ROMEVA: Geometry-Preserving Vocabulary Expansion for Roman Urdu Language Models
Pith reviewed 2026-06-26 10:33 UTC · model grok-4.3
The pith
ROMEVA preserves pretrained embeddings best during vocabulary expansion for Roman Urdu, but naive fine-tuning achieves stronger sentiment classification performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
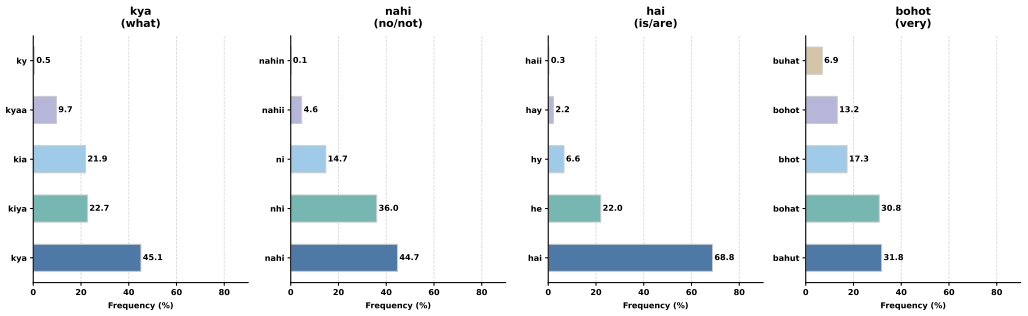
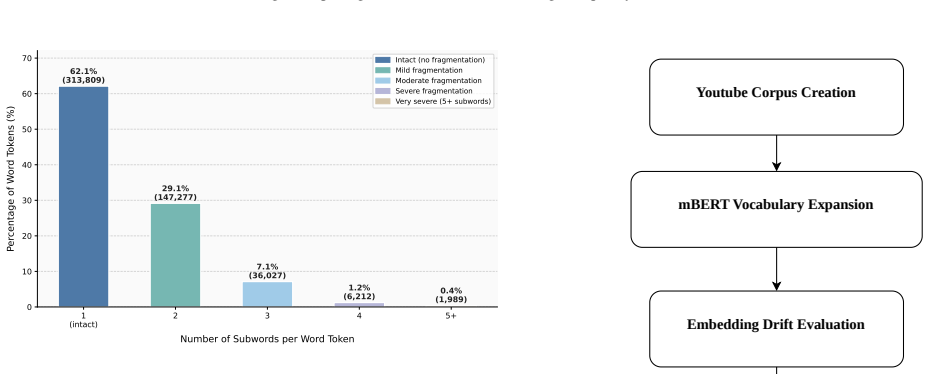
The central claim is that ROMEVA, which combines sub-word-average initialization with a PCA-guided anchor loss, most effectively preserves the geometry of mBERT's pretrained embedding space when 500 highly fragmented tokens are added from a Roman Urdu corpus. In contrast, naive fine-tuning without these constraints produces the highest accuracy on downstream sentiment classification, revealing that embedding stability and task performance can move in opposite directions for morphologically inconsistent languages.
What carries the argument
ROMEVA's sub-word-average initialization paired with a PCA-guided anchor loss that stabilizes new token embeddings relative to the original space during vocabulary expansion.
If this is right
- ROMEVA keeps new embeddings closer to the original space than naive fine-tuning or sub-word-aware fine-tuning.
- Naive fine-tuning produces the strongest results on Roman Urdu sentiment classification despite larger embedding shifts.
- Embedding preservation during vocabulary expansion does not automatically translate to better task performance in this setting.
- Stronger adaptation may be preferable to strict embedding preservation for languages with high spelling inconsistency.
Where Pith is reading between the lines
- The observed trade-off could appear when adapting models to other languages that show similar orthographic variation.
- Future adaptation techniques might deliberately allow limited embedding drift rather than anchoring new tokens.
- Evaluating vocabulary expansion methods should routinely measure both geometric stability and end-task accuracy instead of one alone.
Load-bearing premise
The 36,130-comment corpus and the choice of 500 most-fragmented tokens provide a representative sample of Roman Urdu spelling variation sufficient to support general claims about adaptation strategies for the language.
What would settle it
A larger or more diverse Roman Urdu corpus where ROMEVA yields higher sentiment classification accuracy than naive fine-tuning would falsify the claimed disconnect between embedding preservation and downstream performance.
Figures
read the original abstract
Multilingual Language Models like mBERT are widely used for low-resource NLP, yet their adaptation to morphologically inconsistent languages such as Roman Urdu remains underexplored. Roman Urdu spelling variation causes severe sub-word fragmentation, averaging 1.50 sub-words per token. We propose \textit{ROMEVA} (Roman Urdu Embedding-preserving Vocabulary Adaptation), which combines sub-word-average initialization and a PCA-guided anchor loss to stabilize embeddings during vocabulary expansion. Using a 36,130-comment Roman Urdu corpus, we add 500 highly fragmented tokens to mBERT and compare naive fine-tuning, sub-word-aware fine-tuning, and \textit{ROMEVA}. While \textit{ROMEVA} most effectively preserves the pretrained embedding space, naive fine-tuning achieves the strongest downstream sentiment classification performance. These findings reveal a disconnect between embedding stability and downstream performance, suggesting that stronger adaptation may be preferable to strict embedding preservation in morphologically inconsistent languages.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ROMEVA, a method for expanding mBERT's vocabulary for Roman Urdu that initializes new token embeddings as averages of their sub-word pieces and applies a PCA-guided anchor loss during fine-tuning to preserve the geometry of the original embedding space. On a 36,130-comment corpus, the authors add the 500 most-fragmented tokens and compare ROMEVA against naive fine-tuning and sub-word-aware fine-tuning; they report that ROMEVA best preserves embedding stability while naive fine-tuning achieves the highest sentiment classification accuracy, from which they conclude that strict embedding preservation may be suboptimal for morphologically inconsistent languages.
Significance. If the reported performance gap is statistically reliable, the work usefully documents a potential trade-off between embedding-space stability and downstream utility when adapting multilingual models to languages with high spelling variation. The direct head-to-head comparison of three adaptation strategies is a clear strength and could inform practical choices for low-resource settings.
major comments (2)
- [Abstract / Experimental results] Abstract and experimental results: the headline claim that 'naive fine-tuning achieves the strongest downstream sentiment classification performance' is presented without error bars, statistical significance tests, exact metric definitions (e.g., accuracy vs. F1), or implementation details of the baselines. Because this comparison is the sole empirical support for the asserted disconnect between embedding preservation and task performance, the absence of these elements makes the central conclusion difficult to evaluate.
- [Abstract / Data description] Data and token selection: the generalization that 'stronger adaptation may be preferable to strict embedding preservation in morphologically inconsistent languages' rests on a single 36,130-comment corpus and the extreme tail of 500 most-fragmented tokens. No justification is given that this sample captures the relevant distribution of Roman Urdu spelling variation across platforms or topics, so the observed disconnect could be an artifact of the chosen data rather than a reliable signal about adaptation strategy.
minor comments (1)
- [Method] The precise formulation of the PCA-guided anchor loss (including how the anchor points are chosen and the weighting hyper-parameter) should be stated explicitly with an equation reference so that the geometry-preservation claim can be reproduced.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater statistical rigor and clearer scoping of the empirical claims. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract / Experimental results] Abstract and experimental results: the headline claim that 'naive fine-tuning achieves the strongest downstream sentiment classification performance' is presented without error bars, statistical significance tests, exact metric definitions (e.g., accuracy vs. F1), or implementation details of the baselines. Because this comparison is the sole empirical support for the asserted disconnect between embedding preservation and task performance, the absence of these elements makes the central conclusion difficult to evaluate.
Authors: We agree that the abstract would benefit from more explicit statistical support. The full manuscript defines the evaluation metric as accuracy (Section 4.2) and details baseline implementations in the experimental setup (Section 4.1). In revision we will add error bars computed over five random seeds, report paired t-test p-values for the performance differences, and include a brief note on metric choice in the abstract itself. revision: yes
-
Referee: [Abstract / Data description] Data and token selection: the generalization that 'stronger adaptation may be preferable to strict embedding preservation in morphologically inconsistent languages' rests on a single 36,130-comment corpus and the extreme tail of 500 most-fragmented tokens. No justification is given that this sample captures the relevant distribution of Roman Urdu spelling variation across platforms or topics, so the observed disconnect could be an artifact of the chosen data rather than a reliable signal about adaptation strategy.
Authors: The 36,130-comment corpus was selected as a representative social-media sample exhibiting high spelling variation; the 500 tokens were the most sub-word-fragmented under mBERT tokenization to isolate the core phenomenon. We acknowledge that a single corpus limits broad generalization. In revision we will add a dedicated Limitations paragraph clarifying that the reported trade-off is a case-study observation on this dataset and should be treated as a hypothesis for further multi-corpus validation rather than a definitive claim about all morphologically inconsistent languages. revision: partial
Circularity Check
No circularity: results are direct empirical comparisons on held-out data
full rationale
The paper reports empirical measurements of embedding stability (via geometry metrics) and downstream sentiment classification accuracy after vocabulary expansion on a held-out test set. No equations, fitted parameters, or self-citations are used to derive the reported performance numbers; the central claim (ROMEVA preserves geometry better yet underperforms naive fine-tuning) follows directly from the experimental outcomes rather than reducing to any input by construction. The representativeness concern raised in the skeptic note is a question of external validity, not circularity in the derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
BERT: Pre-training of deep bidirectional transformers for language understanding,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of deep bidirectional transformers for language understanding,” in Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Minneapolis, Minnesota: Association for Co...
2019
-
[2]
Roman urdu hate speech detection using transformer-based model for cyber security applications,
M. Bilal, A. Khan, S. Jan, S. Musa, and S. Ali, “Roman urdu hate speech detection using transformer-based model for cyber security applications,” Sensors, vol. 23, no. 8, p. 3909, 2023
2023
-
[3]
Don’t stop pretraining: Adapt language models to domains and tasks,
S. Gururangan, A. Marasovic, S. Swayamditta, K. Lo, I. Beltagy, D. Downey, and N. A. Smith, “Don’t stop pretraining: Adapt language models to domains and tasks,” inProceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Online: Association for Computational Linguistics, 2020, pp. 8342–8360. [Online]. Available: https://acl...
2020
-
[4]
Neural machine translation of rare words with subword units,
R. Sennrich, B. Haddow, and A. Birch, “Neural machine translation of rare words with subword units,” inProceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Berlin, Germany: Association for Computational Linguistics, 2016, pp. 1715–1725. [Online]. Available: https://aclanthology.org/P16-1162
2016
-
[5]
SentencePiece: A simple and language independent subword tokenizer and detokenizer for neural text processing,
T. Kudo and J. Richardson, “SentencePiece: A simple and language independent subword tokenizer and detokenizer for neural text processing,” inProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. Brussels, Belgium: Association for Computational Linguistics, 2018. [Online]. Available: https://aclanth...
2018
-
[6]
Hate-speech and offensive language detection in roman urdu,
H. Rizwan, M. H. Shakeel, and A. Karim, “Hate-speech and offensive language detection in roman urdu,” inProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2020, pp. 2512–2522
2020
-
[7]
Leveraging multilingual transformer for multiclass sentiment analysis in code-mixed data of low-resource languages,
M. K. Nazir, C. N. Faisal, M. A. Habib, and H. Ahmad, “Leveraging multilingual transformer for multiclass sentiment analysis in code-mixed data of low-resource languages,”IEEE Access, vol. 13, pp. 7538–7554, 2025
2025
-
[8]
A dataset of roman urdu text with spelling variations for sentence level sentiment analysis,
M. A. Soomro, R. N. Memon, A. A. Chandio, M. Leghari, and M. H. Soomro, “A dataset of roman urdu text with spelling variations for sentence level sentiment analysis,”Data in Brief, vol. 57, p. 111170, 2024
2024
-
[9]
J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ramalho, A. Grabska-Barwinska, D. Hassabis, C. Clopath, D. Kumaran, and R. Hadsell, “Overcoming catastrophic forgetting in neural networks,”Proceedings of the National Academy of Sciences, vol. 114, no. 13, pp. 3521–3526, 2017. [Online]. Available: https...
-
[10]
All-but-the-top: Simple and effective postprocessing for word representations,
J. Mu and P. Viswanath, “All-but-the-top: Simple and effective postprocessing for word representations,” inProceedings of the 6th International Conference on Learning Representations, 2018. [Online]. Available: https://openreview.net/forum?id=HkuGJ3kCb
2018
-
[11]
How contextual are contextualized word representations? Revisiting the geometry of BERT, ELMo, and GPT-2,
K. Ethayarajh, “How contextual are contextualized word representations? Revisiting the geometry of BERT, ELMo, and GPT-2,” inProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. Hong Kong, China: Association for Computational Linguistics, 2019. [Online]. Available: https://aclanthology.org/D19-1006
2019
-
[12]
UNLT: Urdu natural language toolkit,
J. Shafi, H. R. Iqbal, R. M. A. Nawab, and P. Rayson, “UNLT: Urdu natural language toolkit,”Natural Language Engineering, vol. 29, no. 4, pp. 942–977, 2023
2023
-
[13]
PIT: A dynamic personalized item tokenizer for end-to-end generative recommendation,
H. Wang, X. Luo, H. Bao, Z. Zhang, L. Ren, Y . Wu, H. Zhang, L. Guan, and G. Chen, “PIT: A dynamic personalized item tokenizer for end-to-end generative recommendation,” 2025. [Online]. Available: https://arxiv.org/abs/2602.08530
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.