VistaRef: Boosting Visual Spatial Orientation Awareness for Pointing-to-Object Detection
Pith reviewed 2026-06-26 00:57 UTC · model grok-4.3
The pith
VistaRef improves pointing-to-object detection accuracy by explicitly modeling hand poses and geometric rays inside Transformers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
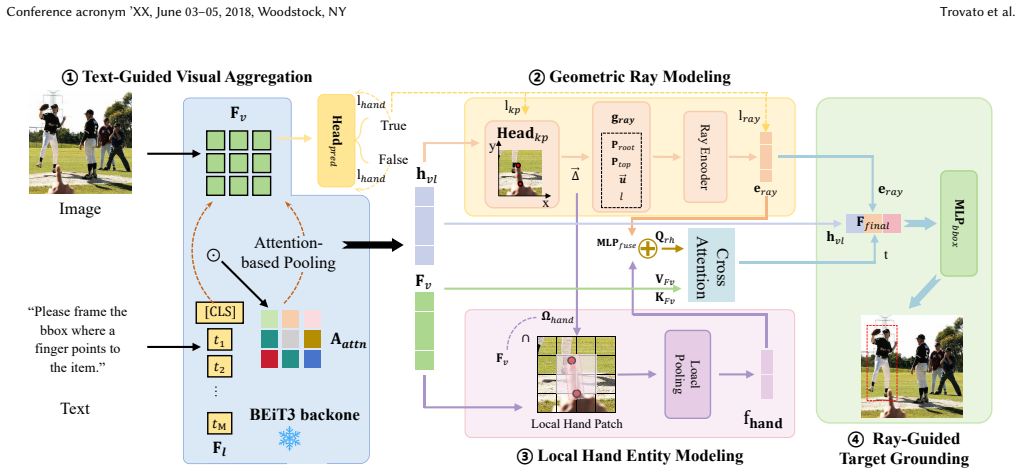
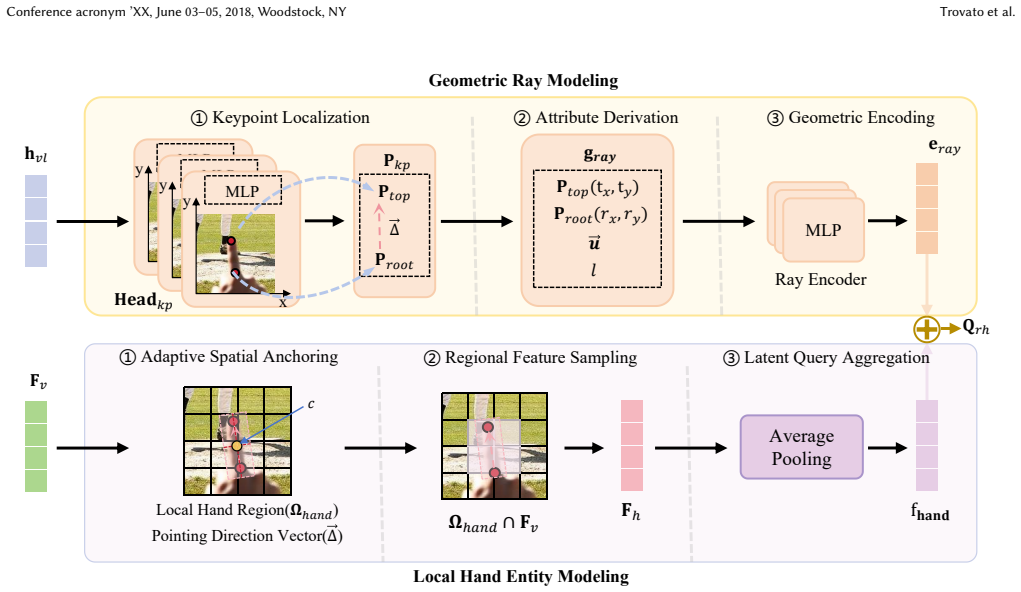
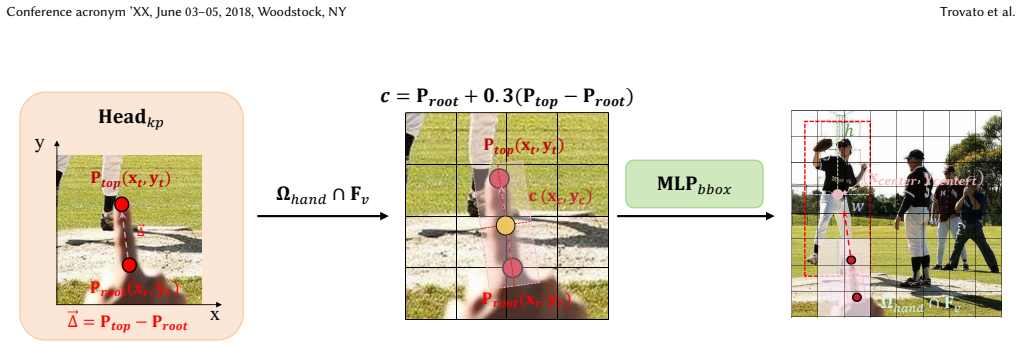
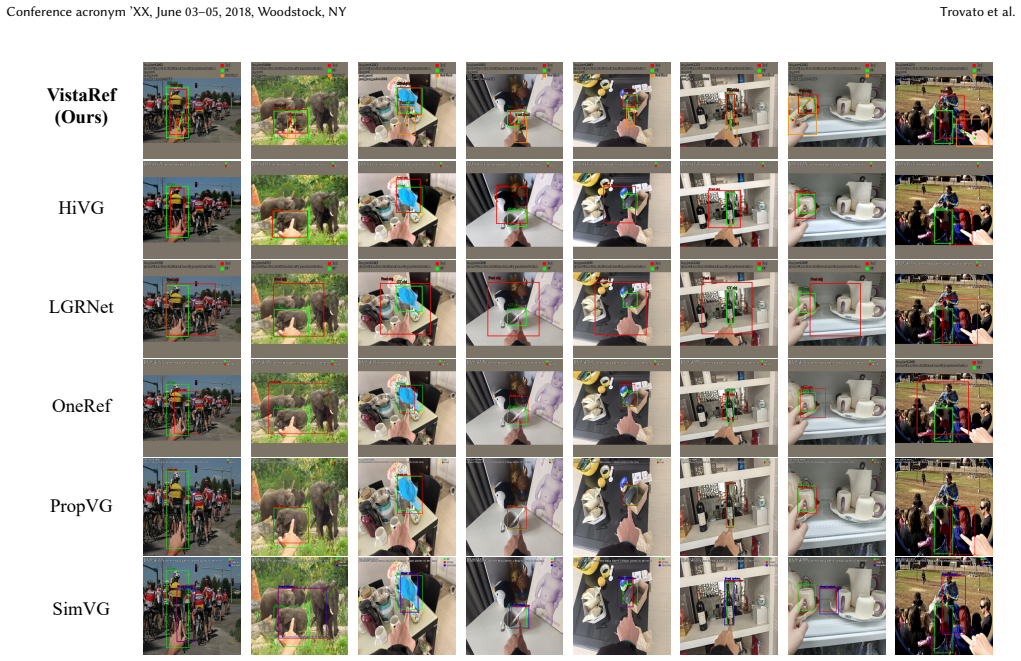
VistaRef is a framework that augments Transformer-based object detectors for deictic gesture grounding. It adds Local Hand Entity Modeling to embed subtle finger deviations, Geometric Ray Modeling to convert implicit orientation into explicit spatial geometric features that guide attention-based fusion, and Orientation-Consistent Alignment Loss to supervise both hand presence and pointing consistency. Together these components close the spatial-perception gap that standard global attention leaves in pointing tasks, yielding a 14-point absolute gain in grounding accuracy and clearer hand-to-target geometric correlation.
What carries the argument
The combination of Local Hand Entity Modeling (LHEM), Geometric Ray Modeling (GRM), and Orientation-Consistent Alignment Loss (OCAL) that converts finger pose into an explicit pointing ray and uses that ray to steer feature aggregation.
If this is right
- Pointing accuracy improves most for distant or densely packed objects where ray drift was previously severe.
- The model now produces explicit geometric features that link hand pose directly to target location.
- All three components must act together to realize the full gain; isolated changes yield smaller benefits.
- Qualitative results show reduced localization ambiguity in AR-style interaction scenes.
Where Pith is reading between the lines
- The same ray-modeling approach could be tested on other directional gestures such as head or gaze pointing.
- If micro-geometric relations matter in other detection subtasks, similar local-entity modules might help beyond pointing.
- The explicit ray representation offers a possible interface for downstream planning modules that need a 3-D direction rather than a 2-D box.
Load-bearing premise
Global attention in Transformers is the main source of orientation errors in pointing tasks, and the three added modules will correct those errors without creating offsetting new failure modes.
What would settle it
A controlled ablation in which any one of LHEM, GRM, or OCAL is removed and the 14-point accuracy gain disappears or reverses on the same pointing-to-object test set.
Figures



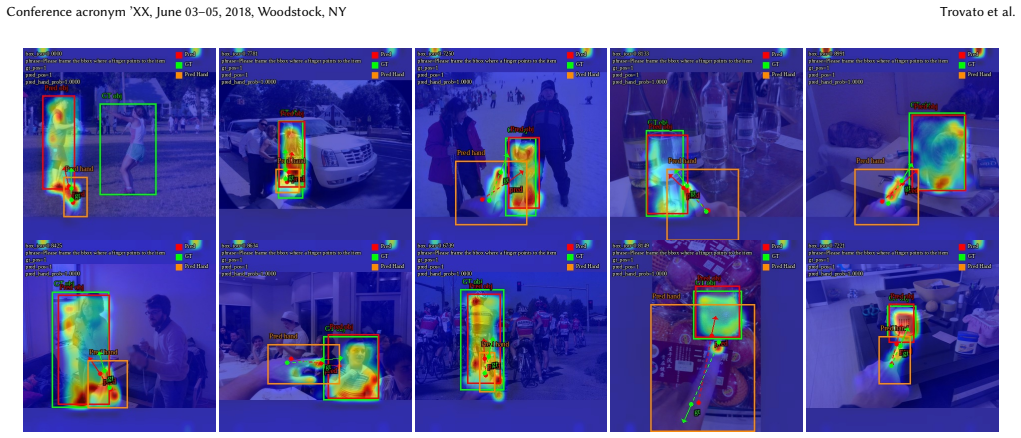
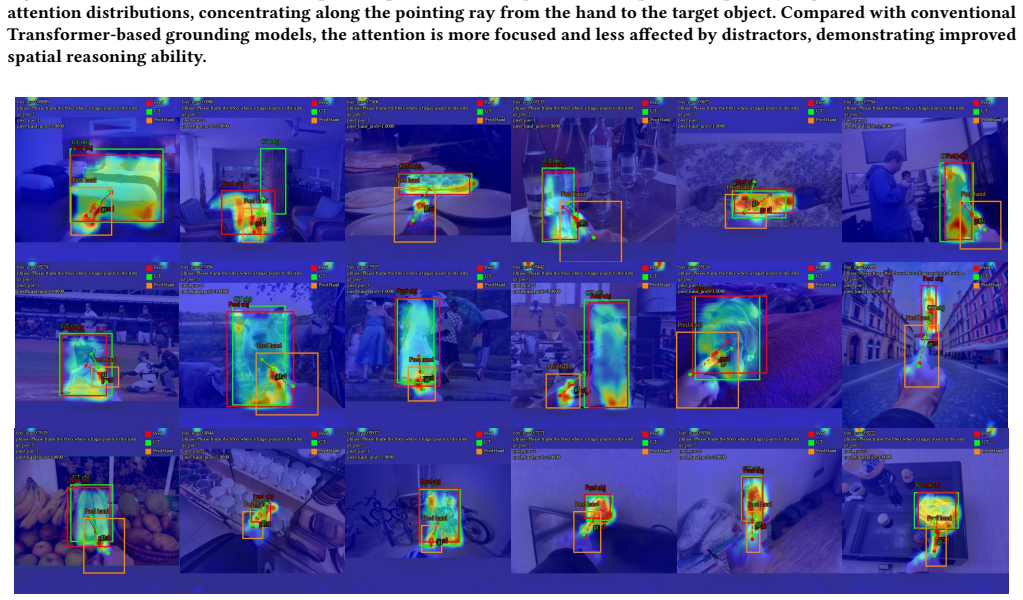
read the original abstract
Grounding deictic gestures in natural images is fundamental to AR and human-robot collaboration, providing a basis for seamless spatial interaction. While Transformer-based visual models have achieved significant progress in general object detection, their global attention mechanisms often neglect micro-geometric relationships, degrading orientation accuracy. In pointing tasks, this deficiency manifests as an inability to accurately capture the pointing ray implied by finger poses, which results in pointing drift and localization ambiguity when dealing with distant or densely packed objects. To address this, we propose VistaRef, a framework designed to explicitly enhance spatial orientation awareness. First, we develop the Local Hand Entity Modeling (LHEM) module, which incorporates hand-pose embeddings to strengthen the model's capability to capture subtle finger deviations. Second, drawing inspiration from multi-view geometry, we construct the Geometric Ray Modeling (GRM) module to transform implicit orientation information into explicit spatial geometric features, guiding feature aggregation and deep fusion via attention mechanisms. Furthermore, we introduce a novel Orientation-Consistent Alignment Loss (OCAL) to synergistically supervise hand presence and pointing consistency, ensuring that all architectural improvements collectively serve the core objective of spatial localization. Experimental results demonstrate that VistaRef significantly outperforms the baseline, achieving a 14-point absolute gain in grounding accuracy. Qualitative analysis further confirms that VistaRef effectively models the geometric correlation from hand to target, bridging the spatial perception gap inherent in traditional Transformers for complex scenarios. Code: https://github.com/lingli1724/VistaRef.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes VistaRef, a Transformer-based framework for pointing-to-object detection that augments the model with three components: the Local Hand Entity Modeling (LHEM) module to incorporate hand-pose embeddings, the Geometric Ray Modeling (GRM) module to convert implicit orientation into explicit multi-view geometric features, and the Orientation-Consistent Alignment Loss (OCAL) to supervise hand presence and pointing consistency. The central claim is that these additions address the neglect of micro-geometric relationships by global attention, yielding a 14-point absolute gain in grounding accuracy over the baseline, with qualitative confirmation of improved hand-to-target geometric correlation.
Significance. If the reported gain is robustly supported by ablations and protocol details, the work would be significant for AR and human-robot collaboration applications by improving spatial localization in deictic gesture grounding. The explicit modeling of hand-ray geometry via LHEM/GRM/OCAL is a targeted response to a known Transformer limitation, but the absence of any experimental verification in the manuscript prevents assessment of whether the result holds or generalizes.
major comments (2)
- [Abstract] Abstract: the claim that 'VistaRef significantly outperforms the baseline, achieving a 14-point absolute gain in grounding accuracy' is presented without any experimental protocol, baseline details, dataset statistics, error bars, ablation results, or secondary metrics. This renders the central performance claim unverifiable and prevents attribution of the gain to LHEM, GRM, or OCAL rather than incidental capacity or training changes.
- [Abstract] Abstract: the motivation assumes global attention is the primary source of orientation inaccuracy and that LHEM/GRM/OCAL will close this gap without new failure modes (e.g., sensitivity to hand-pose noise or degraded performance on non-pointing cases), yet no failure-case analysis, robustness tests, or cross-task evaluation is supplied to support this.
minor comments (1)
- [Abstract] Abstract: the sentence 'Code: https://github.com/lingli1724/VistaRef' appears without indicating whether the repository contains the full experimental setup, training scripts, or evaluation code needed to reproduce the claimed results.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below, clarifying the experimental details available in the full paper while agreeing to strengthen the abstract for better verifiability.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'VistaRef significantly outperforms the baseline, achieving a 14-point absolute gain in grounding accuracy' is presented without any experimental protocol, baseline details, dataset statistics, error bars, ablation results, or secondary metrics. This renders the central performance claim unverifiable and prevents attribution of the gain to LHEM, GRM, or OCAL rather than incidental capacity or training changes.
Authors: We agree that the abstract's brevity omits key protocol details, which limits immediate verifiability. The full manuscript (Section 4) specifies the evaluation protocol on a standard pointing-to-object detection benchmark, the exact baseline architecture and training settings, dataset statistics, ablation studies isolating LHEM/GRM/OCAL contributions (with the 14-point gain in Acc@0.5 attributable to these modules rather than capacity changes), error bars from multiple runs, and secondary metrics such as precision-recall curves. We will revise the abstract to include a concise reference to the benchmark, baseline, and note that full ablations and protocol appear in the Experiments section. revision: yes
-
Referee: [Abstract] Abstract: the motivation assumes global attention is the primary source of orientation inaccuracy and that LHEM/GRM/OCAL will close this gap without new failure modes (e.g., sensitivity to hand-pose noise or degraded performance on non-pointing cases), yet no failure-case analysis, robustness tests, or cross-task evaluation is supplied to support this.
Authors: The motivation is grounded in the Introduction's discussion of Transformer global attention limitations for micro-geometric relations, supported by citations to prior spatial reasoning work. The manuscript provides qualitative evidence of improved hand-to-target correlation and quantitative ablations showing gains without reported degradation on the evaluated pointing cases. However, explicit failure-case analysis for hand-pose noise, non-pointing scenarios, or cross-task generalization is not included in the current version. We can add a dedicated limitations discussion and robustness experiments during revision if required. revision: partial
Circularity Check
No significant circularity; VistaRef claims are empirical and self-contained
full rationale
The paper describes an empirical architecture (LHEM hand-pose embeddings, GRM ray features, OCAL loss) motivated by Transformer limitations in pointing tasks, then reports a 14-point grounding accuracy gain from experiments. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described claims. The performance result is presented as an outcome of the added modules rather than reducing by construction to the input data or prior self-work. This is the normal case for an ML systems paper whose central claim rests on external benchmarks and ablations rather than internal definitional equivalence.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Transformer global attention neglects micro-geometric relationships in hand poses
invented entities (3)
-
Local Hand Entity Modeling (LHEM) module
no independent evidence
-
Geometric Ray Modeling (GRM) module
no independent evidence
-
Orientation-Consistent Alignment Loss (OCAL)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Tijn Bertens, Brandon Caasenbrood, Alessandro Saccon, and Andrei Jalba. 2025. Symmetry-Induced Ambiguity in Orientation Estimation From RGB Images. Machine Vision and Applications36, 2 (2025), 40
2025
-
[2]
Zhe Cao, Gines Hidalgo, Tomas Simon, Shih-En Wei, and Yaser Sheikh. 2019. OpenPose: Realtime Multi-Person 2D Pose Estimation Using Part Affinity Fields. IEEE Transactions on Pattern Analysis and Machine Intelligence43, 1 (2019), 172– 186
2019
- [3]
- [4]
-
[5]
Ming Dai, Wenxuan Cheng, Jiedong Zhuang, Jiang jiang Liu, Hongshen Zhao, Zhenhua Feng, and Wankou Yang. 2025. PropVG: End-to-End Proposal-Driven Visual Grounding With Multi-Granularity Discrimination. InIn Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV ’25). 7058–7068
2025
-
[6]
Ming Dai, Lingfeng Yang, Yihao Xu, Zhenhua Feng, and Wankou Yang. 2024. SimVG: A Simple Framework for Visual Grounding With Decoupled Multi-Modal Fusion.Advances in Neural Information Processing Systems37 (2024), 121670– 121698
2024
-
[7]
Jiajun Deng, Zhengyuan Yang, Tianlang Chen, Wengang Zhou, and Houqiang Li. 2021. TransVG: End-to-End Visual Grounding With Transformers. InIn Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV ’21). 1769–1779
2021
-
[8]
Xiaoyi Dong, Jianmin Bao, Dongdong Chen, Zhang Weiming, Nenghai Yu, Lu Yuan, Dong Chen, and Baining Guo. 2022. CSWin Transformer: A General Vision Transformer Backbone With Cross-Shaped Windows. InIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR ’22). 12124–12134
2022
-
[9]
Fevziye Irem Eyiokur, Dogucan Yaman, Hazım Kemal Ekenel, and Alexander Waibel. 2026. CAPE: A CLIP-Aware Pointing Ensemble of Complementary Heatmap Cues for Embodied Reference Understanding. InIn Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (W ACV ’26). 3939–3950
2026
-
[10]
Kanoko Goto, Takumi Hirose, Mahiro Ukai, Shuhei Kurita, and Nakamasa Inoue
-
[11]
InIn Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV ’25)
Referring Expression Comprehension for Small Objects. InIn Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV ’25). 21231– 21242
-
[12]
Hao Guo, Wei Fan, Baichun Wei, Jianfei Zhu, Jin Tian, Chunzhi Yi, and Feng Jiang. 2025. AD-DINO: Attention-Dynamic DINO for Distance-Aware Embodied Reference Understanding.IEEE Transactions on Circuits and Systems for Video Technology(2025), 1–11
2025
- [13]
-
[14]
Sandeep Gupta, Carsten Maple, Bruno Crispo, Kiran Raja, Artsiom Yautsiukhin, and Fabio Martinelli. 2023. A Survey of Human-Computer Interaction (HCI) & Natural Habits-Based Behavioural Biometric Modalities for User Recognition Schemes.Pattern Recognition139 (2023), 109453
2023
-
[15]
Zeyu Han, Fangrui Zhu, Qianru Lao, and Huaizu Jiang. 2024. Zero-Shot Refer- ring Expression Comprehension via Structural Similarity Between Images and Captions. InIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR ’24). 14364–14374
2024
-
[16]
Berg, and Vicente Ordonez
Ruozhen He, Paola Cascante-Bonilla, Ziyan Yang, Alexander C. Berg, and Vicente Ordonez. 2024. Improved Visual Grounding Through Self-Consistent Explana- tions. InIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR ’24). 13095–13105
2024
- [17]
- [18]
-
[19]
Kritika Johari, Christopher Tay Zi Tong, Vigneshwaran Subbaraju, Jung-Jae Kim, and U-Xuan Tan. 2021. Gaze Assisted Visual Grounding. InIn Proceedings of the International Conference on Social Robotics (ICSR ’21). 191–202
2021
-
[20]
Mark Johnson. 2015. Embodied Understanding.Frontiers in Psychology6 (2015), 875
2015
-
[21]
Gloria Yi-Ming Kao and Cheng-An Ruan. 2022. Designing and Evaluating a High Interactive Augmented Reality System for Programming Learning.Computers in Human Behavior132 (2022), 107245
2022
- [22]
-
[23]
Sven Kreiss, Lorenzo Bertoni, and Alexandre Alahi. 2021. OpenPifPaf: Composite Fields for Semantic Keypoint Detection and Spatio-Temporal Association.IEEE Transactions on Intelligent Transportation Systems23, 8 (2021), 13498–13511
2021
-
[24]
Georgios Lampropoulos. 2025. Intelligent Virtual Reality and Augmented Reality Technologies: An Overview.Future Internet17, 2 (2025), 58
2025
- [25]
-
[26]
Liunian Harold Li, Pengchuan Zhang, Haotian Zhang, Jianwei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, et al
-
[27]
InIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR ’22)
Grounded Language-Image Pre-Training. InIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR ’22). 10965–10975
-
[28]
Yang Li, Xiaoxue Chen, Hao Zhao, Jiangtao Gong, Guyue Zhou, Federico Rossano, and Yixin Zhu. 2023. Understanding Embodied Reference With Touch-Line Transformer. InIn Proceedings of the 11th International Conference on Learning Representations (ICLR ’23). 1–15
2023
-
[29]
Chang Liu, Henghui Ding, and Xudong Jiang. 2023. GRES: Generalized Refer- ring Expression Segmentation. InIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR ’23). 23592–23601
2023
- [30]
-
[31]
Haokun Liu, Yaonan Zhu, Kenji Kato, Atsushi Tsukahara, Izumi Kondo, Tadayoshi Aoyama, and Yasuhisa Hasegawa. 2024. Enhancing the LLM-Based Robot Ma- nipulation Through Human-Robot Collaboration.IEEE Robotics and Automation Letters9, 8 (2024), 6904–6911
2024
-
[32]
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Yang Jie, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. 2024. Grounding DINO: Mar- rying DINO With Grounded Pre-Training for Open-Set Object Detection. In In Proceedings of the 18th European Conference on Computer Vision (ECCV ’24). 38–55
2024
-
[33]
Mingcong Lu, Ruifan Li, Fangxiang Feng, Zhanyu Ma, and Xiaojie Wang. 2024. LGR-NET: Language Guided Reasoning Network for Referring Expression Com- prehension.IEEE Transactions on Circuits and Systems for Video Technology34, 8 (2024), 7771–7784
2024
-
[34]
Ziyang Lu, Yunqiang Pei, Guoqing Wang, Peiwei Li, Yang Yang, Yinjie Lei, and Heng Tao Shen. 2024. Scaneru: Interactive 3D Visual Grounding Based on Embodied Reference Understanding. InIn Proceedings of the 38th AAAI Conference on Artificial Intelligence (AAAI ’24). 3936–3944
2024
-
[35]
Zhihan Lv, Fabio Poiesi, Qi Dong, Jaime Lloret, and Houbing Song. 2022. Deep Learning for Intelligent Human-Computer Interaction.Applied Sciences12, 22 (2022), 11457
2022
-
[36]
Sarma, and Archan Misra
Atharv Mahesh Mane, Dulanga Weerakoon, Vigneshwaran Subbaraju, Sougata Sen, Sanjay E. Sarma, and Archan Misra. 2025. Ges3ViG: Incorporating Pointing Gestures Into Language-Based 3D Visual Grounding for Embodied Reference Understanding. InIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR ’25). 9017–9026
2025
-
[37]
Yuille, and Kevin Murphy
Junhua Mao, Jonathan Huang, Alexander Toshev, Oana Camburu, Alan L. Yuille, and Kevin Murphy. 2016. Generation and Comprehension of Unambiguous Object Descriptions. InIn Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR ’16). 11–20
2016
-
[38]
Nagaraja, Vlad I
Varun K. Nagaraja, Vlad I. Morariu, and Larry S. Davis. 2016. Modeling Context Between Objects for Referring Expression Understanding. InIn Proceedings of the European Conference on Computer Vision (ECCV ’16). 792–807
2016
-
[39]
Shu Nakamura, Yasutomo Kawanishi, Shohei Nobuhara, and Ko Nishino. 2023. DeePoint: Visual Pointing Recognition and Direction Estimation. InIn Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV ’23). 20577– 20587
2023
- [40]
-
[41]
Atharva Paralikar, Pavan Mantripragada, Trong Nguyen, Youness Arjoune, Raj Shekhar, and Reza Monfaredi. 2025. Robot-Assisted Ultrasound Probe Calibration for Image-Guided Interventions.International Journal of Computer Assisted Radiology and Surgery20, 5 (2025), 859–868
2025
-
[42]
Kun Qian, Zhuoyang Zhang, Wei Song, and Jianfeng Liao. 2023. GVGNet: Gaze- Directed Visual Grounding for Learning Under-Specified Object Referring Inten- tion.IEEE Robotics and Automation Letters8, 9 (2023), 5990–5997
2023
-
[43]
Yanyuan Qiao, Chaorui Deng, and Qi Wu. 2021. Referring Expression Compre- hension: A Survey of Methods and Datasets.IEEE Transactions on Multimedia23 (2021), 4426–4440
2021
-
[44]
Hamid Rezatofighi, Nathan Tsoi, JunYoung Gwak, Amir Sadeghian, Ian Reid, and Silvio Savarese. 2019. Generalized Intersection Over Union: A Metric and a Loss for Bounding Box Regression. InIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR ’19). 658–666
2019
-
[45]
Cheng Shi and Sibei Yang. 2022. Spatial and Visual Perspective-Taking via View Rotation and Relation Reasoning for Embodied Reference Understanding. InIn Proceedings of the European Conference on Computer Vision (ECCV ’22). 201–218
2022
- [46]
- [47]
-
[48]
Martin Sundermeyer, Zoltan-Csaba Marton, Maximilian Durner, Manuel Brucker, and Rudolph Triebel. 2018. Implicit 3D Orientation Learning for 6D Object Detection From RGB Images. InIn Proceedings of the European Conference on Computer Vision (ECCV ’18). 699–715
2018
-
[49]
Jinguang Tong, Jinbo Wu, Kaisiyuan Wang, Zhelun Shen, Xuan Huang, Mochu Xiang, Xuesong Li, Yingying Li, Haocheng Feng, Chen Zhao, Hang Zhou, Wei He, Chuong Nguyen, Jingdong Wang, and Hongdong Li. 2026. MVHOI: Bridge Multi-View Condition to Complex Human-Object Interaction Video Reenactment via 3D Foundation Model.arXiv preprint arXiv:2603.14686(2026)
-
[50]
Shijie Wang, Dahun Kim, Ali Taalimi, Chen Sun, and Weicheng Kuo. 2025. Learn- ing Visual Grounding From Generative Vision and Language Model. InIn Pro- ceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (W ACV ’25). 8057–8067
2025
-
[51]
Wenhui Wang, Hangbo Bao, Li Dong, Johan Bjorck, Zhiliang Peng, Qiang Liu, Kriti Aggarwal, Owais Khan Mohammed, Saksham Singhal, Subhojit Som, et al
-
[52]
InIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR ’23)
Image as a Foreign Language: BEiT Pretraining for Vision and Vision- Language Tasks. InIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR ’23). 19175–19186
-
[53]
Dulanga Weerakoon, Vigneshwaran Subbaraju, Nipuni Karumpulli, Tuan Tran, Qianli Xu, U-Xuan Tan, Joo Hwee Lim, and Archan Misra. 2020. Gesture Enhanced Comprehension of Ambiguous Human-to-Robot Instructions. InIn Proceedings of the 2020 International Conference on Multimodal Interaction (ICMI ’20). 251–259
2020
-
[54]
Changli Wu, Qi Chen, Jiayi Ji, Haowei Wang, Yiwei Ma, You Huang, Hao Fei, Xiaoshuai Sun, and Rongrong Ji. 2024. RG-SAN: Rule-Guided Spatial Awareness Network for End-to-End 3D Referring Expression Segmentation.Advances in Neural Information Processing Systems37 (2024), 110972–110999
2024
-
[55]
Yixuan Wu, Zhao Zhang, Chi Xie, Feng Zhu, and Rui Zhao. 2023. Advancing Referring Expression Segmentation Beyond Single Image. InIn Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV ’23). 2628–2638
2023
-
[56]
Linhui Xiao, Xiaoshan Yang, Fang Peng, Yaowei Wang, and Changsheng Xu. 2024. HiVG: Hierarchical Multimodal Fine-Grained Modulation for Visual Grounding. InIn Proceedings of the 32nd ACM International Conference on Multimedia (MM ’24). 5460–5469
2024
-
[57]
Linhui Xiao, Xiaoshan Yang, Fang Peng, Yaowei Wang, and Changsheng Xu. 2024. OneRef: Unified One-Tower Expression Grounding and Segmentation With Mask Referring Modeling.Advances in Neural Information Processing Systems37 (2024), 139854–139885
2024
-
[58]
Linhui Xiao, Xiaoshan Yang, Lan Xiangyuan, Yaowei Wang, and Changsheng Xu
-
[59]
Toward Visual Grounding: A Survey.IEEE Transactions on Pattern Analysis and Machine Intelligence48, 3 (2026), 2749–2771
2026
-
[60]
Jun Xu, Hanchen Wang, Jianrong Zhang, and Linqin Cai. 2022. Robust Hand Ges- ture Recognition Based on RGB-D Data for Natural Human-Computer Interaction. IEEE Access10 (2022), 54549–54562
2022
-
[61]
Yue Yang, Christoph Leuze, Brian Hargreaves, Bruce Daniel, and Fred Baik
- [62]
-
[63]
Jiawen Yi, Jiaojiao Liu, Chuanlong Zhang, and Xiong Lu. 2022. Magnetic Motion Tracking for Natural Human-Computer Interaction: A Review.IEEE Sensors Journal22, 23 (2022), 22356–22367
2022
-
[64]
Licheng Yu, Zhe Lin, Xiaohui Shen, Jimei Yang, Xin Lu, Mohit Bansal, and Tamara L. Berg. 2018. MAttNet: Modular Attention Network for Referring Expression Comprehension. InIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR ’18). 1307–1315
2018
-
[65]
Berg, and Tamara L
Licheng Yu, Patrick Poirson, Shan Yang, Alexander C. Berg, and Tamara L. Berg
-
[66]
InIn Proceedings of the European Conference on Computer Vision (ECCV ’16)
Modeling Context in Referring Expressions. InIn Proceedings of the European Conference on Computer Vision (ECCV ’16). 69–85
- [67]
-
[68]
Peizhi Zhao, Shiyi Zheng, Wenye Zhao, Dongsheng Xu, Pijian Li, Yi Cai, and Huang Qingbao. 2024. Rethinking Two-Stage Referring Expression Compre- hension: A Novel Grounding and Segmentation Method Modulated by Point. In In Proceedings of the 38th AAAI Conference on Artificial Intelligence (AAAI ’24). 7487–7495
2024
-
[69]
Yiyi Zhou, Rongrong Ji, Gen Luo, Xiaoshuai Sun, Jinsong Su, Xinghao Ding, Chia-Wen Lin, and Qi Tian. 2023. A Real-Time Global Inference Network for One-Stage Referring Expression Comprehension.IEEE Transactions on Neural Networks and Learning Systems34, 1 (2023), 134–143
2023
-
[70]
Zhishan Zhou, Shihao Zhou, Lv Zhi, Minqiang Zou, Yao Tang, and Jiajun Liang
-
[71]
A Simple Baseline for Efficient Hand Mesh Reconstruction. InIn Proceedings VistaRef: Boosting Visual Spatial Orientation Awareness for Pointing-to-Object Detection Conference acronym ’XX, June 03–05, 2018, Woodstock, NY of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR ’24). 1367–1376
2018
-
[72]
Chaoyang Zhu, Yiyi Zhou, Yunhang Shen, Gen Luo, Xingjia Pan, Mingbao Lin, Chao Chen, Liujuan Cao, Xiaoshuai Sun, and Rongrong Ji. 2022. SeqTR: A Simple Yet Universal Network for Visual Grounding. InIn Proceedings of the 17th European Conference on Computer Vision (ECCV ’22). 598–615. Received 20 February 2007; revised 12 March 2009; accepted 5 June 2009
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.