End-to-End Training for Discrete Token LLM based TTS System
Pith reviewed 2026-06-27 15:20 UTC · model grok-4.3
The pith
Jointly optimizing the speech tokenizer, LLM, flow-matching model and reward model produces discrete tokens better suited to text-to-speech than separately trained components.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
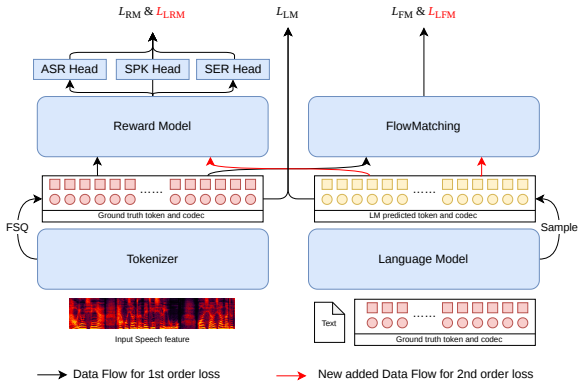
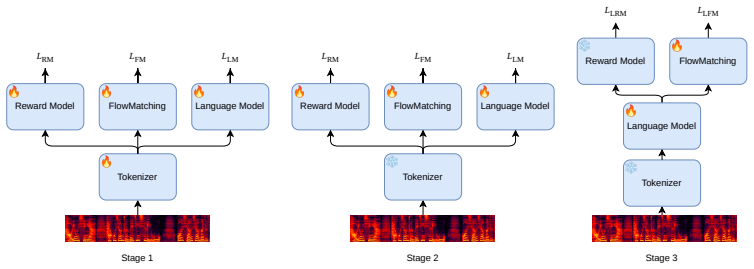
Jointly optimizing the speech tokenizer using reconstruction for the flow-matching model, next-token prediction for the LLM and multi-recognition for the reward model creates a discrete token space better tailored to TTS; further optimizing the LLM with downstream reconstruction and recognition objectives then reduces inference mismatch and steers generations toward preferred outputs, yielding consistent gains over independently trained cascaded pipelines.
What carries the argument
The end-to-end optimization framework that applies multi-task objectives to the tokenizer and downstream reconstruction and recognition objectives to the LLM.
If this is right
- The unified system consistently outperforms cascaded baselines on TTS tasks.
- New state-of-the-art word error rates of 0.78 percent and 1.56 percent are reached on Seed-TTS-Eval.
- The gains hold with a 0.6 B-parameter LLM and 0.5 B-parameter flow-matching model.
- Training is simplified because the components no longer require separate optimization stages.
Where Pith is reading between the lines
- The same joint-objective approach could be tested on other discrete-token pipelines such as music or sound-effect generation.
- Reducing decoder-LLM mismatch through downstream feedback may apply to any autoregressive generation system that uses a separate decoder.
- The resulting token space might also improve performance on downstream speech recognition or understanding tasks.
Load-bearing premise
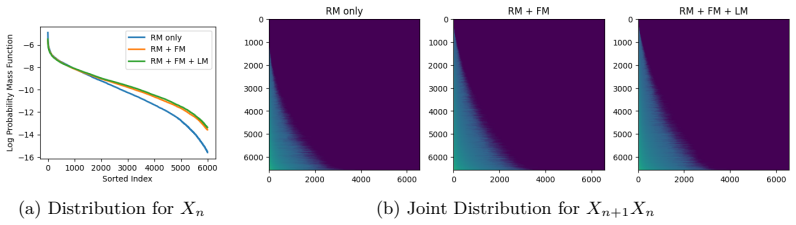
The joint multi-task objectives on the tokenizer produce a discrete token space measurably better suited to TTS than tokens trained independently.
What would settle it
An ablation that trains the tokenizer independently on the same data and measures whether word error rate on Seed-TTS-Eval rises back to the level of the cascaded baseline.
Figures
read the original abstract
Recent state-of-the-art (SOTA) text-to-speech (TTS) systems typically adopt a cascaded pipeline consisting of a speech tokenizer, an autoregressive large language model (LLM), and a diffusion based flow-matching (FM) model, with these components trained independently. In this paper, we propose a fully end-to-end (E2E) optimization framework that unifies the training of the speech tokenizer, LLM, FM model, and an additional reward model (RM). Specifically, we first jointly optimize the tokenizer using multi-task objectives derived from reconstruction for FM, next-token prediction for LLM, and multi recognition task for RM. This joint training encourages the discrete speech token space to capture acoustically and semantically salient information that is better tailored to TTS. We then further optimize the LLM using downstream reconstruction and recognition by FM and RM, which reduces inference-time mismatch and steers the LLM toward more preferred generations. Experimental results show that our E2E framework consistently outperforms cascaded baselines. On the Seed-TTS-Eval benchmark, our system achieves a word error rate (WER) of 0.78% and 1.56%, a new SOTA result with a 0.6B-parameter LLM and 0.5B-parameter FM model. These results validate that holistic E2E optimization is critical for improving discrete-token-based TTS systems with a much simpler training pipeline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a fully end-to-end optimization framework for discrete-token LLM-based TTS that jointly trains the speech tokenizer on multi-task objectives (reconstruction for the flow-matching model, next-token prediction for the LLM, and multi-recognition for an added reward model), then further optimizes the LLM using downstream reconstruction and recognition signals. This is claimed to produce tokens better tailored to TTS and reduce inference-time mismatch, yielding consistent outperformance of cascaded baselines and new SOTA WERs of 0.78% and 1.56% on Seed-TTS-Eval using a 0.6B LLM and 0.5B FM model.
Significance. If the central empirical claims hold after proper controls, the work would demonstrate that holistic joint training can improve discrete-token TTS performance while simplifying the pipeline relative to independent component training, providing evidence that multi-task tokenization and downstream LLM steering are effective for reducing mismatch in cascaded systems.
major comments (2)
- [Abstract / Experimental results] Abstract and experimental results: the headline claim that joint multi-task training of the tokenizer yields a discrete token space measurably better suited to TTS (producing the reported SOTA WER) is load-bearing yet unsupported by any ablation that trains an otherwise identical tokenizer on single objectives or independent stages and measures the resulting WER delta when the same LLM+FM are attached.
- [Abstract] Abstract: the reported WER improvements of 0.78% and 1.56% are presented without quantitative ablations isolating the contribution of each objective, without error bars, and without statistical tests comparing E2E versus cascaded baselines.
minor comments (2)
- The manuscript should clarify the precise training schedule, data splits, and hyperparameter selection procedure to allow assessment of whether evaluation metrics influenced model selection.
- Details on the architecture and training of the reward model (RM) are insufficient for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comments point-by-point below and will revise the paper to incorporate additional experiments and analysis as needed.
read point-by-point responses
-
Referee: [Abstract / Experimental results] Abstract and experimental results: the headline claim that joint multi-task training of the tokenizer yields a discrete token space measurably better suited to TTS (producing the reported SOTA WER) is load-bearing yet unsupported by any ablation that trains an otherwise identical tokenizer on single objectives or independent stages and measures the resulting WER delta when the same LLM+FM are attached.
Authors: We agree that a direct ablation isolating multi-task tokenizer training versus single-objective or independent-stage training would provide stronger support for the claim that the joint objectives produce a token space better suited to TTS. The current manuscript compares the full E2E system against cascaded baselines (independently trained components), which provides indirect evidence, but does not include the requested tokenizer-specific ablation with fixed LLM+FM. We will add these ablations in the revision, training otherwise identical tokenizers on single objectives and reporting the resulting WER deltas. revision: yes
-
Referee: [Abstract] Abstract: the reported WER improvements of 0.78% and 1.56% are presented without quantitative ablations isolating the contribution of each objective, without error bars, and without statistical tests comparing E2E versus cascaded baselines.
Authors: We acknowledge that the reported WER figures lack error bars, statistical tests, and per-objective contribution ablations. In the revised manuscript we will report results across multiple random seeds with error bars, include statistical significance tests (e.g., paired t-tests) against the cascaded baselines, and expand the ablation section to quantify the contribution of each training objective (reconstruction, next-token prediction, and recognition). revision: yes
Circularity Check
No circularity: empirical training claims with no derivations or self-referential reductions
full rationale
The paper describes an end-to-end training procedure for a TTS system using joint multi-task objectives on a tokenizer, followed by LLM optimization, and reports measured WER improvements on Seed-TTS-Eval. No equations, derivations, or first-principles results are present. The central claim (joint objectives yield a better token space) is an empirical assertion supported by benchmark numbers rather than any definitional loop, fitted parameter renamed as prediction, or load-bearing self-citation. The result remains externally falsifiable via independent replication or ablation, satisfying the self-contained criterion.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Seed-TTS: A Family of High-Quality Versatile Speech Generation Models
Philip Anastassiou, Jiawei Chen, Jitong Chen, Yuanzhe Chen, Zhuo Chen, Ziyi Chen, Jian Cong, Lelai Deng, Chuang Ding, Lu Gao, Mingqing Gong, Peisong Huang, Qingqing Huang, Zhiying Huang, Yuanyuan Huo, Dongya Jia, Chumin Li, Feiya Li, Hui Li, Jiaxin Li, Xiaoyang Li, Xingxing Li, Lin Liu, Shouda Liu, Sichao Liu, Xudong Liu, Yuchen Liu, Zhengxi Liu, Lu Lu, J...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
CosyVoice 3: Towards In-the-wild Speech Generation via Scaling-up and Post-training
Zhihao Du, Changfeng Gao, Yuxuan Wang, Fan Yu, Tianyu Zhao, Hao Wang, Xiang Lv, Hui Wang, Chongjia Ni, Xian Shi, et al. Cosyvoice 3: Towards in-the-wild speech generation via scaling-up and post-training. arXiv preprint arXiv:2505.17589, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Hangrui Hu, Xinfa Zhu, Ting He, Dake Guo, Bin Zhang, Xiong Wang, Zhifang Guo, Ziyue Jiang, Hongkun Hao, Zishan Guo, et al. Qwen3-tts technical report. arXiv preprint arXiv:2601.15621, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Asq: An ultra-low bit rate asr-oriented speech quantization method
Lingxuan Ye, Changfeng Gao, Gaofeng Cheng, Liuping Luo, and Qingwei Zhao. Asq: An ultra-low bit rate asr-oriented speech quantization method. IEEE Signal Processing Letters, 31:221–225, 2023
2023
-
[5]
Zhihao Du, Qian Chen, Shiliang Zhang, Kai Hu, Heng Lu, Yexin Yang, Hangrui Hu, Siqi Zheng, Yue Gu, Ziyang Ma, Zhifu Gao, and Zhijie Yan. Cosyvoice: A scalable multilingual zero-shot text-to-speech synthesizer based on supervised semantic tokens. CoRR, abs/2407.05407, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Haohan Guo, Kun Liu, Feiyu Shen, Yi-Chen Wu, Feng-Long Xie, Kun Xie, and Kaituo Xu. Fireredtts: A foundation text-to-speech framework for industry-level generative speech applications. CoRR, abs/2409.03283, 2024
-
[7]
Joyvoice: Long-context condition- ing for anthropomorphic multi-speaker conversational synthesis
Fan Yu, Tao Wang, You Wu, Lin Zhu, Wei Deng, Weisheng Han, Wenchao Wang, Lin Hu, Xiangyu Liang, Xiaodong He, et al. Joyvoice: Long-context condition- ing for anthropomorphic multi-speaker conversational synthesis. arXiv preprint arXiv:2512.19090, 2025
-
[8]
Differentiable reward optimization for llm based tts system
Changfeng Gao, Zhihao Du, and Shiliang Zhang. Differentiable reward optimization for llm based tts system. arXiv preprint arXiv:2507.05911, 2025
-
[9]
Emo-codec: An in-depth look at emotion preservation capacity of legacy and neural codec models with subjective and objective evaluations
Wenze Ren, Yi-Cheng Lin, Huang-Cheng Chou, Haibin Wu, Yi-Chiao Wu, Chi-Chun Lee, Hung-yi Lee, Hsin-Min Wang, and Yu Tsao. Emo-codec: An in-depth look at emotion preservation capacity of legacy and neural codec models with subjective and objective evaluations. In 2024 Asia Pacific Signal and Information Processing Associa- tion Annual Summit and Conference...
2024
-
[10]
Codec2vec: Self-supervised speech representa- tion learning using neural speech codecs
Wei-Cheng Tseng and David Harwath. Codec2vec: Self-supervised speech representa- tion learning using neural speech codecs. arXiv preprint arXiv:2511.16639, 2025
-
[11]
Tadicodec: Text-aware diffusion speech tokenizer for speech language modeling
Yuancheng Wang, Dekun Chen, Xueyao Zhang, Junan Zhang, Jiaqi Li, and Zhizheng Wu. Tadicodec: Text-aware diffusion speech tokenizer for speech language modeling. Advances in Neural Information Processing Systems, 38:147494–147523, 2026
2026
-
[12]
Scaling speech tokenizers with diffusion autoencoders
Yuancheng Wang, Zhenyu Tang, Yun Wang, Arthur Hinsvark, Yingru Liu, Yinghao Li, Kainan Peng, Junyi Ao, Mingbo Ma, Mike Seltzer, et al. Scaling speech tokenizers with diffusion autoencoders. arXiv preprint arXiv:2602.06602, 2026
-
[13]
Finite scalar quantization: VQ-VAE made simple
Fabian Mentzer, David Minnen, Eirikur Agustsson, and Michael Tschannen. Finite scalar quantization: VQ-VAE made simple. In ICLR. OpenReview.net, 2024. 10
2024
-
[14]
Maskgct: Zero-shot text-to- speech with masked generative codec transformer,
Yuancheng Wang, Haoyue Zhan, Liwei Liu, Ruihong Zeng, Haotian Guo, Jiachen Zheng, Qiang Zhang, Shunsi Zhang, and Zhizheng Wu. Maskgct: Zero-shot text- to-speech with masked generative codec transformer. CoRR, abs/2409.00750, 2024
-
[15]
F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching
Yushen Chen, Zhikang Niu, Ziyang Ma, Keqi Deng, Chunhui Wang, Jian Zhao, Kai Yu, and Xie Chen. F5-TTS: A fairytaler that fakes fluent and faithful speech with flow matching. CoRR, abs/2410.06885, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
F5r- tts: Improving flow matching based text-to-speech with group relative policy optimiza- tion
Xiaohui Sun, Ruitong Xiao, Jianye Mo, Bowen Wu, Qun Yu, and Baoxun Wang. F5r- tts: Improving flow matching based text-to-speech with group relative policy optimiza- tion. arXiv preprint arXiv:2504.02407, 2025
-
[17]
Zipvoice: Fast and high-quality zero-shot text- to-speech with flow matching
Han Zhu, Wei Kang, Zengwei Yao, Liyong Guo, Fangjun Kuang, Zhaoqing Li, Weiji Zhuang, Long Lin, and Daniel Povey. Zipvoice: Fast and high-quality zero-shot text- to-speech with flow matching. arXiv preprint arXiv:2506.13053, 2025
-
[18]
OmniVoice: Towards Omnilingual Zero-Shot Text-to-Speech with Diffusion Language Models
Han Zhu, Lingxuan Ye, Wei Kang, Zengwei Yao, Liyong Guo, Fangjun Kuang, Zhifeng Han, Weiji Zhuang, Long Lin, and Daniel Povey. Omnivoice: Towards omnilingual zero- shot text-to-speech with diffusion language models. arXiv preprint arXiv:2604.00688, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
Spark-TTS: An Efficient LLM-Based Text-to-Speech Model with Single-Stream Decoupled Speech Tokens
Xinsheng Wang, Mingqi Jiang, Ziyang Ma, Ziyu Zhang, Songxiang Liu, Linqin Li, Zheng Liang, Qixi Zheng, Rui Wang, Xiaoqin Feng, et al. Spark-tts: An efficient llm- based text-to-speech model with single-stream decoupled speech tokens. arXiv preprint arXiv:2503.01710, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models
Zhihao Du, Yuxuan Wang, Qian Chen, Xian Shi, Xiang Lv, Tianyu Zhao, Zhifu Gao, Yexin Yang, Changfeng Gao, Hui Wang, et al. Cosyvoice 2: Scalable streaming speech synthesis with large language models. arXiv preprint arXiv:2412.10117, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Faster whisper large v3, 2023
Systran. Faster whisper large v3, 2023
2023
-
[22]
Funaudiollm: Voice understanding and generation foundation models for natural interaction between humans and llms
Tongyi Speech Team. Funaudiollm: Voice understanding and generation foundation models for natural interaction between humans and llms. arxiv, 2024
2024
-
[23]
Tera: Self-supervised learning of trans- former encoder representation for speech
Andy T Liu, Shang-Wen Li, and Hung-yi Lee. Tera: Self-supervised learning of trans- former encoder representation for speech. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 29:2351–2366, 2021
2021
-
[24]
vq-wav2vec: Self-supervised learn- ing of discrete speech representations
Alexei Baevski, Steffen Schneider, and Michael Auli. vq-wav2vec: Self-supervised learn- ing of discrete speech representations. arXiv preprint arXiv:1910.05453, 2019. 11
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.