SIFT: Selective-Index For Fast Compute of RAG Prefill by Exploiting Attention Invariance
Pith reviewed 2026-06-27 16:22 UTC · model grok-4.3
The pith
SIFT computes attention only at positions marked by two compact bit vectors that encode local-attention invariance and cross-attention consistency, cutting RAG TTFT by 1.71x with accuracy loss under 1 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
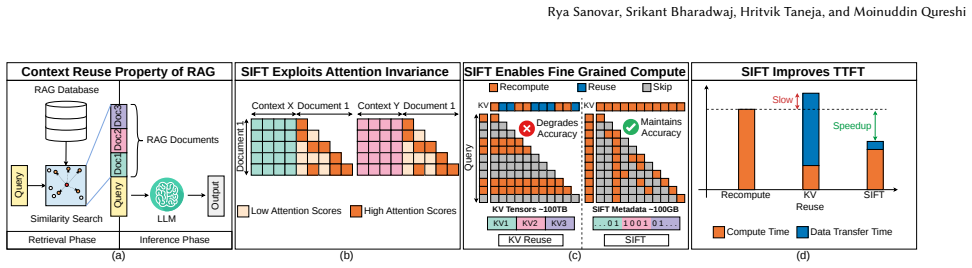
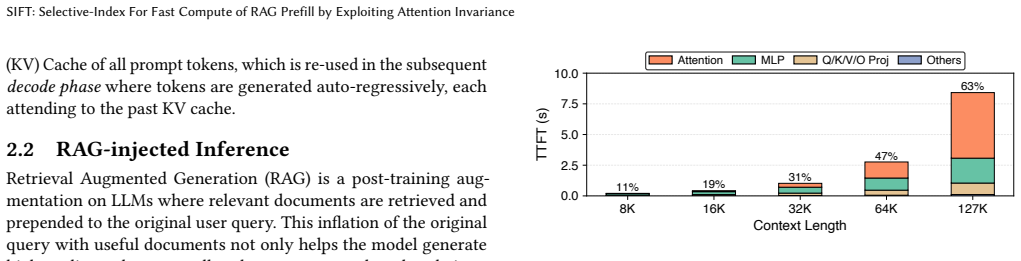
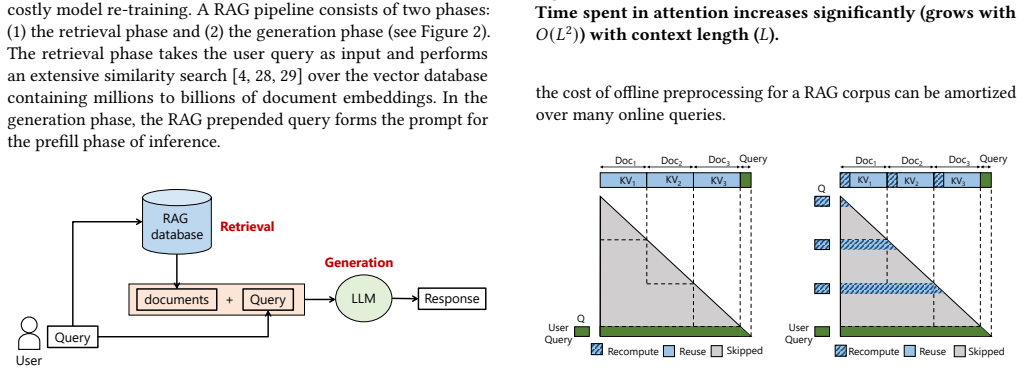
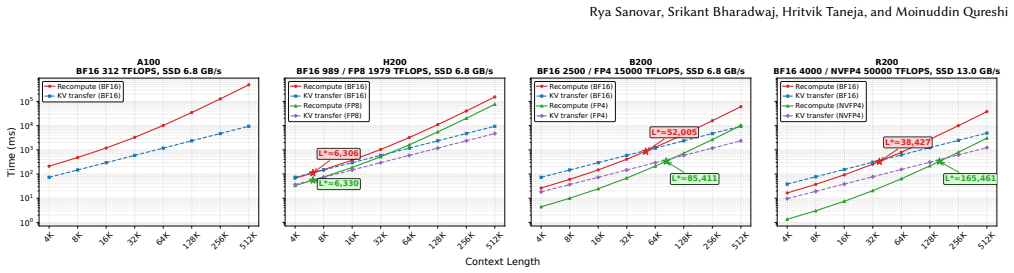
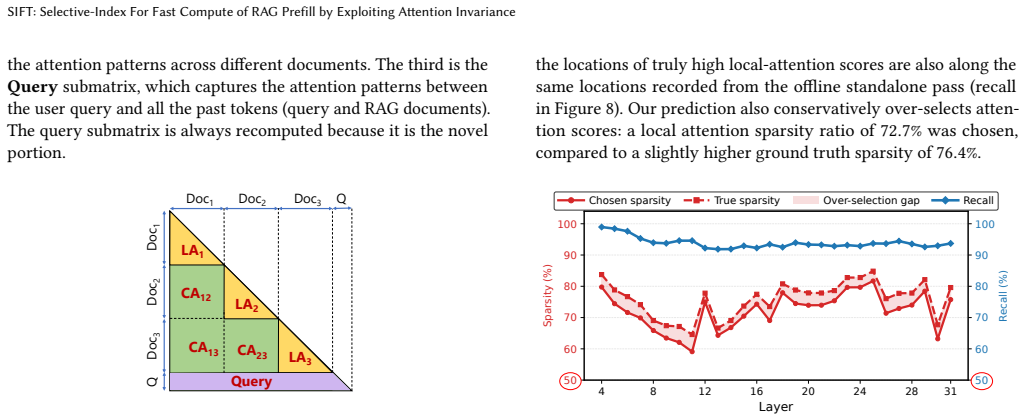
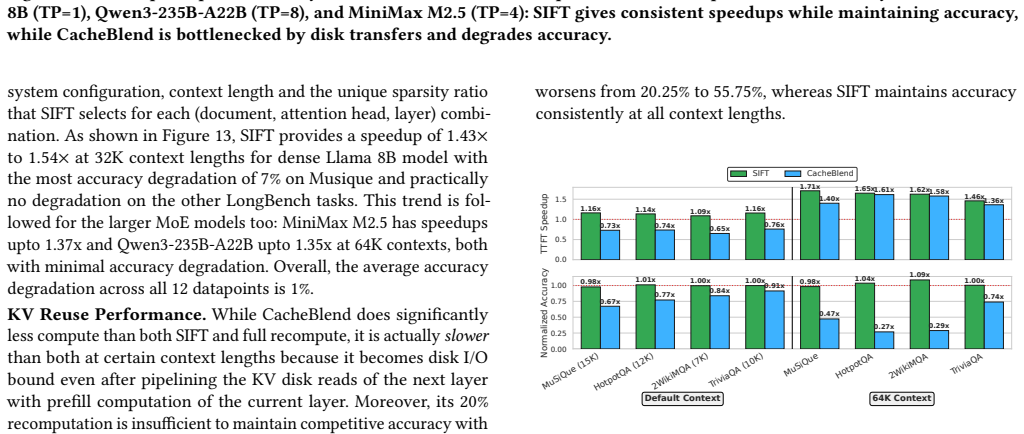
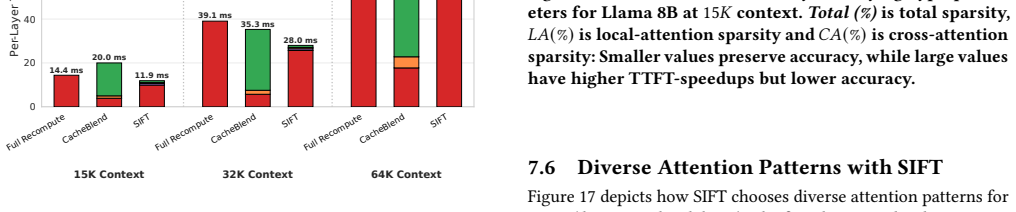
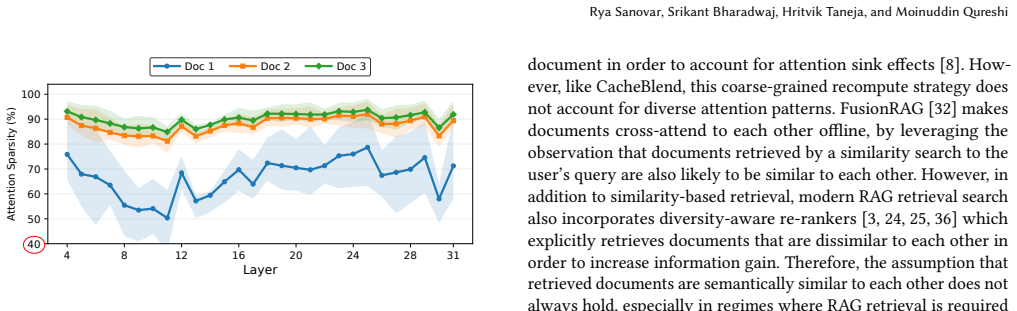
SIFT processes each RAG document offline to extract the fine-grained locations of high attention scores and encodes those locations in two compact bit vectors. One vector exploits local-attention invariance (high-score positions inside a document remain stable regardless of surrounding documents) and the other exploits cross-attention consistency (keys that score highly inside the document also receive high cross-attention from later documents). During online prefill SIFT evaluates attention only at the positions indicated by the bit vectors, improves TTFT by 1.71x, and keeps accuracy within 1 percent of full recompute while storing data 24,000 times smaller than the corresponding KV tensors
What carries the argument
Two compact bit vectors that mark the positions of high attention scores according to local-attention invariance and cross-attention consistency.
If this is right
- TTFT drops by a factor of 1.71 relative to full recompute.
- Answer accuracy remains within 1 percent of the full-recompute case.
- Storage shrinks by up to 24,000 times because only bit vectors are retained instead of KV tensors.
- High-latency disk transfers of KV data are eliminated at inference time.
- Fine-grained position selection replaces coarser recomputation strategies.
Where Pith is reading between the lines
- The same invariance pattern could be used to accelerate prefill in other repeated-context workloads such as multi-turn chat with long history.
- Combining the bit-vector index with existing KV eviction policies might further lower peak memory during extended sessions.
- The offline extraction step suggests that attention patterns can be pre-analyzed once per document collection and reused across many queries.
- Extending the method to documents longer than those tested would require checking whether the invariance holds at greater lengths.
Load-bearing premise
The positions that receive high attention inside a document stay sufficiently stable when other documents are added and the same keys also draw high cross-attention from later documents.
What would settle it
A runtime measurement on held-out queries in which the bit-vector positions diverge from the actual high-attention locations enough to push accuracy more than 1 percent below the full-recompute baseline.
Figures



read the original abstract
Retrieval-Augmented Generation (RAG) injects LLM queries with relevant documents to improve response quality. This injection increases prompt length and slows time to first token (TTFT). Unlike standard queries, RAG queries have a unique property of context reuse where the same documents recur across user queries. Thus, fully recomputing documents for every RAG query does redundant compute and increases TTFT. Prior works precompute KV tensors of RAG documents offline and coarsely recompute some tokens during online prefill. However, such KV reuse is often slower than full recomputation on modern GPUs due to high-latency disk transfers. Further, such a coarse-grained recomputation degrades accuracy. To address these limitations, this paper proposes SIFT: Selective-Index For Fast Compute of RAG Prefill by Exploiting Attention Invariance. SIFT processes documents offline and extracts fine-grained locations of high attention scores for each document. Next, we identify the following attention invariance insights that enable us to exploit the extracted locations during runtime: (1) Local-Attention Invariance: The location of high attention scores within a document remain invariant to surrounding documents. This helps us predict the location of high scores where the document attends to itself. (2) Cross-Attention Consistency: Keys with high intra-document attention also attract cross-attention from subsequent documents. This helps us predict the location of high scores where the document attends to future documents. Critically, SIFT stores no KV data and only stores locations of high scores in the form of two compact bit vectors. SIFT's storage is up to 24,000x smaller than KV tensors, obviating costly disk transfers. During prefill, SIFT computes the attention only for the marked locations and improves TTFT by 1.71x while holding accuracy within 1% of full recompute.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SIFT for accelerating RAG prefill. It pre-processes each document offline to produce two compact bit vectors marking positions of high intra-document attention scores. The method relies on two claimed invariances—local-attention invariance (high-attention locations within a document remain stable regardless of surrounding documents) and cross-attention consistency (keys receiving high intra-document attention also receive high cross-attention from later documents)—to compute attention only at the marked positions at runtime. No KV tensors are stored. The abstract reports a 1.71× TTFT improvement while keeping accuracy within 1 % of full recompute and storage 24,000× smaller than KV tensors.
Significance. If the invariance properties hold with sufficient precision, the technique would offer a storage-efficient alternative to KV caching or full recomputation for RAG workloads that reuse documents, directly addressing TTFT bottlenecks on modern GPUs. The approach is engineering-oriented and could be practically relevant if the empirical claims are substantiated with measurements of attention-mass coverage and sensitivity analysis.
major comments (2)
- [Abstract] Abstract: The central performance claims (1.71× TTFT improvement and accuracy within 1 % of full recompute) are stated without any supporting data, error bars, dataset descriptions, or quantitative validation of the two invariance properties. Because the final attention output is computed exclusively over the marked positions, any systematic mismatch in the bit vectors directly determines whether the accuracy bound holds; the absence of overlap statistics, sensitivity analysis to query content, or bounds on missed attention mass makes the accuracy claim unverifiable from the provided evidence.
- [Abstract] The manuscript asserts local-attention invariance and cross-attention consistency as enabling insights but supplies no measurement of position overlap across query variations or document combinations, nor any analysis of the fraction of important attention mass that would be missed if the invariance is imperfect. These properties are load-bearing for both the correctness of the selective computation and the claimed accuracy retention.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and for highlighting the importance of clearly substantiating the performance claims and invariance properties. We agree that the abstract can be strengthened to better convey the supporting evidence from the manuscript body. We address the comments point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central performance claims (1.71× TTFT improvement and accuracy within 1 % of full recompute) are stated without any supporting data, error bars, dataset descriptions, or quantitative validation of the two invariance properties. Because the final attention output is computed exclusively over the marked positions, any systematic mismatch in the bit vectors directly determines whether the accuracy bound holds; the absence of overlap statistics, sensitivity analysis to query content, or bounds on missed attention mass makes the accuracy claim unverifiable from the provided evidence.
Authors: We agree that the abstract would benefit from additional context to make the claims more verifiable at a glance. The full manuscript contains experimental results in the evaluation sections that report TTFT measurements with error bars across multiple RAG datasets, accuracy comparisons, and quantitative validation of the invariances including overlap statistics and attention mass coverage. We will revise the abstract to briefly reference these supporting experiments and include key quantitative metrics such as average attention mass captured. revision: yes
-
Referee: [Abstract] The manuscript asserts local-attention invariance and cross-attention consistency as enabling insights but supplies no measurement of position overlap across query variations or document combinations, nor any analysis of the fraction of important attention mass that would be missed if the invariance is imperfect. These properties are load-bearing for both the correctness of the selective computation and the claimed accuracy retention.
Authors: We agree that explicit measurements of these properties will strengthen the paper. While the manuscript supports the invariances through empirical accuracy results, we will add a dedicated analysis subsection in the revised version that quantifies position overlap across query variations and document combinations, the fraction of attention mass retained, and sensitivity to query content. revision: yes
Circularity Check
No circularity; empirical engineering technique rests on observed regularities, not equations or self-citations that reduce to inputs.
full rationale
The paper presents SIFT as an empirical method that extracts high-attention locations offline into bit vectors and reuses them at runtime under two stated invariance properties. No mathematical derivation, fitted parameters, or equations are described that would reduce a claimed prediction back to the input data by construction. The two invariance claims are presented as identified insights rather than derived results, and the provided text contains no self-citations that serve as load-bearing justification for uniqueness or ansatzes. The approach is therefore self-contained as an engineering observation whose validity is external to any internal reduction.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Can I Buy Your KV Cache?
Proposes an agent-native prefill CDN where precomputed KV caches are hosted and sold to agents, delivering 9-50x compute savings with exact token and logit matching on Qwen3-4B.
Reference graph
Works this paper leans on
-
[1]
AI@Meta. 2024. Llama 3 Model Card. (2024). https://github.com/meta-llama/ llama3/blob/main/MODEL_CARD.md
2024
-
[2]
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. 2024. LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). ...
-
[3]
Jaime Carbonell and Jade Goldstein. 1998. The use of MMR, diversity-based reranking for reordering documents and producing summaries. InProceedings of the 21st Annual International ACM SIGIR Conference on Research and Develop- ment in Information Retrieval(Melbourne, Australia)(SIGIR ’98). Association for Computing Machinery, New York, NY, USA, 335–336. d...
-
[4]
Qi Chen, Bing Zhao, Haidong Wang, Mingqin Li, Chuanjie Liu, Zengzhong Li, Mao Yang, and Jingdong Wang. 2021. SPANN: Highly-efficient Billion-scale Approximate Nearest Neighbor Search. arXiv:2111.08566 [cs.DB] https://arxiv. org/abs/2111.08566
arXiv 2021
-
[5]
Wenqi Fan, Yujuan Ding, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat-Seng Chua, and Qing Li. 2024. A Survey on RAG Meeting LLMs: Towards Retrieval-Augmented Large Language Models. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining(Barcelona, Spain) (KDD ’24). Association for Computing Machinery, New York, NY, U...
-
[6]
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Meng Wang, and Haofen Wang. 2024. Retrieval-Augmented Generation for Large Language Models: A Survey. arXiv:2312.10997 [cs.CL] https://arxiv.org/abs/2312.10997
Pith/arXiv arXiv 2024
-
[7]
In Gim, Guojun Chen, Seung seob Lee, Nikhil Sarda, Anurag Khandelwal, and Lin Zhong. 2024. Prompt Cache: Modular Attention Reuse for Low-Latency Inference. arXiv:2311.04934 [cs.CL] https://arxiv.org/abs/2311.04934
arXiv 2024
-
[8]
Xiangming Gu, Tianyu Pang, Chao Du, Qian Liu, Fengzhuo Zhang, Cunxiao Du, Ye Wang, and Min Lin. 2025. When Attention Sink Emerges in Language Mod- els: An Empirical View. InThe Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=78Nn4QJTEN
2025
-
[9]
Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Mingwei Chang
-
[10]
InProceedings of the 37th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol
Retrieval Augmented Language Model Pre-Training. InProceedings of the 37th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 119), Hal Daumé III and Aarti Singh (Eds.). PMLR, 3929–
-
[11]
https://proceedings.mlr.press/v119/guu20a.html
-
[12]
Junhao Hu, Wenrui Huang, Weidong Wang, Haoyi Wang, Tiancheng Hu, Qin Zhang, Hao Feng, Xusheng Chen, Yizhou Shan, and Tao Xie. 2025. EPIC: Efficient Position-Independent Caching for Serving Large Language Models. arXiv:2410.15332 [cs.LG] https://arxiv.org/abs/2410.15332
arXiv 2025
-
[13]
Abdi, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, and Lili Qiu
Huiqiang Jiang, Yucheng Li, Chengruidong Zhang, Qianhui Wu, Xufang Luo, Surin Ahn, Zhenhua Han, Amir H. Abdi, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. 2024. MInference 1.0: Accelerating Pre-filling for Long- Context LLMs via Dynamic Sparse Attention. arXiv:2407.02490 [cs.CL] https: //arxiv.org/abs/2407.02490
arXiv 2024
-
[14]
Wenqi Jiang, Shuai Zhang, Boran Han, Jie Wang, Bernie Wang, and Tim Kraska
-
[15]
arXiv:2403.05676 [cs.CL] https://arxiv.org/abs/2403.05676
PipeRAG: Fast Retrieval-Augmented Generation via Algorithm-System Co-design. arXiv:2403.05676 [cs.CL] https://arxiv.org/abs/2403.05676
-
[16]
Chao Jin, Zili Zhang, Xuanlin Jiang, Fangyue Liu, Xin Liu, Xuanzhe Liu, and Xin Jin. 2024. RAGCache: Efficient Knowledge Caching for Retrieval-Augmented Generation. arXiv:2404.12457 [cs.DC] https://arxiv.org/abs/2404.12457
arXiv 2024
-
[17]
Junkyum Kim and Divya Mahajan. 2026. VectorLiteRAG: Latency-Aware and Fine-Grained Resource Partitioning for Efficient RAG. arXiv:2504.08930 [cs.LG] https://arxiv.org/abs/2504.08930
arXiv 2026
-
[18]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. 2023. Efficient Memory Management for Large Language Model Serving with PagedAtten- tion. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles
2023
-
[19]
Xunhao Lai, Jianqiao Lu, Yao Luo, Yiyuan Ma, and Xun Zhou. 2025. FlexPrefill: A Context-Aware Sparse Attention Mechanism for Efficient Long-Sequence Inference. arXiv:2502.20766 [cs.LG] https://arxiv.org/abs/2502.20766
arXiv 2025
-
[20]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2021. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. arXiv:2005.11401 [cs.CL] https://arxiv.org/abs/2005.11401
Pith/arXiv arXiv 2021
-
[21]
Chien-Yu Lin, Keisuke Kamahori, Yiyu Liu, Xiaoxiang Shi, Madhav Kashyap, Yile Gu, Rulin Shao, Zihao Ye, Kan Zhu, Rohan Kadekodi, Stephanie Wang, Arvind Krishnamurthy, Luis Ceze, and Baris Kasikci. 2025. TeleRAG: Effi- cient Retrieval-Augmented Generation Inference with Lookahead Retrieval. arXiv:2502.20969 [cs.DC] https://arxiv.org/abs/2502.20969
Pith/arXiv arXiv 2025
-
[22]
Yuhan Liu, Yihua Cheng, Jiayi Yao, Yuwei An, Xiaokun Chen, Shaoting Feng, Yuyang Huang, Samuel Shen, Rui Zhang, Kuntai Du, and Junchen Jiang. 2025. LMCache: An Efficient KV Cache Layer for Enterprise-Scale LLM Inference. arXiv:2510.09665 [cs.LG] https://arxiv.org/abs/2510.09665
arXiv 2025
-
[23]
Songshuo Lu, Hua Wang, Yutian Rong, Zhi Chen, and Yaohua Tang. 2024. TurboRAG: Accelerating Retrieval-Augmented Generation with Precomputed KV Caches for Chunked Text. arXiv:2410.07590 [cs.CV] https://arxiv.org/abs/ 2410.07590
arXiv 2024
-
[24]
Micron. 2026. Micron 7450 NVMe SSD Datasheet. https://www.micron.com/ products/storage/ssd/data-center-ssd/7450-ssd. Accessed: 2026-04-11
2026
-
[25]
MiniMax. 2025. MiniMax-01: Scaling Foundation Models with Lightning Atten- tion.arXiv preprint arXiv:2501.08313(2025)
Pith/arXiv arXiv 2025
-
[26]
NVIDIA. 2026. NVIDIA H200 GPU. https://www.nvidia.com/en-us/data-center/ h200/. Accessed: 2026-04-11
2026
-
[27]
OpenSearch Project. 2026. Vector search with MMR reranking. https: //docs.opensearch.org/latest/vector-search/specialized-operations/vector- search-mmr/. Accessed: 2026-04-11
2026
-
[28]
Marc Pickett, Jeremy Hartman, Ayan Kumar Bhowmick, Raquib ul Alam, and Aditya Vempaty. 2025. Better RAG using Relevant Information Gain. arXiv:2407.12101 [cs.CL] https://arxiv.org/abs/2407.12101
arXiv 2025
-
[29]
Ori Ram, Yoav Levine, Itay Dalmedigos, Dor Muhlgay, Amnon Shashua, Kevin Leyton-Brown, and Yoav Shoham. 2023. In-Context Retrieval-Augmented Lan- guage Models. arXiv:2302.00083 [cs.CL] https://arxiv.org/abs/2302.00083
arXiv 2023
-
[30]
Jay Shah, Ganesh Bikshandi, Ying Zhang, Vijay Thakkar, Pradeep Ramani, and Tri Dao. 2024. FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision. arXiv:2407.08608 [cs.LG] https://arxiv.org/abs/2407.08608
Pith/arXiv arXiv 2024
-
[31]
Josef Sivic and Andrew Zisserman. 2003. Video Google: A Text Retrieval Ap- proach to Object Matching in Videos. InProceedings of the Ninth IEEE Inter- national Conference on Computer Vision - Volume 2 (ICCV ’03). IEEE Computer Society, USA, 1470
2003
-
[32]
2019.DiskANN: fast accurate billion- point nearest neighbor search on a single node
Suhas Jayaram Subramanya, Devvrit, Rohan Kadekodi, Ravishankar Kr- ishaswamy, and Harsha Vardhan Simhadri. 2019.DiskANN: fast accurate billion- point nearest neighbor search on a single node. Curran Associates Inc., Red Hook, NY, USA
2019
-
[33]
Qwen Team. 2025. Qwen3 Technical Report. arXiv:2505.09388 [cs.CL] https: //arxiv.org/abs/2505.09388
Pith/arXiv arXiv 2025
-
[34]
Dean Wampler, Dave Nielson, and Alireza Seddighi. 2025. Engineering the RAG Stack: A Comprehensive Review of the Architecture and Trust Frameworks for Retrieval-Augmented Generation Systems. arXiv:2601.05264 [cs.IR] https: //arxiv.org/abs/2601.05264
arXiv 2025
-
[35]
Jiahao Wang, Weiyu Xie, Mingxing Zhang, Boxin Zhang, Jianwei Dong, Yuening Zhu, Chen Lin, Jingqi Tang, Yaochen Han, Zhiyuan Ai, Xianglin Chen, Yongwei Wu, and Congfeng Jiang. 2026. From Prefix Cache to Fusion RAG Cache: Accel- erating LLM Inference in Retrieval-Augmented Generation.Proceedings of the ACM on Management of Data4, 1 (April 2026), 1–28. doi:1...
-
[36]
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. 2024. Efficient Streaming Language Models with Attention Sinks. arXiv:2309.17453 [cs.CL] https://arxiv.org/abs/2309.17453
Pith/arXiv arXiv 2024
-
[37]
Jingbo Yang, Bairu Hou, Wei Wei, Yujia Bao, and Shiyu Chang. 2025. KVLink: Accelerating Large Language Models via Efficient KV Cache Reuse. arXiv:2502.16002 [cs.CL] https://arxiv.org/abs/2502.16002
arXiv 2025
-
[38]
Jiayi Yao, Hanchen Li, Yuhan Liu, Siddhant Ray, Yihua Cheng, Qizheng Zhang, Kuntai Du, Shan Lu, and Junchen Jiang. 2025. CacheBlend: Fast Large Language Model Serving for RAG with Cached Knowledge Fusion. arXiv:2405.16444 [cs.LG] https://arxiv.org/abs/2405.16444
arXiv 2025
-
[39]
Tong Zhou. 2025. Knowledge-Aware Diverse Reranking for Cross-Source Ques- tion Answering. arXiv:2506.20476 [cs.CL] https://arxiv.org/abs/2506.20476
arXiv 2025
-
[40]
Qianchao Zhu, Jiangfei Duan, Chang Chen, Siran Liu, Guanyu Feng, Xin Lv, Xiao Chuanfu, Dahua Lin, and Chao Yang. 2025. SampleAttention: Near-Lossless Acceleration of Long Context LLM Inference with Adaptive Structured Sparse Attention. arXiv:2406.15486 [cs.CL] https://arxiv.org/abs/2406.15486
arXiv 2025
-
[41]
Justin Zobel and Alistair Moffat. 2006. Inverted files for text search engines. ACM Comput. Surv.38, 2 (July 2006), 6–es. doi:10.1145/1132956.1132959
-
[42]
Nicolas Zucchet, Francesco d’Angelo, Andrew K. Lampinen, and Stephanie C. Y. Chan. 2025. The emergence of sparse attention: impact of data distribution and benefits of repetition. arXiv:2505.17863 [cs.LG] https://arxiv.org/abs/2505.17863 12
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.