VoidPadding: Let [VOID] Handle Padding in Masked Diffusion Language Models so that [EOS] Can Focus on Semantic Termination
Pith reviewed 2026-06-27 00:40 UTC · model grok-4.3
The pith
VoidPadding introduces a dedicated [VOID] token for padding so [EOS] signals only semantic termination in masked diffusion language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
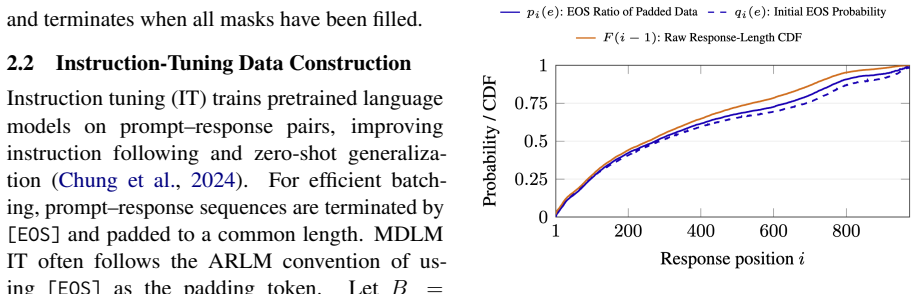
By training with [VOID] as the padding token instead of repeated [EOS], the model learns separate representations so that [EOS] can be used for reliable early stopping and [VOID] can guide adaptive expansion of the response canvas during inference.
What carries the argument
The [VOID] token, introduced for padding during instruction tuning, whose learned signal later controls adaptive canvas expansion while [EOS] controls early stopping.
If this is right
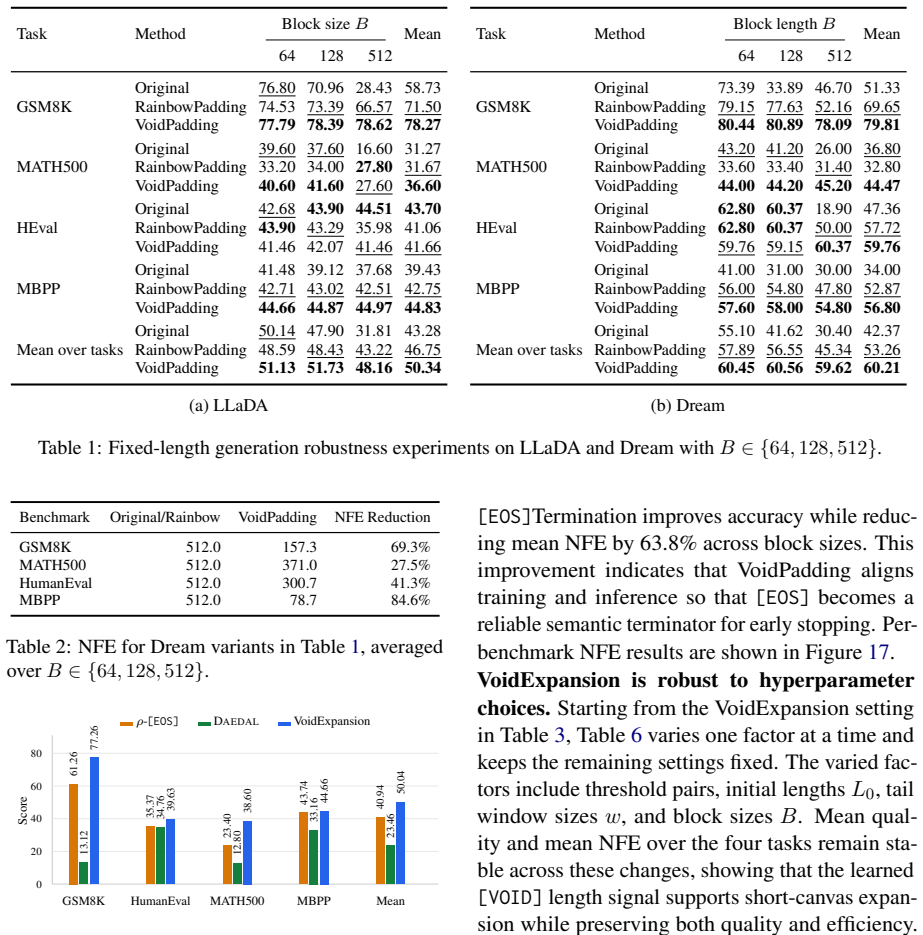
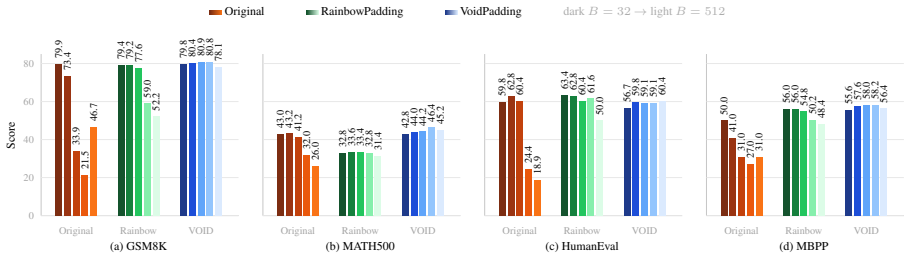
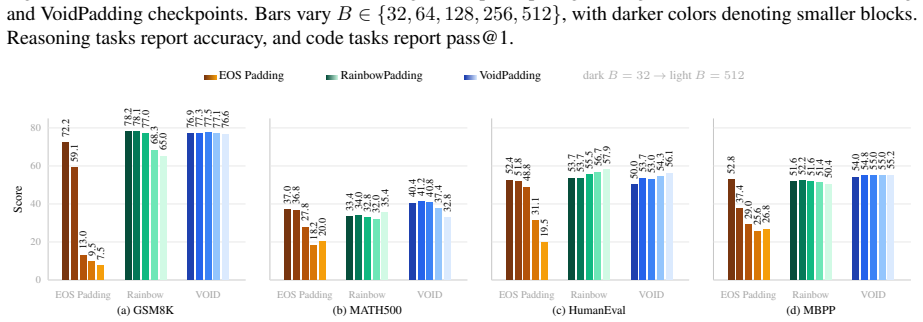
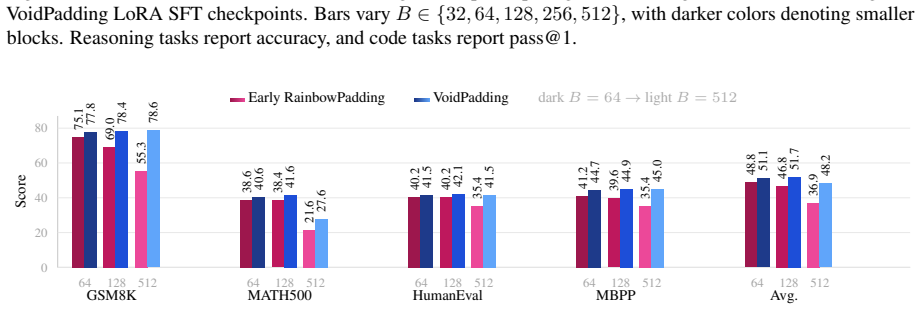
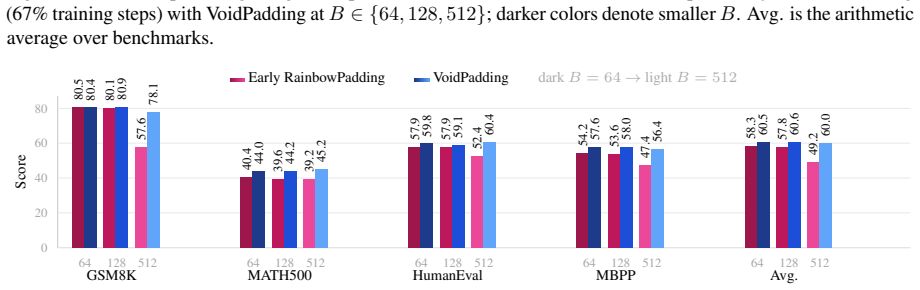
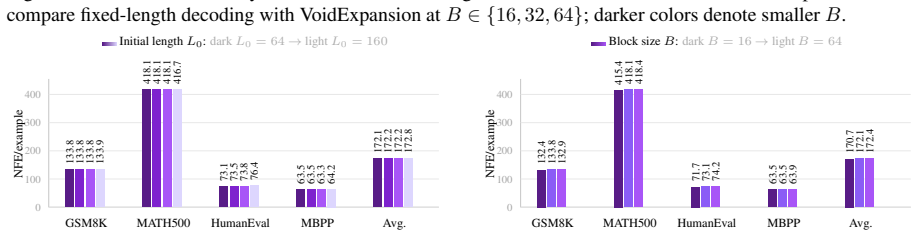
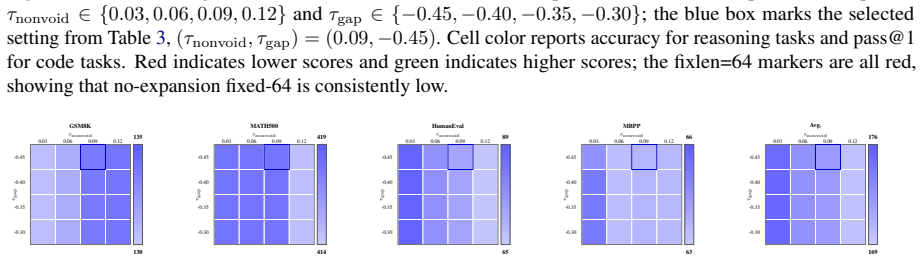
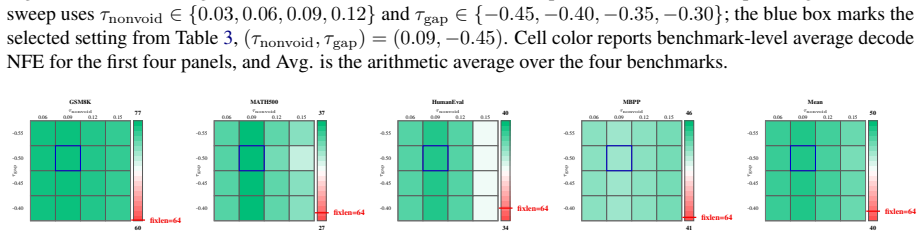
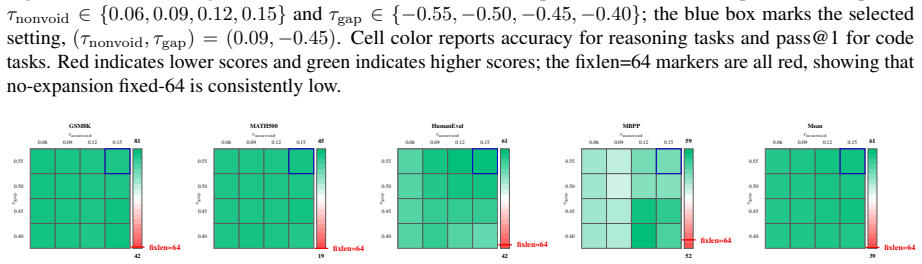
- Block-size-averaged performance across four math and code tasks rises by 17.84 points over the baseline model.
- The same tasks improve by 6.95 points over the prior RainbowPadding method.
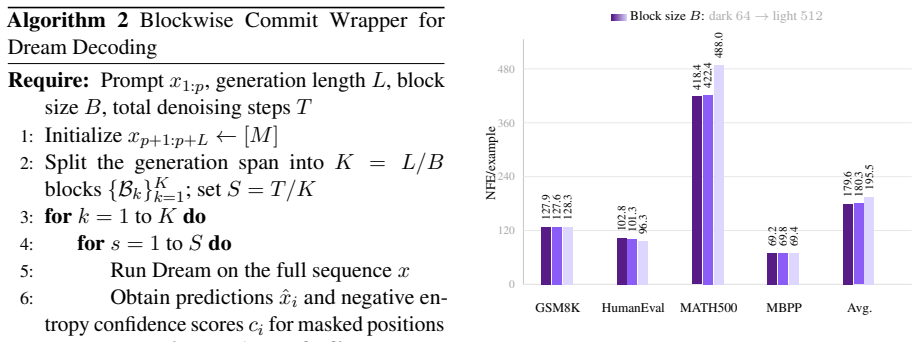
- Average decoding cost measured in number of function evaluations drops by 55.7 percent.
- Early stopping becomes feasible without sacrificing response quality.
Where Pith is reading between the lines
- The same role-separation idea could be tested on other non-autoregressive generative architectures that rely on length or termination tokens.
- If [VOID] truly decouples signals, similar dedicated tokens might simplify length control in any canvas-based diffusion model.
- The method reduces the engineering burden of choosing a single fixed block size at inference time.
Load-bearing premise
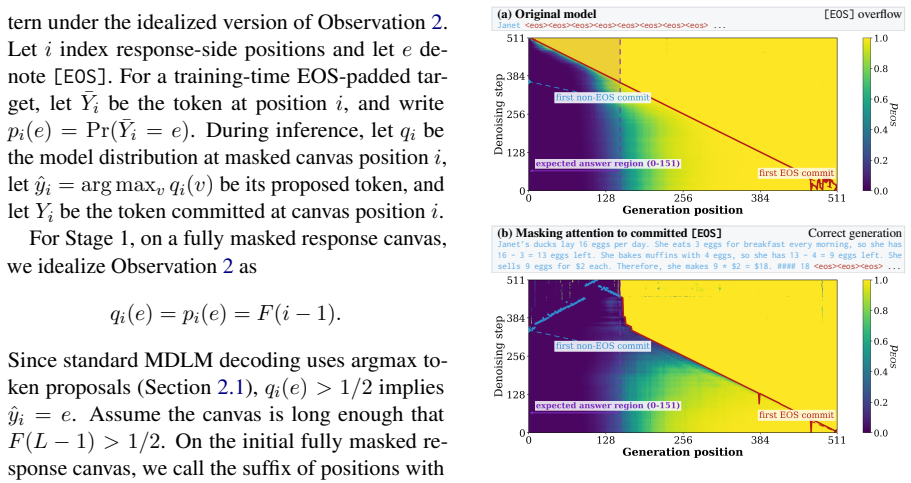
The dual use of [EOS] as both terminator and padding token is the main cause of overflow, and a separate [VOID] token plus ordinary training is enough to produce cleanly separated signals.
What would settle it
Train an identical model with VoidPadding and observe whether [EOS] overflow still occurs under the same large-block decoding regime on the reported benchmarks.
Figures

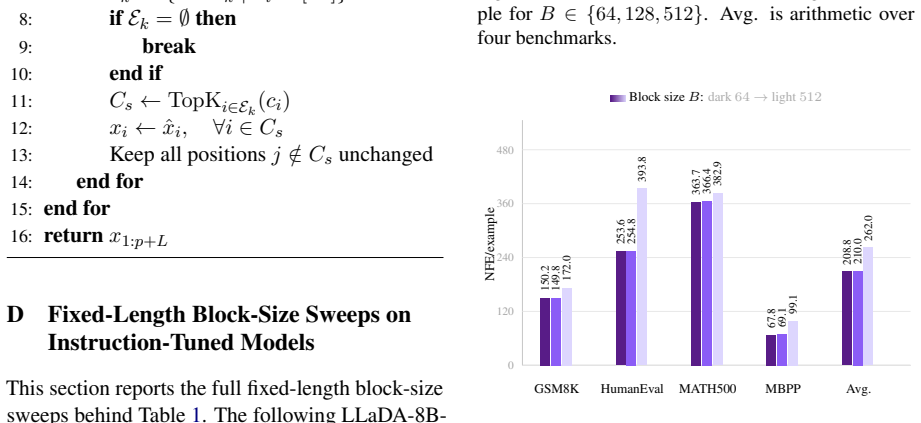
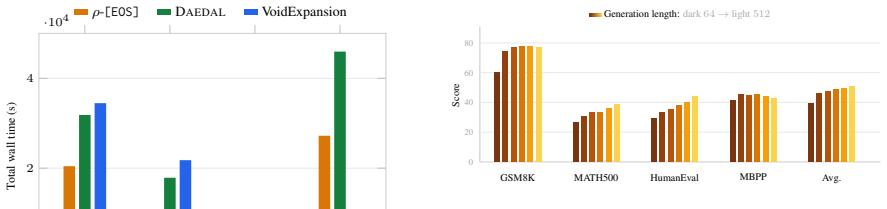
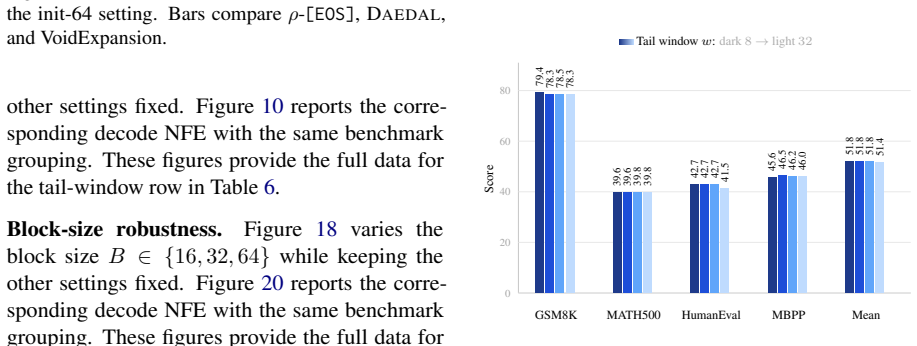
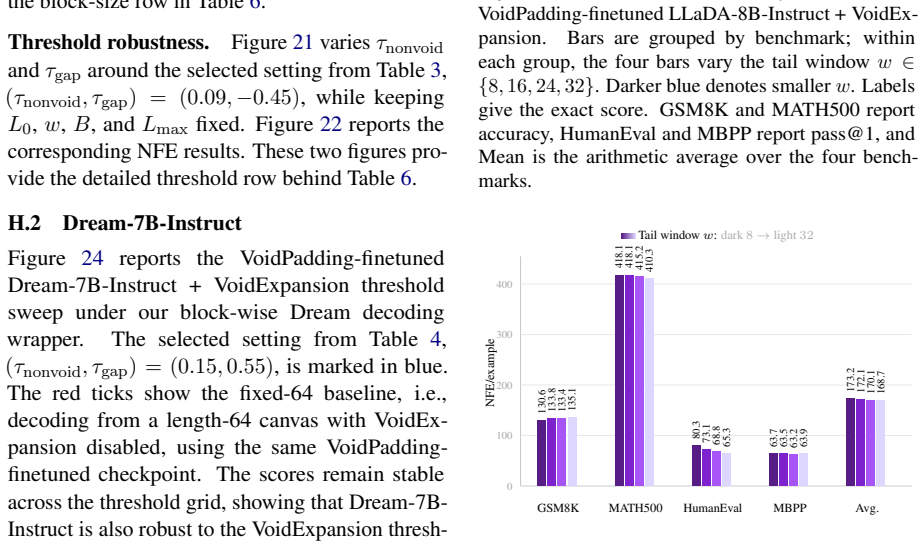

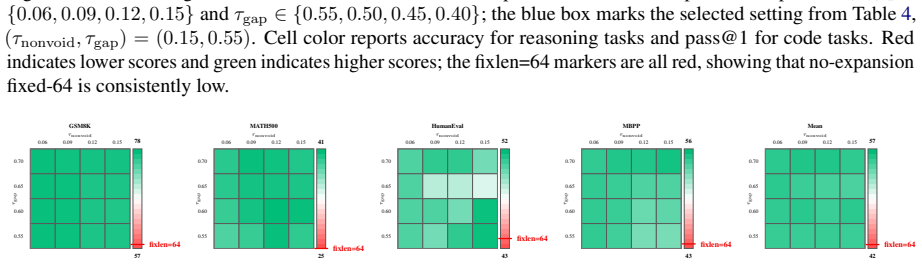
read the original abstract
MDLMs generate text by denoising a preallocated masked response canvas, making response-length modeling central to instruction tuning. Existing MDLMs often inherit the autoregressive convention of using repeated \texttt{[EOS]} tokens for padding during instruction tuning, giving \texttt{[EOS]} a dual role as both a semantic terminator and a padding token. We show that this dual role is a root cause of \texttt{[EOS]} overflow under large-block decoding. To decouple these roles, we propose VoidPadding, which introduces \texttt{[VOID]} for padding and reserves \texttt{[EOS]} for termination. During inference, the learned \texttt{[EOS]} signal enables early stopping, while the learned \texttt{[VOID]} signal guides adaptive response canvas expansion. On Dream-7B-Instruct, VoidPadding improves the block-size-averaged four-task mean across mathematical reasoning and code generation benchmarks by \(+17.84\) points over the original model and \(+6.95\) points over RainbowPadding, while reducing decoding NFE by 55.7\% on average. Code is available at https://github.com/Haru-LCY/VoidPadding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes VoidPadding for masked diffusion language models (MDLMs), claiming that the dual role of [EOS] as both semantic terminator and padding token causes [EOS] overflow under large-block decoding. By introducing a dedicated [VOID] token for padding and reserving [EOS] for termination, the approach enables early stopping via the learned [EOS] signal and adaptive canvas expansion via [VOID] during inference. On Dream-7B-Instruct, it reports a +17.84 point improvement in block-size-averaged four-task mean (math reasoning and code generation) over the original model and +6.95 over RainbowPadding, alongside a 55.7% average reduction in decoding NFE.
Significance. If the results hold, this offers a simple, practical fix to response-length modeling in MDLMs, a key issue for instruction tuning in non-autoregressive generation. The reported gains on reasoning benchmarks and efficiency improvements could make MDLMs more competitive, and the public code release aids reproducibility.
major comments (2)
- [Abstract] Abstract: the claim that the dual semantic/padding role of [EOS] is the root cause of overflow is not supported by any token-level statistics (e.g., [EOS] probability mass on post-termination positions in the baseline) or ablations that isolate this mechanism from the new adaptive expansion rule or vocabulary changes.
- [Abstract] Abstract: the quantitative claims (+17.84 / +6.95 points, -55.7% NFE) are presented without statistical significance tests, exact baseline definitions, data splits, or ablation controls, preventing verification of the central performance result.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the two major comments below and will revise the paper to strengthen the supporting evidence and experimental details as outlined.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the dual semantic/padding role of [EOS] is the root cause of overflow is not supported by any token-level statistics (e.g., [EOS] probability mass on post-termination positions in the baseline) or ablations that isolate this mechanism from the new adaptive expansion rule or vocabulary changes.
Authors: We acknowledge that the abstract and current presentation do not include explicit token-level statistics or isolating ablations. The manuscript supports the claim through the observed [EOS] overflow behavior under large-block decoding and the performance gains from decoupling via [VOID], but we agree these are indirect. In the revision we will add (i) visualizations of [EOS] probability mass on post-termination positions for the baseline and (ii) ablations that separately control for the adaptive expansion rule and vocabulary changes. revision: yes
-
Referee: [Abstract] Abstract: the quantitative claims (+17.84 / +6.95 points, -55.7% NFE) are presented without statistical significance tests, exact baseline definitions, data splits, or ablation controls, preventing verification of the central performance result.
Authors: The reported numbers are block-size-averaged means over the four tasks with the original model and RainbowPadding as baselines, using the standard splits for the math and code benchmarks. However, we did not include p-values, variance estimates, or exhaustive ablation tables in the abstract. We will expand the experimental section with statistical significance tests, precise baseline configurations, data-split details, and additional ablation controls to improve verifiability. revision: yes
Circularity Check
Empirical intervention with no derivation chain or self-referential definitions
full rationale
The paper introduces VoidPadding by adding a dedicated [VOID] token for padding and reserving [EOS] for termination, then trains the model under standard procedures and reports measured benchmark improvements (+17.84 points, -55.7% NFE). No equations, fitted parameters, uniqueness theorems, or self-citations appear in the provided text. The central claim is an empirical outcome of the token change and early-stopping logic rather than a quantity defined in terms of itself or reduced by construction to prior fitted values. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard training of MDLMs on instruction data will cause the model to learn distinct representations and usage patterns for a newly introduced [VOID] token versus the existing [EOS] token.
invented entities (1)
-
[VOID] token
no independent evidence
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2510.24605 , year=
Diffusion llm with native variable generation lengths: Let [eos] lead the way , author=. arXiv preprint arXiv:2510.24605 , year=
-
[2]
Journal of Machine Learning Research , volume=
Scaling instruction-finetuned language models , author=. Journal of Machine Learning Research , volume=
-
[3]
arXiv preprint arXiv:2510.03680 , year=
Rainbow Padding: Mitigating Early Termination in Instruction-Tuned Diffusion LLMs , author=. arXiv preprint arXiv:2510.03680 , year=
-
[4]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[5]
Advances in Neural Information Processing Systems , volume=
Large language diffusion models , author=. Advances in Neural Information Processing Systems , volume=
-
[6]
arXiv preprint arXiv:2508.00819 , year=
Beyond fixed: Training-free variable-length denoising for diffusion large language models , author=. arXiv preprint arXiv:2508.00819 , year=
-
[7]
Yang, Jingyi and Jiang, Yuxian and Shao, Jing , journal=
-
[8]
arXiv preprint arXiv:2603.06123 , year=
Diffusion Language Models Are Natively Length-Aware , author=. arXiv preprint arXiv:2603.06123 , year=
-
[9]
Advances in neural information processing systems , volume=
Diffusion-lm improves controllable text generation , author=. Advances in neural information processing systems , volume=
-
[10]
Advances in neural information processing systems , volume=
Structured denoising diffusion models in discrete state-spaces , author=. Advances in neural information processing systems , volume=
-
[11]
Advances in Neural Information Processing Systems , volume=
Simple and effective masked diffusion language models , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
arXiv preprint arXiv:2508.15487 , year=
Dream 7b: Diffusion large language models , author=. arXiv preprint arXiv:2508.15487 , year=
-
[13]
1: Speeding up text diffusion via token editing , author=
Llada2. 1: Speeding up text diffusion via token editing , author=. arXiv preprint arXiv:2602.08676 , year=
-
[14]
2018 , publisher=
Improving language understanding by generative pre-training , author=. 2018 , publisher=
2018
-
[15]
arXiv preprint arXiv:2505.22618 , year=
Fast-dllm: Training-free acceleration of diffusion llm by enabling kv cache and parallel decoding , author=. arXiv preprint arXiv:2505.22618 , year=
-
[16]
arXiv preprint arXiv:2602.18176 , year=
Improving Sampling for Masked Diffusion Models via Information Gain , author=. arXiv preprint arXiv:2602.18176 , year=
-
[17]
arXiv preprint arXiv:2602.07546 , year=
Improving Variable-Length Generation in Diffusion Language Models via Length Regularization , author=. arXiv preprint arXiv:2602.07546 , year=
-
[18]
Advances in Neural Information Processing Systems , volume=
Accelerated sampling from masked diffusion models via entropy bounded unmasking , author=. Advances in Neural Information Processing Systems , volume=
-
[19]
arXiv preprint arXiv:2505.21467 , year=
FlashDLM: Accelerating Diffusion Language Model Inference via Efficient KV Caching and Guided Diffusion , author=. arXiv preprint arXiv:2505.21467 , year=
-
[20]
arXiv preprint arXiv:2602.01326 , year=
DreamOn: Diffusion Language Models For Code Infilling Beyond Fixed-size Canvas , author=. arXiv preprint arXiv:2602.01326 , year=
-
[21]
arXiv preprint arXiv:2509.24007 , year=
Sequential diffusion language models , author=. arXiv preprint arXiv:2509.24007 , year=
-
[22]
Advances in Neural Information Processing Systems , volume=
Klass: Kl-guided fast inference in masked diffusion models , author=. Advances in Neural Information Processing Systems , volume=
-
[23]
arXiv preprint arXiv:2508.13021 , year=
Pc-sampler: Position-aware calibration of decoding bias in masked diffusion models , author=. arXiv preprint arXiv:2508.13021 , year=
-
[24]
arXiv preprint arXiv:2108.07732 , year=
Program synthesis with large language models , author=. arXiv preprint arXiv:2108.07732 , year=
-
[25]
arXiv preprint arXiv:2107.03374 , year=
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
-
[26]
arXiv preprint arXiv:2103.03874 , year=
Measuring mathematical problem solving with the math dataset , author=. arXiv preprint arXiv:2103.03874 , year=
-
[27]
arXiv preprint arXiv:2110.14168 , year=
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
-
[28]
arXiv preprint arXiv:2411.15124 , year=
Tulu 3: Pushing frontiers in open language model post-training , author=. arXiv preprint arXiv:2411.15124 , year=
-
[29]
Hugging Face Blog , volume=
SmolLM-blazingly fast and remarkably powerful , author=. Hugging Face Blog , volume=
-
[30]
arXiv preprint arXiv:2310.16834 , year=
Discrete diffusion modeling by estimating the ratios of the data distribution , author=. arXiv preprint arXiv:2310.16834 , year=
-
[31]
arXiv preprint arXiv:2502.06768 , year=
Train for the worst, plan for the best: Understanding token ordering in masked diffusions , author=. arXiv preprint arXiv:2502.06768 , year=
-
[32]
International Conference on Learning Representations , volume=
Block diffusion: Interpolating between autoregressive and diffusion language models , author=. International Conference on Learning Representations , volume=
-
[33]
arXiv preprint arXiv:2510.06303 , year=
Sdar: A synergistic diffusion-autoregression paradigm for scalable sequence generation , author=. arXiv preprint arXiv:2510.06303 , year=
-
[34]
arXiv preprint arXiv:2509.06949 , year=
Revolutionizing reinforcement learning framework for diffusion large language models , author=. arXiv preprint arXiv:2509.06949 , year=
-
[35]
arXiv preprint arXiv:2603.22248 , year=
Confidence-Based Decoding is Provably Efficient for Diffusion Language Models , author=. arXiv preprint arXiv:2603.22248 , year=
-
[36]
, author=
Lora: Low-rank adaptation of large language models. , author=. Iclr , volume=
-
[37]
arXiv preprint arXiv:2510.17206 , year=
Soft-masked diffusion language models , author=. arXiv preprint arXiv:2510.17206 , year=
-
[38]
arXiv preprint arXiv:2509.24389 , year=
Llada-moe: A sparse moe diffusion language model , author=. arXiv preprint arXiv:2509.24389 , year=
-
[39]
arXiv preprint arXiv:2505.19223 , year=
Llada 1.5: Variance-reduced preference optimization for large language diffusion models , author=. arXiv preprint arXiv:2505.19223 , year=
-
[40]
0: Scaling up diffusion language models to 100b , author=
Llada2. 0: Scaling up diffusion language models to 100b , author=. arXiv preprint arXiv:2512.15745 , year=
-
[41]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Sparse-dllm: Accelerating diffusion llms with dynamic cache eviction , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[42]
The Fourteenth International Conference on Learning Representations , year=
Dynamic-dLLM: Dynamic Cache-Budget and Adaptive Parallel Decoding for Training-Free Acceleration of Diffusion LLM , author=. The Fourteenth International Conference on Learning Representations , year=
-
[43]
arXiv preprint arXiv:2602.05992 , year=
DSB: Dynamic Sliding Block Scheduling for Diffusion LLMs , author=. arXiv preprint arXiv:2602.05992 , year=
-
[44]
arXiv preprint arXiv:2605.10938 , year=
ELF: Embedded Language Flows , author=. arXiv preprint arXiv:2605.10938 , year=
-
[45]
arXiv preprint arXiv:2512.22737 , year=
Wedlm: Reconciling diffusion language models with standard causal attention for fast inference , author=. arXiv preprint arXiv:2512.22737 , year=
-
[46]
arXiv preprint arXiv:2605.06548 , year=
Continuous Latent Diffusion Language Model , author=. arXiv preprint arXiv:2605.06548 , year=
-
[47]
Advances in Neural Information Processing Systems , volume=
Continuous diffusion model for language modeling , author=. Advances in Neural Information Processing Systems , volume=
-
[48]
arXiv preprint arXiv:2603.02547 , year=
Codar: Continuous diffusion language models are more powerful than you think , author=. arXiv preprint arXiv:2603.02547 , year=
-
[49]
Advances in neural information processing systems , volume=
Denoising diffusion probabilistic models , author=. Advances in neural information processing systems , volume=
-
[50]
Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
Discrete diffusion language model for efficient text summarization , author=. Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
2025
-
[51]
arXiv preprint arXiv:2506.10892 , year=
The diffusion duality , author=. arXiv preprint arXiv:2506.10892 , year=
-
[52]
Advances in neural information processing systems , volume=
Argmax flows and multinomial diffusion: Learning categorical distributions , author=. Advances in neural information processing systems , volume=
-
[53]
Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
Diffusionbert: Improving generative masked language models with diffusion models , author=. Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
-
[54]
arXiv preprint arXiv:2508.19982 , year=
Diffusion language models know the answer before decoding , author=. arXiv preprint arXiv:2508.19982 , year=
-
[55]
Advances in neural information processing systems , volume=
Accelerating diffusion llms via adaptive parallel decoding , author=. Advances in neural information processing systems , volume=
-
[56]
arXiv preprint arXiv:2506.10848 , year=
Accelerating diffusion large language models with slowfast sampling: The three golden principles , author=. arXiv preprint arXiv:2506.10848 , year=
-
[57]
arXiv preprint arXiv:2509.20624 , year=
Fs-dfm: Fast and accurate long text generation with few-step diffusion language models , author=. arXiv preprint arXiv:2509.20624 , year=
-
[58]
arXiv preprint arXiv:2605.00161 , year=
Consistent Diffusion Language Models , author=. arXiv preprint arXiv:2605.00161 , year=
-
[59]
arXiv preprint arXiv:2602.12262 , year=
T3d: Few-step diffusion language models via trajectory self-distillation with direct discriminative optimization , author=. arXiv preprint arXiv:2602.12262 , year=
-
[60]
arXiv preprint arXiv:2506.00290 , year=
Dlm-one: Diffusion language models for one-step sequence generation , author=. arXiv preprint arXiv:2506.00290 , year=
-
[61]
arXiv preprint arXiv:2509.01025 , year=
Any-order flexible length masked diffusion , author=. arXiv preprint arXiv:2509.01025 , year=
-
[62]
arXiv preprint arXiv:2604.23994 , year=
When to Commit? Towards Variable-Size Self-Contained Blocks for Discrete Diffusion Language Models , author=. arXiv preprint arXiv:2604.23994 , year=
-
[63]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Ssd-lm: Semi-autoregressive simplex-based diffusion language model for text generation and modular control , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[64]
arXiv preprint arXiv:1412.6980 , year=
Adam: A method for stochastic optimization , author=. arXiv preprint arXiv:1412.6980 , year=
-
[65]
arXiv preprint arXiv:2511.21759 , year=
Orchestrating Dual-Boundaries: An Arithmetic Intensity Inspired Acceleration Framework for Diffusion Language Models , author=. arXiv preprint arXiv:2511.21759 , year=
-
[66]
Advances in Neural Information Processing Systems , year=
Simplified and Generalized Masked Diffusion for Discrete Data , author=. Advances in Neural Information Processing Systems , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.