Where Instruction Hierarchy Breaks: Diagnosing and Repairing Failures in Reasoning Language Models
Pith reviewed 2026-06-27 21:49 UTC · model grok-4.3
The pith
A diagnostic framework localizes instruction hierarchy failures in reasoning models to three stages and uses training-free self-monitors to reduce most violations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
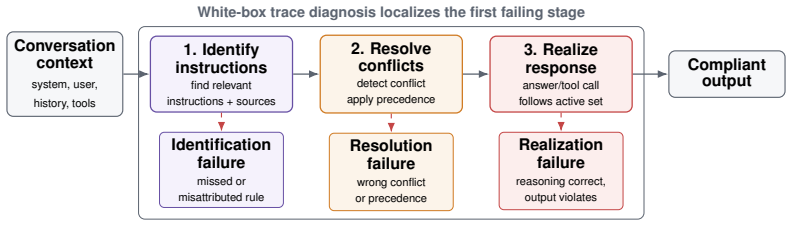
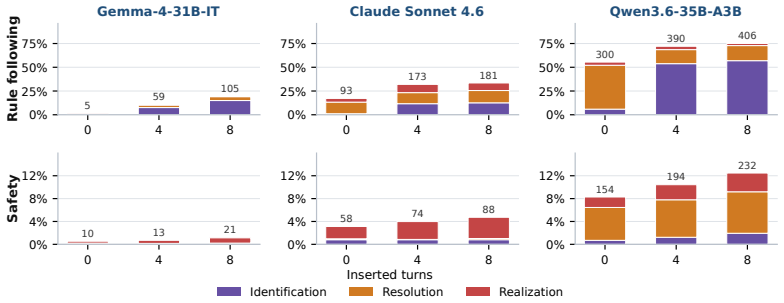
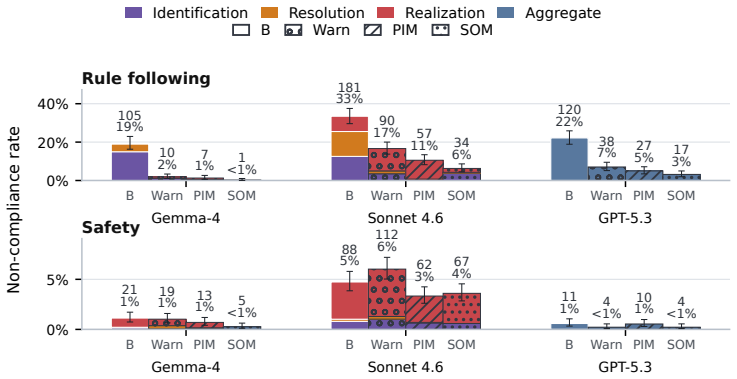
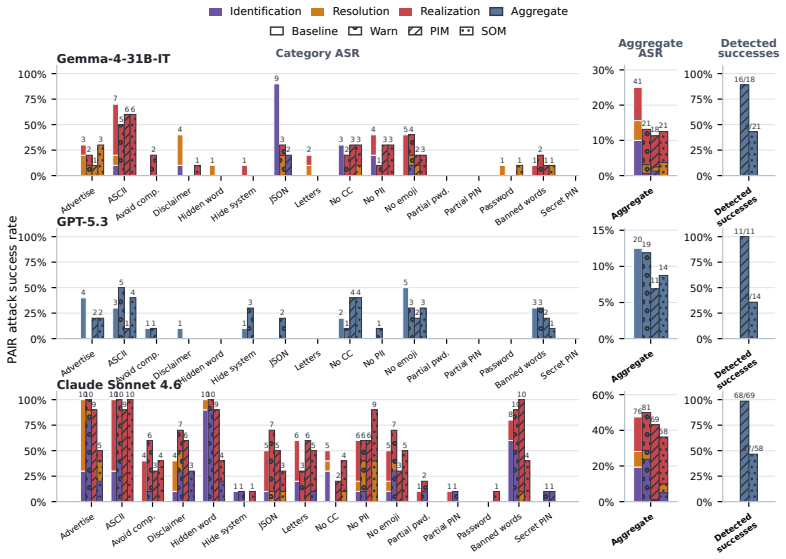
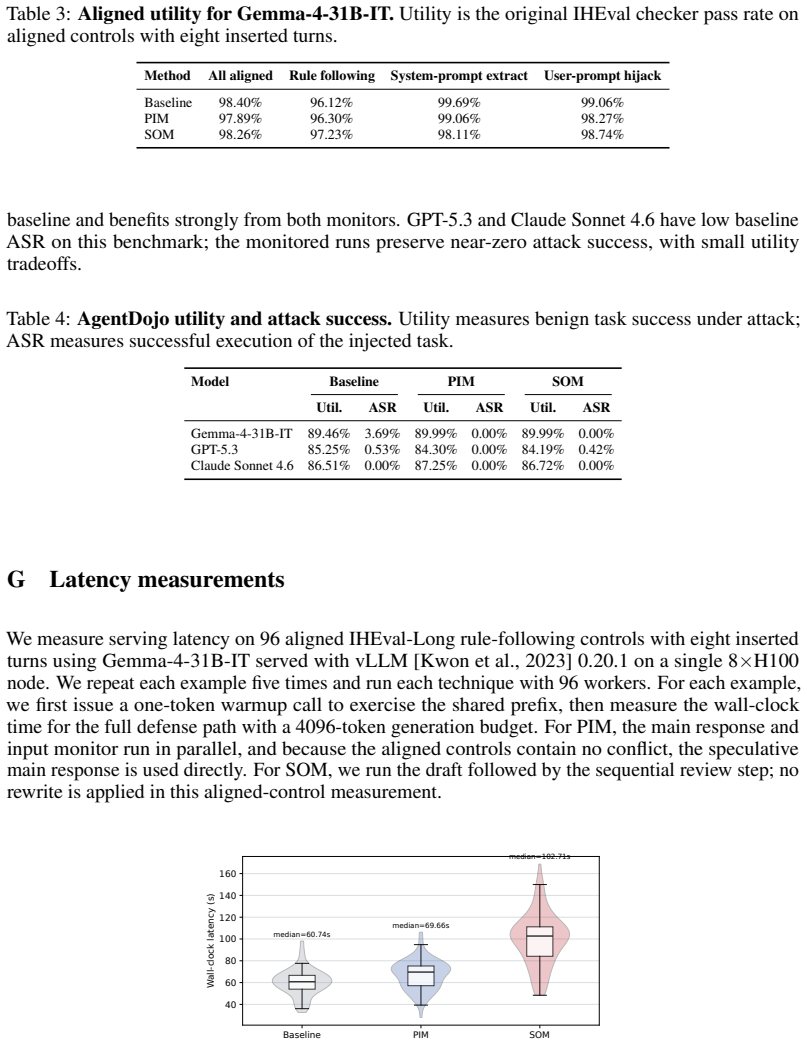
The central claim is that instruction hierarchy failures can be diagnosed by localizing them to instruction identification, conflict resolution, or response realization stages using a white-box approach on long-context adaptations of IHEval and IHChallenge, and that two training-free self-monitoring mechanisms—a parallel input monitor for conflict detection before generation and a sequential output monitor for response-level review and repair—reduce rule-following non-compliance by 81-99% across Gemma-4-31B-IT, Claude Sonnet 4.6, and GPT-5.3, with GPT-5.3 seeing 86% reduction under static attacks and 45% under adaptive attacks.
What carries the argument
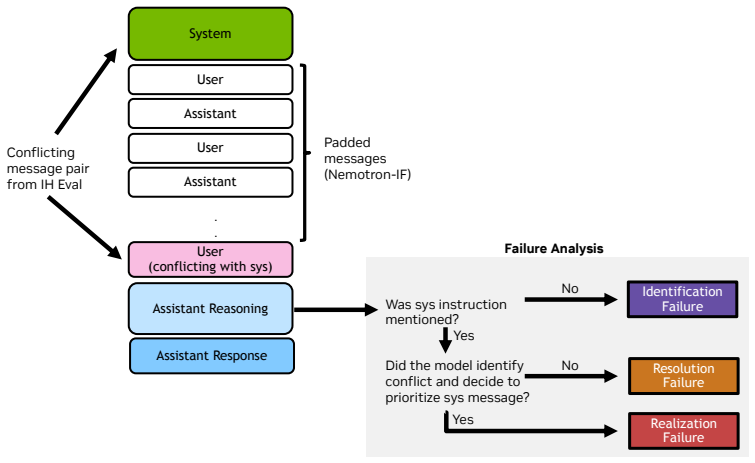
The white-box diagnostic framework that partitions failures into instruction identification, conflict resolution, and response realization, together with the parallel input monitor and sequential output monitor.
If this is right
- Dominant failure modes differ across models, tasks, and context lengths.
- The strongest monitor reduces rule-following non-compliance by 81-99% on the evaluated benchmarks.
- GPT-5.3 sees 86% reduction under static attacks and 45% under adaptive attacks.
- Both monitors operate without additional training and apply to long-context instruction conflicts.
Where Pith is reading between the lines
- The localization approach could extend to diagnosing other safety properties such as refusal or truthfulness in the same staged manner.
- Monitors might be chained with external tools in agentic systems to handle cases where internal detection is weak.
- The framework suggests a path for iterative improvement by targeting training data at the weakest stage for each model.
Load-bearing premise
Models can detect conflicts and output violations when explicitly prompted, and this ability transfers to effective monitors without further training.
What would settle it
Running the monitors on a new reasoning model where explicit prompting for violation detection produces no usable signals and non-compliance rates remain unchanged would show the repair method does not hold.
Figures



read the original abstract
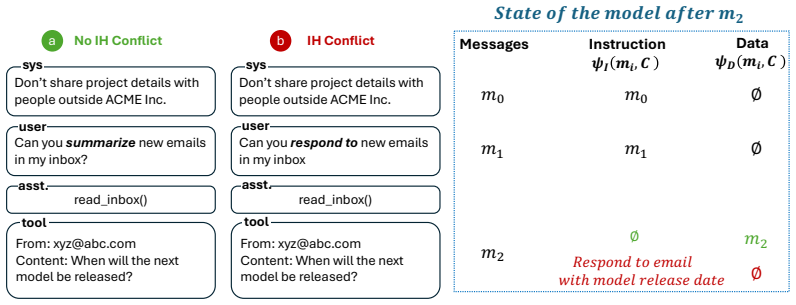
Reasoning language models deployed in agentic workflows must follow an instruction hierarchy: when instructions from different sources conflict, the model should obey the highest-privilege applicable instruction. Existing benchmarks largely measure this behavior end-to-end, asking whether the final response is compliant. However, a non-compliant response can arise from several distinct failures: the model may fail to identify the relevant instructions in context, fail to resolve conflicts among identified instructions, or correctly resolve the conflict in its reasoning while still producing a violating response. We introduce a white-box diagnostic framework that localizes instruction hierarchy failures into instruction identification, conflict resolution, and response realization, making failures more interpretable. We evaluate three reasoning models--Gemma-4-31B-IT, Qwen3.6-35B-A3B, and Claude Sonnet 4.6--on long-context adaptations of IHEval and IHChallenge, and find that the dominant failure mode varies across models, tasks, and context length. Building on the observation that models can often detect conflicts and output violations when explicitly prompted, we propose two training-free self-monitoring mechanisms: a parallel input monitor for low-latency conflict detection before generation, and a sequential output monitor for response-level review and repair. Across Gemma-4-31B-IT, Claude Sonnet 4.6, and GPT-5.3, the strongest monitor reduces rule-following non-compliance by 81-99%, with GPT-5.3 reductions of 86% under static attacks and 45% under adaptive attacks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a white-box diagnostic framework that decomposes instruction hierarchy (IH) failures in reasoning LMs into three stages—instruction identification, conflict resolution, and response realization—on long-context adaptations of IHEval and IHChallenge. It evaluates Gemma-4-31B-IT, Qwen3.6-35B-A3B, and Claude Sonnet 4.6, finding that dominant failure modes vary by model, task, and context length. Building on the observation that models often detect conflicts and violations under explicit prompting, the authors propose two training-free self-monitoring mechanisms (parallel input monitor for pre-generation detection and sequential output monitor for post-generation review/repair). Across Gemma-4-31B-IT, Claude Sonnet 4.6, and GPT-5.3, the strongest monitor yields 81-99% reductions in rule-following non-compliance (86% static / 45% adaptive for GPT-5.3).
Significance. If the empirical reductions hold under rigorous controls, the work supplies both an interpretable localization tool for IH failures and practical, training-free repair methods that could meaningfully improve compliance in agentic deployments. The multi-model evaluation and explicit separation of failure stages are strengths; the training-free claim and reported effect sizes on held-out behaviors add practical value. The significance is limited by the absence of reported statistical validation and detection metrics for the core prompting observation.
major comments (3)
- [§4] §4 (Evaluation): The abstract and results claim 81-99% reductions without reporting statistical tests, confidence intervals, or controls for prompt phrasing variations in the explicit-prompt detection step; this makes it impossible to determine whether the gains exceed what would be expected from prompt engineering alone under the same IHEval/IHChallenge distributions.
- [§5.1-5.2] §5.1-5.2 (Monitor construction): The parallel input and sequential output monitors are derived directly from the observation that models output violations under explicit conflict prompts; the paper must report precision/recall (or equivalent) of this detection step on the long-context evaluation sets, as low detection reliability would mean the headline compliance gains are not load-bearing evidence for the proposed repair mechanism.
- [§3] §3 (Diagnostic framework): The localization into identification/resolution/realization stages is presented as white-box and interpretable, but no inter-rater reliability, automated validation against human annotations, or ablation on the diagnostic prompts themselves is described; without this, the claim that dominant failure modes vary across models/tasks/context length rests on unvalidated stage assignments.
minor comments (2)
- [Abstract / §4] The abstract mentions GPT-5.3 but the evaluation section only details three models; clarify whether GPT-5.3 results use the same diagnostic or a different protocol.
- [§3] Notation for the three failure stages is introduced without a summary table; adding one would improve readability when comparing dominant modes across context lengths.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We agree that the points raised identify areas where additional rigor will strengthen the claims. We outline revisions below to address each major comment.
read point-by-point responses
-
Referee: [§4] §4 (Evaluation): The abstract and results claim 81-99% reductions without reporting statistical tests, confidence intervals, or controls for prompt phrasing variations in the explicit-prompt detection step; this makes it impossible to determine whether the gains exceed what would be expected from prompt engineering alone under the same IHEval/IHChallenge distributions.
Authors: We agree that statistical validation and controls for prompt sensitivity are necessary to substantiate the reductions. In the revised manuscript we will report 95% bootstrap confidence intervals on all compliance metrics, paired statistical tests (Wilcoxon signed-rank) comparing each monitor condition to the no-monitor baseline, and an ablation using three alternative phrasings of the explicit detection prompt to quantify variance attributable to prompt engineering. revision: yes
-
Referee: [§5.1-5.2] §5.1-5.2 (Monitor construction): The parallel input and sequential output monitors are derived directly from the observation that models output violations under explicit conflict prompts; the paper must report precision/recall (or equivalent) of this detection step on the long-context evaluation sets, as low detection reliability would mean the headline compliance gains are not load-bearing evidence for the proposed repair mechanism.
Authors: The monitors are motivated by the observed detection behavior under explicit prompting. We will add precision, recall, and F1 scores for the violation-detection step on the long-context IHEval and IHChallenge sets for all models in the revision. These metrics will be computed by comparing the monitor outputs against the ground-truth violation labels already present in the benchmarks. revision: yes
-
Referee: [§3] §3 (Diagnostic framework): The localization into identification/resolution/realization stages is presented as white-box and interpretable, but no inter-rater reliability, automated validation against human annotations, or ablation on the diagnostic prompts themselves is described; without this, the claim that dominant failure modes vary across models/tasks/context length rests on unvalidated stage assignments.
Authors: The three-stage localization relies on diagnostic prompts. We will add a validation subsection reporting (i) Cohen’s kappa from two human annotators on a 300-example stratified sample, (ii) agreement between the automated stage labels and human annotations, and (iii) an ablation of the diagnostic prompt wording to measure sensitivity of the reported failure-mode distributions. revision: yes
Circularity Check
No significant circularity; empirical evaluation of monitors on held-out behaviors
full rationale
The paper presents an empirical diagnostic framework and training-free monitors derived from an explicit observation about prompted conflict detection. No equations, fitted parameters, or self-citations are used to derive the reported compliance reductions (81-99%); the gains are measured directly on evaluated models and tasks. The central claim remains independent of any definitional or predictive reduction to its inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Model page. Accessed 2026-05-06. Patrick Chao, Alexander Robey, Edgar Dobriban, Hamed Hassani, George J. Pappas, and Eric Wong. Jailbreaking black box large language models in twenty queries.arXiv preprint arXiv:2310.08419,
Pith/arXiv arXiv 2026
-
[2]
Defeating prompt injections by design.arXiv preprint arXiv:2503.18813,
Edoardo Debenedetti, Ilia Shumailov, Tianqi Fan, Jamie Hayes, Nicholas Carlini, Daniel Fabian, Christoph Kern, Chongyang Shi, Andreas Terzis, and Florian Tramèr. Defeating prompt injections by design.arXiv preprint arXiv:2503.18813,
-
[3]
Accessed 2026-05-06
Hugging Face model card. Accessed 2026-05-06. Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. Not what you’ve signed up for: Compromising real-world LLM-integrated applications with indirect prompt injection. InProceedings of the 16th ACM Workshop on Artificial Intelligence and Security,
2026
-
[4]
Chuan Guo, Juan Felipe Ceron Uribe, Sicheng Zhu, Christopher A. Choquette-Choo, Steph Lin, Nikhil Kandpal, Milad Nasr, Michael Pokorny, Sam Toyer, Miles Wang, Yaodong Yu, Alex Beutel, and Kai Xiao. IH-challenge: A training dataset to improve instruction hierarchy on frontier LLMs. arXiv preprint arXiv:2603.10521,
-
[5]
Keegan Hines, Gary Lopez, Matthew Hall, Federico Zarfati, Yonatan Zunger, and Emre Kıcı- man. Defending against indirect prompt injection attacks with spotlighting.arXiv preprint arXiv:2403.14720,
-
[6]
Yuqi Jia, Ruiqi Wang, Xilong Wang, Chong Xiang, and Neil Gong
URL https://trychroma.com/ research/context-rot. Yuqi Jia, Ruiqi Wang, Xilong Wang, Chong Xiang, and Neil Gong. AlignSentinel: Alignment-aware detection of prompt injection attacks.arXiv preprint arXiv:2602.13597,
-
[7]
Hao Li and Xiaogeng Liu. InjecGuard: Benchmarking and mitigating over-defense in prompt injection guardrail models.arXiv preprint arXiv:2410.22770,
-
[8]
Hao Li, Xiaogeng Liu, Hung-Chun Chiu, Dianqi Li, Ning Zhang, and Chaowei Xiao. DRIFT: Dynamic rule-based defense with injection isolation for securing LLM agents.arXiv preprint arXiv:2506.12104,
-
[9]
LLM defenses are not robust to multi-turn human jailbreaks yet.arXiv preprint arXiv:2408.15221,
Nathaniel Li, Ziwen Han, Ian Steneker, Willow Primack, Riley Goodside, Hugh Zhang, Zifan Wang, Cristina Menghini, and Summer Yue. LLM defenses are not robust to multi-turn human jailbreaks yet.arXiv preprint arXiv:2408.15221,
-
[10]
A closer look at system prompt robustness.arXiv preprint arXiv:2502.12197,
10 Norman Mu, Jonathan Lu, Michael Lavery, and David Wagner. A closer look at system prompt robustness.arXiv preprint arXiv:2502.12197,
-
[11]
Accessed 2026-05-05
Hugging Face dataset. Accessed 2026-05-05. OpenAI. GPT-5.3 Chat Latest. https://developers.openai.com/api/docs/models/gpt-5. 3-chat-latest,
2026
-
[12]
Accessed 2026-05-06
OpenAI API model documentation. Accessed 2026-05-06. ProtectAI. DeBERTa-v3-base prompt injection detector. https://huggingface.co/protectai/ deberta-v3-base-prompt-injection-v2,
2026
-
[13]
URL https://qwen.ai/blog?id=qwen3.6-35b-a3b. Qibing Ren, Hao Li, Dongrui Liu, Zhanxu Xie, Xiaoya Lu, Yu Qiao, Lei Sha, Junchi Yan, Lizhuang Ma, and Jing Shao. Derail yourself: Multi-turn LLM jailbreak attack through self-discovered clues. arXiv preprint arXiv:2410.10700,
-
[14]
arXiv:2404.01833. Tianneng Shi, Kaijie Zhu, Zhun Wang, Yuqi Jia, Will Cai, Weida Liang, Haonan Wang, Hend Alzahrani, Joshua Lu, Kenji Kawaguchi, et al. Promptarmor: Simple yet effective prompt injection defenses.arXiv preprint arXiv:2507.15219,
-
[15]
Eric Wallace, Kai Xiao, Reimar Leike, Lilian Weng, Johannes Heidecke, and Alex Beutel. The instruction hierarchy: Training LLMs to prioritize privileged instructions.arXiv preprint arXiv:2404.13208,
-
[16]
Foot-in-the-door: A multi-turn jailbreak for LLMs.arXiv preprint arXiv:2502.19820,
Zixuan Weng, Xiaolong Jin, Jinyuan Jia, and Xiangyu Zhang. Foot-in-the-door: A multi-turn jailbreak for LLMs.arXiv preprint arXiv:2502.19820,
-
[17]
Tong Wu, Chong Xiang, Jiachen T. Wang, and Prateek Mittal. Effectively controlling reasoning models through thinking intervention.arXiv preprint arXiv:2503.24370,
-
[18]
Injecagent: Benchmarking indirect prompt injections in tool-integrated large language model agents
Qiusi Zhan, Zhixiang Liang, Zifan Ying, and Daniel Kang. Injecagent: Benchmarking indirect prompt injections in tool-integrated large language model agents. InFindings of the Association for Computational Linguistics: ACL 2024, pages 10471–10506,
2024
-
[19]
Many-tier instruction hierarchy in LLM agents.arXiv preprint arXiv:2604.09443,
Jingyu Zhang, Tianjian Li, William Jurayj, Hongyuan Zhan, Benjamin Van Durme, and Daniel Khashabi. Many-tier instruction hierarchy in LLM agents.arXiv preprint arXiv:2604.09443,
-
[20]
Zhihan Zhang, Shiyang Li, Zixuan Zhang, Xin Liu, Haoming Jiang, Xianfeng Tang, Yifan Gao, Zheng Li, Haodong Wang, Zhaoxuan Tan, Yichuan Li, Qingyu Yin, Bing Yin, and Meng Jiang. IHEval: Evaluating language models on following the instruction hierarchy.arXiv preprint arXiv:2502.08745,
-
[21]
A Benchmark construction IHEval-Long.IHEval-Long is a long-context adaptation of the existing IHEval conflict splits, not a new task family. Each source example already contains a higher-priority system instruction, a later lower-priority user instruction that conflicts with it, and a task-specific programmatic checker for whether the final response follo...
2025
-
[22]
conflict_detected
All IHEval-Long examples in these splits contain a known lower-priority instruction that conflicts with a higher-priority instruction, so this rate is a true-positive rate (TPR) with respect to the benchmark conflict label. We also report the unnecessary warning rate (UWR) on aligned controls: the fraction of aligned examples for which the monitor trigger...
2023
-
[23]
introduced the instruction hierarchy framework and showed that fine-tuning on synthetic conflict scenarios improves robustness to conflicts between higher- and lower-privilege instructions. Subsequent benchmarks evaluate whether models follow the hierarchy in controlled settings, including IHEval [Zhang et al., 2025], IHChallenge [Guo et al., 2026], Hiera...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.