enters the safe-RL loop.Four injection points evaluated in Section D.7; in each panel thecoloured arrowmarks the injection ed...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.