Civil Court Simulation with Large Language Models
Pith reviewed 2026-06-27 16:43 UTC · model grok-4.3
The pith
A multi-agent LLM framework organizes Chinese civil trials into five stages and produces reliable judgments on liability and remedies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
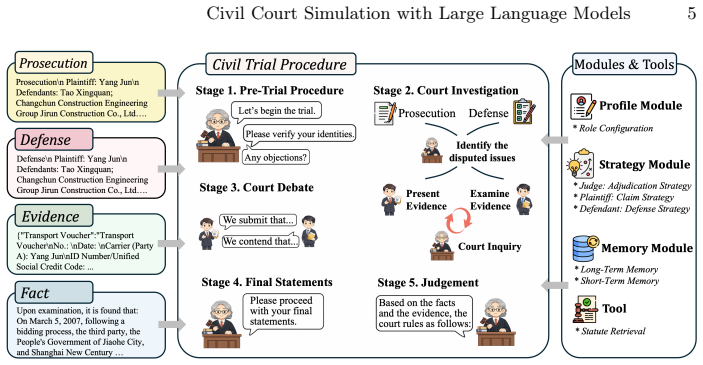
The central claim is that a multi-agent court simulation framework for Chinese civil cases, organized through a five-stage civil trial procedure and integrating memory module and statute retrieval, produces reliable civil judgments with clear strengths in liability allocation and multi-item adjudication.
What carries the argument
Multi-agent LLM role interactions structured by a five-stage civil trial procedure, supported by a memory module and statute retrieval.
If this is right
- The framework allows scalable simulation of civil litigation for training and practice where human participants are costly.
- Memory quality directly determines the reliability of downstream judgments in long-running cases.
- A five-layer factor model can diagnose how legal grounding, information access, judicial capability, role pressures, and social context influence simulation outcomes.
- The approach extends court simulation from criminal to civil matters by accommodating variable claims and remedies.
Where Pith is reading between the lines
- The method could be used to run many parallel simulations of the same facts to estimate outcome distributions under different judicial styles.
- If the memory and retrieval components are strengthened, the system might serve as a testbed for how changes in evidence presentation affect final awards.
- Similar role-based structures could be applied to other flexible decision domains such as regulatory negotiations or insurance disputes.
Load-bearing premise
The five-stage civil trial procedure plus LLM role interactions sufficiently capture the flexibility of real civil claims, liability, and remedies.
What would settle it
Blind expert comparison of the simulated judgments against actual civil case records, measuring agreement on liability shares and remedy amounts.
Figures


read the original abstract
Court simulation bridges legal education and judicial practice, yet human-based simulations are costly and difficult to scale. Large language models (LLMs) offer a scalable alternative, but existing court-simulation research mainly focuses on criminal cases. Civil litigation is more common in practice and harder to simulate because its claims, liability, and remedies are more flexible. We present a multi-agent court simulation framework for Chinese civil cases. The framework organizes role-based interaction through a five-stage civil trial procedure and integrates memory module and statute retrieval to support long-process adjudication. Experiments show that the framework produces reliable civil judgments, with clear strengths in liability allocation and multi-item adjudication. Further experiments show that memory quality substantially affects downstream simulation quality. Through a five-layer factor framework, we analyze how legal grounding, information conditions, judicial capability and role orientation, organizational pressure, and social context affect the framework's reliability and behavior. These results support the effectiveness of the proposed framework for civil court simulation. The dataset and code are available at: https://github.com/foggpoy/Civil-Court.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a multi-agent LLM framework for simulating Chinese civil court cases. It structures interactions via a five-stage civil trial procedure, incorporates memory modules and statute retrieval, and reports that experiments demonstrate reliable civil judgments particularly in liability allocation and multi-item adjudication. A five-layer factor framework is used to analyze influences on reliability, and the dataset and code are made available.
Significance. Should the experimental claims hold under rigorous validation, the work offers a scalable alternative to human-based simulations for civil litigation, filling a gap since most prior work focuses on criminal cases. The public availability of code and data strengthens reproducibility.
major comments (3)
- [Abstract] Abstract: the claim that 'experiments show that the framework produces reliable civil judgments, with clear strengths in liability allocation and multi-item adjudication' supplies no metrics, baselines, sample sizes, or validation against real judgments, so the central experimental claim cannot be assessed.
- [Framework description] Framework description and experiments: no comparison to actual court records, blinded expert review, or inter-rater metrics with human judges is described, so the assertion that outputs are 'reliable' in a legal sense does not follow from internal consistency or statute retrieval alone.
- [Framework description] Five-stage procedure: the assumption that this procedure plus LLM role interactions sufficiently captures the flexibility of real civil claims, liability, and remedies is not tested against external standards, which is load-bearing for the claim that the simulation is effective.
minor comments (1)
- [Abstract] The abstract would benefit from a brief quantitative summary of the reported experimental outcomes (e.g., agreement rates or accuracy figures) to allow readers to gauge the strength of the results immediately.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point by point below, clarifying the basis for our experimental claims while agreeing to revisions where the manuscript can be strengthened.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'experiments show that the framework produces reliable civil judgments, with clear strengths in liability allocation and multi-item adjudication' supplies no metrics, baselines, sample sizes, or validation against real judgments, so the central experimental claim cannot be assessed.
Authors: We agree the abstract would benefit from greater specificity. The manuscript's experiments consist of memory quality ablation studies and analysis through the five-layer factor framework (legal grounding, information conditions, judicial capability and role orientation, organizational pressure, and social context). We will revise the abstract to summarize these experimental components, including the number of simulated cases and the observed effects on judgment quality. revision: yes
-
Referee: [Framework description] Framework description and experiments: no comparison to actual court records, blinded expert review, or inter-rater metrics with human judges is described, so the assertion that outputs are 'reliable' in a legal sense does not follow from internal consistency or statute retrieval alone.
Authors: The reliability claims rest on the internal five-layer factor analysis and the demonstrated impact of memory modules on simulation outcomes, together with statute retrieval. We acknowledge that this does not constitute external legal validation. We will add an explicit limitations paragraph stating that the evaluation is internal and that direct comparison to real court records or blinded expert review was not performed. revision: partial
-
Referee: [Framework description] Five-stage procedure: the assumption that this procedure plus LLM role interactions sufficiently captures the flexibility of real civil claims, liability, and remedies is not tested against external standards, which is load-bearing for the claim that the simulation is effective.
Authors: The five-stage structure follows the standard Chinese civil procedure code, and the experiments show differential performance across liability allocation and multi-item decisions under varying information and memory conditions. We will revise the relevant sections to state that effectiveness is evidenced by the factor framework results rather than by direct external benchmarking, and we will note external validation as future work. revision: partial
- Direct comparison against actual court records or blinded expert review of judgments was not conducted.
Circularity Check
No circularity in framework description or experimental claims
full rationale
The paper describes a multi-agent LLM-based simulation framework for Chinese civil cases structured around a five-stage trial procedure, memory module, and statute retrieval, then reports experimental outputs on judgment reliability. No equations, parameter fits, self-definitional reductions, or load-bearing self-citations appear in the abstract or framework description that would make any result equivalent to its inputs by construction. The central claims rest on direct experimental outputs rather than renamed priors or imported uniqueness theorems.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can simulate the flexible claims, liability determinations, and remedies of civil litigation through role-based multi-agent interaction
Reference graph
Works this paper leans on
-
[1]
Law & Society Review50(3), 703–732 (2016)
Black, R.C., Owens, R.J., Wedeking, J., Wohlfarth, P.C.: The influence of public sentiment on supreme court opinion clarity. Law & Society Review50(3), 703–732 (2016)
2016
-
[2]
In: Strategy on the United States Supreme Court, pp
Brenner, S., Whitmeyer, J.M.: The legal model. In: Strategy on the United States Supreme Court, pp. 3–10. Cambridge University Press, Cambridge (2009)
2009
-
[3]
International Review of Law and Economics76, 106171 (2023)
Chang, Y.C., Chen, K.P., Liao, J.C., Lin, C.C.: Ask more, awarded more: Evidence from taiwan’s courts. International Review of Law and Economics76, 106171 (2023). https://doi.org/10.1016/j.irle.2023.106171, https://www.sciencedirect.com/science/article/pii/S0144818823000492
-
[4]
Chen, G., Fan, L., Gong, Z., Xie, N., Li, Z., Liu, Z., Li, C., Qu, Q., Alinejad- Rokny, H., Ni, S., Yang, M.: Agentcourt: Simulating court with adversarial evolv- able lawyer agents (2025), https://arxiv.org/abs/2408.08089
arXiv 2025
-
[5]
Chen, J., Li, H., Qin, M., Zhou, Y., Ren, Y., Wang, W., Liu, Y., Wu, Y., Ai, Q.: Simulating dispute mediation with llm-based agents for legal research (2025), https://arxiv.org/abs/2509.06586
arXiv 2025
-
[6]
Administration & Society55(5), 921–952 (2023)
Colaux, É., Schiffino, N., Moyson, S.: Neither the magic bullet nor the big bad wolf: A systematic review of frontline judges’ attitudes and coping re- garding managerialization. Administration & Society55(5), 921–952 (2023). https://doi.org/10.1177/00953997231157748
-
[7]
DeepSeek-AI, Liu, A., Mei, A., Lin, B., Xue, B., Wang, B., Xu, B., Wu, B., Zhang, B., Lin, C., Dong, C., Lu, C., Zhao, C., Deng, C., Xu, C., Ruan, C., Dai, D., Guo, D., Yang, D., Chen, D., Li, E., Zhou, F., Lin, F., Dai, F., Hao, G., Chen, G., Li, G., Zhang, H., Xu, H., Li, H., Liang, H., Wei, H., Zhang, H., Luo, H., Ji, H., Ding, H., Tang, H., Cao, H., G...
Pith/arXiv arXiv 2025
-
[8]
Fay, S.A.: “Out of Bounds”: The Influence of Personal and Institutionalized Bounded Rationality on Judicial Decision Making. In: Using Organizational The- ory to Study, Explain, and Understand Criminal Legal Organizations, pp. 17–33. SpringerNatureSwitzerland(2024).https://doi.org/10.1007/978-3-031-66285-0_2
-
[9]
GLM-5-Team, :, Zeng, A., Lv, X., Hou, Z., Du, Z., Zheng, Q., Chen, B., Yin, D., Ge, C., Huang, C., Xie, C., Zhu, C., Yin, C., Wang, C., Pan, G., Zeng, H., Zhang, H., Wang, H., Chen, H., Zhang, J., Jiao, J., Guo, J., Wang, J., Du, J., Wu, J., Wang, K., Li, L., Fan, L., Zhong, L., Liu, M., Zhao, M., Du, P., Dong, Q., Lu, R., Shuang-Li, Cao, S., Liu, S., Jia...
Pith/arXiv arXiv 2026
-
[10]
The Innovation 7(6), 101253 (2026) https://doi.org/10.1016/j.xinn.2025.101253
Gu, J., Jiang, X., Shi, Z., Tan, H., Zhai, X., Xu, C., Li, W., Shen, Y., Ma, S., Liu, H., Wang, S., Zhang, K., Lin, Z., Zhang, B., Ni, L., Gao, W., Wang, Y., Guo, J.: A survey on llm-as-a-judge. The In- novation p. 101253 (2026). https://doi.org/10.1016/j.xinn.2025.101253, https://www.sciencedirect.com/science/article/pii/S2666675825004564
-
[11]
Lai, J., Gan, W., Wu, J., Qi, Z., Yu, P.S.: Large language models in law: A survey (2023), https://arxiv.org/abs/2312.03718
arXiv 2023
-
[12]
In: Proceedings of the 34th Interna- Civil Court Simulation with Large Language Models 15 tional Conference on Neural Information Processing Systems
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W.t., Rocktäschel, T., Riedel, S., Kiela, D.: Retrieval-augmented generation for knowledge-intensive nlp tasks. In: Proceedings of the 34th Interna- Civil Court Simulation with Large Language Models 15 tional Conference on Neural Information Processing Sy...
2020
-
[13]
Li, D., Jiang, B., Huang, L., Beigi, A., Zhao, C., Tan, Z., Bhattacharjee, A., Jiang, Y., Chen, C., Wu, T., Shu, K., Cheng, L., Liu, H.: From gen- eration to judgment: Opportunities and challenges of llm-as-a-judge (2025), https://arxiv.org/abs/2411.16594
arXiv 2025
-
[14]
Li, H., Chen, Y., YiRan, H., Ai, Q., Chen, J., Yang, X., Yang, J., Wu, Y., Liu, Z., Liu, Y.: Lexrag: Benchmarking retrieval-augmented generation in multi-turn legal consultation conversation. In: Proceedings of the 48th In- ternational ACM SIGIR Conference on Research and Development in Infor- mation Retrieval. p. 3606–3615. SIGIR ’25, Association for Com...
-
[15]
Li, H., Shao, Y., Wu, Y., Ai, Q., Ma, Y., Liu, Y.: Lecardv2: A large- scale chinese legal case retrieval dataset. In: Proceedings of the 47th In- ternational ACM SIGIR Conference on Research and Development in Infor- mation Retrieval. p. 2251–2260. SIGIR ’24, Association for Computing Ma- chinery, New York, NY, USA (2024). https://doi.org/10.1145/3626772....
-
[16]
Li, H., Ye, J., Hu, Y., Chen, J., Ai, Q., Wu, Y., Chen, J., Chen, Y., Luo, C., Zhou, Q., Liu, Y.: Casegen: A benchmark for multi-stage legal case documents generation (2025), https://arxiv.org/abs/2502.17943
arXiv 2025
-
[17]
Luo, J., Zhang, W., Yuan, Y., Zhao, Y., Yang, J., Gu, Y., Wu, B., Chen, B., Qiao, Z., Long, Q., Tu, R., Luo, X., Ju, W., Xiao, Z., Wang, Y., Xiao, M., Liu, C., Yuan, J., Zhang, S., Jin, Y., Zhang, F., Wu, X., Zhao, H., Tao, D., Yu, P.S., Zhang, M.: Large language model agent: A survey on methodology, applications and challenges (2025), https://arxiv.org/a...
Pith/arXiv arXiv 2025
-
[18]
Generative agents: Interactive simulacra of human behavior,
Park, J.S., O’Brien, J., Cai, C.J., Morris, M.R., Liang, P., Bernstein, M.S.: Generative agents: Interactive simulacra of human behavior. In: Pro- ceedings of the 36th Annual ACM Symposium on User Interface Soft- ware and Technology. UIST ’23, Association for Computing Machin- ery, New York, NY, USA (2023). https://doi.org/10.1145/3586183.3606763, https:/...
-
[19]
https://qwen.ai/blog?id=qwen3.5 (2026)
Qwen Team: Qwen3.5: Towards native multimodal agents. https://qwen.ai/blog?id=qwen3.5 (2026)
2026
-
[20]
Indiana Law Journal90(2), 695–739 (2015), https://www.repository.law.indiana.edu/ilj/vol90/iss2/6
Rachlinski, J.J., Wistrich, A.J., Guthrie, C.: Can judges make reliable numeric judgments? distorted damages and skewed sentences. Indiana Law Journal90(2), 695–739 (2015), https://www.repository.law.indiana.edu/ilj/vol90/iss2/6
2015
-
[21]
Team, K., Bai, T., Bai, Y., Bao, Y., Cai, S.H., Cao, Y., Charles, Y., Che, H.S., Chen, C., Chen, G., Chen, H., Chen, J., Chen, J., Chen, J., Chen, J., Chen, K., Chen, L., Chen, R., Chen, X., Chen, Y., Chen, Y., Chen, Y., Chen, Y., Chen, Y., Chen, Y., Chen, Y., Chen, Y., Chen, Z., Chen, Z., Cheng, D., Chu, M., Cui, J., Deng, J., Diao, M., Ding, H., Dong, M...
Pith/arXiv arXiv 2026
-
[22]
Wojciechowski, B.W., White, L.C., Allefeld, C., Pothos, E.M.: Order effects and the evaluation bias in legal decision making. Decision12(3), 246–267 (2025). https://doi.org/10.1037/dec0000263
-
[23]
Wu, Q., Bansal, G., Zhang, J., Wu, Y., Li, B., Zhu, E., Jiang, L., Zhang, X., Zhang, S., Liu, J., Awadallah, A.H., White, R.W., Burger, D., Wang, C.: Au- togen: Enabling next-gen llm applications via multi-agent conversation (2023), https://arxiv.org/abs/2308.08155
Pith/arXiv arXiv 2023
-
[24]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., Zheng, C., Liu, D., Zhou, F., Huang, F., Hu, F., Ge, H., Wei, H., Lin, H., Tang, J., Yang, J., Tu, J., Zhang, J., Yang, J., Yang, J., Zhou, J., Zhou, J., Lin, J., Dang, K., Bao, K., Yang, K., Yu, L., Deng, L., Li, M., Xue, M., Li, M., Zhang, P., Wang, P., Zhu, Q...
Pith/arXiv arXiv 2025
-
[25]
Zhang, K., Li, J., Wu, Y., Li, H., Luo, C., Zou, S., Zhou, Y., Su, W., Ai, Q., Liu, Y.: Chinese court simulation with llm-based agent system (2025), https://arxiv.org/abs/2508.17322
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.