Neuromorphic Speech Enhancement with Dual-Branch Spiking Neural Networks
Pith reviewed 2026-06-26 06:50 UTC · model grok-4.3
The pith
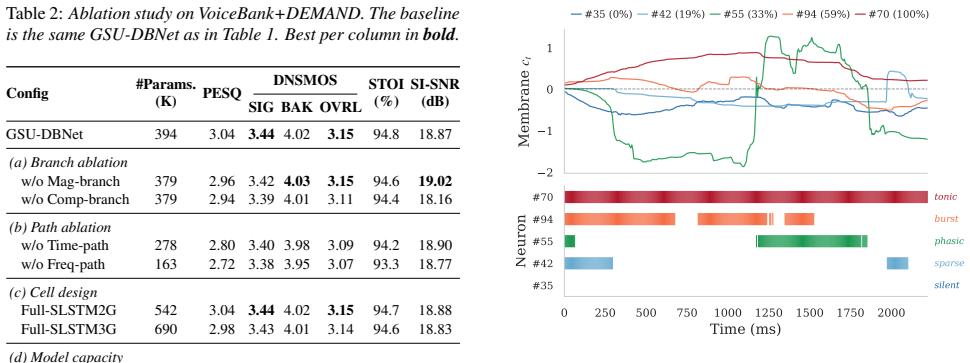
GSU-DBNet reaches a PESQ score of 3.04 in speech enhancement using a dual-branch spiking architecture with only 394K parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GSU-DBNet simultaneously predicts magnitude and complex spectral masks through its dual-branch structure, with the gated spiking unit handling activation and the dual-path GSU module extracting spatiotemporal features; on a standard benchmark this produces a PESQ of 3.04 at 394K parameters, surpassing earlier SNN approaches and requiring only 4.5 to 10.6 percent of the parameters used by representative ANN models.
What carries the argument
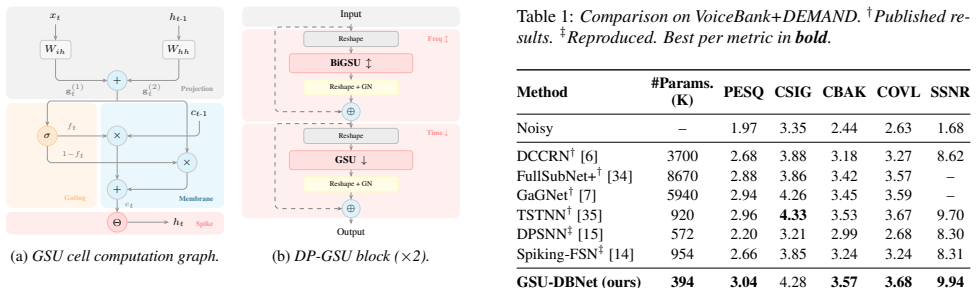
Dual-branch architecture with gated spiking unit (GSU) and dual-path GSU module, which separately processes magnitude and complex spectra while combining temporal and frequency information.
If this is right
- SNN models become competitive with ANN models for speech enhancement without needing orders-of-magnitude more parameters.
- Neuromorphic chips can run real-time speech cleanup at lower power than conventional networks.
- Resource-limited devices gain access to effective audio enhancement through the reduced parameter count.
- Further SNN architectures can build on the dual-branch pattern for other spectrum-based audio tasks.
Where Pith is reading between the lines
- The same dual-branch pattern might transfer to related problems such as source separation or dereverberation.
- Direct comparison of latency and power on actual spiking hardware would quantify the promised efficiency gain.
- Extending the GSU to handle multi-channel or streaming inputs could broaden practical use cases.
Load-bearing premise
The two branches can model magnitude and complex spectra at the same time without one branch interfering with the other or dropping essential phase details.
What would settle it
Running the same test set on neuromorphic hardware and measuring actual energy draw against an equivalent ANN, or checking whether the 3.04 PESQ holds on an unseen speech corpus with different noise conditions.
Figures

read the original abstract
Spiking neural network (SNN)-based neuromorphic speech enhancement has emerged as a promising paradigm due to its energy efficiency, yet it still underperforms classical artificial neural network (ANN)-based approaches owing to binary activations and the lack of well-designed network architectures. To overcome this limitation, we propose a novel dual-branch spiking neural network architecture equipped with a gated spiking unit (GSU), termed GSU-DBNet. Specifically, GSU-DBNet simultaneously models the speech magnitude spectrum and complex spectrum, predicting the corresponding magnitude and complex spectral masks. Meanwhile, a dual-path GSU module is adopted to exploit temporal and frequency information for enhanced spatiotemporal feature representation. Experiments on a popular benchmark dataset show that GSU-DBNet achieves a PESQ score of 3.04 with only 394K parameters, outperforming existing SNN-based methods while using only 4.5%--10.6% of the parameters of representative ANN-based models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce GSU-DBNet, a dual-branch spiking neural network architecture equipped with a gated spiking unit (GSU) and a dual-path GSU module for neuromorphic speech enhancement. The network simultaneously models the speech magnitude spectrum and complex spectrum by predicting corresponding masks. Experiments on a popular benchmark dataset are reported to yield a PESQ score of 3.04 with only 394K parameters, outperforming existing SNN-based methods while using 4.5%--10.6% of the parameters of representative ANN-based models.
Significance. If the performance result holds under proper validation, the work would be significant for neuromorphic audio processing by showing that targeted SNN architectural choices (dual-branch magnitude/complex modeling plus GSU) can achieve competitive enhancement quality at very low parameter counts relative to ANNs, supporting energy-efficient deployment on neuromorphic hardware.
major comments (2)
- [Abstract] Abstract: the central claim of PESQ 3.04 at 394K parameters outperforming prior SNN methods rests on experimental outcomes, yet the abstract supplies no experimental protocol, baseline comparisons, statistical tests, or error bars. The full manuscript's experiments section must supply these to make the performance claim verifiable and load-bearing.
- [Abstract] Abstract: the description that the dual-branch architecture with GSU and dual-path module simultaneously models magnitude and complex spectra without branch interference or loss of phase information is presented as a design feature, but no ablation or analysis is referenced to confirm this assumption supports the reported PESQ gain.
Simulated Author's Rebuttal
We thank the referee for the detailed comments on the abstract. We address each point below, confirming that the full manuscript supplies the required experimental details and supporting analyses while noting that abstracts are intentionally concise summaries.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of PESQ 3.04 at 394K parameters outperforming prior SNN methods rests on experimental outcomes, yet the abstract supplies no experimental protocol, baseline comparisons, statistical tests, or error bars. The full manuscript's experiments section must supply these to make the performance claim verifiable and load-bearing.
Authors: The Experiments section (Section 4) of the full manuscript details the experimental protocol on the standard benchmark dataset, including training and evaluation procedures, direct comparisons against prior SNN-based methods and representative ANN models with parameter counts, and the reported PESQ of 3.04 for GSU-DBNet. Results follow the common single-run reporting convention in speech enhancement literature on fixed test partitions; no statistical significance tests or error bars from multiple random seeds are included, as this is not standard in the cited baselines. We can add multi-seed error bars in a revision if requested. revision: no
-
Referee: [Abstract] Abstract: the description that the dual-branch architecture with GSU and dual-path module simultaneously models magnitude and complex spectra without branch interference or loss of phase information is presented as a design feature, but no ablation or analysis is referenced to confirm this assumption supports the reported PESQ gain.
Authors: The dual-branch design with separate magnitude and complex mask prediction paths is motivated precisely to model both spectra without cross-interference while preserving phase via the complex branch. Section 4.3 of the manuscript presents ablation studies that isolate the contributions of the dual-branch structure, the GSU, and the dual-path module, showing measurable PESQ improvements attributable to these choices. The abstract summarizes the architecture without citing the ablations due to length constraints, but the supporting analysis is present in the body. revision: no
Circularity Check
No significant circularity
full rationale
The paper proposes a dual-branch SNN architecture (GSU-DBNet) and reports empirical results on a benchmark dataset, including a PESQ score of 3.04 at 394K parameters. No derivation chain, first-principles predictions, fitted parameters renamed as predictions, or self-citation load-bearing steps are present in the provided text. The central claims rest on experimental outcomes rather than any reduction of outputs to the model's own equations or inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction Speech enhancement (SE) aims to recover clean speech from noisy observations and serves as a critical front-end for hearing aids, automatic speech recognition, and real-time commu- nication. Deep neural networks have become the dominant paradigm [1, 2, 3], achieving remarkable speech enhancement performance [4, 5]. However, current high-perfo...
Pith/arXiv arXiv 2026
-
[2]
Architecture overview As illustrated in Figure 1, GSU-DBNet follows an encoder– separator–decoder paradigm
Proposed method 2.1. Architecture overview As illustrated in Figure 1, GSU-DBNet follows an encoder– separator–decoder paradigm. The noisy speech is first trans- formed via STFT, from which the real part, imaginary part, and magnitude spectrum are extracted and concatenated into a three-channel spectral input. The encoder comprises three con- volutional b...
-
[3]
Experiments 3.1. Dataset We evaluate our method on the V oiceBank+DEMAND dataset [2], which comprises 11,572 training utterances from 28 speakers mixed with 10 noise types at SNRs of 0, 5, 10, and 15 dB. The test set contains 824 utterances from two held-out speakers mixed with five unseen noise types at SNRs of 2.5, 7.5, 12.5, and 17.5 dB, all sampled at...
-
[4]
Comparison with existing methods Table 1 summarizes a comparison between GSU-DBNet and representative ANN-based methods and SNN baselines
Results 4.1. Comparison with existing methods Table 1 summarizes a comparison between GSU-DBNet and representative ANN-based methods and SNN baselines. GSU- DBNet achieves a PESQ score of 3.04 with only 394K parame- ters and attains the best scores on CBAK, COVL, and SSNR, in- dicating that dual-branch spectral modeling provides consistent improvements in...
-
[5]
Conclusions We propose GSU-DBNet, which integrates the Gated Spiking Unit into a dual-path, dual-branch architecture as a replace- ment for LSTM, enabling joint magnitude and complex mask estimation. Experiments on V oiceBank+DEMAND show that GSU-DBNet achieves a PESQ of 3.04 with only 394K param- eters, improving by 0.84 and 0.38 over DPSNN and Spiking- ...
-
[6]
LMS26F020008), and in part by the Zhejiang Provincial College Student Inno- vation and Entrepreneurship Training Program under Grant S202510336076
Acknowledgments This work was supported in part by Yangtze River Delta Science and Technology Innovation Community Joint Research under Grant 2024CSJGG1100, in part by the Zhejiang Provincial Natural Science Foundation of China (No. LMS26F020008), and in part by the Zhejiang Provincial College Student Inno- vation and Entrepreneurship Training Program und...
-
[7]
All experimental results, method design, and scientific conclusions are the sole responsibility of the authors
Generative AI Use Disclosure Generative AI tools were used for editing and polishing the manuscript text. All experimental results, method design, and scientific conclusions are the sole responsibility of the authors
-
[8]
Supervised speech separation based on deep learning: An overview,
D. Wang and J. Chen, “Supervised speech separation based on deep learning: An overview,”IEEE/ACM Transactions on Au- dio, Speech, and Language Processing, vol. 26, no. 10, pp. 1702– 1726, 2018
2018
-
[9]
In- vestigating RNN-based speech enhancement methods for noise- robust text-to-speech,
C. Valentini-Botinhao, X. Wang, S. Takaki, and J. Yamagishi, “In- vestigating RNN-based speech enhancement methods for noise- robust text-to-speech,” inProc. ISCA Speech Synthesis Workshop (SSW), 2016, pp. 146–152
2016
-
[10]
Unsupervised speech enhance- ment using optimal transport and speech presence probability,
W. Jiang, K. Yu, and F. Wen, “Unsupervised speech enhance- ment using optimal transport and speech presence probability,” IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 32, pp. 4445–4455, 2024
2024
-
[11]
HyFlowSE: Hybrid end-to-end flow-matching speech enhance- ment via generative-discriminative learning,
Y . Zhang, W. Jiang, Z. Wang, K. Wu, W. Zhang, and F. Wen, “HyFlowSE: Hybrid end-to-end flow-matching speech enhance- ment via generative-discriminative learning,” inProc. ICASSP, 2026, pp. 16 177–16 181
2026
-
[12]
Speech enhancement with integration of neural homomorphic synthesis and spectral masking,
W. Jiang and K. Yu, “Speech enhancement with integration of neural homomorphic synthesis and spectral masking,”IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 31, pp. 1758–1770, 2023
2023
-
[13]
DCCRN: Deep complex convolution recurrent net- work for phase-aware speech enhancement,
Y . Hu, Y . Liu, S. Lv, M. Xing, S. Zhang, Y . Fu, J. Wu, B. Zhang, and L. Xie, “DCCRN: Deep complex convolution recurrent net- work for phase-aware speech enhancement,” inProc. Interspeech, 2020, pp. 2472–2476
2020
-
[14]
Glance and gaze: A col- laborative learning framework for single-channel speech enhance- ment,
A. Li, C. Zheng, L. Zhang, and X. Li, “Glance and gaze: A col- laborative learning framework for single-channel speech enhance- ment,”Applied Acoustics, vol. 187, p. 108499, 2022
2022
-
[15]
MP-SENet: A speech enhancement model with parallel denoising of magnitude and phase spectra,
Y .-X. Lu, Y . Ai, Z.-H. Du, and Z.-H. Zhu, “MP-SENet: A speech enhancement model with parallel denoising of magnitude and phase spectra,” inProc. Interspeech, 2023, pp. 3834–3838
2023
-
[16]
Loihi: A neuro- morphic manycore processor with on-chip learning,
M. Davies, N. Srinivasa, T.-H. Lin, G. Chinya, Y . Cao, S. H. Cho- day, G. Dimou, P. Joshi, N. Imam, S. Jainet al., “Loihi: A neuro- morphic manycore processor with on-chip learning,”IEEE Micro, vol. 38, no. 1, pp. 82–99, 2018
2018
-
[17]
Surrogate gradient learn- ing in spiking neural networks,
E. O. Neftci, H. Mostafa, and F. Zenke, “Surrogate gradient learn- ing in spiking neural networks,”IEEE Signal Processing Maga- zine, vol. 36, no. 6, pp. 51–63, 2019
2019
-
[18]
Deep spiking neural networks for large vocabulary automatic speech recogni- tion,
J. Wu, E. Yılmaz, M. Zhang, H. Li, and K. C. Tan, “Deep spiking neural networks for large vocabulary automatic speech recogni- tion,”Frontiers in Neuroscience, vol. 14, p. 199, 2020
2020
-
[19]
A surrogate gradient spiking base- line for speech command recognition,
A. Bittar and P. N. Garner, “A surrogate gradient spiking base- line for speech command recognition,”Frontiers in Neuroscience, vol. 16, p. 865897, 2022
2022
-
[20]
Spiking structured state space model for monaural speech enhancement,
Y . Du, X. Liu, and Y . Chua, “Spiking structured state space model for monaural speech enhancement,” inProc. ICASSP, 2024, pp. 766–770
2024
-
[21]
Toward ultralow-power neuromorphic speech enhancement with Spiking- FullSubNet,
X. Hao, C. Ma, Q. Yang, J. Wu, and K. C. Tan, “Toward ultralow-power neuromorphic speech enhancement with Spiking- FullSubNet,”IEEE Transactions on Neural Networks and Learn- ing Systems, vol. 36, no. 9, pp. 17 350–17 364, 2025
2025
-
[22]
DPSNN: Spiking neural network for low-latency streaming speech enhancement,
T. Sun and S. M. Bohte, “DPSNN: Spiking neural network for low-latency streaming speech enhancement,”Neuromorphic Computing and Engineering, vol. 4, no. 4, p. 044008, 2024
2024
-
[23]
Dual-path RNN: Efficient long sequence modeling for time-domain single-channel speech sepa- ration,
Y . Luo, Z. Chen, and T. Yoshioka, “Dual-path RNN: Efficient long sequence modeling for time-domain single-channel speech sepa- ration,” inProc. ICASSP, 2020, pp. 46–50
2020
-
[24]
Conv-TasNet: Surpassing ideal time– frequency magnitude masking for speech separation,
Y . Luo and N. Mesgarani, “Conv-TasNet: Surpassing ideal time– frequency magnitude masking for speech separation,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 27, no. 8, pp. 1256–1266, 2019
2019
-
[25]
Dual- branch attention-in-attention transformer for single-channel speech enhancement,
G. Yu, A. Li, Y . Wang, Y . Guo, C. Zheng, and H. Wang, “Dual- branch attention-in-attention transformer for single-channel speech enhancement,” inProc. ICASSP, 2022, pp. 7847–7851
2022
-
[26]
Long short-term memory,
S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural Computation, vol. 9, no. 8, pp. 1735–1780, 1997
1997
-
[27]
Learning phrase rep- resentations using RNN encoder–decoder for statistical machine translation,
K. Cho, B. van Merri ¨enboer, C. Gulcehre, D. Bahdanau, F. Bougares, H. Schwenk, and Y . Bengio, “Learning phrase rep- resentations using RNN encoder–decoder for statistical machine translation,” inProc. EMNLP, 2014, pp. 1724–1734
2014
-
[28]
MOS-GAN: Mean opinion score gan for unsupervised speech enhancement,
W. Jiang, F. Wen, and K. Yu, “MOS-GAN: Mean opinion score gan for unsupervised speech enhancement,”IEEE Signal Process. Lett., vol. 32, pp. 3465–3469, 2025
2025
-
[29]
CBAM: Convolu- tional block attention module,
S. Woo, J. Park, J.-Y . Lee, and I. S. Kweon, “CBAM: Convolu- tional block attention module,” inProc. ECCV, 2018, pp. 3–19
2018
-
[30]
U-Net: Convolutional networks for biomedical image segmentation,
O. Ronneberger, P. Fischer, and T. Brox, “U-Net: Convolutional networks for biomedical image segmentation,” inProc. MICCAI, 2015, pp. 234–241
2015
-
[31]
DeepFilterNet: Perceptually motivated real-time speech en- hancement,
H. Schr ¨oter, A. Maier, A. N. Escalante-B, and T. Rosenkranz, “DeepFilterNet: Perceptually motivated real-time speech en- hancement,” inProc. Interspeech, 2022, pp. 51–55
2022
-
[32]
A review of the integrate-and-fire neuron model: I. homogeneous synaptic input,
A. N. Burkitt, “A review of the integrate-and-fire neuron model: I. homogeneous synaptic input,”Biological Cybernetics, vol. 95, no. 1, pp. 1–19, 2006
2006
-
[33]
Backpropagation through time: What it does and how to do it,
P. J. Werbos, “Backpropagation through time: What it does and how to do it,”Proceedings of the IEEE, vol. 78, no. 10, pp. 1550– 1560, 1990
1990
-
[34]
Long short-term memory spiking networks and their applications,
A. Lotfi Rezaabad and S. Vishwanath, “Long short-term memory spiking networks and their applications,” inProc. International Conference on Neuromorphic Systems (ICONS), 2020, pp. 3:1– 3:9
2020
-
[35]
SDR – half-baked or well done?
J. Le Roux, S. Wisdom, H. Erdogan, and J. R. Hershey, “SDR – half-baked or well done?” inProc. ICASSP, 2019, pp. 626–630
2019
-
[36]
Decoupled weight decay regulariza- tion,
I. Loshchilov and F. Hutter, “Decoupled weight decay regulariza- tion,” inProc. ICLR, 2019
2019
-
[37]
Per- ceptual evaluation of speech quality (PESQ)—a new method for speech quality assessment of telephone networks and codecs,
A. W. Rix, J. G. Beerends, M. P. Hollier, and A. P. Hekstra, “Per- ceptual evaluation of speech quality (PESQ)—a new method for speech quality assessment of telephone networks and codecs,” in Proc. ICASSP, vol. 2, 2001, pp. 749–752
2001
-
[38]
Evaluation of objective quality measures for speech enhancement,
Y . Hu and P. C. Loizou, “Evaluation of objective quality measures for speech enhancement,”IEEE Transactions on Audio, Speech, and Language Processing, vol. 16, no. 1, pp. 229–238, 2008
2008
-
[39]
DNSMOS P.835 – a non-intrusive perceptual objective speech quality metric to evalu- ate noise suppressors,
C. K. A. Reddy, V . Gopal, and R. Cutler, “DNSMOS P.835 – a non-intrusive perceptual objective speech quality metric to evalu- ate noise suppressors,” inProc. IEEE ICASSP, 2022, pp. 886–890
2022
-
[40]
An al- gorithm for intelligibility prediction of time–frequency weighted noisy speech,
C. H. Taal, R. C. Hendriks, R. Heusdens, and J. Jensen, “An al- gorithm for intelligibility prediction of time–frequency weighted noisy speech,”IEEE Transactions on Audio, Speech, and Lan- guage Processing, vol. 19, no. 7, pp. 2125–2136, 2011
2011
-
[41]
Full- SubNet+: Channel attention FullSubNet with complex spectro- grams for speech enhancement,
J. Chen, Z. Wang, D. Tuo, Z. Wu, S. Kang, and H. Meng, “Full- SubNet+: Channel attention FullSubNet with complex spectro- grams for speech enhancement,” inProc. ICASSP, 2022, pp. 7857–7861
2022
-
[42]
TSTNN: Two-stage transformer based neural network for speech enhancement in the time do- main,
K. Wang, B. He, and W.-P. Zhu, “TSTNN: Two-stage transformer based neural network for speech enhancement in the time do- main,” inProc. ICASSP, 2021, pp. 7098–7102
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.