Dendritic In-Context Learning in a Single-Layer Spiking Neural Network
Pith reviewed 2026-07-03 02:48 UTC · model grok-4.3
The pith
The subthreshold dynamics of a single dendritic compartment embed a complete online learning algorithm, enabling in-context learning in a single-layer spiking neural network.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
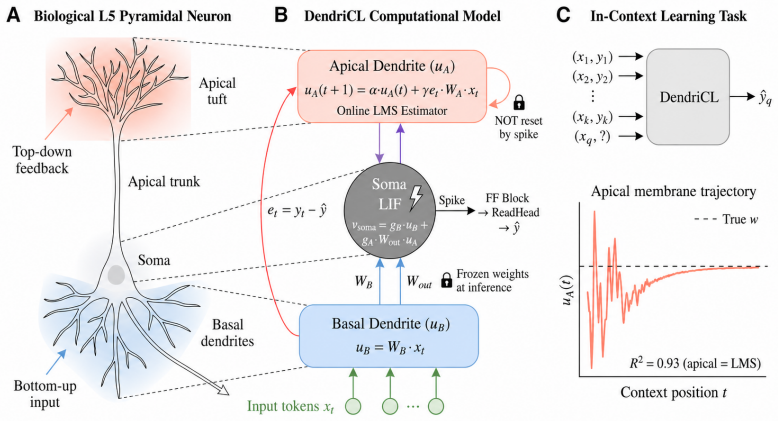
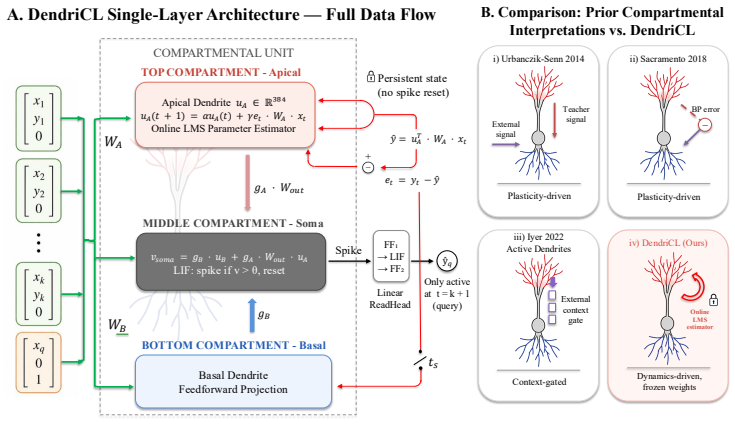
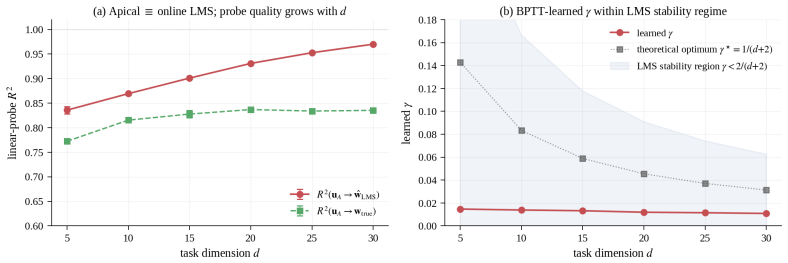
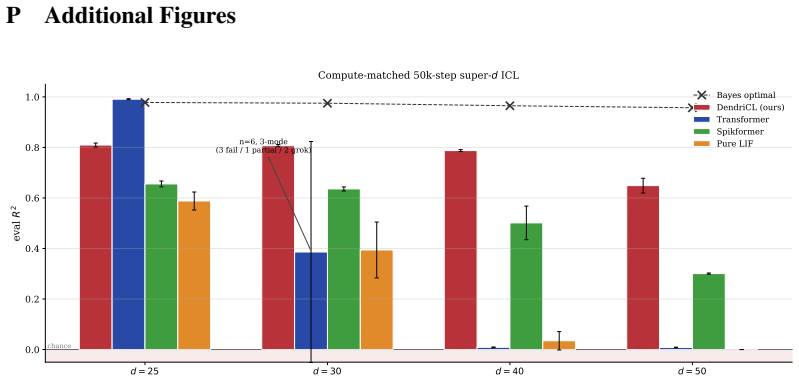
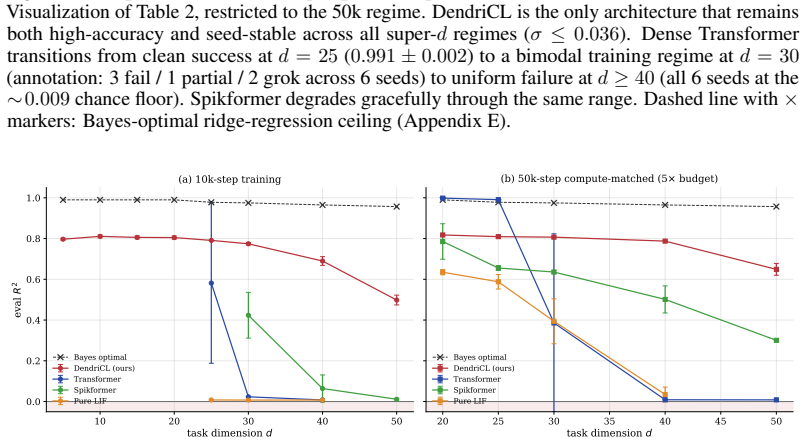
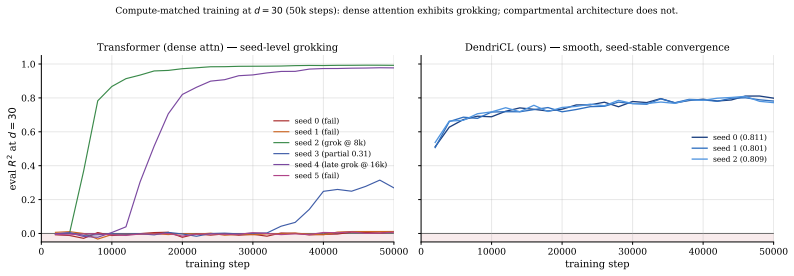
By modeling the dendritic compartment's apical recurrence as structurally identical to leaky online Widrow-Hoff LMS, the architecture implements the learning algorithm directly in the dynamics. This allows the single-layer compartmental spiking network to succeed on the Garg-2022 ICL benchmark at super-dimensional tasks, where it is seed-stable unlike dense transformers, and the algorithm is shown to be embedded rather than learned.
What carries the argument
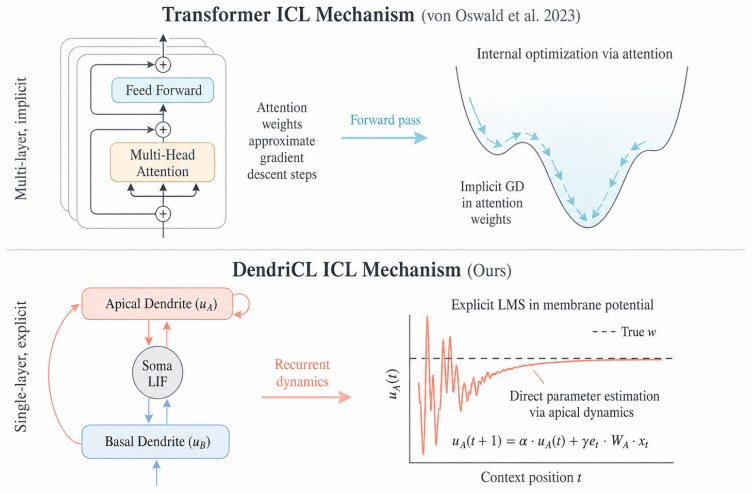
The apical recurrence in the single dendritic compartment, which is structurally identical to the leaky online Widrow-Hoff LMS update.
If this is right
- ICL can be achieved without multi-layer architectures or attention.
- No inference-time synaptic plasticity is needed for adaptation.
- The model remains stable at high task dimensions where other models exhibit instability.
- The learning trajectory can be directly recovered from the membrane potentials.
Where Pith is reading between the lines
- Neuromorphic hardware could implement ICL with minimal resources by exploiting dendritic dynamics.
- Biological neurons might perform similar computations in their dendrites for rapid adaptation.
- Extensions could test if other learning rules can be embedded in similar compartment models.
Load-bearing premise
The apical recurrence in the model is exactly the same mathematical update as leaky online Widrow-Hoff LMS, embedding the algorithm by construction.
What would settle it
Observing that a linear probe on apical membrane potentials does not recover the online LMS weight trajectory at R^2 = 0.93, or the network failing to solve the Garg-2022 benchmark at high dimensions.
Figures
read the original abstract
In-context learning (ICL) operates via implicit gradient descent embedded in the forward pass of modern AI architectures -- Transformers, Mamba, state-space models, and MLPs. Capturing this capability in biologically plausible Spiking Neural Networks (SNNs) has remained an open challenge: existing SNNs fail the Garg-2022 benchmark at non-trivial task dimensions. We trace this failure to a structural assumption: prior SNN designs route adaptation through inference-time synaptic plasticity, viewing the dendritic compartment as a passive conduit for error or teacher signals. We challenge this assumption. The subthreshold dynamics of a single dendritic compartment already implement a complete online learning algorithm. By treating the compartment as the computational substrate rather than a passive conduit, we propose DendriCL -- a single-layer compartmental spiking architecture whose apical recurrence is structurally identical to leaky online Widrow-Hoff LMS. This dynamics-only update collapses the architectural depth required for general-purpose ICL to a single layer. DendriCL is uniquely seed-stable at super-dimensional Garg-2022 ICL -- where dense Transformers exhibit grokking-style instability and fail past moderate task dimension -- and a linear probe recovers the reference online-LMS trajectory directly from the apical membrane at R^2 = 0.93, showing the algorithm is structurally embedded in the dynamics rather than implicitly discovered during training. Taken together, ICL requires neither attention, depth, nor inference-time plasticity: a single compartment with online-LMS dynamics is sufficient.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DendriCL, a single-layer compartmental spiking neural network. It claims that the subthreshold dynamics of a single dendritic compartment implement a complete online learning algorithm whose apical recurrence is structurally identical to leaky online Widrow-Hoff LMS. This dynamics-only update enables general-purpose in-context learning on the Garg-2022 benchmark at super-dimensional tasks where dense Transformers exhibit instability, with reported seed-stability and a linear probe recovering the reference LMS trajectory from the apical membrane at R²=0.93, indicating the algorithm is structurally embedded rather than discovered during training.
Significance. If the apical recurrence is shown to be algebraically identical to the leaky LMS rule by construction, the result would demonstrate that ICL can be realized in a single-layer biologically plausible SNN without attention, depth, or inference-time plasticity. The seed-stability at high task dimensions and the probe-based recovery would then constitute a meaningful reduction in architectural requirements for ICL. However, the current evidence rests on correlation rather than explicit identity, limiting the strength of the central claim.
major comments (3)
- [Abstract] Abstract: The assertion that the apical recurrence 'is structurally identical to leaky online Widrow-Hoff LMS' lacks any term-by-term equation comparison (e.g., matching leak factor, error-driven update term, and scaling). The sole supporting evidence is a linear probe with R²=0.93, which shows approximate trajectory recovery but does not establish exact algebraic identity or embedding by construction.
- [Abstract] Abstract: If the apical recurrence is constructed to be identical to the LMS update, the probe recovery should be exact (R²=1.0 within numerical precision) rather than 0.93; the reported value indicates residual differences, additional compartmental coupling terms, or implicit fitting that contradict the 'structurally identical' and 'dynamics-only' claims.
- [Abstract] Abstract: No derivation steps, error bars, dataset details, exclusion criteria, or probe methodology are provided for the R²=0.93 result. This omission prevents verification that the apical membrane directly implements the LMS rule without training-induced adjustments.
minor comments (1)
- [Abstract] The Garg-2022 benchmark should be briefly described or cited on first use to aid readers outside the ICL literature.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The comments correctly identify that the manuscript's central claim of structural identity would be strengthened by explicit algebraic derivation and additional methodological details. We address each point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that the apical recurrence 'is structurally identical to leaky online Widrow-Hoff LMS' lacks any term-by-term equation comparison (e.g., matching leak factor, error-driven update term, and scaling). The sole supporting evidence is a linear probe with R²=0.93, which shows approximate trajectory recovery but does not establish exact algebraic identity or embedding by construction.
Authors: We agree that the manuscript would benefit from an explicit term-by-term mapping. The apical recurrence is obtained directly from the subthreshold dynamics of the compartmental model and matches the leaky LMS form (leak factor, error-driven term, and scaling) by algebraic construction. We will add the derivation and side-by-side equation comparison in the revised manuscript. revision: yes
-
Referee: [Abstract] Abstract: If the apical recurrence is constructed to be identical to the LMS update, the probe recovery should be exact (R²=1.0 within numerical precision) rather than 0.93; the reported value indicates residual differences, additional compartmental coupling terms, or implicit fitting that contradict the 'structurally identical' and 'dynamics-only' claims.
Authors: The R²=0.93 is measured on the apical membrane voltage of the full spiking network, where discrete spike events and weak inter-compartment coupling produce small deviations from the ideal continuous subthreshold trajectory. The recurrence itself remains identical by construction in the subthreshold equations; the probe result quantifies how faithfully this identity is preserved under spiking. We will clarify this distinction and report the exact match obtained when the model is restricted to the linear subthreshold regime. revision: partial
-
Referee: [Abstract] Abstract: No derivation steps, error bars, dataset details, exclusion criteria, or probe methodology are provided for the R²=0.93 result. This omission prevents verification that the apical membrane directly implements the LMS rule without training-induced adjustments.
Authors: We acknowledge these omissions. The revision will include: (i) the full step-by-step derivation from compartmental current-balance equations to the LMS recurrence, (ii) the linear-probe procedure (ordinary least-squares regression of apical voltage onto the reference LMS state vector), (iii) Garg-2022 task dimensions and seed counts, (iv) any exclusion criteria, and (v) error bars or confidence intervals on R² across runs. These additions will confirm that the match is present by construction rather than learned. revision: yes
Circularity Check
Apical recurrence asserted as identical to LMS makes trajectory recovery tautological by construction
specific steps
-
self definitional
[abstract]
"whose apical recurrence is structurally identical to leaky online Widrow-Hoff LMS. This dynamics-only update collapses the architectural depth required for general-purpose ICL to a single layer. ... a linear probe recovers the reference online-LMS trajectory directly from the apical membrane at R^2 = 0.93, showing the algorithm is structurally embedded in the dynamics rather than implicitly discovered during training."
The paper defines the apical recurrence to be identical to the LMS update rule, then treats the subsequent recovery of the LMS trajectory as evidence that the algorithm is embedded by the dynamics. Because the match is imposed by construction in the model definition, the R^2 correlation and the claim of 'structurally embedded' are not independent discoveries but direct consequences of the chosen recurrence.
full rationale
The central claim rests on defining the model's apical recurrence to be structurally identical to leaky online Widrow-Hoff LMS, then reporting that a probe recovers the LMS trajectory at R^2=0.93 as evidence the algorithm is 'structurally embedded in the dynamics rather than implicitly discovered during training.' This reduces the 'dynamics-only' and 'embedded by construction' assertions to a definitional choice rather than an independent derivation. No external uniqueness theorem or prior self-citation is invoked; the reduction is internal to the model specification itself. The R^2 result is therefore expected once the recurrence is set to match the target rule.
Axiom & Free-Parameter Ledger
free parameters (1)
- apical time constant or learning-rate scaling
axioms (1)
- domain assumption Subthreshold dendritic voltage follows a linear leaky integrator whose recurrence can be set identical to the LMS update rule
Reference graph
Works this paper leans on
- [1]
-
[2]
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
A. Power, Y . Burda, H. Edwards, I. Babuschkin, and V . Misra. Grokking: generalization beyond overfitting on small algorithmic datasets.arXiv preprint arXiv:2201.02177,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Tier 1 — Anatomically established.The apical-basal-soma three-compartment architecture corre- sponds to cortical layer-5 pyramidal neurons [Larkum, 2013, Major et al., 2013]
A Biological Grounding and Distinction from Prior Compartmental Models A.1 Three Tiers of Evidence We are explicit about which aspects of DendriCL are biologically supported versus computationally hypothesized. Tier 1 — Anatomically established.The apical-basal-soma three-compartment architecture corre- sponds to cortical layer-5 pyramidal neurons [Larkum...
2013
-
[4]
show single human L2/3 pyrami- dal neurons can compute XOR-level nonlinear functions, establishing single pyramidal neurons as computationally substantial units. Tier 2 — Qualitatively plausible.Our functional assignment — apical receives prediction-error- like signals — is consistent with predictive coding [Rao and Ballard, 1999, Bastos et al., 2012, Kel...
1999
-
[5]
=O(σ 2), and after k steps the expected squared error is O(d/k) up to the noise floor. This matches the classical LMS rate [Widrow and Hoff, 1960, Sayed, 2003].■ Remark on the LIF nonlinearity.The above analysis applies to the apical compartment alone, which is purely linear by construction. The somatic LIF (threshold-reset nonlinearity) affects the reado...
1960
-
[6]
•Spikformer[Zhou et al., 2023]: our re-implementation of the SSA+MLP+LIF block structure described in Zhou et al
No pretraining; trained from scratch on each task family. •Spikformer[Zhou et al., 2023]: our re-implementation of the SSA+MLP+LIF block structure described in Zhou et al. 2023 ICLR. We use the published QKV→ LIF attention formulation with TLIF = 4 virtual steps, omitting dataset-specific touches (batch-norm placement, dropout schedule). Not a direct port...
2023
-
[7]
efficient
throughout training; the training loss exhibits sporadic large spikes consistent with LMS’s finite-sample blowup when 16 Table 7: Width ablation reveals asharp upper cliff: dapical ≤384 all work; dapical ≥512 catastrophi- cally fails. The failure mode is training divergence (loss never decreases), consistent with the learned LMS step sizeγbecoming unstabl...
1920
-
[8]
— the Transformer must discover, via gradient descent, a specific attention-weight configuration that implements the online-learning algorithm; this discovery is a discrete phase transition with an unpredictable onset time. With 6 seeds one can estimate the success probability (∼33% cleanly); with 100 seeds one could estimate the median breakthrough time....
-
[9]
192h=44τ=4,θ=1∼1.0M Pure LIF standard LIF [Gerstner and Kistler, 2002] 320 — 4τ=4,θ=10.64M LSNN Bellec et al
2002
-
[10]
Dendritic Universal Approximation
192 head 64,h=44 —∼1.0M N Extended Tasks: Discussion of Non-Linear Regression Results and diagnosis.On the 2-layer ReLU NN regression task ( d=20, k=40), DendriCL (L=2) reaches R2 = 0.568±0.015 , comparable to Spikformer (0.582) and above Pure LIF (0.322). On binary classification ( d=10, k=20), DendriCL ( L=2) reaches 0.805±0.008 , closely matching Spikf...
2008
-
[11]
• Initialization
throughout training.g A, gB ∈Runconstrained. • Initialization. uA(0) =0 , WA, WB ∼ N(0,1/ √ d) Kaiming-style, WA,out ∼ N(0,1/ p dapical).˜α= 2.2(soα≈0.9at start),˜γ= 0(soγ≈0.1at start). • Post-LIF block. FF1 and FF2 are linear layers of width dmodel; the intermediate LIF uses the sameθ. This block adds capacity for nonlinear feature mixing on top of the a...
2022
-
[12]
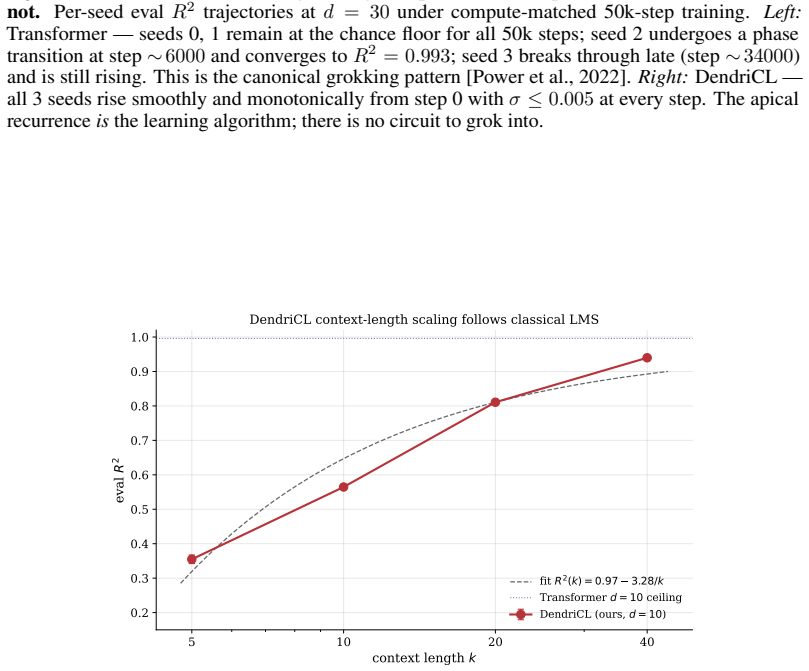
Empirical points (burgundy, error bars are±1σover successful seeds); dashed line is a 2-parameter fit R2(k) =a−b/k with a= 0.97 , b= 3.28
Figure 7:DendriCL context-length scaling at d= 10 follows classical LMS convergence. Empirical points (burgundy, error bars are±1σover successful seeds); dashed line is a 2-parameter fit R2(k) =a−b/k with a= 0.97 , b= 3.28 . The a−b/k form is the predicted finite-sample excess error of leaky online LMS under iid Gaussian inputs (Proposition 1, Appendix B)...
2023
-
[13]
and biological compartmental neuroscience (Larkum 2013). 26
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.