How Do Tool-Augmented LLM Agents Perform on Real-World Energy Analytics Tasks?
Pith reviewed 2026-06-26 01:32 UTC · model grok-4.3
The pith
Tool-augmented LLM agents can be systematically evaluated on 243 expert-curated real-world energy market analytics tasks using a configurable suite of domain tools and multi-dimensional scoring.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
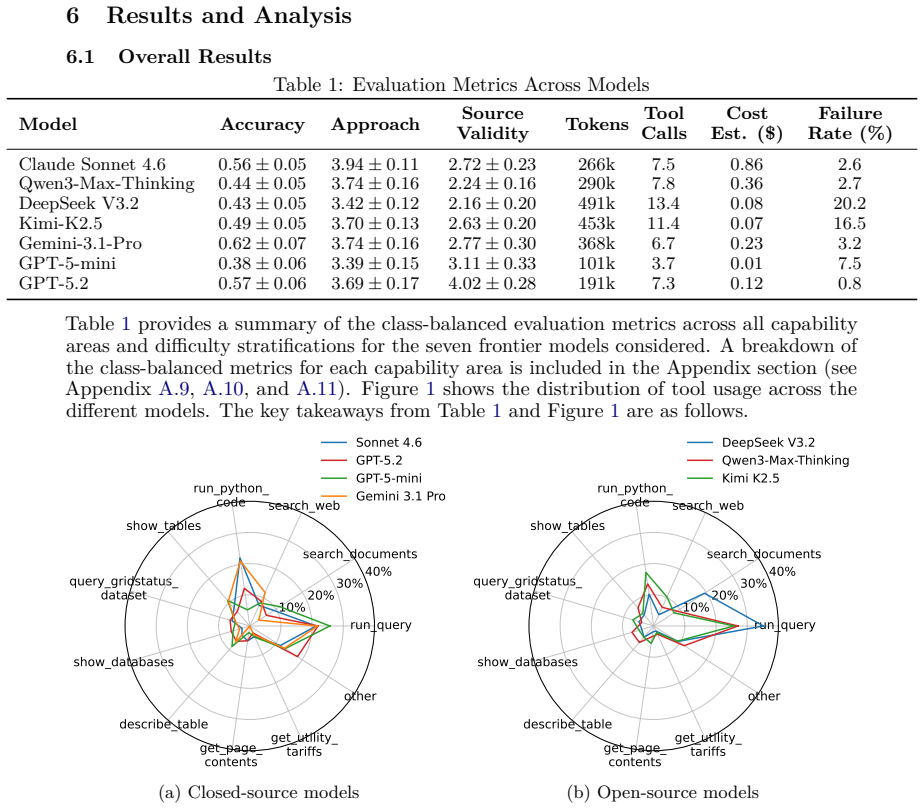
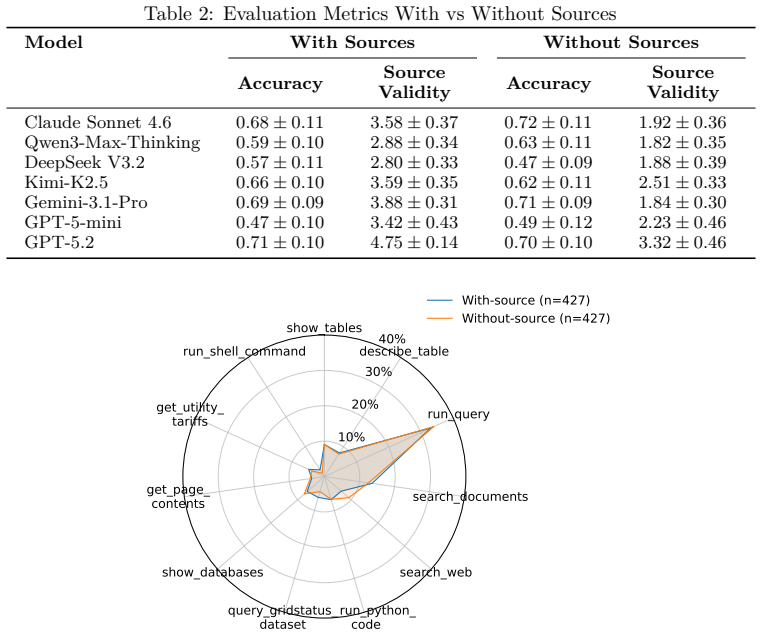
A benchmark consisting of 243 expert-curated problems across market data analysis, knowledge retrieval, and quantitative decision analytics, equipped with live electricity market APIs, regulatory search, tariff databases, and asset optimization models, enables systematic measurement of tool-augmented LLM agent performance through multi-dimensional scoring of correctness, accuracy, alignment, and validity.
What carries the argument
A configurable suite of domain tools (live U.S. ISO electricity APIs, regulatory docket search, utility tariff databases, asset optimization models) paired with a multi-dimensional evaluation protocol that routes scoring criteria by question category.
If this is right
- Closed-source and open-source LLMs can be compared on their ability to combine domain tooling with multi-step reasoning in a high-stakes regulated sector.
- Task performance varies measurably across the three categories and difficulty levels, revealing where current agents succeed or fail at live data handling versus regulatory interpretation.
- Public release of the problem set, tools, and scoring artifacts supports direct replication and incremental extension by other researchers.
- The evaluation protocol isolates the contribution of tool access from base model capability.
Where Pith is reading between the lines
- The same tool-and-scoring structure could be ported to adjacent regulated domains such as water utilities or natural gas markets without starting from scratch.
- If agents show consistent gaps on optimization modeling tasks, targeted improvements in tool-calling interfaces would be a higher-leverage research direction than further scaling of the base model.
- Expanding the benchmark to include time-series forecasting or multi-agent coordination would test whether the current categories already capture the hardest professional constraints.
Load-bearing premise
The 243 expert-curated problems together with the supplied tool suite represent the actual workflows and constraints that professional energy analysts encounter.
What would settle it
A direct comparison showing that professional energy analysts routinely solve tasks outside the 243-problem set or that agent rankings on the benchmark diverge from rankings on live client assignments not included in the curation.
Figures
read the original abstract
Agentic benchmarks have emerged across general-purpose and domain-specific settings, including finance, coding, law, and drug discovery, yet energy-domain evaluations remain largely limited to static knowledge recall. This is a critical gap for a sector that requires live data retrieval, specialized regulatory and market knowledge, and multi-step quantitative reasoning under real-world constraints. We present an empirical study of tool-augmented LLM agents on real-world energy market analytics tasks. Our evaluation environment includes 243 expert-curated problems across three categories: (1) Market Data Retrieval and Analysis, (2) Knowledge Retrieval and Interpretation, and (3) Advanced Quantitative Modeling and Decision Analytics. Tasks include price and demand analysis, tariff impact modeling, asset revenue and returns estimation, hedging strategy analysis, and optimization modeling, with problems spanning multiple difficulty levels. Agents are equipped with a configurable suite of domain tools, including live electricity market APIs for major U.S. ISOs, regulatory docket search, utility tariff databases, asset optimization models, and retrieval-augmented generation over energy market documents. We assess agent responses using a multi-dimensional evaluation protocol that scores approach correctness, answer accuracy, attribute alignment, and source validity, with category-aware routing to match scoring criteria to question type. We evaluate both closed-source and open-source LLMs, providing a comparative analysis of how model capability and domain tooling interact in a high-stakes professional domain. Key artifacts are publicly released to support reproducibility and future research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an empirical study of tool-augmented LLM agents on real-world energy market analytics tasks. It introduces a benchmark of 243 expert-curated problems across three categories (Market Data Retrieval and Analysis, Knowledge Retrieval and Interpretation, and Advanced Quantitative Modeling and Decision Analytics), equips agents with a configurable suite of domain tools (live electricity market APIs, regulatory docket search, utility tariff databases, asset optimization models, and RAG over energy documents), and applies a multi-dimensional scoring protocol (approach correctness, answer accuracy, attribute alignment, source validity) with category-aware routing. The work evaluates closed- and open-source LLMs and releases key artifacts for reproducibility.
Significance. If the benchmark is representative and the evaluation yields reliable distinctions, the work would address a clear gap in domain-specific agent benchmarks for the energy sector, which requires live data retrieval, regulatory knowledge, and multi-step quantitative reasoning. The public release of the problem set, tool suite, and evaluation protocol is a concrete strength that enables reproducibility and future extensions.
major comments (2)
- [Problem set construction and categories] The manuscript asserts that the 243 expert-curated problems are representative of professional energy analytics workflows (spanning price/demand analysis, tariff modeling, hedging, and optimization), but provides no external validation such as task-frequency matching against job logs, analyst surveys, or published case studies. This assumption is load-bearing for the central claim that performance differences reflect domain-relevant agent capabilities rather than benchmark artifacts.
- [Evaluation protocol and results] The abstract and description outline the evaluation protocol and promise a comparative analysis of how model capability and domain tooling interact, yet the available text reports no performance numbers, error analysis, statistical results, or specific findings from the LLM evaluations. This prevents assessment of the empirical claims in the title and abstract.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on the benchmark construction and the presentation of empirical results. We address each major comment below.
read point-by-point responses
-
Referee: [Problem set construction and categories] The manuscript asserts that the 243 expert-curated problems are representative of professional energy analytics workflows (spanning price/demand analysis, tariff modeling, hedging, and optimization), but provides no external validation such as task-frequency matching against job logs, analyst surveys, or published case studies. This assumption is load-bearing for the central claim that performance differences reflect domain-relevant agent capabilities rather than benchmark artifacts.
Authors: We agree that formal external validation (e.g., via job logs or analyst surveys) would further strengthen claims of representativeness. The problems were developed by domain experts with direct professional experience in energy analytics, drawing from standard workflows in ISO market operations, regulatory filings, and utility tariff modeling. In revision we will expand the Methods section with a detailed account of the curation process, expert qualifications, and explicit mapping to published industry case studies. We will also add a limitations paragraph acknowledging the absence of quantitative task-frequency validation. revision: partial
-
Referee: [Evaluation protocol and results] The abstract and description outline the evaluation protocol and promise a comparative analysis of how model capability and domain tooling interact, yet the available text reports no performance numbers, error analysis, statistical results, or specific findings from the LLM evaluations. This prevents assessment of the empirical claims in the title and abstract.
Authors: The complete manuscript includes Section 4 (Results) with performance tables, error breakdowns by category and model, statistical significance tests, and analysis of tool-interaction effects. If these sections were omitted from the reviewed version, we will ensure they are fully restored and expanded with additional visualizations in the revision. revision: yes
Circularity Check
No circularity: empirical benchmark with no derivations or self-referential reductions
full rationale
The paper is an empirical benchmark study that defines 243 expert-curated problems, a tool suite, and a multi-dimensional scoring protocol, then reports agent performance on them. No equations, fitted parameters, predictions, or uniqueness theorems appear in the abstract or described structure. The evaluation relies on external live APIs, regulatory databases, and curated tasks rather than any self-definition or self-citation chain that reduces the central claim to its own inputs. This matches the default expectation of a non-circular empirical paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
OpenAI. GPT-4 technical report. Technical report, OpenAI, 2024. URL https: //arxiv.org/abs/2303.08774
Pith/arXiv arXiv 2024
-
[2]
The Claude 3 model family: Opus, Sonnet, Haiku
Anthropic. The Claude 3 model family: Opus, Sonnet, Haiku. Technical re- port, Anthropic, 2024. URL https://api.semanticscholar.org/CorpusID: 268232499
2024
-
[3]
Gemini: A family of highly capable multimodal models
Google DeepMind. Gemini: A family of highly capable multimodal models. Technical report, Google DeepMind, 2024. URLhttps://arxiv.org/abs/2312.11805
Pith/arXiv arXiv 2024
-
[4]
ReAct: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. In International Conference on Learning Representations (ICLR), 2023. URLhttps: //arxiv.org/abs/2210.03629
Pith/arXiv arXiv 2023
-
[5]
Toolformer: Language models can teach themselves to use tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. InAdvances in Neural Information Processing Systems (NeurIPS), 2023. URLhttps://arxiv.org/abs/2302.04761
Pith/arXiv arXiv 2023
-
[6]
Fingpt: Open-source financial large language models, 2025
Hongyang Yang, Xiao-Yang Liu, and Christina Dan Wang. Fingpt: Open-source financial large language models, 2025. URLhttps://arxiv.org/abs/2306.06031
arXiv 2025
-
[7]
Finance agent benchmark: Benchmarking llms on real-world financial research tasks, 2025
Antoine Bigeard, Langston Nashold, Rayan Krishnan, and Shirley Wu. Finance agent benchmark: Benchmarking llms on real-world financial research tasks, 2025. URL https://arxiv.org/abs/2508.00828
arXiv 2025
-
[8]
Neel Guha, Julian Nyarko, Daniel E. Ho, Christopher Ré, Adam Chilton, Aditya Narayana, Alex Chohlas-Wood, Austin Peters, Brandon Waldon, Daniel N. Rockmore, Diego Zambrano, Dmitry Talisman, Enam Hoque, Faiz Surani, Frank Fagan, Galit Sarfaty, Gregory M. Dickinson, Haggai Porat, Jason Hegland, Jessica Wu, Joe Nudell, Joel Niklaus, John Nay, Jonathan H. Cho...
arXiv 2023
-
[9]
Jiménez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jiménez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. SWE-bench: Can language models resolve real-world GitHub issues? InInternational Conference on Learning Representations (ICLR), 2024. URL https://arxiv.org/abs/2310.06770
Pith/arXiv arXiv 2024
-
[10]
Bran, Sam Cox, Oliver Schilter, Carlo Baldassari, Andrew D
Andres M. Bran, Sam Cox, Oliver Schilter, Carlo Baldassari, Andrew D. White, and Philippe Schwaller. ChemCrow: Augmenting large language models with chemistry tools, 2023. URLhttps://arxiv.org/abs/2304.05376
Pith/arXiv arXiv 2023
-
[11]
Probabilistic electric load forecasting: A tutorial review
Tao Hong and Shu Fan. Probabilistic electric load forecasting: A tutorial review. International Journal of Forecasting, 32(3):914–938, 2016. doi: https://doi.org/10.1016/ j.ijforecast.2015.11.011. 10
2016
-
[12]
Rafał Weron. Electricity price forecasting: A review of the state-of-the-art with a look into the future.International Journal of Forecasting, 30(4):1030–1081, 2014. doi: https://doi.org/10.1016/j.ijforecast.2014.08.008
-
[13]
Benchmarking large language models for the electric power sector
Electric Power Research Institute (EPRI). Benchmarking large language models for the electric power sector. White Paper 3002034347, Electric Power Research Institute, Palo Alto, CA, 2025
2025
-
[14]
GAIA: A benchmark for general AI assistants
Grégoire Mialon, Clémentine Fourrier, Craig Swift, Thomas Wolf, Yann LeCun, and Thomas Scialom. GAIA: A benchmark for general AI assistants. InInternational Conference on Learning Representations (ICLR), 2024. URLhttps://arxiv.org/ abs/2311.12983
Pith/arXiv arXiv 2024
-
[16]
URLhttps://arxiv.org/abs/2308.03688
-
[17]
ToolLLM: Facilitating large language models to master 16000+ real-world APIs
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Lauren Hong, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, Dahai Li, Zhiyuan Liu, and Maosong Sun. ToolLLM: Facilitating large language models to master 16000+ real-world APIs. InInternational Conference on Learning Representat...
Pith/arXiv arXiv 2024
-
[18]
URLhttps://arxiv.org/abs/2406.12045
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan.τ-bench: A benchmark for tool-agent-user interaction in real-world domains.arXiv preprint arXiv:2406.12045, 2024. URLhttps://arxiv.org/abs/2406.12045
Pith/arXiv arXiv 2024
-
[19]
Xu, Yufan Song, Boxuan Li, Yuxuan Tang, Kritanjali Jain, Mengxue Bao, Zora Z
Frank F. Xu, Yufan Song, Boxuan Li, Yuxuan Tang, Kritanjali Jain, Mengxue Bao, Zora Z. Wang, Xuhui Zhou, Zhitong Guo, Murong Cao, Mingyang Yang, Hao Yang Lu, Amaad Martin, Zhe Su, Leander Maben, Raj Mehta, Wayne Chi, Lawrence Jang, Yiqing Xie, Shuyan Zhou, and Graham Neubig. TheAgentCompany: Benchmarking LLM agents on consequential real world tasks. InAdv...
Pith/arXiv arXiv 2025
-
[20]
Jonathan Bragg, Mike D’Arcy, Nishant Balepur, Dan Bareket, Bhavana Dalvi, Sergey Feldman, Dany Haddad, Jena D. Hwang, Peter Jansen, Varsha Kishore, Bod- hisattwa Prasad Majumder, Aakanksha Naik, Sigal Rahamimov, Kyle Richardson, Amanpreet Singh, Harshit Surana, Aryeh Tiktinsky, Rosni Vasu, Guy Wiener, Chloe Anastasiades, Stefan Candra, Jason Dunkelberger,...
Pith/arXiv arXiv 2024
-
[21]
Haohang Li, Yupeng Cao, Yangyang Yu, Shashidhar Reddy Javaji, Zhiyang Deng, Yueru He, Yuechen Jiang, Zining Zhu, Koduvayur Subbalakshmi, Guojun Xiong, Jimin Huang, Lingfei Qian, Xueqing Peng, Qianqian Xie, and Jordan W. Suchow. InvestorBench: A benchmark for financial decision-making tasks with LLM-based agents. InProceedings of the 63rd Annual Meeting of...
2025
-
[22]
Top of the CLASS: Bench- marking LLM agents on real-world enterprise tasks
Michael Wornow, Vaishnav Garodia, and Vasilis Vassalos. Top of the CLASS: Bench- marking LLM agents on real-world enterprise tasks. InICLR 2025 Workshop on Building Trust in LLMs and LLM Applications, 2025. URLhttps://openreview. net/forum?id=RQjUpeINII. 11
2025
-
[23]
Can LLMs help you at work? A sandbox for evaluating LLM agents in enterprise environments
Harsh Vishwakarma, Ankush Agarwal, Ojas Patil, Chaitanya Devaguptapu, and Mahesh Chandran. Can LLMs help you at work? A sandbox for evaluating LLM agents in enterprise environments. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2025. URLhttps://arxiv.org/abs/ 2510.27287
arXiv 2025
-
[24]
PaperBench: Evaluating AI’s ability to replicate AI research, 2025
Giulio Starace, Oliver Jaffe, Dane Sherburn, James Aung, Jun Shern Chan, Leon Maksin, Rachel Dias, Evan Mays, Benjamin Kinsella, Wyatt Thompson, Johannes Heidecke, Amelia Glaese, and Tejal Patwardhan. PaperBench: Evaluating AI’s ability to replicate AI research, 2025. URLhttps://arxiv.org/abs/2504.01848
Pith/arXiv arXiv 2025
-
[25]
Baker, Benjamin Burns, Daniel Adu-Ampratwum, Xuhui Huang, Xia Ning, Song Gao, Yu Su, and Huan Sun
Ziru Chen, Shijie Chen, Yuting Ning, Qianheng Zhang, Boshi Wang, Botao Yu, Yifei Li, Zeyi Liao, Chen Wei, Zitong Lu, Vishal Dey, Mingyi Xue, Frazier N. Baker, Benjamin Burns, Daniel Adu-Ampratwum, Xuhui Huang, Xia Ning, Song Gao, Yu Su, and Huan Sun. ScienceAgentBench: Toward rigorous assessment of language agents for data-driven scientific discovery. InI...
-
[26]
URLhttps://arxiv.org/abs/2410.05080
-
[27]
OdysseyBench: Evaluating LLM agents on long-horizon complex office application workflows, 2025
Weixuan Wang, Dongge Han, Daniel Madrigal Díaz, Jin Xu, Victor Rühle, and Saravan Rajmohan. OdysseyBench: Evaluating LLM agents on long-horizon complex office application workflows, 2025. URLhttps://arxiv.org/abs/2508.09124
arXiv 2025
-
[28]
Barr, Federica Sarro, Zhaoyang Chu, and He Ye
Han Li, Letian Zhu, Bohan Zhang, Rili Feng, Jiaming Wang, Yue Pan, Earl T. Barr, Federica Sarro, Zhaoyang Chu, and He Ye. ContextBench: A benchmark for context retrieval in coding agents, 2026. URLhttps://arxiv.org/abs/2602.05892
arXiv 2026
-
[29]
Black, Gloria Geng, Danny Park, James Zou, Andrew Y
Yixing Jiang, Kameron C. Black, Gloria Geng, Danny Park, James Zou, Andrew Y. Ng, and Jonathan H. Chen. MedAgentBench: A realistic virtual EHR environment to benchmark medical LLM agents.NEJM AI, 2025. URLhttps://arxiv.org/abs/ 2501.14654
arXiv 2025
-
[30]
LegalAgentBench: Evaluating LLM agents in legal domain
Haitao Li, Junjie Chen, Jingli Yang, Qingyao Ai, Wei Jia, Youfeng Liu, Kai Lin, Yueyue Wu, Guozhi Yuan, Yiran Hu, Wuyue Wang, Yiqun Liu, and Minlie Huang. LegalAgentBench: Evaluating LLM agents in legal domain. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL), Volume 1: Long Papers, pages 2322–2344, Vienna, A...
2025
-
[31]
Skillsbench: Benchmarking how well agent skills work across diverse tasks, 2026
Xiangyi Li, Wenbo Chen, Yimin Liu, Shenghan Zheng, Xiaokun Chen, Yifeng He, Yubo Li, Bingran You, Haotian Shen, Jiankai Sun, Shuyi Wang, Binxu Li, Qunhong Zeng, Di Wang, Xuandong Zhao, Yuanli Wang, Roey Ben Chaim, Zonglin Di, Yipeng Gao, Junwei He, Yizhuo He, Liqiang Jing, Luyang Kong, Xin Lan, Jiachen Li, Songlin Li, Yijiang Li, Yueqian Lin, Xinyi Liu, X...
2026
-
[32]
Stefan Pfenninger and Iain Staffell. Long-term patterns of european PV output using 30 years of validated hourly reanalysis and satellite data.Energy, 114:1251–1265, 2016. doi: https://doi.org/10.1016/j.energy.2016.08.060
-
[33]
Furqan Amjad, Tarmo Korõtko, and Argo Rosin. Review of llms applications in electrical power and energy systems.IEEE Access, 13:150951–150969, 2025. doi: 10.1109/ACCESS.2025.3599922
-
[34]
Xiyuan Zhou, Huan Zhao, Yuheng Cheng, Yuji Cao, Gaoqi Liang, Guolong Liu, Wenxuan Liu, Yan Xu, and Junhua Zhao. ElecBench: A power dispatch evaluation benchmark for large language models.arXiv preprint arXiv:2407.05365, 2024. URL https: //arxiv.org/abs/2407.05365
arXiv 2024
-
[35]
Sai Santhosh Polagani. AI agents for smart grid operations and renewable energy management.Iconic Research and Engineering Journals, 8(11):1278–1292, 2025. URL https://www.irejournals.com/formatedpaper/1708600.pdf. 12
arXiv 2025
-
[36]
Power-flowbenchmarkforllm-basedpowersystemagentevaluation(pfbench),
BuxinShe. Power-flowbenchmarkforllm-basedpowersystemagentevaluation(pfbench),
-
[37]
URLhttps://dx.doi.org/10.21227/jnrm-q720
-
[38]
Available: https://doi.org/10.1145/3731599.3767404
GridMind Authors. Gridmind: Llms-powered agents for power system analysis and operations. InProceedings of the SC ’25 Workshops of the International Conference for High Performance Computing, Networking, Storage and Analysis. ACM, nov 2025. doi: 10.1145/3731599.3767409. URLhttps://doi.org
-
[39]
Grid- agent: An llm-powered multi-agent system for power grid control, 2025
Yan Zhang, Ahmad Mohammad Saber, Amr Youssef, and Deepa Kundur. Grid- agent: An llm-powered multi-agent system for power grid control, 2025. URLhttps: //arxiv.org/abs/2508.05702
arXiv 2025
-
[40]
Emmanuel O. Badmus and Amritanshu Pandey. Powerdag: Reliable agentic ai system for automating distribution grid analysis, 2026. URLhttps://arxiv.org/abs/ 2603.17418
Pith/arXiv arXiv 2026
-
[41]
Badmus, Peng Sang, Dimitrios Stamoulis, and Amritanshu Pandey
Emmanuel O. Badmus, Peng Sang, Dimitrios Stamoulis, and Amritanshu Pandey. Powerchain: A verifiable agentic ai system for automating distribution grid analyses,
-
[42]
URLhttps://arxiv.org/abs/2508.17094
-
[43]
LLM-in-Sandbox elicits general agentic intelligence, 2026
Daixuan Cheng, Shaohan Huang, Yuxian Gu, Huatong Song, Guoxin Chen, Li Dong, Wayne Xin Zhao, Ji-Rong Wen, and Furu Wei. LLM-in-Sandbox elicits general agentic intelligence, 2026. URLhttps://arxiv.org/abs/2601.16206
Pith/arXiv arXiv 2026
-
[44]
Baker, Ziru Chen, Garrett Herb, Boyu Gou, Daniel Adu- Ampratwum, Xia Ning, and Huan Sun
Botao Yu, Frazier N. Baker, Ziru Chen, Garrett Herb, Boyu Gou, Daniel Adu- Ampratwum, Xia Ning, and Huan Sun. Tooling or not tooling? the impact of tools on language agents for chemistry problem solving. InFindings of the Association for Computational Linguistics: NAACL 2025, 2025. URLhttps://arxiv.org/abs/ 2411.07228
arXiv 2025
-
[45]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging LLM-as-a-Judge with MT-Bench and chatbot arena. In Advances in Neural Information Processing Systems (NeurIPS), 2023. URLhttps: //arxiv.org/abs/2306.05685
Pith/arXiv arXiv 2023
-
[46]
Yann Dubois, Chen Xuechen Li, Rohan Taori, Tianyi Zhang, Ishaan Gulrajani, Jimmy Ba, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. AlpacaFarm: A simulation framework for methods that learn from human feedback.arXiv preprint arXiv:2305.14387, 2023. URLhttps://arxiv.org/abs/2305.14387
arXiv 2023
-
[47]
Benchmarking foundation models with language-model-as-an-examiner
Yushi Bai, Jiahao Ying, Yixin Cao, Xin Lv, Yuze He, Xiaozhi Wang, Jifan Yu, Kaisheng Zeng, Yijia Xiao, Haozhe Lyu, Jiayin Zhang, Juanzi Li, and Lei Hou. Benchmarking foundation models with language-model-as-an-examiner. InProceedings of the 37th International Conference on Neural Information Processing Systems, NIPS ’23, Red Hook, NY, USA, 2023. Curran As...
arXiv 2023
-
[48]
Deepinfra models library, 2026
DeepInfra. Deepinfra models library, 2026. URLhttps://deepinfra.com/models. Accessed: 2026-03-24
2026
-
[49]
OpenAI. Models. https://developers.openai.com/api/docs/models, 2026. OpenAI API Documentation. Accessed: 2026-03-24
2026
-
[50]
Gemini pro, 2026
Google DeepMind. Gemini pro, 2026. URLhttps://deepmind.google/models/ gemini/pro/. Model page describing the Gemini Pro family of multimodal AI models. Accessed: 2026-03-24
2026
-
[51]
Claude sonnet, 2026
Anthropic. Claude sonnet, 2026. URL https://www.anthropic.com/claude/ sonnet. Anthropic model page describing the Claude Sonnet family of models. Accessed: 2026-03-24. 13 A Appendices A.1 Dataset Breakdown Table A.1: Dataset breakdown by capability area and difficulty level (n=243) Capability Area Easy Medium Hard T otal Data 13 61 33 107 Knowledge 40 43 ...
2026
-
[52]
A question from the benchmark dataset is presented to a ReAct agent backed by one of seven LLMs
Observation Final Answer done repeat ReAct Agent Loop Benchmark Questions 243 tasks Categories: Data Retrieval Knowledge Quantitative Difficulty: Easy / Med / Hard task GridStatus API Tariff Database Renewables.ninja Battery Optimizer Docket Search Web Search (Exa) Weather API RAG Server (MCP) Database (MCP) Domain T ools call / result LLM-as-a-Judge Cate...
-
[53]
Explicit inclusion of sources in an AI agent’s answer to a question relating to energy markets analysis
-
[54]
What was the difference between average ERCOT weekday and weekend day-ahead prices in the summer of 2023 based on your ERCOT database?
Relevance of the included sources for the question You can extract or infer relevant sources from the question itself or from the suggested approach ground truth Do not penalize for not explicitly adding queries or code for pulling data for verification as long as the source specified is consistent with what the agent has access to and is plausible Intern...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.