TriALS: Triphasic-Aided Liver Lesion Segmentation Benchmark in Non-Contrast CT
Pith reviewed 2026-05-20 18:51 UTC · model grok-4.3
The pith
A new benchmark shows liver lesion segmentation on non-contrast CT reaches only 0.57 Dice even with triphasic training data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
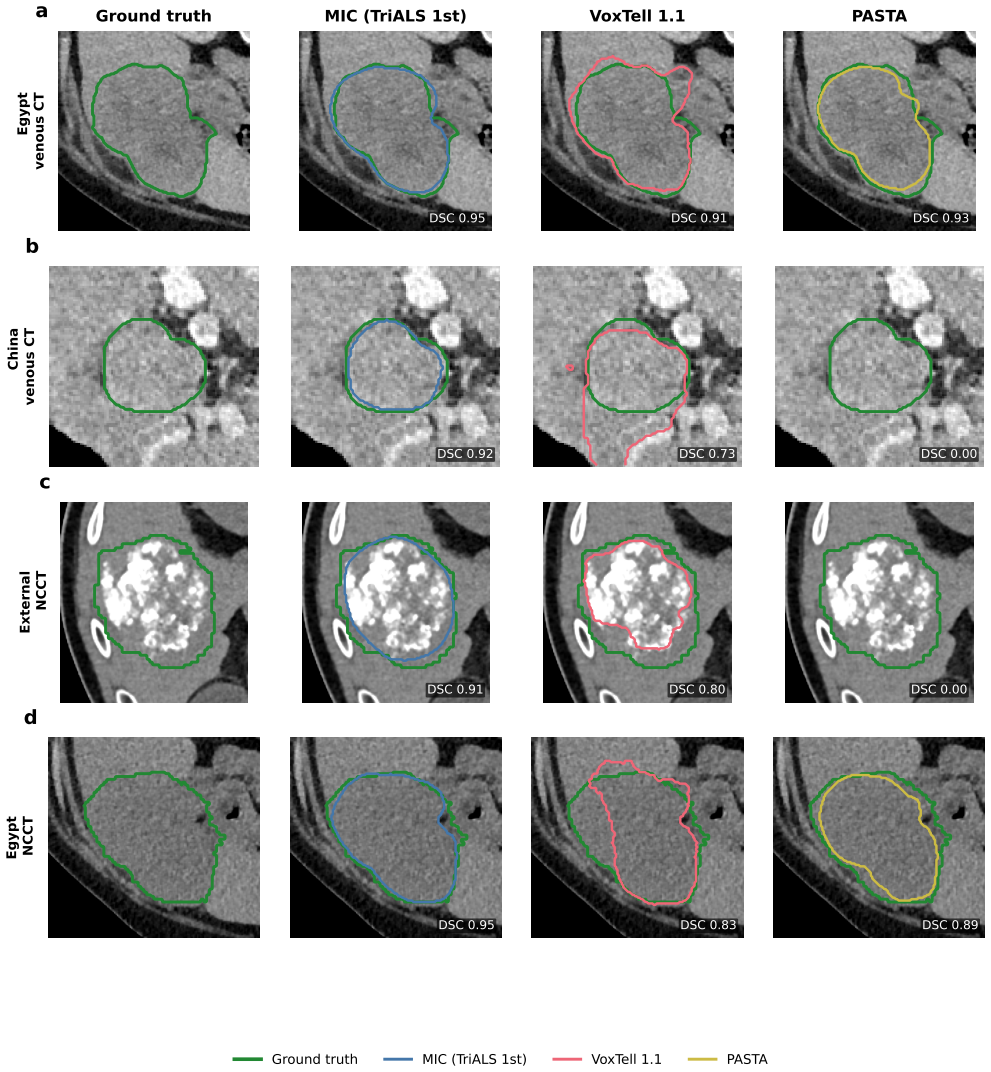
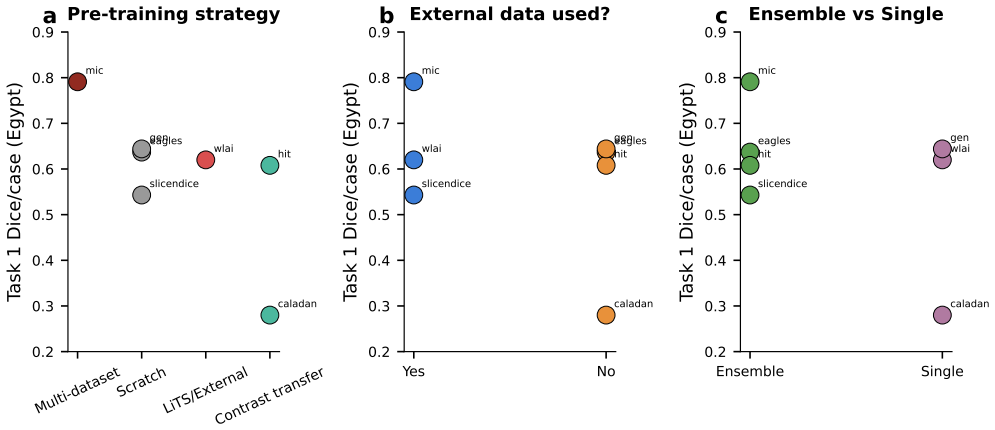
The TriALS challenge establishes a standardized, multi-centre benchmark for liver lesion segmentation under contrast-limited conditions. Using 600 volumes from 150 cases acquired at Egyptian and Chinese sites, the evaluation shows that leading methods achieve near human-level accuracy on venous-phase images but suffer a substantial drop on non-contrast CT, with external validation confirming gains of up to 28 percent Dice over off-the-shelf models. Algorithm success is driven primarily by data scale and pre-training strategy, yet a persistent perceptual barrier on non-contrast scans remains even after these factors are optimized.
What carries the argument
The TriALS benchmark dataset, consisting of 150 multi-centre cases with four-phase CT acquisitions that enable triphasic-aided training for non-contrast segmentation evaluation.
If this is right
- Training data volume and choice of pre-training directly determine how well a method performs on non-contrast liver lesion segmentation.
- Methods tuned on the TriALS data generalize better to unseen institutions than standard pre-trained models on non-contrast scans.
- A performance ceiling on non-contrast images persists that cannot be removed by increasing pre-training scale alone.
- The benchmark supplies a common reference that lets groups in different regions compare progress under realistic contrast constraints.
Where Pith is reading between the lines
- Future architectures may need explicit mechanisms for handling the reduced lesion conspicuity that occurs without contrast rather than relying solely on more data.
- The same triphasic-to-non-contrast transfer pattern could be tested on other abdominal organs to see whether the observed perceptual barrier is liver-specific.
- If the gap remains after larger-scale pre-training, synthetic contrast generation or unpaired image translation techniques become higher-priority research directions.
- The external-validation gain suggests that releasing the full dataset and code could accelerate method development in settings without access to contrast agents.
Load-bearing premise
The 150-case multi-centre collection from Egyptian and Chinese hospitals adequately captures the range of clinical variability found in low-resource settings across Africa and Asia.
What would settle it
A new method trained only on non-contrast data that exceeds 0.65 mean Dice on the external NCCT test set without any triphasic volumes.
Figures









read the original abstract
Automated segmentation of liver lesions on non-contrast computed tomography (NCCT) is clinically important but fundamentally challenging, particularly in low-resource settings across Africa and Asia where contrast agents are frequently unavailable. Progress has been limited by the absence of annotated NCCT benchmarks. Here we describe the TriALS challenge for automated liver lesion segmentation under contrast-limited conditions, supported by a multi-centre dataset of 150 cases with four-phase CT acquisitions (600 volumes) from Egyptian and Chinese institutions. Algorithms were evaluated on 70 cases from three institutions, including an independent external cohort. The top-performing method achieved a mean venous-phase Dice of 0.754, consistent with human-level performance, yet dropped to 0.57 on NCCT. On external validation, the leading method outperformed off-the-shelf models by up to 28% in Dice on NCCT. Algorithm performance was most strongly predicted by training data scale and pre-training strategy. A cross-year comparison exposed a persistent perceptual barrier on NCCT that scaling pre-training alone cannot overcome. Data, annotations, and code are available at https://github.com/xmed-lab/TriALS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the TriALS benchmark for automated liver lesion segmentation on non-contrast CT (NCCT) under contrast-limited conditions. It releases a multi-centre dataset of 150 cases with four-phase CT acquisitions (600 volumes) from Egyptian and Chinese institutions, evaluates participating algorithms on a 70-case test set that includes an independent external cohort, and reports that the top method reaches a mean venous-phase Dice of 0.754 (human-level) but drops to 0.57 on NCCT, with up to 28% Dice improvement over off-the-shelf models on external NCCT. Performance correlates most strongly with training data scale and pre-training strategy; a cross-year analysis indicates a persistent perceptual barrier on NCCT. Data, annotations, and code are made public.
Significance. If the empirical results hold, the work supplies a much-needed public benchmark and reproducible baseline for NCCT liver-lesion segmentation, directly addressing a clinical gap in low-resource environments. The concrete Dice scores on internal and external held-out data, together with the public release of data, annotations, and code, enable independent verification and future comparisons. The finding that scaling pre-training alone does not close the NCCT gap is a useful falsifiable observation for the field.
major comments (1)
- [Abstract and external-validation paragraph] Abstract and external-validation paragraph: the positioning of the benchmark as directly relevant to 'low-resource settings across Africa and Asia' rests on the untested assumption that the Egyptian-Chinese four-phase acquisitions capture scanner variability, lesion etiology distributions, and acquisition protocols typical of other low-resource sites. The reported external cohort remains within the same institutional pool and does not probe this geographic or resource-level shift, weakening the generalizability claim that underpins the paper's clinical motivation.
minor comments (2)
- [Methods section on data splits] Methods section on data splits: explicitly state the exact partition of the 150 cases into training, internal validation, and the 70-case test set (including how many cases belong to the external cohort) so that the 0.57 NCCT Dice and 28% gain figures can be reproduced without ambiguity.
- [Results tables or supplementary material] Results tables or supplementary material: report the precise off-the-shelf baseline models (e.g., nnU-Net, Swin-UNETR) and their training regimes against which the 28% Dice improvement on external NCCT is measured.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the generalizability of our claims. We address the point directly below and have revised the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and external-validation paragraph] Abstract and external-validation paragraph: the positioning of the benchmark as directly relevant to 'low-resource settings across Africa and Asia' rests on the untested assumption that the Egyptian-Chinese four-phase acquisitions capture scanner variability, lesion etiology distributions, and acquisition protocols typical of other low-resource sites. The reported external cohort remains within the same institutional pool and does not probe this geographic or resource-level shift, weakening the generalizability claim that underpins the paper's clinical motivation.
Authors: We agree that the external cohort, while drawn from a held-out institution, remains within the same multi-center Egyptian-Chinese collection and therefore does not constitute a full geographic or resource-level shift test. The dataset does span two continents and multiple scanner vendors, supplying more diversity than typical single-center NCCT studies, yet this still falls short of validating performance across all low-resource environments. In the revised version we have moderated the abstract and introduction to describe the benchmark as addressing challenges 'particularly relevant to low-resource settings in regions such as Africa and Asia' rather than claiming direct capture of all such variability. We have also inserted a limitations paragraph that explicitly notes the need for future validation on additional sites outside the current institutional pool. revision: yes
Circularity Check
Empirical benchmark study with direct held-out measurements; no derivations or self-referential reductions.
full rationale
The paper describes a multi-centre dataset, challenge setup, and reports Dice scores from algorithm evaluations on 70 held-out cases including external validation. All central claims (0.754 venous Dice, 0.57 NCCT drop, up to 28% gain) are direct empirical measurements on split data, not derived from equations or predictions that reduce to the paper's own fitted inputs. No load-bearing self-citations, uniqueness theorems, or ansatzes are invoked in the provided text. The representativeness assumption for low-resource settings is an external generalization claim, not a circular derivation within the paper's own chain.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Dice coefficient is an appropriate overlap metric for evaluating lesion segmentation performance.
Reference graph
Works this paper leans on
-
[1]
Reports15, 10.1038/s41598-025-02031-w (2025)
Zhao, Y .et al.Epidemiological and demographic analysis of liver cancer attributable to modifiable risk factors from 1990 to 2021.Sci. Reports15, 10.1038/s41598-025-02031-w (2025)
-
[2]
El-Kassas, M.et al.Hepatocellular carcinoma in egypt in the post hcv elimination era: Changing aetiology, surveillance, and management pathways.Liver Int.46, e70595, https://doi.org/10.1111/liv.70595 (2026). https://onlinelibrary.wiley. com/doi/pdf/10.1111/liv.70595
-
[3]
Natembeya, M., Anudjo, M., Ackah, J., Osei, M. & Akudjedu, T. The environmental sustainability implications of contrast media supply chain disruptions during the covid-19 pandemic: A document analysis of international practice guidelines. Radiography30, 43–54, 10.1016/j.radi.2024.05.017 (2024). 4.Egypt Independent. Dye shortage in Egypt for CT scans threa...
-
[4]
Bilic, P.et al.The liver tumor segmentation benchmark (lits).Med. Image Analysis84, 102680, https://doi.org/10.1016/j. media.2022.102680 (2023)
work page doi:10.1016/j 2022
-
[5]
Heller, N.et al.The kits21 challenge: Automatic segmentation of kidneys, renal tumors, and renal cysts in corticomedullary- phase ct (2023). 2307.01984
-
[6]
(2022) AMOS: A Large-Scale Abdominal Multi-Organ Benchmark for Versatile Medical Image Segmentation
Ji, Y .et al.Amos: A large-scale abdominal multi-organ benchmark for versatile medical image segmentation (2022). 2206.08023
-
[7]
Data13, 10.1038/ s41597-025-06343-4 (2025)
Wu, X.et al.A multi-phase ct dataset for automated differential diagnosis of liver tumors.Sci. Data13, 10.1038/ s41597-025-06343-4 (2025). 9.Rokuss, M.et al.V oxtell: Free-text promptable universal 3d medical image segmentation (2025). 2511.11450. 10.Lei, W.et al.A synthetic data-driven radiology foundation model for pan-tumor clinical diagnosis (2026). 2...
-
[8]
nnU-Net: A Self-Configuring Method for Deep Learning-Based Biomedical Image Segmentation,
Isensee, F., Jaeger, P. F., Kohl, S. A. A., Petersen, J. & Maier-Hein, K. H. nnu-net: a self-configuring method for deep learning-based biomedical image segmentation.Nat. Methods18, 203–211, 10.1038/s41592-020-01008-z (2020)
-
[9]
Ulrich, C.et al. MultiTalent: A Multi-dataset Approach to Medical Image Segmentation, 648–658 (Springer Nature Switzerland, 2023)
work page 2023
-
[10]
Interactive segmentation of medical images through fully convolutional neural networks
Sakinis, T.et al.Interactive segmentation of medical images through fully convolutional neural networks.CoRR abs/1903.08205(2019). 1903.08205
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[11]
Nature Communications15(1), 654 (1 2024)
Kirillov, A.et al.Segment anything. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 4015–4026 (2023). 15.Ma, J.et al.Segment anything in medical images.Nat. Commun.15, 10.1038/s41467-024-44824-z (2024)
-
[12]
Klein, S., Staring, M., Murphy, K., Viergever, M. A. & Pluim, J. P. W. elastix: A toolbox for intensity-based medical image registration.IEEE Transactions on Med. Imaging29, 196–205, 10.1109/TMI.2009.2035616 (2010)
-
[13]
Warfield, S., Zou, K. & Wells, W. Simultaneous truth and performance level estimation (staple): An algorithm for the validation of image segmentation.IEEE Transactions on Med. Imaging23, 903–921, 10.1109/tmi.2004.828354 (2004)
-
[14]
Bias:Transparentreportingofbiomedicalimageanalysis challenges
Maier-Hein, L.et al.Bias: Transparent reporting of biomedical image analysis challenges.Med. Image Analysis66, 101796, https://doi.org/10.1016/j.media.2020.101796 (2020). 19.Reinke, A.et al.Understanding metric-related pitfalls in image analysis validation.Nat. Methods21, 182–194, 10.1038/ s41592-023-02150-0 (2024)
-
[15]
Commun.9, 10.1038/s41467-018-07619-7 (2018)
Maier-Hein, L.et al.Why rankings of biomedical image analysis competitions should be interpreted with care.Nat. Commun.9, 10.1038/s41467-018-07619-7 (2018)
-
[16]
Benjamini, Y . & Hochberg, Y . Controlling the false discovery rate: A practical and powerful approach to multiple testing. J. Royal Stat. Soc. Ser. B (Methodological)57, 289–300 (1995)
work page 1995
-
[17]
Roy, S.et al. MedNeXt: Transformer-Driven Scaling of ConvNets for Medical Image Segmentation, 405–415 (Springer Nature Switzerland, 2023)
work page 2023
-
[18]
Huang, Z.et al.Stu-net: Scalable and transferable medical image segmentation models empowered by large-scale supervised pre-training.arXiv preprint arXiv:2304.06716(2023). 11/34 Train China EgyptExternal 0 20 40 60 80 Number of cases a 80 17 28 25 20 60 Cohort composition Venous NC Combined 0 50 100 150 200 250 Number of lesions b 31 45 38 222 163 260 82 ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.