When More Documents Hurt RAG: Mitigating Vector Search Dilution with Domain-Scoped, Model-Agnostic Retrieval
Pith reviewed 2026-06-27 13:28 UTC · model grok-4.3
The pith
Domain scoping using organizational metadata raises RAG P@10 from 0.77 to 0.86 on large heterogeneous corpora.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
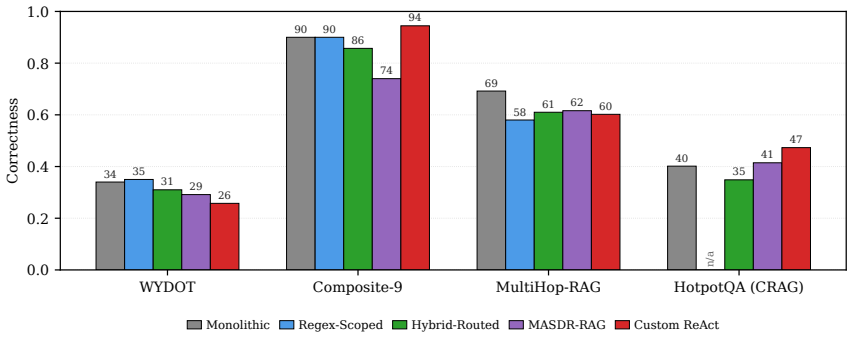
Domain scoping using organizational metadata is the key fix for vector search dilution in RAG, significantly improving P@10 from 0.77 to 0.86 (p < 0.05) across five LLM backbones, six corpora, and two index stacks, while multi-agent orchestration creates a precision-faithfulness paradox that makes it less reliable than a single synthesis call after scoping.
What carries the argument
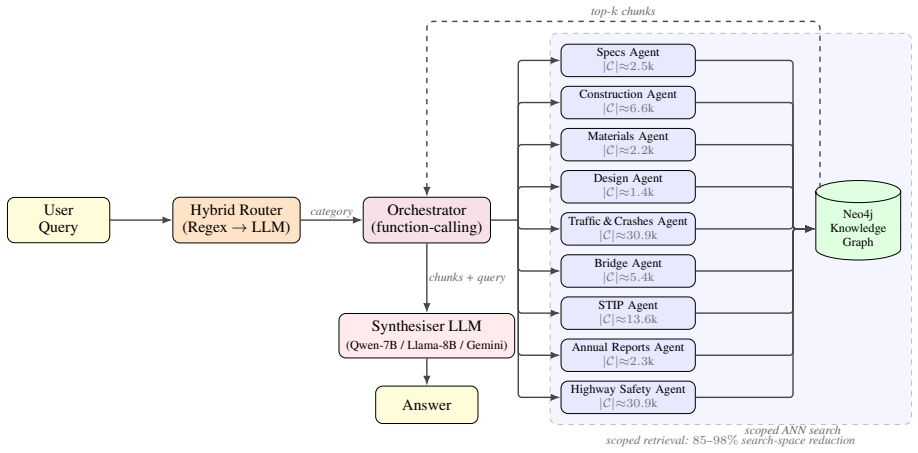
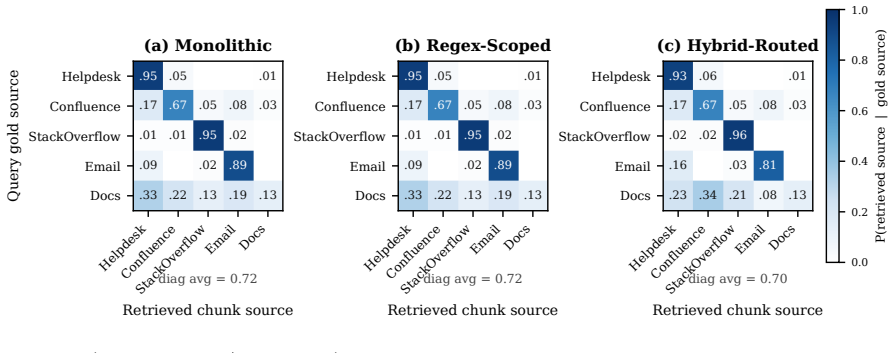
Domain scoping using organizational metadata to restrict retrieval to relevant document subsets before similarity search.
If this is right
- Scoping first followed by a single synthesis call outperforms full multi-agent orchestration on single-domain corpora.
- Hybrid dense-plus-sparse retrieval alone does not prevent dilution on heterogeneous collections.
- Multi-agent orchestration should be reserved for multi-domain corpora paired with native-tool-call backbones.
- The precision-faithfulness paradox appears when orchestration degree increases without corresponding domain separation.
Where Pith is reading between the lines
- If reliable organizational metadata is absent, learned domain classifiers could serve as a substitute but would need separate validation.
- The scoping technique could be extended to query-time dynamic partitioning without static metadata tags.
- Production RAG pipelines may benefit more from investing in metadata quality than from increasing retrieval complexity.
Load-bearing premise
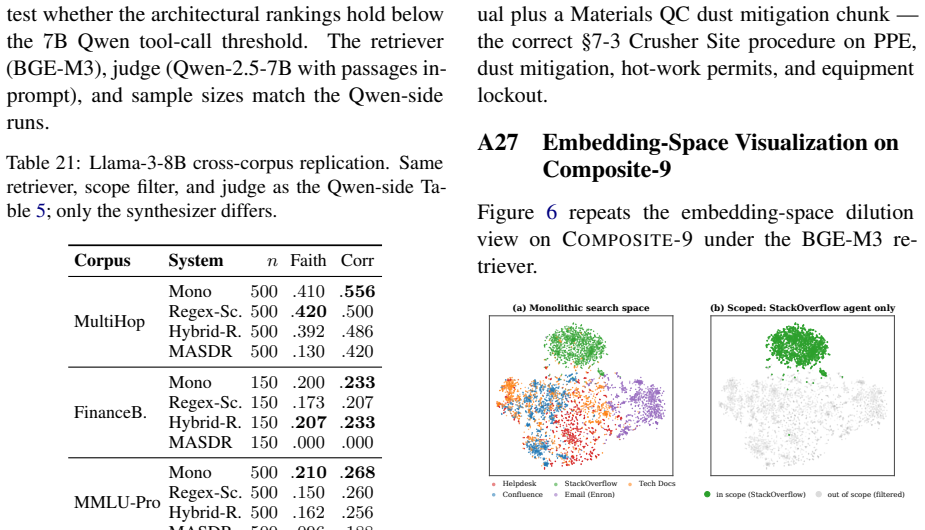
The observed accuracy drop when scaling document count is caused by vector search dilution rather than changes in query distribution, index details, or corpus properties.
What would settle it
A controlled scaling experiment that holds query distribution and index construction fixed while adding documents and shows no accuracy loss without scoping would falsify the dilution mechanism.
Figures




read the original abstract
Retrieval-augmented generation degrades when scaled to large, heterogeneous document collections, where dense similarity loses discriminative power, and top-k retrieval increasingly returns semantically similar but contextually incorrect chunks. We refer to this failure mode as vector search dilution. Even when using hybrid dense+sparse retrieval, we observed this firsthand in a deployed Wyoming Department of Transportation corpus, where scaling from 54 to 1,128 documents (88,907 chunks) reduced accuracy from 75% to below 40%. To address this dilution, we propose MASDR-RAG ( Multi-Agent Scoped Domain Retrieval for RAG) and evaluate it on 200 expert-validated queries across five LLM backbones, six corpora, and two index stacks. Our results indicate that domain scoping using organizational metadata is the key fix, significantly improving P@10 from 0.77 to 0.86 ($p < 0.05$). Furthermore, our investigation of multi-agent orchestration revealed that a high degree of configuration dependence results --creating what we call the precision-faithfulness paradox. Based on these varied outcomes, our practical recommendation is simple: scope first, then perform a single synthesis call, reserving full multi-agent orchestration for genuinely multi-domain corpora paired with native-tool-call backbones. Code and Data will be made public upon acceptance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that RAG performance degrades due to 'vector search dilution' in large heterogeneous corpora, as shown by an accuracy drop from 75% to below 40% when scaling a Wyoming DoT corpus from 54 to 1,128 documents (88,907 chunks). It proposes MASDR-RAG, which applies domain scoping via organizational metadata, and reports that this yields a statistically significant P@10 improvement from 0.77 to 0.86 (p < 0.05) on 200 expert-validated queries evaluated across five LLM backbones, six corpora, and two index stacks. The work additionally identifies a 'precision-faithfulness paradox' in multi-agent orchestration and recommends scoping first followed by a single synthesis call, reserving full multi-agent setups for multi-domain cases with tool-calling models.
Significance. If the central attribution to dilution holds after tighter controls, the result offers actionable deployment guidance for RAG in organizational settings by showing that metadata-based scoping can outperform more elaborate multi-agent pipelines. The breadth of the evaluation (multiple LLMs, corpora, and index types) provides modest evidence of robustness, and the commitment to release code and data upon acceptance is a positive factor for reproducibility.
major comments (2)
- [Abstract] Abstract: the reported P@10 lift (0.77 to 0.86, p < 0.05) is presented without any description of the statistical test performed, query sampling procedure, construction or validation process for the 200 expert-validated queries, or multiple-comparison correction; this absence directly undermines confidence in the central empirical claim.
- [Abstract / reported experiments] Abstract / reported experiments: the accuracy drop when scaling the Wyoming DoT corpus is attributed to vector search dilution, yet the scaling necessarily increases corpus heterogeneity. No controlled ablation is described that holds domain, query distribution, and index construction fixed while varying only document count; consequently the observed P@10 gain could be explained by reduced heterogeneity rather than the proposed scoping mechanism.
minor comments (1)
- [Abstract] Abstract: the parenthetical expansion of MASDR-RAG contains an extraneous space before 'Multi-Agent'.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported P@10 lift (0.77 to 0.86, p < 0.05) is presented without any description of the statistical test performed, query sampling procedure, construction or validation process for the 200 expert-validated queries, or multiple-comparison correction; this absence directly undermines confidence in the central empirical claim.
Authors: We agree that the abstract omits these methodological details. In the revised manuscript we will add a concise methods clause (or footnote) stating: the test is a paired t-test on per-query P@10 scores; the 200 queries were drawn from an expert-validated pool constructed by domain specialists who reviewed real user logs and confirmed relevance; validation included double annotation with reported agreement; and no multiple-comparison correction was applied because the primary comparison was pre-specified. Full procedures remain in Sections 3.3 and 4.1. revision: yes
-
Referee: [Abstract / reported experiments] Abstract / reported experiments: the accuracy drop when scaling the Wyoming DoT corpus is attributed to vector search dilution, yet the scaling necessarily increases corpus heterogeneity. No controlled ablation is described that holds domain, query distribution, and index construction fixed while varying only document count; consequently the observed P@10 gain could be explained by reduced heterogeneity rather than the proposed scoping mechanism.
Authors: The referee is correct that the scaling observation confounds document count with increased domain heterogeneity. That experiment was an in-situ deployment measurement rather than a controlled ablation. Our primary evidence for domain scoping comes from the six-corpus evaluation in which we hold query distribution, index type, and LLM fixed while toggling only the scoping filter; the consistent P@10 gains (0.77 → 0.86) therefore cannot be attributed to heterogeneity reduction alone. We will revise the text to explicitly label the scaling result as observational, note the confound, and clarify that the scoping mechanism is validated by the controlled multi-corpus experiments. revision: partial
Circularity Check
No circularity; empirical results are direct measurements on external data
full rationale
The paper reports measured P@10 improvements (0.77 to 0.86) from domain scoping on 200 expert-validated queries across six corpora, five LLMs, and two index stacks. No equations, fitted parameters, or self-citations appear in the provided text. The claimed gains are obtained by direct evaluation of the proposed system versus baselines on held-out data; the attribution of scaling degradation to vector search dilution is an interpretive hypothesis but does not reduce any result to its own inputs by construction. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 200 expert-validated queries constitute a representative and unbiased test set for measuring retrieval precision.
Reference graph
Works this paper leans on
-
[1]
Retrieval-Augmented Generation for Knowledge-Intensive
Lewis, Patrick and Perez, Ethan and Piktus, Aleksandra and Petroni, Fabio and Karpukhin, Vladimir and Goyal, Naman and K. Retrieval-Augmented Generation for Knowledge-Intensive
-
[2]
Guu, Kelvin and Lee, Kenton and Tung, Zora and Pasupat, Panupong and Chang, Ming-Wei , booktitle =
-
[3]
Retrieval-Augmented Generation for Large Language Models: A Survey , author =
-
[4]
Seven Failure Points When Engineering a Retrieval Augmented Generation System , author =
-
[5]
Advanced Engineering Informatics , year =
Retrieval augmented generation-driven information retrieval and question answering in construction management , author =. Advanced Engineering Informatics , year =
-
[6]
Retrieval Augmentation Reduces Hallucination in Conversation , author =
-
[7]
A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions , author =
-
[8]
Atlas: Few-shot Learning with Retrieval Augmented Language Models , author =
-
[9]
Natural Questions: A Benchmark for Question Answering Research , author =
-
[10]
and Zettlemoyer, Luke , booktitle =
Joshi, Mandar and Choi, Eunsol and Weld, Daniel S. and Zettlemoyer, Luke , booktitle =
-
[11]
Chen, Danqi and Fisch, Adam and Weston, Jason and Bordes, Antoine , booktitle =. Reading
-
[12]
Dense Passage Retrieval for Open-Domain Question Answering , author =
-
[13]
Approximate Nearest Neighbor Negative Contrastive Learning for Dense Text Retrieval , author =
-
[14]
The Probabilistic Relevance Framework:
Robertson, Stephen and Zaragoza, Hugo , journal =. The Probabilistic Relevance Framework:
-
[15]
Efficient and Robust Approximate Nearest Neighbor Search Using Hierarchical Navigable Small World Graphs , author =
-
[16]
Billion-Scale Similarity Search with
Johnson, Jeff and Douze, Matthijs and Jegou, Herve , journal =. Billion-Scale Similarity Search with
-
[17]
Accelerating Large-Scale Inference with Anisotropic Vector Quantization , author =
-
[18]
Sawarkar, Kunal and Mangal, Abhilasha and Solanki, Sanmitra , journal =. Blended
-
[19]
Adaptive-
Jeong, Soyeong and Baek, Jinheon and Cho, Sukmin and Hwang, Sung Ju and Park, Jong , journal =. Adaptive-
-
[20]
Zhang, Jiarui and Liu, Xiangyu and Hu, Yong and Niu, Chaoyue and Wu, Fan and Chen, Guihai , journal =
-
[21]
Guo, Yucan and Su, Miao and Guan, Saiping and Sun, Zihao and Jin, Xiaolong and Guo, Jiafeng and Cheng, Xueqi , journal =
-
[22]
and others , journal =
Poliakov, M. and others , journal =. Multi-Meta-
-
[23]
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik and Cao, Yuan , booktitle =
-
[24]
Schick, Timo and Dwivedi-Yu, Jane and Dessi, Roberto and Raileanu, Roberta and Lomeli, Maria and Hambro, Eric and Zettlemoyer, Luke and Cancedda, Nicola and Scialom, Thomas , booktitle =
-
[25]
Parisi, Aaron and Zhao, Yao and Fiedel, Noah , year = 2022, eprint =
2022
-
[26]
Wu, Qingyun and others , journal =
-
[27]
and others , journal =
Nguyen, T. and others , journal =
-
[28]
From Local to Global: A
Edge, Darren and Trinh, Ha and Cheng, Newman and others , journal =. From Local to Global: A
-
[29]
and others , journal =
Sarmah, B. and others , journal =
-
[30]
and others , journal =
Sanmartin, D. and others , journal =
-
[31]
Agentic Retrieval-Augmented Generation: A Survey , author =
-
[32]
and others , journal =
Masoudifard, M. and others , journal =. Leveraging Domain-Partitioned Retrieval for Engineering
-
[33]
Es, Shahul and James, Jithin and Espinosa Anke, Luis and Schockaert, Steven , booktitle =
-
[34]
Nguyen, Tri and Rosenberg, Mir and Song, Xia and Gao, Jianfeng and Tiwary, Saurabh and Majumder, Rangan and Deng, Li , journal =
-
[35]
and Salakhutdinov, Ruslan and Manning, Christopher D
Yang, Zhilin and Qi, Peng and Zhang, Saizheng and Bengio, Yoshua and Cohen, William W. and Salakhutdinov, Ruslan and Manning, Christopher D. , booktitle =
-
[36]
Tang, Yixuan and Yang, Yi , year = 2024, eprint =
2024
-
[37]
Yang, Xiao and others , year = 2024, eprint =
2024
-
[38]
Sentence-
Reimers, Nils and Gurevych, Iryna , journal =. Sentence-
-
[39]
Improving Text Embeddings with Large Language Models , author =
-
[40]
Grattafiori, Aaron and others , year = 2024, eprint =. The
2024
-
[41]
Chen, Jianlv and Xiao, Shitao and Zhang, Peitian and Luo, Kun and Lian, Defu and Liu, Zheng , year = 2024, eprint =
2024
-
[42]
Retrieval-Augmented Generation for AI-Generated Content: A Survey
Retrieval-Augmented Generation in the Era of Large Language Models , author =. 2402.19473 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Khattab, Omar and Zaharia, Matei , booktitle =
-
[44]
Santhanam, Keshav and Khattab, Omar and Saad-Falcon, Jon and Potts, Christopher and Zaharia, Matei , booktitle =
-
[45]
Chase, Harrison , year = 2023, howpublished =
2023
-
[46]
Asai, Akari and Wu, Zeqiu and Wang, Yizhong and Sil, Avirup and Hajishirzi, Hannaneh , booktitle =
-
[47]
Large Language Models Can Be Easily Distracted by Irrelevant Context , author =
-
[48]
Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge-Intensive Multi-Step Questions , author =
-
[49]
Measuring and Narrowing the Compositionality Gap in Language Models , author =
-
[50]
Enron Email Dataset , author =
-
[51]
Wang, Zhilin and others , booktitle =
-
[52]
Findings of EMNLP , year=
Document Ranking with a Pretrained Sequence-to-Sequence Model , author=. Findings of EMNLP , year=
-
[53]
EMNLP , year=
RocketQAv2: A Joint Training Method for Dense Passage Retrieval and Passage Re-ranking , author=. EMNLP , year=
-
[54]
SIGIR , year=
From Distillation to Hard Negative Sampling: Making Sparse Neural IR Models More Effective , author=. SIGIR , year=
- [55]
-
[56]
2024 , howpublished=
Neural Sparse Encoding --. 2024 , howpublished=
2024
-
[57]
ACL Findings , year=
Context Aware Query Rewriting for Text Rankers using LLM , author=. ACL Findings , year=
-
[58]
SIGIR , year=
Efficient Neural Ranking using Forward Indexes and Lightweight Encoders , author=. SIGIR , year=
-
[59]
ACL-IJCNLP (Short Papers) , year =
The Curse of Dense Low-Dimensional Information Retrieval for Large Index Sizes , author =. ACL-IJCNLP (Short Papers) , year =
-
[60]
The Power of Noise: Redefining Retrieval for
Cuconasu, Florin and Trappolini, Giovanni and Siciliano, Federico and Filice, Simone and Campagnano, Cesare and Maarek, Yoelle and Tonellotto, Nicola and Silvestri, Fabrizio , booktitle =. The Power of Noise: Redefining Retrieval for
-
[61]
, booktitle =
Jin, Bowen and Yoon, Jinsung and Han, Jiawei and Arik, Sercan O. , booktitle =. Long-Context
-
[62]
Yen, Howard and Gao, Tianyu and Hou, Minmin and Ding, Ke and Fleischer, Daniel and Izsak, Peter and Wasserblat, Moshe and Chen, Danqi , booktitle =
-
[63]
Li, Longkun and Zou, Yuanben and Wu, Jinghan and Wen, Yuqing and Li, Jing and Qian, Hangwei and Tsang, Ivor , journal =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.