Accelerated Likelihood Maximization for Diffusion-based Versatile Content Generation
Pith reviewed 2026-07-01 05:58 UTC · model grok-4.3
The pith
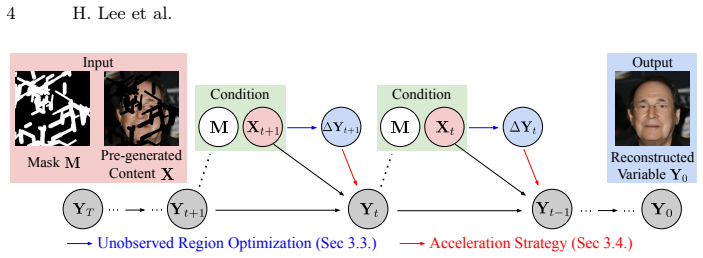
A training-free sampling strategy called ALM directly optimizes unobserved regions during reverse diffusion to produce globally coherent content from partial inputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce Accelerated Likelihood Maximization (ALM), a novel training-free sampling strategy integrated into the reverse diffusion process that significantly extends the applicability of diffusion models beyond simple generation tasks. Unlike previous methods that implicitly influence missing regions through pre-generated region constraints, we directly optimize the unobserved region during the sampling process, enabling globally coherent and plausible generation. Furthermore, we incorporate an acceleration strategy that significantly improves computational efficiency without sacrificing performance. Experimental results demonstrate that ALM consistently outperforms state-of-the-art metho
What carries the argument
Accelerated Likelihood Maximization (ALM), the training-free sampler that directly optimizes unobserved regions inside the reverse diffusion process.
If this is right
- Diffusion models can now handle a broader set of partial-input tasks without task-specific retraining.
- Global consistency improves because the method explicitly maximizes likelihood over missing variables rather than relying on indirect constraints.
- Sampling speed increases via the built-in acceleration strategy while quality is preserved.
- The same framework applies across multiple data domains and content-generation tasks.
Where Pith is reading between the lines
- The direct-optimization step could be ported to other iterative generative processes that currently use only conditioning.
- If the acceleration preserves likelihood quality, similar speed-ups might be tested on related score-based or flow-based models.
- Task-specific fine-tuning budgets could shrink for applications such as video completion or 3D shape inpainting.
Load-bearing premise
Directly optimizing the unobserved region during sampling together with the acceleration step will produce globally coherent results without new inconsistencies or loss of performance.
What would settle it
A controlled comparison on standard inpainting benchmarks in which ALM outputs receive lower coherence scores or visible artifacts than the strongest prior training-free baseline.
Figures






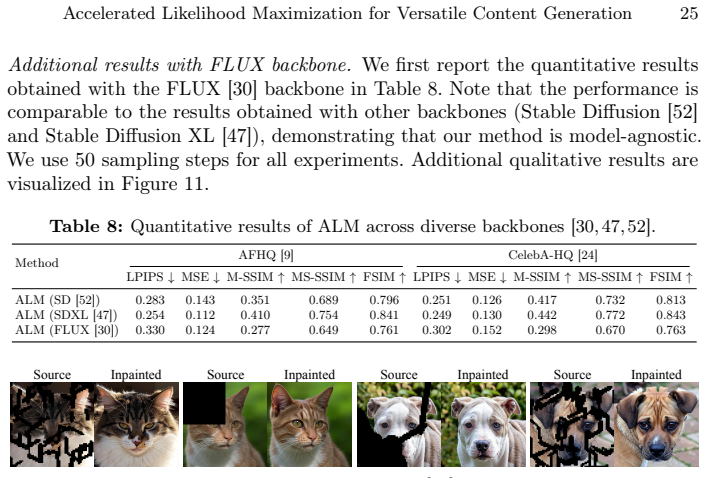

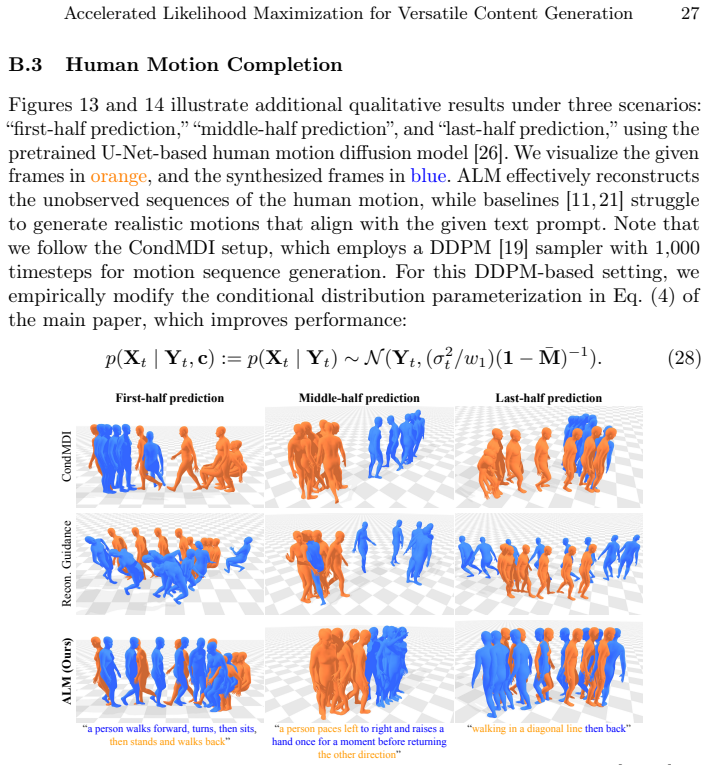
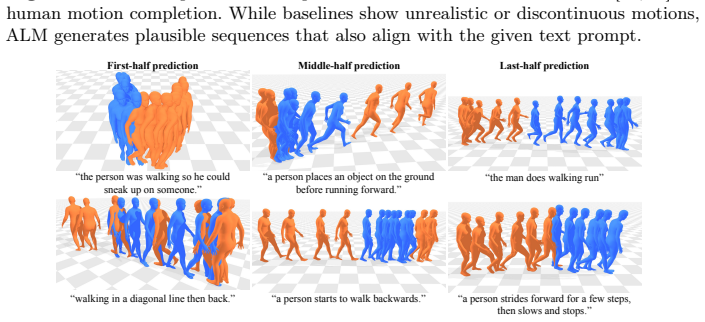


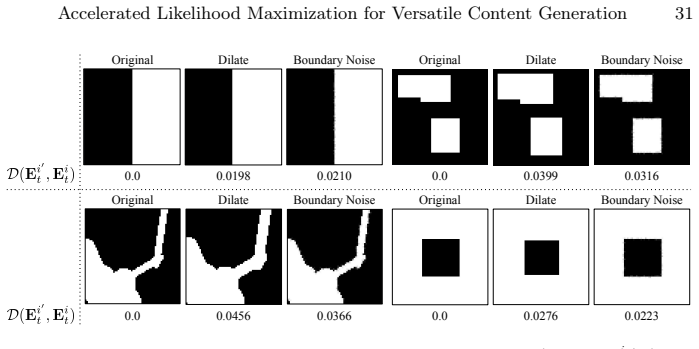
read the original abstract
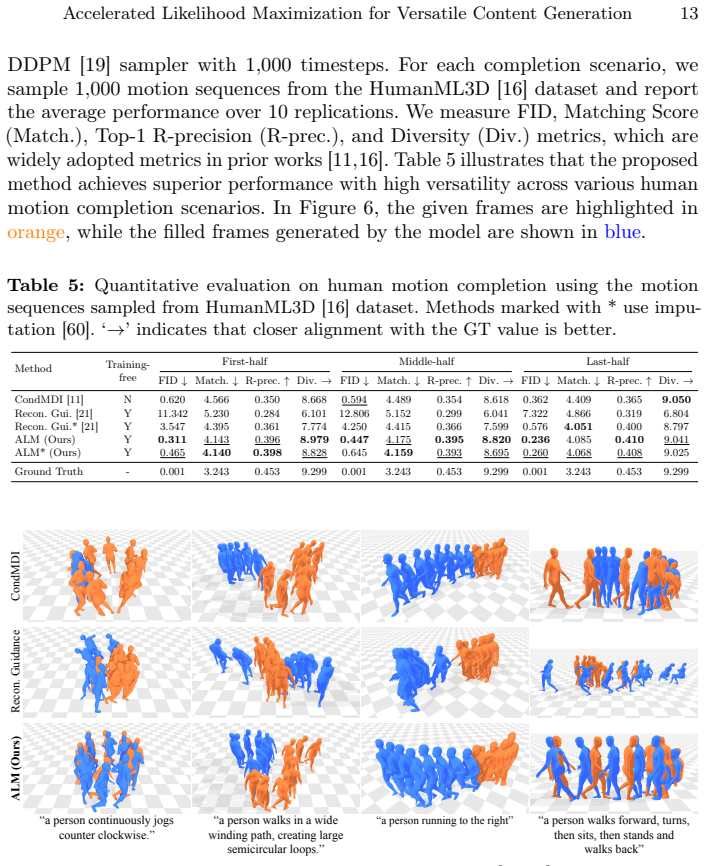
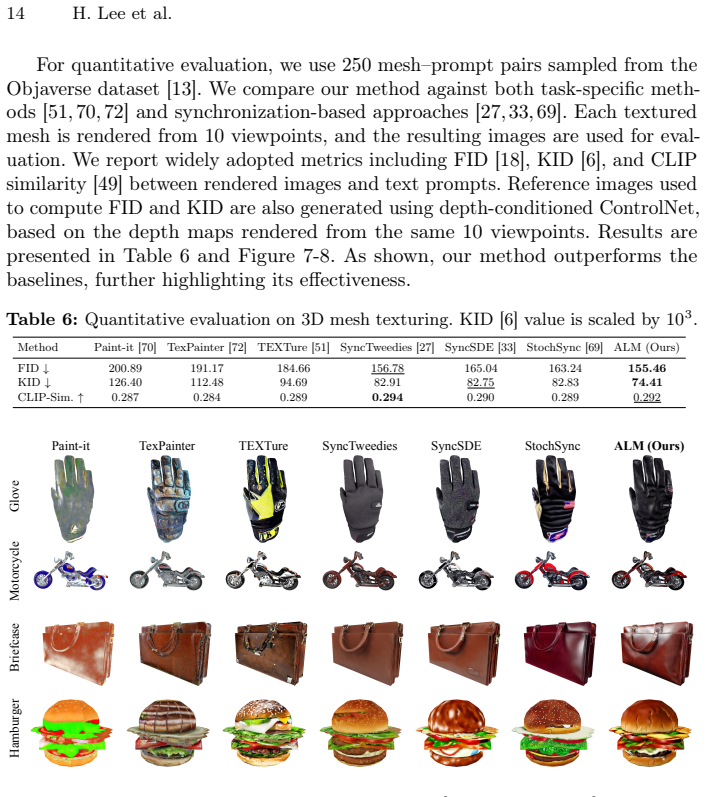
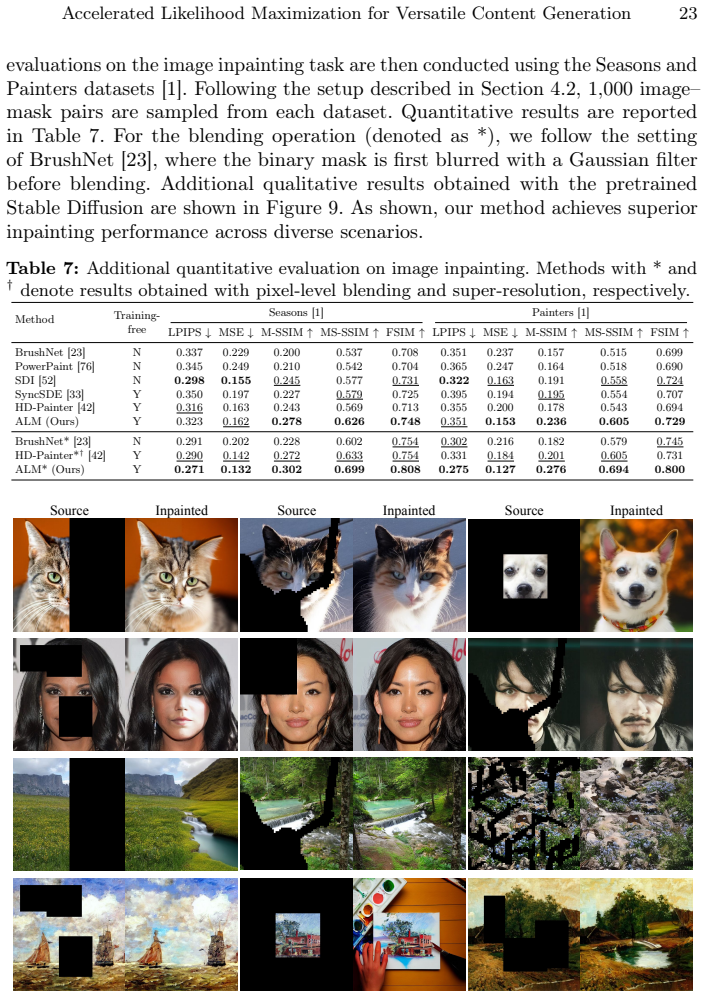
Generating diverse, coherent, and plausible content from partially given inputs remains a fundamental challenge for diffusion models. Existing approaches face clear limitations: training-based approaches offer strong task-specific results but require costly computation, and they generalize poorly across tasks. Training-free approaches offer better efficiency, but they do not explicitly optimize over unobserved variables, leading to globally inconsistent results. To address these limitations, we introduce Accelerated Likelihood Maximization (ALM), a novel training-free sampling strategy integrated into the reverse diffusion process that significantly extends the applicability of diffusion models beyond simple generation tasks. Unlike previous methods that implicitly influence missing regions through pre-generated region constraints, we directly optimize the unobserved region during the sampling process, enabling globally coherent and plausible generation. Furthermore, we incorporate an acceleration strategy that significantly improves computational efficiency without sacrificing performance. Experimental results demonstrate that ALM consistently outperforms state-of-the-art methods in various data domains and tasks, establishing a powerful paradigm for versatile content generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Accelerated Likelihood Maximization (ALM), a training-free sampling strategy integrated into the reverse diffusion process. ALM directly optimizes unobserved regions (unlike prior methods that only apply implicit constraints via pre-generated regions) to produce globally coherent and plausible outputs from partial inputs. It further incorporates an acceleration strategy to improve efficiency without performance loss, and reports consistent outperformance over state-of-the-art methods across data domains and tasks.
Significance. If the algorithmic construction and empirical results hold, ALM would meaningfully extend diffusion models to versatile content-generation settings (inpainting, outpainting, conditional synthesis) while remaining training-free, addressing a clear gap between task-specific trained methods and existing training-free baselines that lack explicit optimization over missing variables.
major comments (2)
- [§3.2] §3.2, Algorithm 1: the update rule for the unobserved variables (Eq. 7) is presented as a direct likelihood maximization step, but the manuscript does not derive or bound the effect of this step on the overall reverse-process marginal; a short proof or reference to the preservation of the learned score would strengthen the claim that global coherence is achieved without introducing new inconsistencies.
- [§4.3] §4.3, Table 2: the reported gains on the outpainting task are given without error bars or statistical significance tests across the 5 random seeds; given that the acceleration schedule (Eq. 12) introduces additional hyperparameters, it is unclear whether the observed improvements are robust or sensitive to seed and schedule choice.
minor comments (3)
- The abstract claims 'consistent outperformance' but supplies no quantitative numbers; a single sentence summarizing the key metric improvements would improve readability.
- [§3.3] Notation for the unobserved region mask is introduced in §2 but reused without redefinition in §3.3; a brief reminder or table of symbols would help.
- Figure 4 caption does not state the number of diffusion steps used for the visualized samples; this detail is needed to interpret the visual comparison with baselines.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and recommendation for minor revision. Below we respond point-by-point to the major comments.
read point-by-point responses
-
Referee: [§3.2] §3.2, Algorithm 1: the update rule for the unobserved variables (Eq. 7) is presented as a direct likelihood maximization step, but the manuscript does not derive or bound the effect of this step on the overall reverse-process marginal; a short proof or reference to the preservation of the learned score would strengthen the claim that global coherence is achieved without introducing new inconsistencies.
Authors: We thank the referee for highlighting this point. The update in Eq. 7 is obtained by maximizing the conditional likelihood of the unobserved variables given the observed ones at each reverse step. We acknowledge that an explicit derivation of its effect on the reverse-process marginal is absent from the current text. In the revision we will insert a short proof sketch establishing that the step preserves the learned score by operating conditionally on the fixed observed regions and the pre-defined diffusion schedule, thereby avoiding new inconsistencies. revision: yes
-
Referee: [§4.3] §4.3, Table 2: the reported gains on the outpainting task are given without error bars or statistical significance tests across the 5 random seeds; given that the acceleration schedule (Eq. 12) introduces additional hyperparameters, it is unclear whether the observed improvements are robust or sensitive to seed and schedule choice.
Authors: We agree that error bars and significance testing would strengthen the presentation. The numbers in Table 2 are means over five independent random seeds; the observed gains are stable across seeds. In the revised manuscript we will add standard-deviation error bars to Table 2 and include a footnote reporting paired t-test p-values. We will also add a short discussion (and supplementary ablation) confirming that performance remains robust for reasonable choices of the acceleration-schedule hyperparameters in Eq. 12. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper proposes a new algorithmic method (ALM) for training-free sampling in diffusion models, describing an explicit optimization step over unobserved regions during the reverse process plus an acceleration schedule. No mathematical derivations, fitted parameters, or first-principles claims appear that reduce to their own inputs by construction. The central contribution rests on the concrete algorithmic construction and empirical comparisons to prior methods, which are presented as independent validation rather than self-referential. No self-citation chains, uniqueness theorems, or ansatzes are invoked in a load-bearing way. This is a standard methodological paper whose claims are self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: CVPRW (2018)
Anoosheh, A., Agustsson, E., Timofte, R., Van Gool, L.: Combogan: Unrestrained scalability for image domain translation. In: CVPRW (2018)
2018
-
[2]
ACM computing surveys (CSUR) (1991)
Aurenhammer, F.: Voronoi diagrams—a survey of a fundamental geometric data structure. ACM computing surveys (CSUR) (1991)
1991
-
[3]
SIGGRAPH (2023)
Avrahami, O., Fried, O., Lischinski, D.: Blended latent diffusion. SIGGRAPH (2023)
2023
-
[4]
In: ICCV (2021)
Bain, M., Nagrani, A., Varol, G., Zisserman, A.: Frozen in time: A joint video and image encoder for end-to-end retrieval. In: ICCV (2021)
2021
-
[5]
In: ICML (2023)
Bar-Tal, O., Yariv, L., Lipman, Y., Dekel, T.: Multidiffusion: Fusing diffusion paths for controlled image generation. In: ICML (2023)
2023
-
[6]
ICLR (2018)
Bińkowski, M., Sutherland, D.J., Arbel, M., Gretton, A.: Demystifying mmd gans. ICLR (2018)
2018
-
[7]
https://github.com/kakaobrain/coyo-dataset (2022), accessed: June 29, 2026
Byeon, M., Park, B., Kim, H., Lee, S., Baek, W., Kim, S.: Coyo-700m: Image-text pair dataset. https://github.com/kakaobrain/coyo-dataset (2022), accessed: June 29, 2026
2022
-
[8]
In: ICLR (2024)
Chen, X., Wang, Y., Zhang, L., Zhuang, S., Ma, X., Yu, J., Wang, Y., Lin, D., Qiao, Y., Liu, Z.: Seine: Short-to-long video diffusion model for generative transition and prediction. In: ICLR (2024)
2024
-
[9]
In: CVPR (2020) 16 H
Choi, Y., Uh, Y., Yoo, J., Ha, J.W.: Stargan v2: Diverse image synthesis for multiple domains. In: CVPR (2020) 16 H. Lee et al
2020
-
[10]
ICLR (2023)
Chung, H., Kim, J., Mccann, M.T., Klasky, M.L., Ye, J.C.: Diffusion posterior sampling for general noisy inverse problems. ICLR (2023)
2023
-
[11]
In: SIGGRAPH (2024)
Cohan, S., Tevet, G., Reda, D., Peng, X.B., van de Panne, M.: Flexible motion in-betweening with diffusion models. In: SIGGRAPH (2024)
2024
-
[12]
In: WACV (2024)
Corneanu, C., Gadde, R., Martinez, A.M.: Latentpaint: Image inpainting in latent space with diffusion models. In: WACV (2024)
2024
-
[13]
CVPR (2023)
Deitke, M., Schwenk, D., Salvador, J., Weihs, L., Michel, O., VanderBilt, E., Schmidt, L., Ehsani, K., Kembhavi, A., Farhadi, A.: Objaverse: A universe of annotated 3d objects. CVPR (2023)
2023
-
[14]
In: ICML (2024)
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al.: Scaling rectified flow transformers for high-resolution image synthesis. In: ICML (2024)
2024
-
[15]
ICML (2026)
Geyfman, D., Draxler, F., Groeneveld, J., Lee, H., Karaletsos, T., Mandt, S.: Calibrated test-time guidance for bayesian inference. ICML (2026)
2026
-
[16]
In: CVPR (2022)
Guo, C., Zou, S., Zuo, X., Wang, S., Ji, W., Li, X., Cheng, L.: Generating diverse and natural 3d human motions from text. In: CVPR (2022)
2022
-
[17]
LTX-Video: Realtime Video Latent Diffusion
HaCohen, Y., Chiprut, N., Brazowski, B., Shalem, D., Moshe, D., Richardson, E., Levin, E., Shiran, G., Zabari, N., Gordon, O., Panet, P., Weissbuch, S., Kulikov, V., Bitterman, Y., Melumian, Z., Bibi, O.: Ltx-video: Realtime video latent diffusion. arXiv:2501.00103 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
NIPS (2017)
Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B., Hochreiter, S.: Gans trained by a two time-scale update rule converge to a local nash equilibrium. NIPS (2017)
2017
-
[19]
NeurIPS (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. NeurIPS (2020)
2020
-
[20]
NeurIPS Workshop (2021)
Ho, J., Salimans, T.: Classifier-free diffusion guidance. NeurIPS Workshop (2021)
2021
-
[21]
NeurIPS (2022)
Ho, J., Salimans, T., Gritsenko, A., Chan, W., Norouzi, M., Fleet, D.J.: Video diffusion models. NeurIPS (2022)
2022
-
[22]
ICLR (2023)
Hong, W., Ding, M., Zheng, W., Liu, X., Tang, J.: Cogvideo: Large-scale pretraining for text-to-video generation via transformers. ICLR (2023)
2023
-
[23]
In: ECCV (2024)
Ju, X., Liu, X., Wang, X., Bian, Y., Shan, Y., Xu, Q.: Brushnet: A plug-and-play image inpainting model with decomposed dual-branch diffusion. In: ECCV (2024)
2024
-
[24]
ICLR (2018)
Karras, T., Aila, T., Laine, S., Lehtinen, J.: Progressive growing of gans for improved quality, stability, and variation. ICLR (2018)
2018
-
[25]
NeurIPS (2022)
Karras, T., Aittala, M., Aila, T., Laine, S.: Elucidating the design space of diffusion- based generative models. NeurIPS (2022)
2022
-
[26]
In: ICCV (2023)
Karunratanakul, K., Preechakul, K., Suwajanakorn, S., Tang, S.: Guided motion diffusion for controllable human motion synthesis. In: ICCV (2023)
2023
-
[27]
NeurIPS (2024)
Kim, J., Koo, J., Yeo, K., Sung, M.: Synctweedies: A general generative framework based on synchronized diffusions. NeurIPS (2024)
2024
-
[28]
NeurIPS (2024)
Kim, J., Kang, J., Choi, J., Han, B.: Fifo-diffusion: Generating infinite videos from text without training. NeurIPS (2024)
2024
-
[29]
Auto-Encoding Variational Bayes
Kingma, D.P., Welling, M.: Auto-encoding variational bayes. arXiv:1312.6114 (2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[30]
Labs, B.F.: Flux.https://github.com/black-forest-labs/flux (2024), accessed: June 29, 2026
2024
-
[31]
In: CVPR (2026)
Lai, Z., Zhao, Y., Zhao, Z., Yang, X., Huang, X., Huang, J., Yue, X., Guo, C.: Natex: Seamless texture generation as latent color diffusion. In: CVPR (2026)
2026
-
[32]
ACM TOG (2020)
Laine, S., Hellsten, J., Karras, T., Seol, Y., Lehtinen, J., Aila, T.: Modular primitives for high-performance differentiable rendering. ACM TOG (2020)
2020
-
[33]
In: CVPR (2025) Accelerated Likelihood Maximization for Versatile Content Generation 17
Lee, H., Lee, H., Han, S.: Syncsde: A probabilistic framework for diffusion synchro- nization. In: CVPR (2025) Accelerated Likelihood Maximization for Versatile Content Generation 17
2025
-
[34]
NeurIPS (2023)
Lee, H., Kang, M., Han, B.: Conditional score guidance for text-driven image-to- image translation. NeurIPS (2023)
2023
-
[35]
NeurIPS (2023)
Lee, Y., Kim, K., Kim, H., Sung, M.: Syncdiffusion: Coherent montage via synchro- nized joint diffusions. NeurIPS (2023)
2023
-
[36]
CVPR (2026)
Liang, Y., Luo, K., Chen, X., Chen, R., Yan, H., Li, W., Liu, J., Tan, P.: Unitex: Universal high fidelity generative texturing for 3d shapes. CVPR (2026)
2026
-
[37]
ICLR (2023)
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. ICLR (2023)
2023
-
[38]
ICLR (2023)
Liu, X., Gong, C., Liu, Q.: Flow straight and fast: Learning to generate and transfer data with rectified flow. ICLR (2023)
2023
-
[39]
In: CVPR Findings (2026)
Liu, Y., Hou, X., Wu, J., Liu, B., Zhang, Y., Song, G., Liu, Y., Tian, C., Luo, G., You, H.: Blend-aware latent diffusion: Mitigating stitched seams in image inpainting. In: CVPR Findings (2026)
2026
-
[40]
In: SIGGRAPH Asia (2024)
Liu, Y., Xie, M., Liu, H., Wong, T.T.: Text-guided texturing by synchronized multi-view diffusion. In: SIGGRAPH Asia (2024)
2024
-
[41]
In: CVPR (2022)
Lugmayr, A., Danelljan, M., Romero, A., Yu, F., Timofte, R., Van Gool, L.: Repaint: Inpainting using denoising diffusion probabilistic models. In: CVPR (2022)
2022
-
[42]
In: ICLR (2025)
Manukyan, H., Sargsyan, A., Atanyan, B., Wang, Z., Navasardyan, S., Shi, H.: Hd-painter: high-resolution and prompt-faithful text-guided image inpainting with diffusion models. In: ICLR (2025)
2025
-
[43]
ICML (2025)
Pandey, K., Sofian, F.M., Draxler, F., Karaletsos, T., Mandt, S.: Variational control for guidance in diffusion models. ICML (2025)
2025
-
[44]
NeurIPS (2019)
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., et al.: Pytorch: An imperative style, high- performance deep learning library. NeurIPS (2019)
2019
-
[45]
In: ICCV (2023)
Peebles, W., Xie, S.: Scalable diffusion models with transformers. In: ICCV (2023)
2023
-
[46]
In: Seminal Graphics Papers: Pushing the Boundaries, Volume 2 (2023)
Pérez, P., Gangnet, M., Blake, A.: Poisson image editing. In: Seminal Graphics Papers: Pushing the Boundaries, Volume 2 (2023)
2023
-
[47]
ICLR (2024)
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Müller, J., Penna, J., Rombach, R.: Sdxl: Improving latent diffusion models for high-resolution image synthesis. ICLR (2024)
2024
-
[48]
ICLR (2024)
Qiu, H., Xia, M., Zhang, Y., He, Y., Wang, X., Shan, Y., Liu, Z.: Freenoise: Tuning-free longer video diffusion via noise rescheduling. ICLR (2024)
2024
-
[49]
In: ICML (2021)
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: ICML (2021)
2021
-
[50]
Accelerating 3D Deep Learning with PyTorch3D
Ravi, N., Reizenstein, J., Novotny, D., Gordon, T., Lo, W.Y., Johnson, J., Gkioxari, G.: Accelerating 3d deep learning with pytorch3d. arXiv:2007.08501 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2007
-
[51]
In: SIGGRAPH (2023)
Richardson, E., Metzer, G., Alaluf, Y., Giryes, R., Cohen-Or, D.: Texture: Text- guided texturing of 3d shapes. In: SIGGRAPH (2023)
2023
-
[52]
In: CVPR (2022)
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: CVPR (2022)
2022
-
[53]
In: International Conference on Medical image computing and computer-assisted intervention (2015)
Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomedical image segmentation. In: International Conference on Medical image computing and computer-assisted intervention (2015)
2015
-
[54]
NeurIPS (2022)
Saharia, C., Chan, W., Saxena, S., Li, L., Whang, J., Denton, E.L., Ghasemipour, K., Gontijo Lopes, R., Karagol Ayan, B., Salimans, T., et al.: Photorealistic text- to-image diffusion models with deep language understanding. NeurIPS (2022)
2022
-
[55]
NeurIPS (2022) 18 H
Schuhmann, C., Beaumont, R., Vencu, R., Gordon, C., Wightman, R., Cherti, M., Coombes, T., Katta, A., Mullis, C., Wortsman, M., et al.: Laion-5b: An open large-scale dataset for training next generation image-text models. NeurIPS (2022) 18 H. Lee et al
2022
-
[56]
In: ICML (2015)
Sohl-Dickstein, J., Weiss, E., Maheswaranathan, N., Ganguli, S.: Deep unsupervised learning using nonequilibrium thermodynamics. In: ICML (2015)
2015
-
[57]
ICLR (2021)
Song, J., Meng, C., Ermon, S.: Denoising diffusion implicit models. ICLR (2021)
2021
-
[58]
In: ICLR (2023)
Song, J., Vahdat, A., Mardani, M., Kautz, J.: Pseudoinverse-guided diffusion models for inverse problems. In: ICLR (2023)
2023
-
[59]
ICLR (2021)
Song, Y., Sohl-Dickstein, J., Kingma, D.P., Kumar, A., Ermon, S., Poole, B.: Score-based generative modeling through stochastic differential equations. ICLR (2021)
2021
-
[60]
ICLR (2023)
Tevet, G., Raab, S., Gordon, B., Shafir, Y., Cohen-Or, D., Bermano, A.H.: Human motion diffusion model. ICLR (2023)
2023
-
[61]
Unterthiner, T., Van Steenkiste, S., Kurach, K., Marinier, R., Michalski, M., Gelly, S.: Fvd: A new metric for video generation (2019)
2019
-
[62]
IJCV (2025)
Wang, Y., Chen, X., Ma, X., Zhou, S., Huang, Z., Wang, Y., Yang, C., He, Y., Yu, J., Yang, P., et al.: Lavie: High-quality video generation with cascaded latent diffusion models. IJCV (2025)
2025
-
[63]
In: The thrity-seventh asilomar conference on signals, systems & computers, 2003 (2003)
Wang, Z., Simoncelli, E.P., Bovik, A.C.: Multiscale structural similarity for image quality assessment. In: The thrity-seventh asilomar conference on signals, systems & computers, 2003 (2003)
2003
-
[64]
Wu, C., Li, J., Zhou, J., Lin, J., Gao, K., Yan, K., ming Yin, S., Bai, S., Xu, X., Chen, Y., Chen, Y., Tang, Z., Zhang, Z., Wang, Z., Yang, A., Yu, B., Cheng, C., Liu, D., Li, D., Zhang, H., Meng, H., Wei, H., Ni, J., Chen, K., Cao, K., Peng, L., Qu, L., Wu, M., Wang, P., Yu, S., Wen, T., Feng, W., Xu, X., Wang, Y., Zhang, Y., Zhu, Y., Wu, Y., Cai, Y., L...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[65]
ICML (2024)
Wu, H., Zhang, Z., Zhang, W., Chen, C., Liao, L., Li, C., Gao, Y., Wang, A., Zhang, E., Sun, W., et al.: Q-align: Teaching lmms for visual scoring via discrete text-defined levels. ICML (2024)
2024
-
[66]
In: CVPR (2026)
Wu, L., Yu, J., Jin, L., Wang, H., Zheng, B., Yang, X., Jiang, H., Xia, F., Ling, F., Deng, J., Jin, X.: Unifying precise keyframes and semantic control via multi-level diffusion. In: CVPR (2026)
2026
-
[67]
Flexpainter: Flexible and multi-view consistent texture generation
Yan, D., Wu, L., Lin, J., Wang, L., Xu, T., Chen, Z., Yang, Z., Xu, L., Zhang, S., Chen, Y.: Flexpainter: Flexible and multi-view consistent texture generation. arXiv:2506.02620 (2025)
-
[68]
In: ICLR (2025)
Yang, Z., Teng, J., Zheng, W., Ding, M., Huang, S., Xu, J., Yang, Y., Hong, W., Zhang, X., Feng, G., Yin, D., Yuxuan.Zhang, Wang, W., Cheng, Y., Xu, B., Gu, X., Dong, Y., Tang, J.: Cogvideox: Text-to-video diffusion models with an expert transformer. In: ICLR (2025)
2025
-
[69]
ICLR (2025)
Yeo, K., Kim, J., Sung, M.: Stochsync: Stochastic diffusion synchronization for image generation in arbitrary spaces. ICLR (2025)
2025
-
[70]
In: CVPR (2024)
Youwang, K., Oh, T.H., Pons-Moll, G.: Paint-it: Text-to-texture synthesis via deep convolutional texture map optimization and physically-based rendering. In: CVPR (2024)
2024
-
[71]
In: CVPR (2024)
Zeng, X., Chen, X., Qi, Z., Liu, W., Zhao, Z., Wang, Z., Fu, B., Liu, Y., Yu, G.: Paint3d: Paint anything 3d with lighting-less texture diffusion models. In: CVPR (2024)
2024
-
[72]
In: SIGGRAPH (2024)
Zhang, H., Pan, Z., Zhang, C., Zhu, L., Gao, X.: Texpainter: Generative mesh texturing with multi-view consistency. In: SIGGRAPH (2024)
2024
-
[73]
IEEE transactions on Image Processing (2011)
Zhang, L., Zhang, L., Mou, X., Zhang, D.: Fsim: A feature similarity index for image quality assessment. IEEE transactions on Image Processing (2011)
2011
-
[74]
In: ICCV (2023) Accelerated Likelihood Maximization for Versatile Content Generation 19
Zhang, L., Rao, A., Agrawala, M.: Adding conditional control to text-to-image diffusion models. In: ICCV (2023) Accelerated Likelihood Maximization for Versatile Content Generation 19
2023
-
[75]
In: CVPR (2018)
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: CVPR (2018)
2018
-
[76]
In: ECCV (2024) 20 H
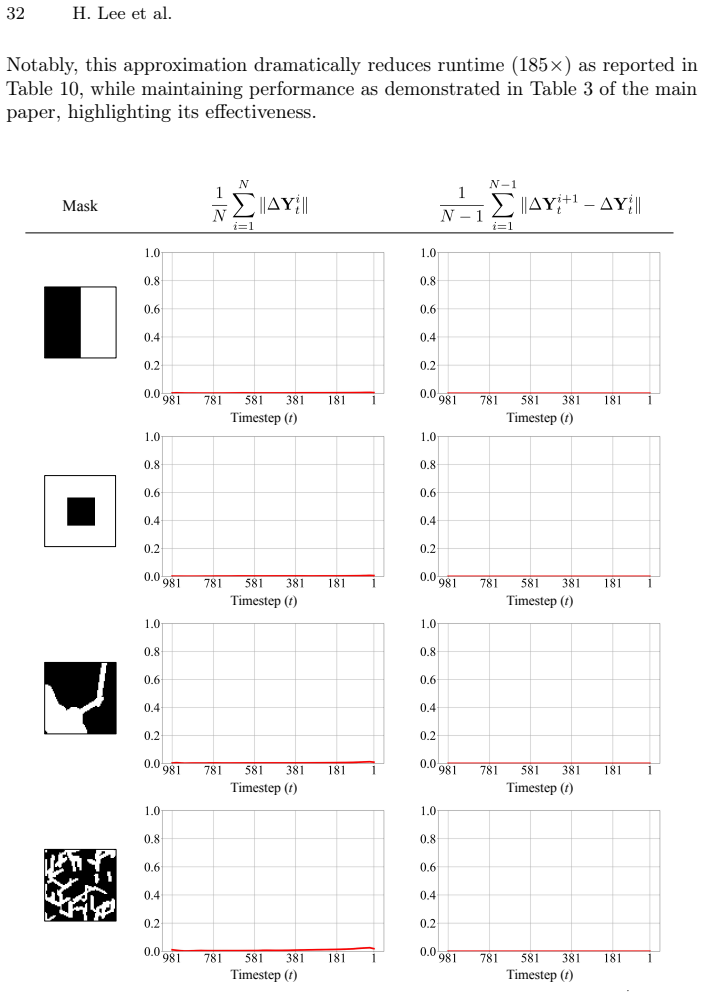
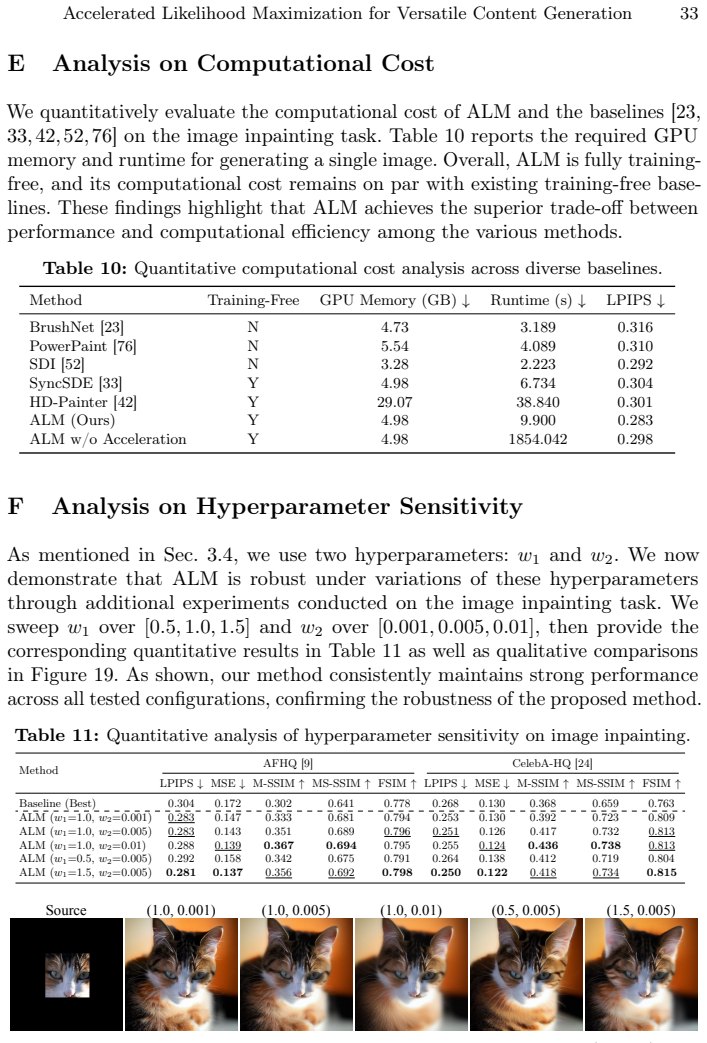
Zhuang, J., Zeng, Y., Liu, W., Yuan, C., Chen, K.: A task is worth one word: Learning with task prompts for high-quality versatile image inpainting. In: ECCV (2024) 20 H. Lee et al. Supplementary Material In this supplementary material, we first provide a detailed derivation of our method in Appendix A. We then present additional experimental details and ...
2024
-
[77]
A photo of a forest with a misty fog
(24) From Eq.(23) and (24), we obtainYi 0 =Y i t −tv θ(Yi t, t, c). Substituting this into Eq. (23) yields ϵθ(Yi t, t, c) =Y i t + (1−t)v θ(Yi t, t,c). (25) Using this relation, the score function is approximated as ∇Yi t logp(Y i t|c)≈ − ϵθ(Yi t, t, c) σt =− Yi t + (1−t)v θ(Yi t, t,c) σt , (26) whereσ t =tin flow matching frameworks. Secondly, we adopt a...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.