Multi-Agent Reasoning with Adaptive Worker Allocation for Stance Detection
Pith reviewed 2026-06-27 10:17 UTC · model grok-4.3
The pith
A manager-worker system allocates variable agents to synthesize distinct reasoning paths instead of voting on stance labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
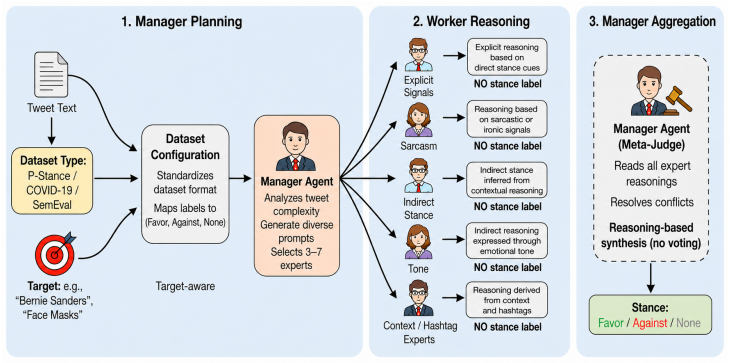
The central claim is that a Manager-Worker architecture adaptively allocates a variable number of Worker agents according to input complexity; each Worker produces a reasoning-only explanation from a distinct perspective without emitting a stance label; the Manager then synthesizes the collected explanations to output the final stance, yielding higher accuracy than label-level aggregation methods especially when stance cannot be read from surface cues.
What carries the argument
The Manager-Worker architecture that performs adaptive allocation of workers based on input complexity followed by reasoning-level synthesis of explanations.
If this is right
- Largest performance gains appear on implicit and context-dependent stance instances.
- Competitive results are retained on datasets where stance is more explicit.
- The same pattern holds across Llama, Mistral, and Gemini models.
- Reasoning-level aggregation preserves intermediate steps that label voting discards.
Where Pith is reading between the lines
- The same adaptive-reasoning pattern could be tested on other ambiguous classification tasks such as sarcasm detection or rumor verification.
- Measuring the actual token cost of variable versus fixed worker counts would show whether the allocation step saves compute on easy inputs.
- Replacing the manager's complexity judgment with a learned router might further stabilize performance across domains.
Load-bearing premise
That the manager can reliably judge input complexity to choose the right number of workers and that combining multiple reasoning explanations produces a more accurate stance than aggregating the labels those same agents would have produced.
What would settle it
A direct head-to-head comparison on a set of implicit stance examples in which the reasoning-synthesis method fails to exceed the Macro-F1 of majority voting or self-consistency applied to the same base model.
Figures
read the original abstract
Stance detection requires identifying an author's position toward a target, often from short-form texts where stance is implicit, indirect, or rhetorically framed. Although large language models (LLMs) achieve strong performance on this task, single-pass prompting can be brittle when multiple interpretations are plausible. Existing aggregation strategies, such as majority voting or self-consistency, improve robustness by combining labels, but they discard the intermediate reasoning needed to resolve conflicting interpretations. We introduce a multi-agent reasoning framework with adaptive worker allocation for stance detection that shifts aggregation from label-level voting to reasoning-level synthesis. The framework employs a Manager-Worker architecture in which a Manager adaptively allocates a variable number of Worker agents based on input complexity. Each Worker analyzes the input from a distinct perspective and produces a reasoning-only explanation without emitting a stance label; the Manager then synthesizes these explanations to produce the final prediction. We evaluate the proposed framework on SemEval-2016, P-Stance, and COVID-19 Stance using Llama, Mistral, and Gemini. Results show that the framework yields the largest gains on implicit and context-dependent stance cases, achieving 86.07 Macro-F1 on COVID-19 and 82.90 on SemEval-2016, while remaining competitive on more explicit stance datasets such as P-Stance. These findings suggest that adaptive reasoning-level aggregation is most beneficial when stance cannot be reliably inferred from surface cues alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a Manager-Worker multi-agent framework for stance detection in which a Manager adaptively allocates a variable number of Workers based on estimated input complexity; each Worker produces a reasoning-only explanation from a distinct perspective, and the Manager synthesizes the explanations (rather than labels) to output the final stance. Experiments on SemEval-2016, P-Stance, and COVID-19 Stance with Llama, Mistral, and Gemini report the largest gains on implicit/context-dependent cases, reaching 86.07 Macro-F1 on COVID-19 and 82.90 on SemEval-2016.
Significance. If the adaptive allocation and reasoning-level synthesis can be shown to drive the reported gains beyond what is obtained by simply increasing the number of parallel reasoning chains, the framework would offer a concrete advance for handling implicit stance, a known pain point for single-pass and label-aggregation methods. The emphasis on implicit subsets is a positive focus, but the current evidence does not yet isolate the claimed mechanisms.
major comments (3)
- [Experiments / Results] The central claim that adaptive worker allocation and reasoning-level synthesis outperform label-level aggregation requires an ablation that holds total worker-steps (or total reasoning tokens) fixed while disabling adaptivity. No such controlled comparison is described; the headline numbers on the implicit subsets of COVID-19 and SemEval-2016 could therefore be explained by raw compute rather than the adaptive or synthesis components.
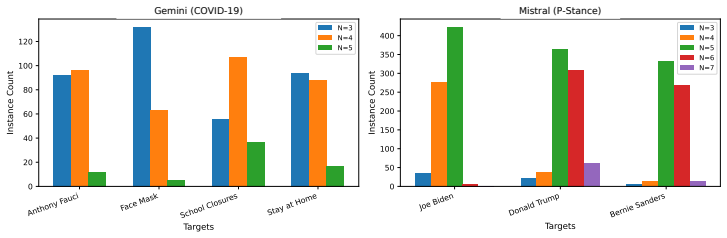
- [Method / Manager-Worker Architecture] The manuscript states that the Manager "adaptively allocates a variable number of Worker agents based on input complexity" and that gains are largest on implicit cases, yet provides no correlation analysis or human-annotated ambiguity labels showing that higher worker counts are in fact assigned to the implicit subset. Without this link, the routing mechanism remains unverified.
- [Experiments / Results] Table or figure reporting the per-dataset Macro-F1 scores (including the 86.07 and 82.90 figures) does not include standard deviations across runs, statistical significance tests against the strongest baselines (majority voting, self-consistency), or an explicit breakdown by explicit vs. implicit subsets; this weakens the claim that gains are concentrated on implicit cases.
minor comments (2)
- [Method] The description of how the Manager judges complexity (prompt, features, or learned module) is only sketched at a high level; a concrete algorithm or pseudocode would improve reproducibility.
- [Experiments] Baseline descriptions should explicitly state whether the compared methods also receive the same total reasoning budget as the proposed adaptive runs.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important gaps in our experimental validation. We address each point below and commit to revisions that directly strengthen the evidence for our claims.
read point-by-point responses
-
Referee: [Experiments / Results] The central claim that adaptive worker allocation and reasoning-level synthesis outperform label-level aggregation requires an ablation that holds total worker-steps (or total reasoning tokens) fixed while disabling adaptivity. No such controlled comparison is described; the headline numbers on the implicit subsets of COVID-19 and SemEval-2016 could therefore be explained by raw compute rather than the adaptive or synthesis components.
Authors: We agree that this controlled ablation is required to isolate the contribution of adaptivity. In the revised manuscript we will add an experiment that fixes the total number of worker reasoning steps (or token budget) across conditions and directly compares the adaptive manager against a non-adaptive baseline that always uses the maximum worker count. This will clarify whether gains arise from the routing policy or from aggregate compute. revision: yes
-
Referee: [Method / Manager-Worker Architecture] The manuscript states that the Manager "adaptively allocates a variable number of Worker agents based on input complexity" and that gains are largest on implicit cases, yet provides no correlation analysis or human-annotated ambiguity labels showing that higher worker counts are in fact assigned to the implicit subset. Without this link, the routing mechanism remains unverified.
Authors: We acknowledge the absence of this verification. In revision we will add a correlation analysis between allocated worker count and stance implicitness, using the existing explicit/implicit annotations in the COVID-19 and SemEval datasets (or a simple surface-feature proxy for ambiguity on P-Stance). We will also report the distribution of worker counts conditioned on subset type. revision: yes
-
Referee: [Experiments / Results] Table or figure reporting the per-dataset Macro-F1 scores (including the 86.07 and 82.90 figures) does not include standard deviations across runs, statistical significance tests against the strongest baselines (majority voting, self-consistency), or an explicit breakdown by explicit vs. implicit subsets; this weakens the claim that gains are concentrated on implicit cases.
Authors: We agree these reporting elements are necessary. The revised tables will include (i) standard deviations over at least three independent runs, (ii) statistical significance tests (paired t-test or McNemar) against majority voting and self-consistency, and (iii) explicit per-subset Macro-F1 breakdowns for all three datasets. The headline figures will be presented with these supporting statistics. revision: yes
Circularity Check
No circularity: empirical evaluation on public benchmarks with no fitted predictions or self-referential derivations
full rationale
The manuscript describes an empirical multi-agent framework evaluated on standard public stance-detection datasets (SemEval-2016, P-Stance, COVID-19). Reported Macro-F1 numbers are direct experimental outcomes, not quantities defined in terms of fitted parameters, renamed known results, or load-bearing self-citations. No equations, uniqueness theorems, or ansatzes appear; the central claims rest on comparative performance rather than any derivation chain that reduces to its own inputs by construction. This is the expected non-finding for a purely experimental systems paper.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Large language models can generate distinct, non-redundant reasoning explanations from different perspectives when prompted appropriately.
- domain assumption Input complexity can be assessed automatically to decide the number of workers needed.
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 10th international workshop on semantic evaluation (SemEval-2016) , pages=
Semeval-2016 task 6: Detecting stance in tweets , author=. Proceedings of the 10th international workshop on semantic evaluation (SemEval-2016) , pages=
2016
-
[2]
Proceedings of the sixth international joint conference on natural language processing , pages=
Stance classification of ideological debates: Data, models, features, and constraints , author=. Proceedings of the sixth international joint conference on natural language processing , pages=
-
[3]
Proceedings of the 2016 conference on empirical methods in natural language processing , pages=
Stance detection with bidirectional conditional encoding , author=. Proceedings of the 2016 conference on empirical methods in natural language processing , pages=
2016
-
[4]
Proceedings of the 10th international workshop on semantic evaluation (SemEval-2016) , pages=
Mitre at semeval-2016 task 6: Transfer learning for stance detection , author=. Proceedings of the 10th international workshop on semantic evaluation (SemEval-2016) , pages=
2016
-
[5]
Proceedings of the fifth joint conference on lexical and computational semantics , pages=
Detecting stance in tweets and analyzing its interaction with sentiment , author=. Proceedings of the fifth joint conference on lexical and computational semantics , pages=
-
[6]
26th International Joint Conference on Artificial Intelligence, IJCAI 2017 , pages=
Stance classification with target-specific neural attention networks , author=. 26th International Joint Conference on Artificial Intelligence, IJCAI 2017 , pages=. 2017 , organization=
2017
-
[7]
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers) , pages=
2019
-
[8]
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
Zero-shot stance detection: A dataset and model using generalized topic representations , author=. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
2020
-
[9]
Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
Will-they-won’t-they: A very large dataset for stance detection on Twitter , author=. Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
-
[10]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[11]
Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics (ACL) , year=
Stance Detection in COVID-19 Tweets , author=. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics (ACL) , year=
-
[12]
Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , pages=
Edda: An encoder-decoder data augmentation framework for zero-shot stance detection , author=. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , pages=
2024
-
[13]
Findings of the association for computational linguistics: ACL-IJCNLP 2021 , pages=
P-stance: A large dataset for stance detection in political domain , author=. Findings of the association for computational linguistics: ACL-IJCNLP 2021 , pages=
2021
-
[14]
Findings of the Association for Computational Linguistics: NAACL 2022 , year=
A Survey on Stance Detection for Mis- and Disinformation Identification , author=. Findings of the Association for Computational Linguistics: NAACL 2022 , year=
2022
-
[15]
Proceedings of NAACL-HLT , pages =
Kawintiranon, Kornraphop and Singh, Lisa , title =. Proceedings of NAACL-HLT , pages =
-
[16]
Proceedings of the 12th Workshop on Computational Approaches to Subjectivity, Sentiment & Social Media Analysis , pages=
Infusing knowledge from Wikipedia to enhance stance detection , author=. Proceedings of the 12th Workshop on Computational Approaches to Subjectivity, Sentiment & Social Media Analysis , pages=
-
[17]
Proceedings of WWW , pages =
Liang, Bin and Chen, Zixiao and Gui, Lin and He, Yulan and Yang, Min and Xu, Ruifeng , title =. Proceedings of WWW , pages =
-
[18]
International Conference on Learning Representations (ICLR) , year=
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author=. International Conference on Learning Representations (ICLR) , year=
-
[19]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Large Language Models are Zero-Shot Reasoners , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[20]
International Conference on Learning Representations (ICLR) , year=
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models , author=. International Conference on Learning Representations (ICLR) , year=
-
[21]
Advances in neural information processing systems , volume=
Tree of thoughts: Deliberate problem solving with large language models , author=. Advances in neural information processing systems , volume=
-
[22]
Proceedings of the international AAAI conference on web and social media , volume=
Stance detection with collaborative role-infused llm-based agents , author=. Proceedings of the international AAAI conference on web and social media , volume=
-
[23]
First conference on language modeling , year=
Autogen: Enabling next-gen LLM applications via multi-agent conversations , author=. First conference on language modeling , year=
-
[24]
Advances in neural information processing systems , volume=
Camel: Communicative agents for" mind" exploration of large language model society , author=. Advances in neural information processing systems , volume=
-
[25]
MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework
MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework , author=. arXiv preprint arXiv:2308.00352 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Forty-first international conference on machine learning , year=
Improving factuality and reasoning in language models through multiagent debate , author=. Forty-first international conference on machine learning , year=
-
[27]
Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , year=
DEEM: Dynamic Experienced Expert Modeling for Stance Detection , author=. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , year=
2024
-
[28]
Proceedings of LREC-COLING 2024 , year=
Stance Reasoner: Zero-Shot Stance Detection on Social Media with Explicit Reasoning , author=. Proceedings of LREC-COLING 2024 , year=
2024
-
[29]
Proceedings of the AAAI conference on artificial intelligence , volume=
Graph of thoughts: Solving elaborate problems with large language models , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[30]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
Stanceformer: Target-aware transformer for stance detection , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[31]
International Conference on Database Systems for Advanced Applications , pages=
Collaborative stance detection via small-large language model consistency verification , author=. International Conference on Database Systems for Advanced Applications , pages=. 2025 , organization=
2025
-
[32]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
MSME: A Multi-Stage Multi-Expert Framework for Zero-Shot Stance Detection , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[33]
Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
Sarcasm as Contrast between a Positive Sentiment and a Negative Situation , author=. Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
-
[34]
proceedings of the international AAAI conference on web and social media , volume=
Contextualized sarcasm detection on twitter , author=. proceedings of the international AAAI conference on web and social media , volume=
-
[35]
Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing (ACL-IJCNLP) , year=
Recognizing Stances in Online Debates , author=. Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing (ACL-IJCNLP) , year=
-
[36]
International Conference on Learning Representations (ICLR) , year=
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer , author=. International Conference on Learning Representations (ICLR) , year=
-
[37]
International Conference on Learning Representations (ICLR) , year=
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding , author=. International Conference on Learning Representations (ICLR) , year=
-
[38]
International Conference on Machine Learning (ICML) , year=
GLaM: Efficient Scaling of Language Models with Mixture-of-Experts , author=. International Conference on Machine Learning (ICML) , year=
-
[39]
International Conference on Learning Representations (ICLR) , year=
Large Language Models are Human-Level Prompt Engineers , author=. International Conference on Learning Representations (ICLR) , year=
-
[40]
Gradient Descent
Automatic Prompt Optimization with "Gradient Descent" and Beam Search , author=. Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP) , year=
-
[41]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.