PCB-QA: Evaluating LLMs over the First Printed Circuit Board Design Question-Answer Dataset
Pith reviewed 2026-06-27 08:13 UTC · model grok-4.3
The pith
A JSON textual format lets LLMs answer PCB design questions at 93 percent accuracy on a new benchmark of 480 pairs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that LLMs can understand and answer questions about printed circuit board designs when the designs are supplied in a JSON-based textual format, with Gemini 3 Flash Preview reaching 93 percent accuracy on the PCB-QA dataset of 480 pairs drawn from eight projects of varying complexity; native graphical PDFs and KiCAD files produce lower scores, establishing that text representations are usable for LLM evaluation in PCB tasks.
What carries the argument
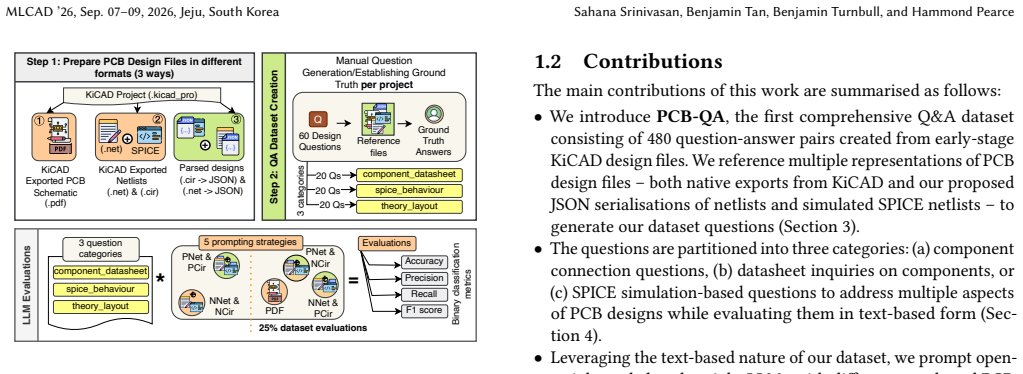
The PCB-QA dataset of 480 manually authored question-answer pairs that probe component connections, datasheet details, and SPICE simulation outputs, paired with experiments that feed LLMs the same designs in PDF, KiCAD, and JSON forms.
If this is right
- Text-based formats such as the proposed JSON representation outperform graphical and native file formats for LLM comprehension of schematics and netlists.
- Commercial models can be benchmarked on PCB tasks for the first time using this dataset.
- The open questionnaire enables repeated evaluation of future LLMs on board design questions.
- LLM assistance becomes feasible for routine PCB checks involving connections and simulation data.
Where Pith is reading between the lines
- Design tools could embed the JSON format and an LLM to flag connection errors before fabrication.
- Extending the dataset to include more layers or proprietary boards would test whether the 93 percent result generalizes.
- The same prompting approach might apply to other hardware formats such as FPGA or mechanical CAD files.
Load-bearing premise
The 480 question-answer pairs drawn from eight projects of varying complexities are representative of real PCB design tasks and the chosen file representations fairly measure what LLMs actually understand.
What would settle it
Running the same four LLMs on a fresh collection of PCB projects that include multi-layer boards or designs absent from the original eight would show whether accuracy stays near 93 percent or falls sharply.
Figures

read the original abstract
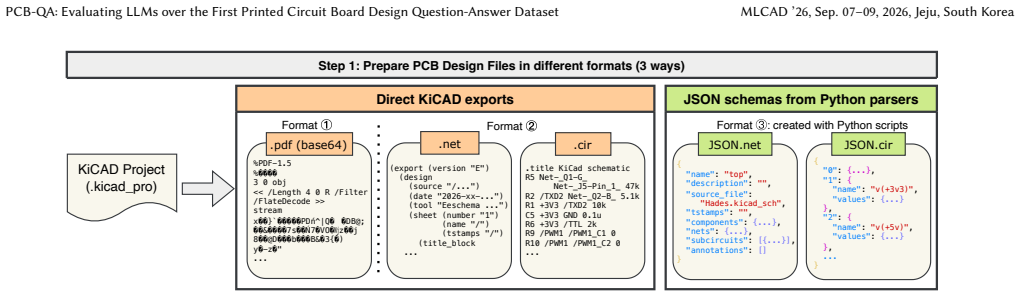
Large Language Models (LLMs) have demonstrated capabilities in electronic design automation (EDA) for integrated circuits. However, their applications in printed circuit board (PCB) design and analysis tasks remain underexplored. In part, this is due to a (1) a lack of text-based PCB datasets to evaluate LLMs and (2) a lack of methodologies for prompting LLMs with different types of PCB design files. To address this gap, our paper proposes PCB-QA: a manually created questionnaire dataset amounting to 480 question-answer pairs for PCBs, derived from 8 different open-source hardware projects of varying complexities. We examine multiple aspects of PCB designs and cover questions about component connections, datasheet examination, and simulation data obtainable via SPICE. Using our dataset as a benchmark, we prompt LLMs with different representations (and combinations) of PCB design files and record observations. This allows us to measure, for the first time, if LLMs can understand schematics and netlists in their "native forms" (i.e. graphical PDFs, KiCAD-format design files) or if textual formats are preferred. Including both commercial and open-weight models, we benchmark 4 state-of-the-art LLMs on our dataset, finding that Gemini 3 Flash Preview can answer questions with an accuracy of 93% using a proposed JSON-based textual format. This demonstrates that text-based PCB design formats can be evaluated by LLMs. Our open-source questionnaire is the first step towards enabling LLM integrations within the PCB design life cycle.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PCB-QA, the first manually created dataset of 480 question-answer pairs derived from 8 open-source PCB projects of varying complexity. It benchmarks four LLMs (including commercial and open-weight models) on multiple PCB design representations—graphical PDFs, KiCAD files, and a proposed JSON-based textual format—reporting that Gemini 3 Flash Preview achieves 93% accuracy on the JSON format. The work positions this as evidence that text-based PCB representations can be effectively evaluated by LLMs and as an initial step toward LLM integration in the PCB design lifecycle.
Significance. If the dataset is shown to be representative and the performance claims are validated, the open-sourced PCB-QA dataset would be a valuable contribution by filling a noted gap in benchmarks for LLM-based EDA on PCBs. The explicit comparison of native graphical vs. textual formats and the release of the questionnaire enable follow-on work; these strengths are noted even though the current evidence for generalization remains limited.
major comments (3)
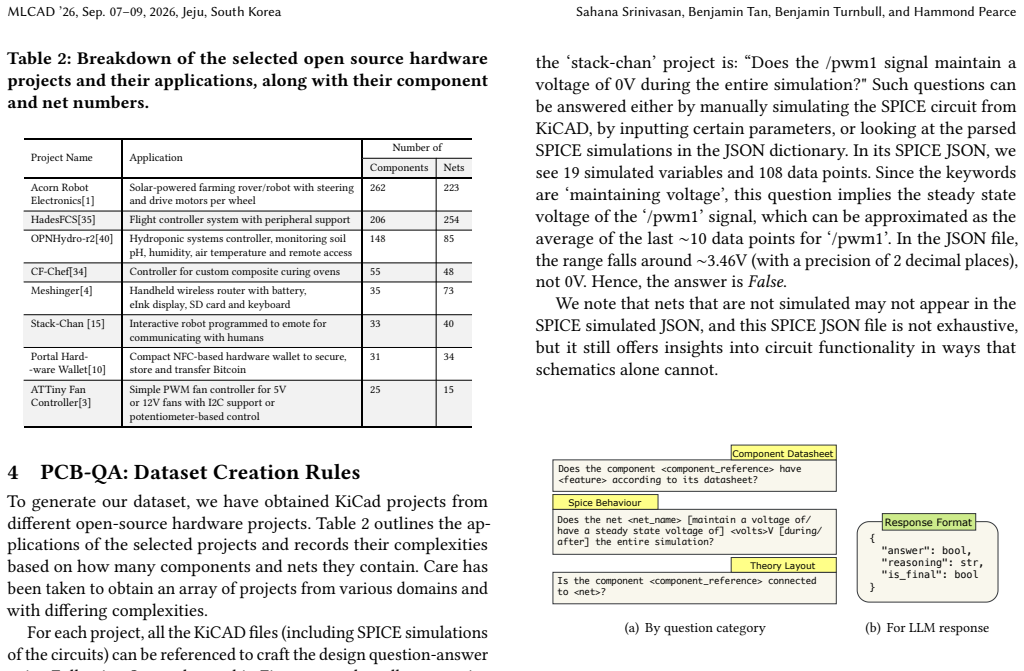
- [Dataset Construction] Dataset section: No description is provided of the question-generation process, inter-annotator agreement, error analysis, or coverage metrics for the 480 pairs across the eight projects. This directly undermines the central claim that the 93% accuracy demonstrates LLM understanding of PCB designs, as the pairs' representativeness for tasks such as connectivity, datasheets, SPICE, routing, and constraints is unverified.
- [Results] Results and Evaluation sections: The headline 93% accuracy for Gemini 3 Flash Preview on the JSON format is reported without statistical testing, confidence intervals, per-question-type breakdowns, or hold-out project evaluation. This makes it impossible to determine whether the result is robust or merely reflects narrow patterns in the eight source projects.
- [Introduction] Introduction and Dataset sections: Reliance on only eight open-source projects leaves open the possibility of training-data overlap and incomplete coverage of real-world PCB issues (e.g., manufacturing rules, high-speed constraints, thermal/EMI). No analysis addresses these risks, which are load-bearing for the generalization that text-based formats are preferred for LLM evaluation.
minor comments (2)
- [Experimental Setup] Clarify the exact model version and prompting details (temperature, few-shot examples, JSON schema definition) in the experimental setup to improve reproducibility.
- [Results] The abstract states the dataset size and 93% result but the main text should include a table summarizing accuracy by model and representation for quick comparison.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and indicate planned revisions to improve the manuscript.
read point-by-point responses
-
Referee: [Dataset Construction] Dataset section: No description is provided of the question-generation process, inter-annotator agreement, error analysis, or coverage metrics for the 480 pairs across the eight projects. This directly undermines the central claim that the 93% accuracy demonstrates LLM understanding of PCB designs, as the pairs' representativeness for tasks such as connectivity, datasheets, SPICE, routing, and constraints is unverified.
Authors: We agree that the current manuscript lacks sufficient detail on dataset construction. In the revision we will expand the Dataset section with a description of the question-generation process (expert review of each project to create questions on connectivity, datasheets, and SPICE), categorization of the 480 pairs, any inter-annotator agreement metrics, error analysis, and coverage statistics across the eight projects. This will directly support the representativeness claim. revision: yes
-
Referee: [Results] Results and Evaluation sections: The headline 93% accuracy for Gemini 3 Flash Preview on the JSON format is reported without statistical testing, confidence intervals, per-question-type breakdowns, or hold-out project evaluation. This makes it impossible to determine whether the result is robust or merely reflects narrow patterns in the eight source projects.
Authors: We accept that additional statistical rigor is required. The revised Results section will include statistical significance tests, confidence intervals (via bootstrap resampling), and per-question-type accuracy breakdowns. We will also add leave-one-project-out evaluation to assess robustness across the eight source projects. revision: yes
-
Referee: [Introduction] Introduction and Dataset sections: Reliance on only eight open-source projects leaves open the possibility of training-data overlap and incomplete coverage of real-world PCB issues (e.g., manufacturing rules, high-speed constraints, thermal/EMI). No analysis addresses these risks, which are load-bearing for the generalization that text-based formats are preferred for LLM evaluation.
Authors: The work is framed as an initial benchmark using publicly available projects of varying complexity. We will add an explicit Limitations subsection discussing potential training-data overlap and incomplete coverage of advanced topics such as manufacturing rules, high-speed constraints, and EMI. The core empirical result on JSON vs. native formats will be presented with these caveats. revision: partial
- Complete verification of training-data overlap is not feasible for closed-source models whose training corpora are not disclosed.
Circularity Check
No circularity: empirical benchmark on newly authored dataset with direct measurements
full rationale
The paper constructs a new 480-pair QA dataset from 8 open-source projects and reports LLM accuracies via direct prompting experiments. No equations, fitted parameters, self-citations as load-bearing premises, ansatzes, or uniqueness theorems appear in the provided text. The 93% accuracy figure is a direct empirical measurement on the authors' own test items rather than a derived quantity that reduces to prior inputs by construction. The central claim (text-based PCB formats are evaluable by LLMs) follows from the benchmark results without self-referential reduction. This is the expected non-finding for a dataset/benchmark paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sequoia Alexander. 2021. Twisted-Fields/acorn-robot-electronics. https: //github.com/Twisted-Fields/acorn-robot-electronics original-date: 2021-01- 31T00:37:35Z
2021
-
[2]
Anthropic. 2026. Claude Sonnet 4.6. https://www.anthropic.com/claude/sonnet
2026
-
[3]
Arya. 2019. CRImier/MyKiCad. https://github.com/CRImier/MyKiCad original- date: 2019-07-22T02:53:26Z
2019
-
[4]
awgh. 2022. Meshinger/Meshinger. https://github.com/Meshinger/Meshinger
2022
-
[5]
Dylan Bristot. 2025. Compare LLMs Side-by-Side | WhatLLM.org. https:// whatllm.org/compare
2025
-
[6]
Maurizio Calabrese, Leonardo Agnusdei, Gianmauro Fontana, Gabriele Papadia, and Antonio Del Prete. 2025. Application of Mask R-CNN and YOLOv8 algorithms for defect detection in printed circuit board manufacturing.Discover Applied Sciences7, 4 (March 2025), 257. doi:10.1007/s42452-025-06641-x
-
[7]
Kaiyan Chang, Ying Wang, Haimeng Ren, Mengdi Wang, Shengwen Liang, Yinhe Han, Huawei Li, and Xiaowei Li. 2023. ChipGPT: How far are we from natural language hardware design. doi:10.48550/arXiv.2305.14019 arXiv:2305.14019 [cs]
-
[8]
Mark Chen et al . 2021. Evaluating Large Language Models Trained on Code. doi:10.48550/arXiv.2107.03374 arXiv:2107.03374 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2107.03374 2021
-
[9]
Pradeep Dasigi, Kyle Lo, Iz Beltagy, Arman Cohan, Noah A. Smith, and Matt Gard- ner. 2021. A Dataset of Information-Seeking Questions and Answers Anchored Table 4: Binary classification metrics of the selected LLMs on a 25% subset of the entire dataset, with different input combinations from design sets➁and➂. NNet and NCir denote native KiCAD exports, PNe...
-
[10]
Alekos Filini. 2024. TwentyTwoHW/portal-hardware. https://github.com/ TwentyTwoHW/portal-hardware
2024
-
[11]
Shajib Ghosh, Antika Roy, Nitin Varshney, Patrick Craig, Md Mahfuz Al Hasan, and Navid Asadizanjani. 2025. Advanced metrics for high-precision PCB inspec- tion using 3D x-ray reconstruction. InMetrology, Inspection, and Process Control XXXIX, Vol. 13426. SPIE, 835–844. doi:10.1117/12.3058653
-
[12]
Google. 2025. Gemini 3 Flash Preview. https://ollama.com/gemini-3-flash- preview
2025
-
[13]
Taojun Hu and Xiao-Hua Zhou. 2024. Unveiling LLM Evaluation Focused on Met- rics: Challenges and Solutions. doi:10.48550/arXiv.2404.09135 arXiv:2404.09135 [cs]
-
[14]
Hugging Face. 2024. sentence-transformers/all-MiniLM-L6-v2·Hugging Face. https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2
2024
-
[15]
Shinya Ishikawa. 2021. stack-chan/stack-chan. https://github.com/stack-chan/ stack-chan
2021
-
[16]
Peter Jansen. 2023. From Words to Wires: Generating Functioning Electronic Devices from Natural Language Descriptions. doi:10.48550/arXiv.2305.14874 arXiv:2305.14874 [cs]
-
[17]
Yao Lai, Sungyoung Lee, Guojin Chen, Souradip Poddar, Mengkang Hu, David Z. Pan, and Ping Luo. 2025. AnalogCoder: Analog Circuit Design via Training-Free Code Generation.Proceedings of the AAAI Conference on Artificial Intelligence39, 1 (April 2025), 379–387. doi:10.1609/aaai.v39i1.32016 Number: 1
-
[18]
Jindong Li, Lianrong Chen, Bin Yang, Jiadong Zhu, Ying Wang, Yuzhe Ma, and Menglin Yang. 2025. PCB-Bench: Benchmarking LLMs for Printed Circuit Board Placement and Routing. https://openreview.net/forum?id=Q5QLu7XTWx
2025
-
[19]
Junyan Li, Sam-Zaak Wong, Gwok-Waa Wan, Xi Wang, and Jun Yang. 2025. EDA-Debugger: An LLM-Based Framework for Automated EDA Runtime Issue Resolution. In2025 26th International Symposium on Quality Electronic Design (ISQED). 1–7. doi:10.1109/ISQED65160.2025.11014463
-
[20]
Ming Li, Jike Zhong, Tianle Chen, Yuxiang Lai, and Konstantinos Psounis
-
[21]
13337–13349
EEE-Bench: A Comprehensive Multimodal Electrical And Electronics Engineering Benchmark. 13337–13349. https://openaccess.thecvf.com/content/ CVPR2025/html/Li_EEE-Bench_A_Comprehensive_Multimodal_Electrical_ And_Electronics_Engineering_Benchmark_CVPR_2025_paper.html
-
[22]
Renjie Li, Wenjie Wei, Qi Xin, Xiaoli Liu, Sixuan Mao, Erik Ma, Zijian Chen, Malu Zhang, Haizhou Li, and Zhaoyu Zhang. 2025. What Is Next for LLMs? Next-Generation AI Computing Hardware Using Photonic Chips. doi:10.48550/ arXiv.2505.05794 arXiv:2505.05794 [cs]
arXiv 2025
-
[23]
Fanfan Lin, Xinze Li, Weihao Lei, Juan J. Rodriguez-Andina, Josep M. Guerrero, Changyun Wen, Xin Zhang, and Hao Ma. 2025. PE-GPT: A New Paradigm for Power Electronics Design.IEEE Transactions on Industrial Electronics72, 4 (April 2025), 3778–3791. doi:10.1109/TIE.2024.3454408
-
[24]
Junhua Liu, Fanfan Lin, Xinze Li, Kwan Hui Lim, and Shuai Zhao. 2024. Physics- Informed LLM-Agent for Automated Modulation Design in Power Electronics Systems. doi:10.48550/arXiv.2411.14214 arXiv:2411.14214 [cs]
-
[25]
Mingjie Liu, Nathaniel Pinckney, Brucek Khailany, and Haoxing Ren. 2023. VerilogEval: Evaluating Large Language Models for Verilog Code Generation. doi:10.48550/arXiv.2309.07544 arXiv:2309.07544 [cs]
-
[26]
Shang Liu, Wenji Fang, Yao Lu, Jing Wang, Qijun Zhang, Hongce Zhang, and Zhiyao Xie. 2025. RTLCoder: Fully Open-Source and Efficient LLM-Assisted RTL Code Generation Technique.IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems44, 4 (April 2025), 1448–1461. doi:10.1109/TCAD. 2024.3483089
-
[27]
Aman Madaan, Shuyan Zhou, Uri Alon, Yiming Yang, and Graham Neubig. 2022. Language Models of Code are Few-Shot Commonsense Learners. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Abu Dhabi, United Arab Emirates, 1384–1403. doi:10.18653/v1/2022.emnlp-main.90
-
[28]
Shane Mattner. 2025. https://circuit-synth.readthedocs.io/en/latest/JSON_ SCHEMA.html
2025
-
[29]
Dizon-Paradis, Nathan Jessurun, Damon L
Dhwani Mehta, John True, Olivia P. Dizon-Paradis, Nathan Jessurun, Damon L. Woodard, Navid Asadizanjani, and Mark Tehranipoor. 2022. FICS PCB X-ray: A dataset for automated printed circuit board inter-layers inspection. https: //eprint.iacr.org/2022/924 Publication info: Preprint
2022
-
[30]
Pragati Shuddhodhan Meshram, Swetha Karthikeyan, Bhavya, and Suma Bhat
-
[31]
ElectroVizQA: How well do Multi-modal LLMs perform in Electronics Visual Question Answering? doi:10.48550/arXiv.2412.00102 arXiv:2412.00102 [cs]
-
[32]
Meta. 2024. meta-llama/Llama-3.3-70B-Instruct·Hugging Face. https:// huggingface.co/meta-llama/Llama-3.3-70B-Instruct
2024
-
[33]
Long Phan et al. 2025. Humanity’s Last Exam. doi:10.48550/arXiv.2501.14249 arXiv:2501.14249 [cs] version: 1
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.14249 2025
-
[34]
Weibo Qiu, Yinhao Xiao, and Runyu Pan. 2026. HWE-Bench: Can Language Models Perform Board-level Schematic Designs? doi:10.48550/arXiv.2603.18102 arXiv:2603.18102 [cs]
-
[35]
Pranav Rajpurkar, Robin Jia, and Percy Liang. 2018. Know What You Don’t Know: Unanswerable Questions for SQuAD. doi:10.48550/arXiv.1806.03822 arXiv:1806.03822 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1806.03822 2018
-
[36]
Andrew Reilley. 2025. reilleya/CF-Chef. https://github.com/reilleya/CF-Chef
2025
-
[37]
Philip Salmony. 2019. pms67/HadesFCS. https://github.com/pms67/HadesFCS original-date: 2019-12-01T22:27:22Z
2019
-
[38]
Lejla Skelic, Yan Xu, Matthew Cox, Wenjie Lu, Tao Yu, and Ruonan Han. 2025. CIRCUIT: A Benchmark for Circuit Interpretation and Reasoning Capabilities of LLMs. doi:10.48550/arXiv.2502.07980 arXiv:2502.07980 [cs]
-
[39]
Minqing Sun, Lanqi Ding, Huifeng Zhu, Yier Jin, An Zou, Minqing Sun, Lanqi Ding, Huifeng Zhu, Yier Jin, and An Zou. 2026. From ICs to Device: A Survey on Hardware Tampering Detection via Power Delivery Network and Signal Trace. ACM Trans. Des. Autom. Electron. Syst.31, 2 (Jan. 2026), 37:1–37:31. doi:10.1145/ 3779441
2026
-
[40]
Sanli Tang, Fan He, Xiaolin Huang, and Jie Yang. 2019. Online PCB De- fect Detector On A New PCB Defect Dataset. doi:10.48550/arXiv.1902.06197 arXiv:1902.06197 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1902.06197 2019
-
[41]
Shailja Thakur, Jason Blocklove, Hammond Pearce, Benjamin Tan, Siddharth Garg, and Ramesh Karri. 2024. AutoChip: Automating HDL Generation Using LLM Feedback. doi:10.48550/arXiv.2311.04887 arXiv:2311.04887 [cs]
-
[42]
Coert Vonk. 2026. OPNhydro/hardware at main·cvonk/OPNhydro. https: //github.com/cvonk/OPNhydro/tree/main/hardware
2026
-
[43]
Deepak Vungarala, Md Hasibul Amin, Pietro Mercati, Arnob Ghosh, Arman Roohi, Ramtin Zand, and Shaahin Angizi. 2025. LIMCA: LLM for Automating Analog In-Memory Computing Architecture Design Exploration. doi:10.48550/ arXiv.2503.13301 arXiv:2503.13301 [cs]
Pith/arXiv arXiv 2025
-
[44]
Deepak Vungarala, Md Hasibul Amin, Arman Roohi, Arnob Ghosh, Ramtin Zand, and Shaahin Angizi. 2025. From Prompt to Accelerator: A Perspective on LLM- Based Analog In-Memory Accelerator Design Automation. InProceedings of the Great Lakes Symposium on VLSI 2025 (GLSVLSI ’25). Association for Computing Machinery, New York, NY, USA, 811–816. doi:10.1145/37163...
-
[45]
Sam-Zaak Wong, Gwok-Waa Wan, Dongping Liu, and Xi Wang. 2024. VGV: Verilog Generation using Visual Capabilities of Multi-Modal Large Language Models. In2024 IEEE LLM Aided Design Workshop (LAD). 1–5. doi:10.1109/ LAD62341.2024.10691753 MLCAD ’26, Sep. 07–09, 2026, Jeju, South Korea Sahana Srinivasan, Benjamin Tan, Benjamin Turnbull, and Hammond Pearce
arXiv 2024
-
[46]
Youzhi Xu, Hao Wu, Yulong Liu, and Xiaoming Liu. 2025. Printed Circuit Board Sample Expansion and Automatic Defect Detection Based on Diffusion Models and ConvNeXt.Micromachines16, 3 (Feb. 2025), 261. doi:10.3390/mi16030261
-
[47]
Jianfeng Zheng, Xiaopeng Sun, Haixiang Zhou, Chenyang Tian, and Hao Qiang
-
[48]
doi:10.1109/ ACCESS.2022.3214306 Received 29 May 2026
Printed Circuit Boards Defect Detection Method Based on Improved Fully Convolutional Networks.IEEE Access10 (2022), 109908–109918. doi:10.1109/ ACCESS.2022.3214306 Received 29 May 2026
arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.