Knowing What to Solve Before How: Preplan Empowered LLM Mathematical Reasoning
Pith reviewed 2026-06-29 07:27 UTC · model grok-4.3
The pith
An explicit preplan stage that first identifies problem type, tools, and pitfalls improves LLM mathematical reasoning before any planning begins.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors introduce the PPC framework that inserts an explicit preplan stage before planning and chain-of-thought, producing the question to preplan to plan to cot paradigm. The preplan determines the problem type, applicable tools, and foreseeable pitfalls. A three-stage synthesis pipeline equipped with a spoiler-score detector builds supervision data that avoids leakage, and a composite GRPO reward ensures generated plans remain consistent with the preplan. Experiments on four backbones and five mathematical reasoning benchmarks demonstrate gains under this structure.
What carries the argument
The preplan stage, which explicitly recognizes the problem type, applicable tools, and foreseeable pitfalls, enforced by a three-stage synthesis pipeline with spoiler-score detector and composite GRPO reward.
If this is right
- The question-preplan-plan-cot sequence produces higher accuracy than question-plan-cot on mathematical reasoning tasks across different model sizes.
- The preplan stage can be added to existing backbones without increasing the number of tokens used during inference.
- Plans generated after an explicit preplan remain more consistent with the initial problem understanding.
- The synthesis pipeline and reward design allow the new stage to be trained without contaminating the supervision signal.
Where Pith is reading between the lines
- The same preplan-first separation could be tested on code generation or scientific question answering to see whether early problem classification helps outside mathematics.
- If preplans are made visible to users, they might serve as a lightweight explanation of why a model chose a particular solution path.
- Learned preplans without the supervised synthesis step could be explored as a next step once the supervised version shows gains.
Load-bearing premise
A three-stage synthesis pipeline with a spoiler-score detector can generate clean preplan supervision data without leakage or spoiler failures, and the GRPO reward can ensure later plans follow from that preplan.
What would settle it
Train a model with the PPC pipeline, then run inference on the same benchmarks while omitting the preplan generation step and check whether the reported accuracy gains disappear.
Figures







read the original abstract
Current plan-based reasoning methods improve large language models (LLMs) by inserting a planning stage before execution, giving rise to the question $\rightarrow$ plan $\rightarrow$ cot paradigm. While effective, a closer examination reveals an inherent paradigm-level gap: both the planning and its execution stages decide how to solve a problem, while the prior question of what to solve; recognizing the problem type, the applicable tools, and the foreseeable pitfalls; remains entirely implicit. To bridge this gap, we propose PPC (Preplan-Plan-CoT), a framework that introduces an explicit problem-understanding stage, the preplan, yielding a new question $\rightarrow$ preplan $\rightarrow$ plan $\rightarrow$ cot paradigm. Realizing this paradigm requires safeguarding the conceptual integrity of preplan at both ends. Specifically, we design a three-stage synthesis pipeline with a spoiler-score detector that filters out leakage and spoiler failures to build clean preplan supervision, and a composite GRPO reward enforces that the generated plan genuinely follows from the preplan. Experiments across four backbones and five mathematical reasoning benchmarks show that PPC achieves the best results on 39 of 40 metrics, improving maj@16 and pass@16 by +2.23 and +3.06 over the strongest baseline without introducing additional inference token overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that existing plan-based LLM reasoning follows a question→plan→cot paradigm that leaves problem-type understanding implicit, and introduces PPC (Preplan-Plan-CoT) to add an explicit preplan stage. It realizes the new paradigm via a three-stage synthesis pipeline plus spoiler-score detector for clean preplan data and a composite GRPO reward to enforce plan-preplan consistency. Across four backbones and five math benchmarks, PPC is reported to win on 39 of 40 metrics, improving maj@16 and pass@16 by +2.23 and +3.06 over the strongest baseline with no added inference tokens.
Significance. If the performance gains can be attributed to genuine problem-understanding preplans rather than residual solution leakage, the work would offer a concrete, low-overhead extension of the planning paradigm with practical value for mathematical reasoning. The explicit separation of “what” from “how” is a clear conceptual contribution, and the absence of extra inference cost strengthens deployability. However, the soundness of this attribution rests on unverified properties of the data pipeline and reward.
major comments (3)
- [Abstract, §3.2] Abstract and §3.2: the central claim that the three-stage synthesis pipeline with spoiler-score detector yields clean preplan supervision (no executable solution leakage) is load-bearing for attributing the +2.23/+3.06 gains to the new paradigm rather than shortcut hints; yet the manuscript reports neither a measured spoiler rate on held-out problems nor inter-annotator agreement on whether preplans contain executable steps.
- [§3.3] §3.3: the composite GRPO reward is asserted to enforce that generated plans genuinely follow from the preplan, but no ablation, mismatch-penalty analysis, or scale test is provided to confirm the reward actually prevents plan-preplan divergence; this directly affects whether the observed improvements reflect the intended separation.
- [§4, Table 2] §4 and Table 2: the headline results (best on 39/40 metrics) are presented without statistical significance tests, run-to-run variance, or confidence intervals, making it impossible to assess whether the reported margins are robust or could be explained by implementation differences in the baselines.
minor comments (2)
- [§3.2] Notation for the spoiler-score threshold and the exact form of the composite GRPO reward should be defined with explicit equations rather than prose descriptions.
- [Figure 1] Figure 1 caption should clarify whether the depicted preplan examples were filtered by the spoiler detector or are raw outputs.
Simulated Author's Rebuttal
We thank the referee for the constructive comments that identify key areas for strengthening the attribution of results to the proposed paradigm. We respond to each major comment below and will make the indicated revisions.
read point-by-point responses
-
Referee: [Abstract, §3.2] Abstract and §3.2: the central claim that the three-stage synthesis pipeline with spoiler-score detector yields clean preplan supervision (no executable solution leakage) is load-bearing for attributing the +2.23/+3.06 gains to the new paradigm rather than shortcut hints; yet the manuscript reports neither a measured spoiler rate on held-out problems nor inter-annotator agreement on whether preplans contain executable steps.
Authors: We agree that quantitative validation of the spoiler-score detector on held-out data would strengthen the claim of clean preplan supervision. In the revision we will add an evaluation reporting the measured spoiler/leakage rate on a held-out problem set. The detector is a deterministic rule-based scorer rather than a human annotation task, so inter-annotator agreement does not apply; we will clarify this design choice and its coverage of common leakage patterns. revision: yes
-
Referee: [§3.3] §3.3: the composite GRPO reward is asserted to enforce that generated plans genuinely follow from the preplan, but no ablation, mismatch-penalty analysis, or scale test is provided to confirm the reward actually prevents plan-preplan divergence; this directly affects whether the observed improvements reflect the intended separation.
Authors: We acknowledge that direct empirical confirmation of the reward's effect on plan-preplan consistency is missing. The revision will include an ablation that removes the mismatch-penalty term, together with a quantitative analysis of plan-preplan divergence rates on sampled outputs before and after the full reward, to demonstrate that the composite objective successfully enforces the intended separation. revision: yes
-
Referee: [§4, Table 2] §4 and Table 2: the headline results (best on 39/40 metrics) are presented without statistical significance tests, run-to-run variance, or confidence intervals, making it impossible to assess whether the reported margins are robust or could be explained by implementation differences in the baselines.
Authors: We agree that measures of statistical robustness are needed to support the headline margins. In the revised manuscript we will augment Table 2 with run-to-run standard deviations and bootstrap confidence intervals obtained from multiple independent training and evaluation seeds (where compute permits), and will add pairwise significance tests against the strongest baseline. revision: yes
Circularity Check
No circularity: empirical gains rest on external benchmarks and independent synthesis choices
full rationale
The paper introduces an explicit preplan stage via a three-stage synthesis pipeline (with spoiler detector) and composite GRPO reward, then reports empirical improvements on five standard math benchmarks across four backbones. All metrics are compared to external baselines; no equations or claims reduce the reported maj@16/pass@16 gains to quantities defined by the method itself. The synthesis and reward are methodological design decisions whose validity is asserted but not tautological with the final numbers. No self-citations, fitted-input predictions, or ansatz smuggling appear in the provided text.
Axiom & Free-Parameter Ledger
free parameters (1)
- spoiler-score threshold
axioms (1)
- domain assumption Composite GRPO reward can enforce conceptual integrity between preplan and plan
Reference graph
Works this paper leans on
-
[1]
Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains
Rubrics as rewards: Reinforcement learn- ing beyond verifiable domains.arXiv preprint arXiv:2507.17746. Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, and 1 others. 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Let’s verify step by step.arXiv preprint arXiv:2305.20050. Ivan Moshkov, Darragh Hanley, Ivan Sorokin, Shubham Toshniwal, Christof Henkel, Benedikt Schifferer, Wei Du, and Igor Gitman. 2025. Aimo-2 winning solu- tion: Building state-of-the-art mathematical reason- ing models with openmathreasoning dataset.arXiv preprint arXiv:2504.16891. Mihir Parmar, Pal...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jian- hong Tu, Jingren Zhou, Junyang Lin, Keming Lu, Mingfeng Xue, Runji Lin, Tianyu Liu, Xingzhang Ren, and Zhenru Zhang. 2024. Qwen2.5-math tech- nical report: Toward mathematical expert model via self-improvement...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
LIMO: Less is More for Reasoning
Tree of thoughts: Deliberate problem solving with large language models.Advances in neural information processing systems, 36:11809–11822. Yixin Ye, Zhen Huang, Yang Xiao, Ethan Chern, Shijie Xia, and Pengfei Liu. 2025. Limo: Less is more for reasoning.arXiv preprint arXiv:2502.03387. Xiang Yue, Xingwei Qu, Ge Zhang, Yao Fu, Wenhao Huang, Huan Sun, Yu Su,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
simplifies to
We should also be careful not to assume uniqueness without verifying compatibility of the congruences. One potential pitfall is misapplying the theorem or mixing up moduli during calculations . . . Figure 5: Two preplans of comparable difficulty, both reaching correct answers.Top:a discarded preplan that computes and pre-enacts—asserting computed classifi...
-
[6]
simplifies to
Derivation phrasing.The text contains any phrase signalling an inference or transforma- tion has been carried out: e.g. “simplifies to”, “reduces to”, “leads to”, “yields”, “implies that”, “becomes”. Such phrases indicate the preplan is performing, not previewing, the derivation
-
[7]
A preplan that states constraints needs few equalities; a high count signals worked relations
Equation density.The combined count of equality symbols ( = and \equiv) is at least three. A preplan that states constraints needs few equalities; a high count signals worked relations
-
[8]
Short named quantities are permitted, but extended expressions indicate concrete manipulation
Long inline expressions.At least two inline- math spans exceed 30 characters. Short named quantities are permitted, but extended expressions indicate concrete manipulation
-
[9]
Multi-digit constants.The text contains a standalone integer of three or more digits, which typically appears only once specific numbers are being computed or stated
-
[10]
the answer
Answer-revealing wording.The text con- tains phrases such as “the answer”, “the result is”, “we get”, or “we obtain”, which tend to precede a disclosed outcome
-
[11]
this is a contour integral
Inline-math span count.The total number of inline-math spans is at least four, indicating the preplan leans on formal expressions rather than prose analysis. Aggregation and rationale.The final score sums the six indicators, s(ypp) = 6X i=1 1 signali fires ony pp ∈ {0, . . . ,6}, (8) 12 Stage 1 — Preplan Prompt You are a math teacher briefing a student be...
-
[12]
this simplifies to
NO derivations. Do NOT use phrases like "this simplifies to", "this leads to", "this implies", "this becomes", "we get", " ,→the result is"
-
[13]
the integral
NO formulas longer than 15 characters. You may name a quantity (e.g., "the integral", "the polynomial f(x)") but DO NOT ,→write extended expressions in $...$
-
[14]
let n be the count of
NO equations beyond definitional ones (e.g., "let n be the count of...")
-
[15]
Even if you know the answer, do NOT mention it
NO specific computed values. Even if you know the answer, do NOT mention it
-
[16]
The plan comes later -- your job is meta-thinking
NO step-by-step procedures. The plan comes later -- your job is meta-thinking
-
[17]
this suggests
Write as flowing prose, NOT as a list. Use natural transitions like "this suggests", "a natural approach is", "we should ,→also be careful about"
-
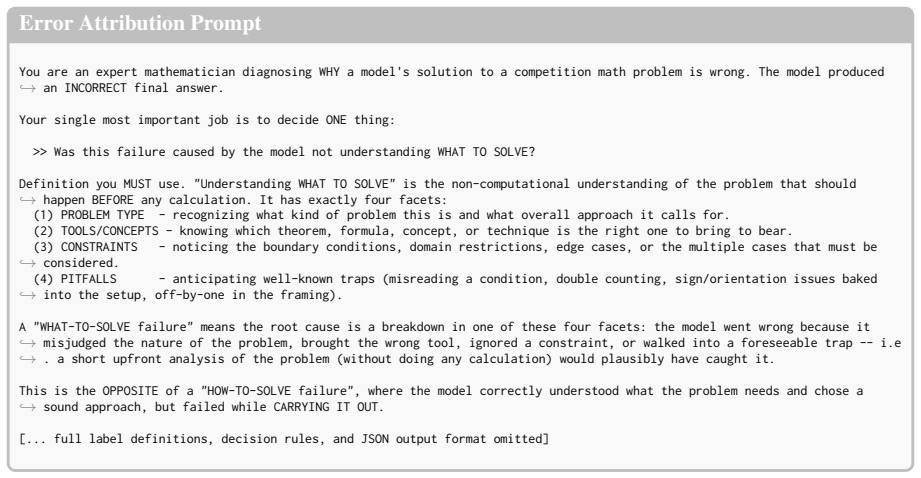
[18]
Output the paragraph directly
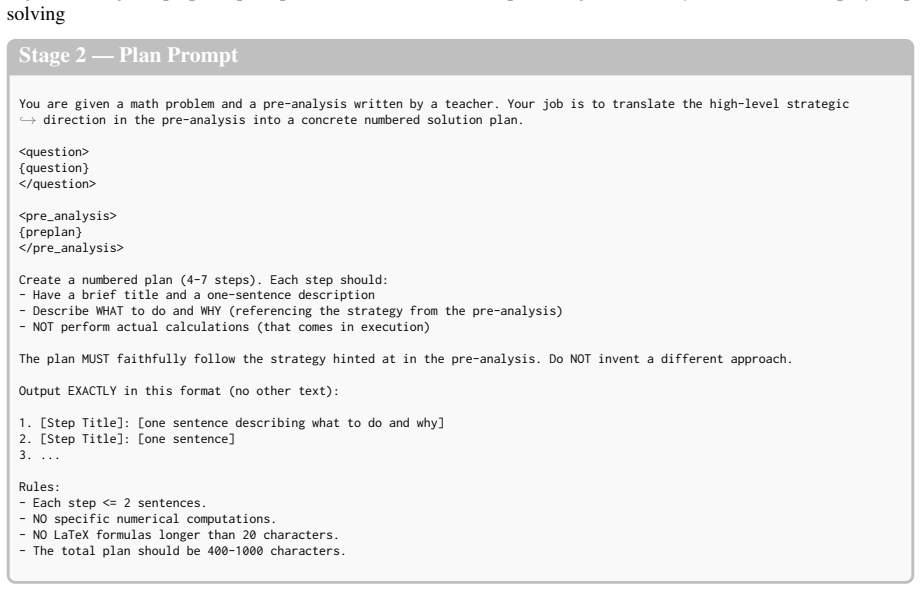
Be reasonably concise -- focus on insights, not exhaustive coverage. Output the paragraph directly. No headers, no labels, no quotation marks around the output. Figure 7: Stage 1 (preplan) prompt, which constrains the output to high-level analysis rather than step-by-step solving Stage 2 — Plan Prompt You are given a math problem and a pre-analysis writte...
-
[19]
[Step Title]: [one sentence describing what to do and why]
-
[20]
[Step Title]: [one sentence]
-
[21]
- NO specific numerical computations
Rules: - Each step <= 2 sentences. - NO specific numerical computations. - NO LaTeX formulas longer than 20 characters. - The total plan should be 400-1000 characters. Figure 8: Stage 2 (plan) prompt. The plan is conditioned on the preplan and must faithfully follow its strategy. This additive design tolerates the incidental use of light notation that eve...
-
[22]
Each step title MUST exactly match the corresponding plan step title
-
[23]
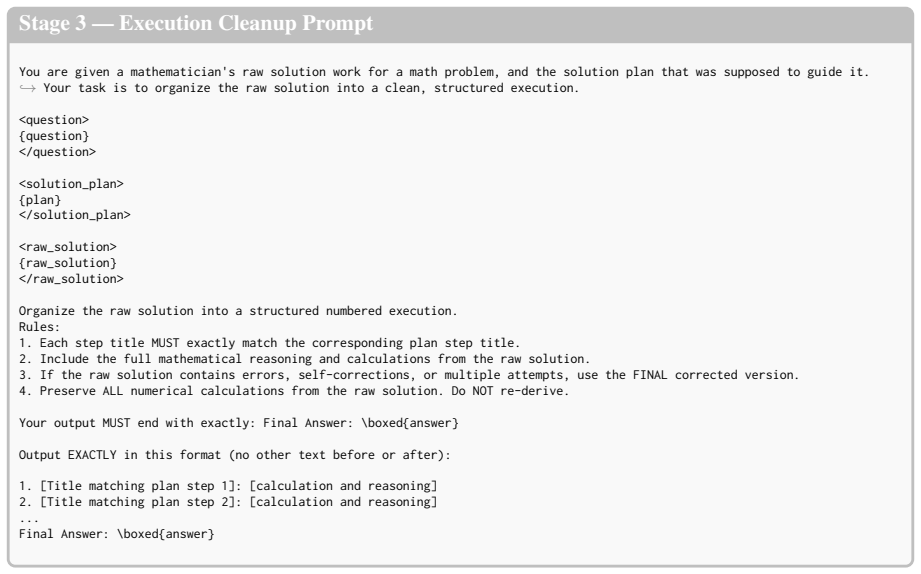
Include the full mathematical reasoning and calculations from the raw solution
-
[24]
If the raw solution contains errors, self-corrections, or multiple attempts, use the FINAL corrected version
-
[25]
Do NOT re-derive
Preserve ALL numerical calculations from the raw solution. Do NOT re-derive. Your output MUST end with exactly: Final Answer: \boxed{answer} Output EXACTLY in this format (no other text before or after):
-
[26]
[Title matching plan step 1]: [calculation and reasoning]
-
[27]
Final Answer: \boxed{answer} Figure 9: Stage 3 cleanup prompt
[Title matching plan step 2]: [calculation and reasoning] ... Final Answer: \boxed{answer} Figure 9: Stage 3 cleanup prompt. The raw reasoning trace is reorganized so that step titles align with the plan, preserving (not re-deriving) all computed values. Plan-adherence judge prompt (Radh) You are evaluating whether a solution plan truly follows from a pre...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.