See & Sniff: Learning Visuo-Olfactory Representations
Pith reviewed 2026-06-26 05:28 UTC · model grok-4.3
The pith
Synthetically pairing smell samples with semantically matched web images enables self-supervised visuo-olfactory representations that raise smell classification accuracy by 7%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
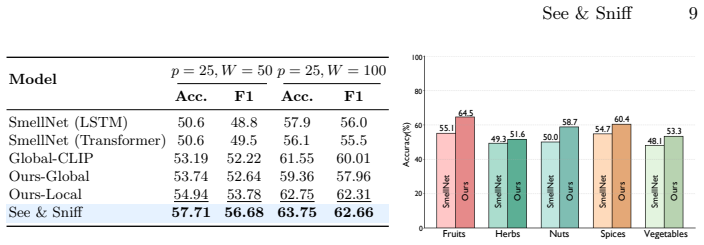
Odor identity is largely invariant to visual transformations within a semantic category. This invariance permits synthetic pairing of smell-only samples with aligned web images to form SmellNet-V. See & Sniff then learns joint visuo-olfactory representations through self-supervised dense local alignment, which improves smell classification from smell input alone by 7 percent over baselines, enables cross-modal retrieval, and produces smell saliency maps for pixel-level smell localization.
What carries the argument
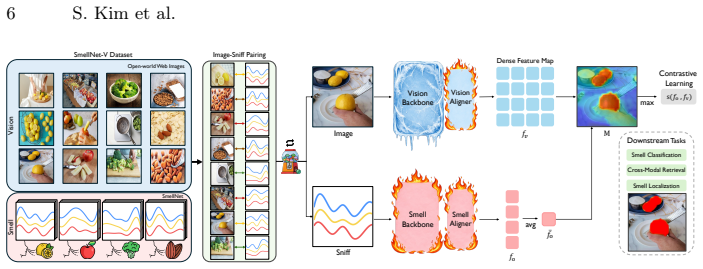
See & Sniff self-supervised framework that performs dense local alignment between visual and olfactory features on the synthetically paired SmellNet-V dataset, yielding joint representations and smell saliency maps.
If this is right
- Smell classification accuracy from olfactory input alone rises by 7 percent relative to smell-only baselines.
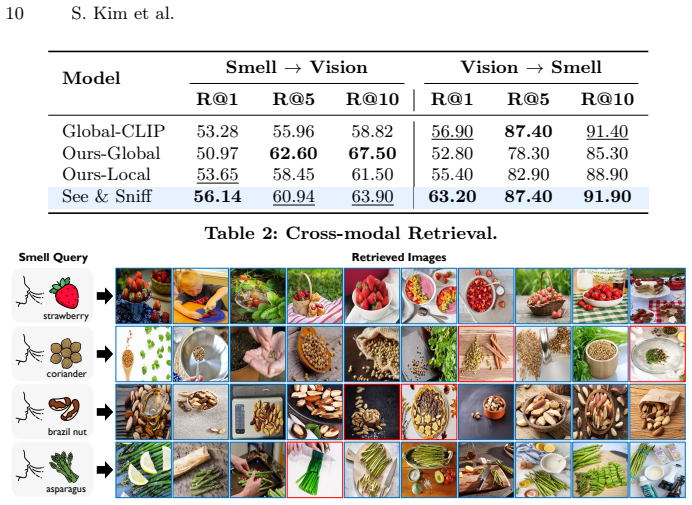
- The learned representations support retrieval between images and smell samples across modalities.
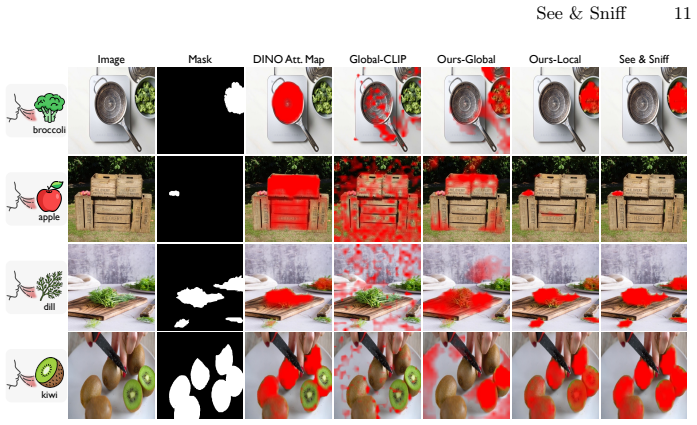
- Saliency maps from the model enable evaluation on a new pixel-level smell localization benchmark.
Where Pith is reading between the lines
- The same semantic-invariance pairing trick could bootstrap multimodal datasets for other data-scarce senses such as taste or touch.
- Spatial smell grounding via saliency maps may transfer to embodied systems that must locate odor sources in visual scenes.
Load-bearing premise
Odor identity remains the same even when the visual appearance of the source object changes within the same semantic category.
What would settle it
Collect a set of truly co-located vision and smell recordings, train See & Sniff on the synthetic pairs, and test whether the model still outperforms smell-only baselines on classification or localization; equal or worse performance would falsify the value of the synthetic pairing.
Figures








read the original abstract
While modern multimodal models integrate vision with language, audio, or touch, olfaction remains largely unexplored due to the lack of paired visuo-olfactory data. We introduce SmellNet-V, a scalable visuo-olfactory dataset built on the insight that odor identity is largely invariant to visual transformations within a semantic category. This allows us to synthetically pair smell-only samples with semantically aligned in-the-wild web images, converting a unimodal olfactory dataset into a cross-modal benchmark without costly co-collection. Building on this dataset, we propose See & Sniff, a self-supervised framework that learns joint visuo-olfactory representations via dense local alignment and naturally produces smell saliency maps for spatial grounding of odor sources. We further introduce pixel-level smell localization task and a benchmark for evaluation. Our method surpasses smell-only baselines by 7% in smell classification from smell alone and generalizes to cross-modal retrieval and smell localization, establishing visuo-olfactory learning as a new direction in multimodal perception.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SmellNet-V, a visuo-olfactory dataset constructed by synthetically pairing smell-only samples with semantically matched in-the-wild web images under the assumption that odor identity is largely invariant to visual transformations within a semantic category. It proposes the See & Sniff self-supervised framework that learns joint representations through dense local alignment and generates smell saliency maps for spatial grounding. The method reports a 7% improvement over smell-only baselines in smell classification and shows generalization to cross-modal retrieval and a new pixel-level smell localization task and benchmark.
Significance. If the synthetic pairing holds and the gains are reproducible, the work offers a scalable route to multimodal olfaction research without co-collection costs and introduces a useful new localization benchmark. The self-supervised dense alignment approach is a sensible technical direction for this modality pair.
major comments (3)
- [§3 (Dataset Construction)] The invariance assumption ('odor identity is largely invariant to visual transformations within a semantic category') used to justify synthetic pairing of smell samples with web images is stated without any reported validation (e.g., human agreement scores on pairing quality, odor consistency checks across visual instances, or ablation versus real co-collected pairs). This assumption is load-bearing for the SmellNet-V dataset quality, the dense local alignment objective, and the derived saliency maps.
- [§5 (Experiments)] The claimed 7% improvement in smell classification from smell alone is presented without error bars, statistical significance tests, dataset statistics, or ablations that isolate the contribution of the visual pairing versus the self-supervised objective. This makes it impossible to determine whether the lift is robust or an artifact of the synthetic construction.
- [§4 (Method)] The dense local alignment loss and the procedure for extracting smell saliency maps from the learned representations are described only at a high level; no explicit equations or algorithmic details are provided for either component, preventing assessment of their technical novelty relative to prior cross-modal alignment methods.
minor comments (1)
- [Abstract] Quantitative results for cross-modal retrieval and smell localization are mentioned in the abstract but not reported with numbers or tables in the provided text, weakening the generalization claim.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments, which highlight important areas for improvement in our manuscript. We address each major comment below and commit to revisions that strengthen the work.
read point-by-point responses
-
Referee: [§3 (Dataset Construction)] The invariance assumption ('odor identity is largely invariant to visual transformations within a semantic category') used to justify synthetic pairing of smell samples with web images is stated without any reported validation (e.g., human agreement scores on pairing quality, odor consistency checks across visual instances, or ablation versus real co-collected pairs). This assumption is load-bearing for the SmellNet-V dataset quality, the dense local alignment objective, and the derived saliency maps.
Authors: We agree that the invariance assumption requires empirical support to fully validate the dataset construction. Although the assumption is motivated by the semantic consistency of odors (e.g., the odor of 'rose' remains similar regardless of the visual depiction), we acknowledge the lack of reported validation in the current manuscript. In the revised version, we will conduct and report a human study to assess pairing quality and consistency, including agreement scores, and discuss its implications for the method. revision: yes
-
Referee: [§5 (Experiments)] The claimed 7% improvement in smell classification from smell alone is presented without error bars, statistical significance tests, dataset statistics, or ablations that isolate the contribution of the visual pairing versus the self-supervised objective. This makes it impossible to determine whether the lift is robust or an artifact of the synthetic construction.
Authors: We concur that additional statistical rigor is necessary to substantiate the reported improvements. We will update §5 to include error bars from multiple experimental runs, statistical significance tests, detailed dataset statistics, and ablations that separate the effects of visual pairing from the self-supervised objective. This will clarify the robustness of the 7% gain. revision: yes
-
Referee: [§4 (Method)] The dense local alignment loss and the procedure for extracting smell saliency maps from the learned representations are described only at a high level; no explicit equations or algorithmic details are provided for either component, preventing assessment of their technical novelty relative to prior cross-modal alignment methods.
Authors: We appreciate the feedback on the need for greater technical specificity. In the revised manuscript, we will expand §4 to include explicit mathematical formulations for the dense local alignment loss and the saliency map extraction procedure, along with algorithmic pseudocode. This will facilitate direct comparison with existing cross-modal methods and highlight any novel aspects. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's core steps consist of (1) constructing SmellNet-V via semantic-category pairing of existing smell samples with web images under an explicit invariance assumption, and (2) training a self-supervised model with dense local alignment on that dataset. No equations, fitted parameters, or predictions are described that reduce by construction to the inputs (no self-definitional loops, no fitted-input-called-prediction, no load-bearing self-citations, no uniqueness theorems, no ansatz smuggling). The reported 7% lift and cross-modal generalization are empirical outcomes of training rather than algebraic identities. The derivation chain is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Odor identity is largely invariant to visual transformations within a semantic category
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:1906.02569 (2019)
Abid, A., Abdalla, A., Abid, A., Khan, D., Alfozan, A., Zou, J.: Gradio: Hassle- free sharing and testing of ml models in the wild. arXiv preprint arXiv:1906.02569 (2019)
Pith/arXiv arXiv 1906
-
[2]
Scientific reports (2022)
Achebouche,R.,Tromelin,A.,Audouze,K.,Taboureau,O.:Applicationofartificial intelligencetodecodetherelationshipsbetweensmell,olfactoryreceptorsandsmall molecules. Scientific reports (2022)
2022
-
[3]
In: ICCV (2017)
Arandjelovic, R., Zisserman, A.: Look, listen and learn. In: ICCV (2017)
2017
-
[4]
In: NeurIPS (2016)
Aytar, Y., Vondrick, C., Torralba, A.: Soundnet: Learning sound representations from unlabeled video. In: NeurIPS (2016)
2016
-
[5]
arXiv preprint arXiv:1607.06450 (2016)
Ba, J.L., Kiros, J.R., Hinton, G.E.: Layer normalization. arXiv preprint arXiv:1607.06450 (2016)
Pith/arXiv arXiv 2016
-
[6]
In: ICLR (2026)
Carion, N., Gustafson, L., Hu, Y.T., Debnath, S., Hu, R., Suris, D., Ryali, C., Alwala,K.V.,Khedr,H.,Huang,A.,etal.:Sam3:Segmentanythingwithconcepts. In: ICLR (2026)
2026
-
[7]
Scientific Reports (2025)
Castellotti, S., Soldo, M., Plank, T., Viva, M.M.D., Greenlee, M.W.: Visual search performance depends on the congruency of olfactory sensations. Scientific Reports (2025)
2025
-
[8]
In: CVPR (2022)
Cheng, B., Misra, I., Schwing, A.G., Kirillov, A., Girdhar, R.: Masked-attention mask transformer for universal image segmentation. In: CVPR (2022)
2022
-
[9]
In: ICASSP (2023)
Elizalde, B., Deshmukh, S., Ismail, M.A., Wang, H.: Clap: Learning audio concepts from natural language supervision. In: ICASSP (2023)
2023
-
[10]
IJCV (2015)
Everingham, M., Eslami, S.A., Van Gool, L., Williams, C.K., Winn, J., Zisserman, A.: The pascal visual object classes challenge: A retrospective. IJCV (2015)
2015
-
[11]
Hugging Face Spaces (2025), https : / / huggingface
Fancy Feast: Joycaption Watermark Detection. Hugging Face Spaces (2025), https : / / huggingface . co / spaces / fancyfeast / joycaption - watermark - detection, Accessed 24 June 2026
2025
-
[12]
In: ICLR (2026)
Feng, D., Dai, W., Li, C., Pernigo, A., Wen, Y., Liang, P.P.: Smellnet: A large-scale dataset for real-world smell recognition. In: ICLR (2026)
2026
-
[13]
arXiv preprint arXiv:2512.08683 (2025)
Fichtelmann, P., Westermayr, J.: Machine learning for smell: Ordinal odor strength prediction of molecular perfumery components. arXiv preprint arXiv:2512.08683 (2025)
Pith/arXiv arXiv 2025
-
[14]
In: ICML (2024)
Fu, L., Datta, G., Huang, H., Panitch, W.C.H., Drake, J., Ortiz, J., Mukadam, M., Lambeta, M., Calandra, R., Goldberg, K.: A touch, vision, and language dataset for multimodal alignment. In: ICML (2024)
2024
-
[15]
In: CVPR (2023)
Girdhar, R., El-Nouby, A., Liu, Z., Singh, M., Alwala, K.V., Joulin, A., Misra, I.: Imagebind: One embedding space to bind them all. In: CVPR (2023)
2023
-
[16]
In: ICLR (2022) 16 S
Gong, Y., Rouditchenko, A., Liu, A.H., Harwath, D., Karlinsky, L., Kuehne, H., Glass, J.: Contrastive audio-visual masked autoencoder. In: ICLR (2022) 16 S. Kim et al
2022
-
[17]
chirp" fromthe
Hamilton,M.,Zisserman,A.,Hershey,J.R.,Freeman,W.T.:Separatingthe"chirp" fromthe"chat":Self-supervisedvisualgroundingofsoundandlanguage.In:CVPR (2024)
2024
-
[18]
In: ECCV (2018)
Harwath, D., Recasens, A., Surís, D., Chuang, G., Torralba, A., Glass, J.: Jointly discovering visual objects and spoken words from raw sensory input. In: ECCV (2018)
2018
-
[19]
Intel Corporation: CVAT: Computer Vision Annotation Tool (2025),https:// www.cvat.ai/, Accessed 24 June 2026
2025
-
[20]
Current Research in Food Science (2025)
Iwata, H.: Interpretable multitask deep learning models for odor perception based on molecular structure. Current Research in Food Science (2025)
2025
-
[21]
In: ICML (2021)
Jia, C., Yang, Y., Xia, Y., Chen, Y.T., Parekh, Z., Pham, H., Le, Q., Sung, Y.H., Li, Z., Duerig, T.: Scaling up visual and vision-language representation learning with noisy text supervision. In: ICML (2021)
2021
-
[22]
arXiv preprint arXiv:2601.19561 (2026)
Kang,D.,Kim,J.,Park,J.,Lee,K.,Choi,J.W.,So,J.:Aromma:Unifyingolfactory embeddings for single molecules and mixtures. arXiv preprint arXiv:2601.19561 (2026)
arXiv 2026
-
[23]
The Home Magazine (1934),https://www.afb
Keller, H.: A neglected treasure. The Home Magazine (1934),https://www.afb. org/HelenKellerArchive?a=d&d=A-HK02-B225-F02-024
1934
-
[24]
In: CVPR (2026)
Kim, S., Lee, S., Ryu, H., Chung, J.S., Senocak, A.: Seeing through touch: Tactile- driven visual localization of material regions. In: CVPR (2026)
2026
-
[25]
In: ICCV (2023)
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.Y., et al.: Segment anything. In: ICCV (2023)
2023
-
[26]
Science (2023)
Lee, B.K., Mayhew, E.J., Sanchez-Lengeling, B., Wei, J.N., Qian, W.W., Little, K.A., Andres, M., Nguyen, B.B., Moloy, T., Yasonik, J., et al.: A principal odor map unifies diverse tasks in olfactory perception. Science (2023)
2023
-
[27]
In: ICML (2023)
Li, J., Li, D., Savarese, S., Hoi, S.: Blip-2: Bootstrapping language-image pre- training with frozen image encoders and large language models. In: ICML (2023)
2023
-
[28]
In: ICML (2022)
Li, J., Li, D., Xiong, C., Hoi, S.: Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In: ICML (2022)
2022
-
[29]
In: CVPR (2022)
Lüddecke, T., Ecker, A.: Image segmentation using text and image prompts. In: CVPR (2022)
2022
-
[30]
arXiv preprint arXiv:2405.16108 (2024)
Lyu, Y., Zheng, X., Kim, D., Wang, L.: Omnibind: Teach to build unequal-scale modality interaction for omni-bind of all. arXiv preprint arXiv:2405.16108 (2024)
arXiv 2024
-
[31]
Chemical senses (2006)
Mainland, J., Sobel, N.: The sniff is part of the olfactory percept. Chemical senses (2006)
2006
-
[32]
Expert systems with applications (2019)
Mueller, P., Salminen, K., Nieminen, V., Kontunen, A., Karjalainen, M., Isokoski, P., Rantala, J., Savia, M., Väliaho, J., Kallio, P., et al.: Scent classification by k nearest neighbors using ion-mobility spectrometry measurements. Expert systems with applications (2019)
2019
-
[33]
In: ECCV (2024)
Naeem, M.F., Xian, Y., Zhai, X., Hoyer, L., Van Gool, L., Tombari, F.: Silc: Im- proving vision language pretraining with self-distillation. In: ECCV (2024)
2024
-
[34]
In: ECCV (2018)
Owens, A., Efros, A.A.: Audio-visual scene analysis with self-supervised multisen- sory features. In: ECCV (2018)
2018
-
[35]
arXiv preprint arXiv:2511.20544 (2025)
Ozguroglu, E., Liang, J., Liu, R., Chiquier, M., DeTienne, M., Qian, W.W., Horowitz, A., Owens, A., Vondrick, C.: New york smells: A large multimodal dataset for olfaction. arXiv preprint arXiv:2511.20544 (2025)
arXiv 2025
-
[36]
In: ICML (2021) See & Sniff 17
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: ICML (2021) See & Sniff 17
2021
-
[37]
Neuroscience & Biobehavioral Reviews (2021)
Raithel, C.U., Gottfried, J.A.: Using your nose to find your way: Ethological com- parisons between human and non-human species. Neuroscience & Biobehavioral Reviews (2021)
2021
-
[38]
In: CVPR (2025)
Ryu, H., Kim, S., Chung, J.S., Senocak, A.: Seeing speech and sound: Distinguish- ing and locating audio sources in visual scenes. In: CVPR (2025)
2025
-
[39]
arXiv preprint arXiv:1910.10685 (2019)
Sanchez-Lengeling, B., Wei, J.N., Lee, B.K., Gerkin, R.C., Aspuru-Guzik, A., Wiltschko, A.B.: Machine learning for scent: Learning generalizable perceptual representations of small molecules. arXiv preprint arXiv:1910.10685 (2019)
arXiv 1910
-
[40]
In: CVPR (2018)
Senocak, A., Oh, T.H., Kim, J., Yang, M.H., Kweon, I.S.: Learning to localize sound source in visual scenes. In: CVPR (2018)
2018
-
[41]
In: ICCV (2023)
Senocak, A., Ryu, H., Kim, J., Oh, T.H., Pfister, H., Chung, J.S.: Sound source localization is all about cross-modal alignment. In: ICCV (2023)
2023
-
[42]
Senocak, A., Ryu, H., Kim, J., Oh, T.H., Pfister, H., Chung, J.S.: Toward in- teractive sound source localization: Better align sight and sound! IEEE TPAMI (2025)
2025
-
[43]
arXiv preprint arXiv:2508.10104 (2025)
Siméoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khali- dov, V., Szafraniec, M., Yi, S., Ramamonjisoa, M., et al.: Dinov3. arXiv preprint arXiv:2508.10104 (2025)
Pith/arXiv arXiv 2025
-
[44]
arXiv preprint arXiv:2601.03267 (2025)
Singh, A., Fry, A., Perelman, A., Tart, A., Ganesh, A., El-Kishky, A., McLaughlin, A., Low, A., Ostrow, A., Ananthram, A., et al.: Openai gpt-5 system card. arXiv preprint arXiv:2601.03267 (2025)
Pith/arXiv arXiv 2025
-
[45]
Nature communications (2024)
Sung,S.H.,Suh,J.M.,Hwang,Y.J.,Jang,H.W.,Park,J.G.,Jun,S.C.:Data-centric artificial olfactory system based on the eigengraph. Nature communications (2024)
2024
-
[46]
In: ICML (2019)
Tran, N., Kepple, D., Shuvaev, S., Koulakov, A.: Deepnose: Using artificial neural networks to represent the space of odorants. In: ICML (2019)
2019
-
[47]
In: NeurIPS (2017)
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, L., Polosukhin, I.: Attention is all you need. In: NeurIPS (2017)
2017
-
[48]
Neuron (2011)
Wachowiak, M.: All in a sniff: olfaction as a model for active sensing. Neuron (2011)
2011
-
[49]
In: CVPR (2018)
Wu, Z., Xiong, Y., Yu, S., Lin, D.: Unsupervised feature learning via non- parametric instance-level discrimination. In: CVPR (2018)
2018
-
[50]
In: CVPR (2024)
Yang, F., Feng, C., Chen, Z., Park, H., Wang, D., Dou, Y., Zeng, Z., Chen, X., Gangopadhyay, R., Owens, A., et al.: Binding touch to everything: Learning unified multimodal tactile representations. In: CVPR (2024)
2024
-
[51]
In: NeurIPS - Datasets and Benchmarks Track (2022)
Yang, F., Ma, C., Zhang, J., Zhu, J., Yuan, W., Owens, A.: Touch and go: Learning from human-collected vision and touch. In: NeurIPS - Datasets and Benchmarks Track (2022)
2022
-
[52]
In: ICCV (2023)
Yang, F., Zhang, J., Owens, A.: Generating visual scenes from touch. In: ICCV (2023)
2023
-
[53]
seeds” (rather than “leaves
Zhai, X., Mustafa, B., Kolesnikov, A., Beyer, L.: Sigmoid loss for language image pre-training. In: ICCV (2023) 18 S. Kim et al. – Supplementary Material – See & Sniff: Learning Visuo-Olfactory Representations The contents in this supplementary material are as follows: 7 Details onSmellNet-V.......................................... 18 8 Implementation De...
2023
-
[54]
Category Consistency: ‘a photo of real, high-quality {category}’ ‘a photo of something else entirely’2. Photorealism: ‘a photo of real, high-quality {category}’ ‘a drawing of {category}’, ‘an illustration of {category}’, ‘a cartoon of {category}’3. Valid Object State: ‘a photo of fresh, good-quality {category}’ ‘a photo of rotten, spoiled, or moldy {categ...
arXiv 2072
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.