KaLM-Reranker-V1: Fast but Not Late Interaction for Compressed Document Reranking
Pith reviewed 2026-06-26 08:54 UTC · model grok-4.3
The pith
KaLM-Reranker-V1 decouples passage pre-encoding from query processing while using cross-attention to retain full relevance modeling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
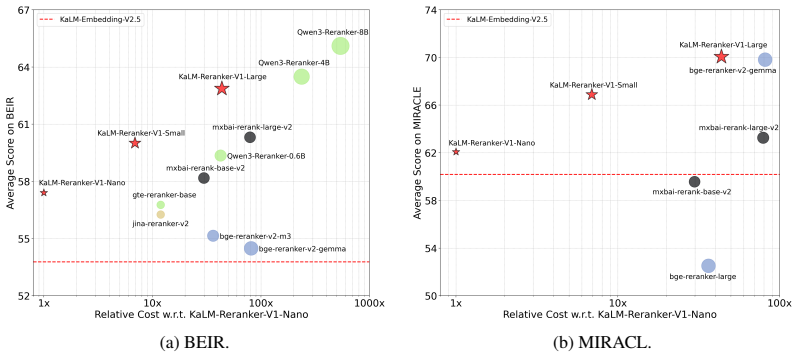
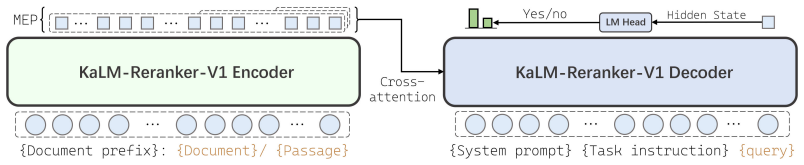
KaLM-Reranker-V1 is built on an encoder-decoder architecture in which the encoder pre-encodes passages with Matryoshka embedding pooling, the decoder models instructions and query intent, and cross-attention then captures relevance between query context and passage representations, yielding state-of-the-art results on BEIR on par with the Qwen3-Reranker series together with strong performance on MIRACL and LMEB even for the 0.27B Nano variant.
What carries the argument
FBNL (fast but not late-interaction) design: encoder pre-encodes passages with Matryoshka embedding pooling while decoder cross-attention models query-passage relevance after independent encoding.
If this is right
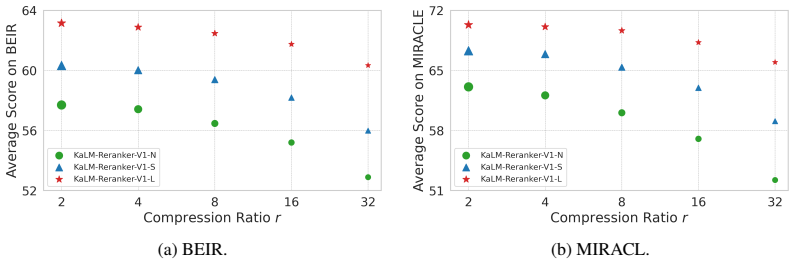
- Three model sizes (0.27B Nano, 1B Small, 4B Large) each deliver competitive reranking accuracy with lower inference cost than joint-encoding baselines.
- Strong results on MIRACL occur without heavy multilingual training, indicating the architecture generalizes beyond English-centric data.
- On LMEB the Nano model remains competitive with 7-12B embedding models, showing reranking advantage even at small scale.
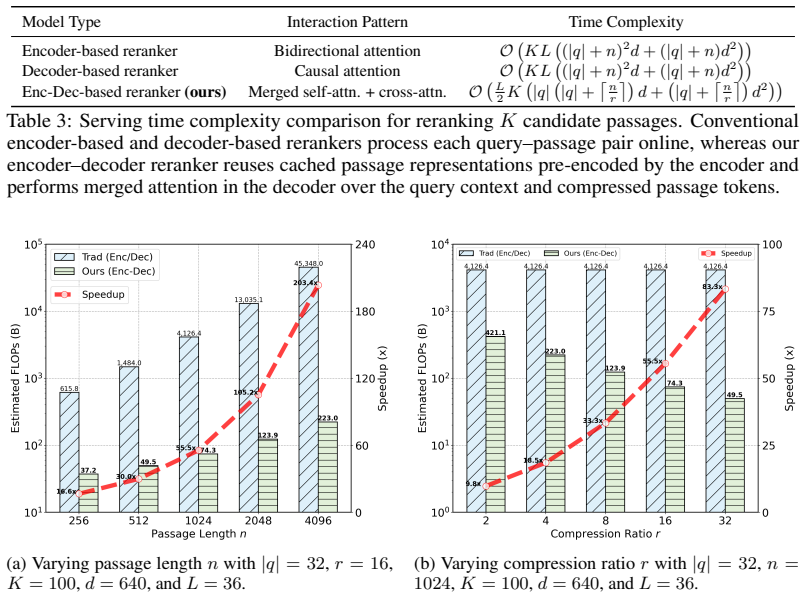
- Decoupled passage encoding allows pre-computation of document representations for faster online query handling.
Where Pith is reading between the lines
- The same decoupling pattern could be applied to other cross-encoder tasks where passage representations can be cached in advance.
- Matryoshka pooling may allow variable-length passage embeddings to be traded against accuracy in resource-constrained settings.
- If the cross-attention step proves robust, hybrid pipelines could mix this reranker with cheaper embedding stages without large accuracy loss.
Load-bearing premise
Pre-encoding passages independently with Matryoshka embedding pooling and applying decoder cross-attention later is sufficient to recover the relevance signals that would be obtained by jointly encoding query and passage.
What would settle it
A controlled head-to-head evaluation on a BEIR subset or new dataset where a jointly encoded reranker of similar size shows a consistent and statistically significant gain in nDCG over all three KaLM-Reranker-V1 sizes.
Figures

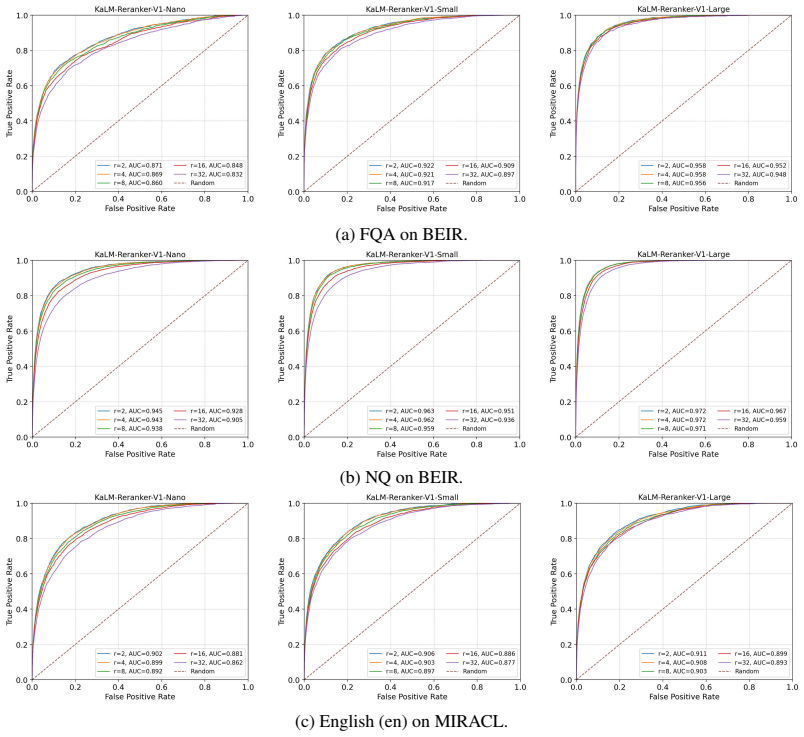
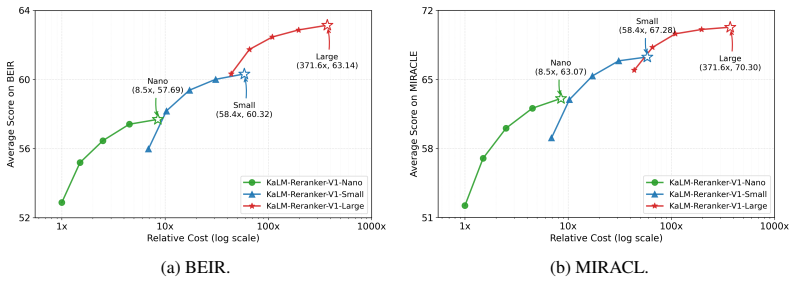
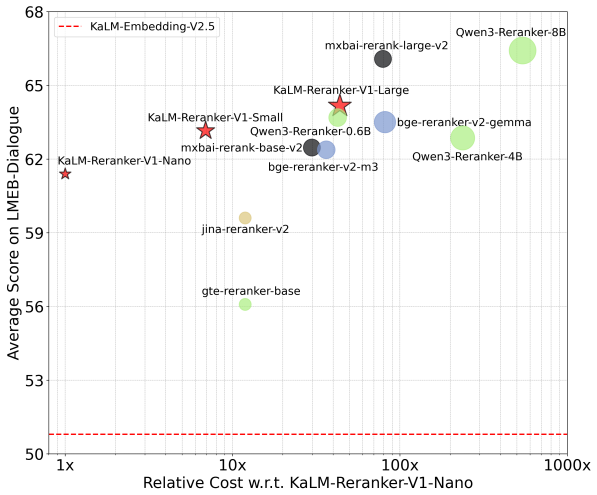
read the original abstract
As retrieval systems scale, high-quality reranking becomes increasingly important. However, most existing rerankers, whether encoder-based or decoder-based, jointly encode the query and passage, tightly coupling their computation and limiting deployment efficiency as well as flexibility. We present KaLM-Reranker-V1, a fast but not late-interaction (FBNL) reranker that decouples query and passage computation while retaining expressive relevance modeling. Built on an encoder-decoder architecture, KaLM-Reranker-V1 uses the encoder to pre-encode passages with Matryoshka embedding pooling, while the decoder models the system instruction, user instruction, and query intent; cross-attention then captures relevance between the query context and passage representations. This design makes KaLM-Reranker-V1 efficient through decoupled passage encoding, yet not late interaction, by preserving rich relevance modeling through cross-attention. We instantiate KaLM-Reranker-V1 in three sizes, Nano, Small, and Large, with 0.27B, 1B, and 4B activated parameters, respectively. Extensive experiments on BEIR, MIRACL, and LMEB demonstrate that KaLM-Reranker-V1 achieves strong reranking performance with superior efficiency. On BEIR, KaLM-Reranker-V1 achieves state-of-the-art performance, on par with strong industrial models such as the Qwen3-Reranker series; on MIRACL, despite not being extensively trained on multilingual data, KaLM-Reranker-V1 still shows excellent reranking performance. Moreover, on LMEB, reranking models demonstrate a clear advantage, with even the 0.27B Nano model remaining competitive with 7-12B embedding models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces KaLM-Reranker-V1, a fast-but-not-late-interaction reranker built on an encoder-decoder architecture. Passages are pre-encoded independently by the encoder using Matryoshka embedding pooling; the decoder processes system/user instructions and query intent, with cross-attention used to model relevance. The work instantiates three sizes (0.27B/1B/4B activated parameters) and reports state-of-the-art results on BEIR (on par with Qwen3-Reranker), strong multilingual performance on MIRACL, and competitive results on LMEB even for the smallest variant, attributing gains to decoupled passage encoding while retaining expressive modeling.
Significance. If the performance claims prove robust under proper controls, the design offers a practical middle ground between fully joint encoder-decoder rerankers and late-interaction methods, potentially improving deployment efficiency for large document collections without sacrificing relevance signal capture. The explicit use of Matryoshka pooling and cross-attention to achieve decoupling is a concrete architectural contribution worth further exploration.
major comments (2)
- [Abstract / Experiments] Abstract and Experiments section: the central SOTA claim on BEIR (and parity with Qwen3-Reranker) is presented without any reported baselines, training data composition, statistical significance tests, error bars, or ablation results, rendering the performance assertions unverifiable from the provided text and undermining assessment of whether the decoupled design actually retains full relevance modeling power.
- [Abstract / Model description] The weakest assumption—that independent Matryoshka-pooled passage encodings plus decoder cross-attention suffice to capture the signals provided by joint query-passage encoding—is stated but not tested via controlled comparisons or failure-case analysis, which is load-bearing for the “not late interaction” claim.
minor comments (1)
- Clarify the precise definition and implementation of “activated parameters” for the three model sizes and how Matryoshka pooling dimensionality is chosen.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the recommendation for major revision. We address each major comment below with specific plans for revision. The responses focus on improving verifiability and providing additional controls while preserving the core contributions of the decoupled encoder-decoder design.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the central SOTA claim on BEIR (and parity with Qwen3-Reranker) is presented without any reported baselines, training data composition, statistical significance tests, error bars, or ablation results, rendering the performance assertions unverifiable from the provided text and undermining assessment of whether the decoupled design actually retains full relevance modeling power.
Authors: We agree that the abstract would benefit from greater specificity to allow immediate assessment of the claims. The full Experiments section contains tables comparing against multiple baselines including the Qwen3-Reranker series, with results on BEIR, MIRACL, and LMEB. To address the concern, we will revise the abstract to list the primary competing models and add a short statement on training data composition. We will also incorporate statistical significance tests, error bars, and a brief reference to ablation results in the Experiments section of the revised manuscript. These changes will make the performance assertions directly verifiable without altering the reported numbers. revision: yes
-
Referee: [Abstract / Model description] The weakest assumption—that independent Matryoshka-pooled passage encodings plus decoder cross-attention suffice to capture the signals provided by joint query-passage encoding—is stated but not tested via controlled comparisons or failure-case analysis, which is load-bearing for the “not late interaction” claim.
Authors: The competitive results across benchmarks provide indirect support that cross-attention recovers the necessary relevance signals, but we acknowledge that a direct controlled comparison would strengthen the argument. We will add an ablation in the revised manuscript that compares the proposed decoupled architecture against a joint encoder-decoder variant (with identical parameter count and training) on a subset of BEIR tasks. This will quantify any performance gap attributable to decoupling. We will also include a short discussion of observed failure modes where the decoupled model underperforms relative to fully joint baselines. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an empirical architecture for a reranker model and reports benchmark results on BEIR, MIRACL, and LMEB. No equations, derivations, or first-principles predictions are present in the provided text. Performance claims rely on external comparisons rather than internal fitting, self-definitions, or self-citation chains that reduce the central claim to its inputs. The design choices (encoder-decoder with Matryoshka pooling and cross-attention) are presented as engineering decisions validated empirically, with no load-bearing steps that collapse by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
jina-embeddings-v5-text: Task-targeted embedding distillation
Mohammad Kalim Akram, Saba Sturua, Nastia Havriushenko, Quentin Herreros, Michael Günther, Maximilian Werk, and Han Xiao. jina-embeddings-v5-text: Task-targeted embedding distillation. 12 arXiv preprint arXiv:2602.15547,
-
[2]
Ms marco: A human generated machine reading comprehension dataset.arXiv preprint arXiv:1611.09268,
Payal Bajaj, Daniel Campos, Nick Craswell, Li Deng, Jianfeng Gao, Xiaodong Liu, Rangan Ma- jumder, Andrew McNamara, Bhaskar Mitra, Tri Nguyen, et al. Ms marco: A human generated machine reading comprehension dataset.arXiv preprint arXiv:1611.09268,
-
[3]
Luiz Bonifacio, Vitor Jeronymo, Hugo Queiroz Abonizio, Israel Campiotti, Marzieh Fadaee, Roberto Lotufo, and Rodrigo Nogueira. mmarco: A multilingual version of the ms marco passage ranking dataset.arXiv preprint arXiv:2108.13897,
-
[4]
Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. Bge m3-embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation.arXiv preprint arXiv:2402.03216, 4(5),
-
[5]
A span-extraction dataset for chinese machine reading comprehension
Yiming Cui, Ting Liu, Wanxiang Che, Li Xiao, Zhipeng Chen, Wentao Ma, Shijin Wang, and Guoping Hu. A span-extraction dataset for chinese machine reading comprehension. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 5883–5889,
2019
-
[6]
Matthew Dunn, Levent Sagun, Mike Higgins, V Ugur Guney, V olkan Cirik, and Kyunghyun Cho. Searchqa: A new q&a dataset augmented with context from a search engine.arXiv preprint arXiv:1704.05179,
-
[7]
Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531,
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531,
-
[8]
Lcsts: A large scale chinese short text summariza- tion dataset
Baotian Hu, Qingcai Chen, and Fangze Zhu. Lcsts: A large scale chinese short text summariza- tion dataset. InProceedings of the 2015 conference on empirical methods in natural language processing, pages 1967–1972,
2015
-
[9]
Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022a
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022a. Xinshuo Hu, Zifei Shan, Xinping Zhao, Zetian Sun, Zhenyu Liu, Dongfang Li, Shaolin Ye, Xinyuan Wei, Qian Chen, Baotian Hu, and Min Zhang. KaLM-Embedding: Superior traini...
-
[10]
Chef: A pilot chinese dataset for evidence-based fact-checking
13 Xuming Hu, Zhijiang Guo, GuanYu Wu, Aiwei Liu, Lijie Wen, and Philip S Yu. Chef: A pilot chinese dataset for evidence-based fact-checking. InProceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 3362–3376, 2022b. Gautier Izacard, Mathilde Caron, Lucas Hossei...
2022
-
[11]
Pubmedqa: A dataset for biomedical research question answering
Qiao Jin, Bhuwan Dhingra, Zhengping Liu, William Cohen, and Xinghua Lu. Pubmedqa: A dataset for biomedical research question answering. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), pages 2567–2577,
2019
-
[12]
Dense passage retrieval for open-domain question answering
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. In Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP), pages 6769–6781,
2020
-
[13]
Gooaq: Open question answering with diverse answer types
Daniel Khashabi, Amos Ng, Tushar Khot, Ashish Sabharwal, Hannaneh Hajishirzi, and Chris Callison-Burch. Gooaq: Open question answering with diverse answer types. InFindings of the Association for Computational Linguistics: EMNLP 2021, pages 421–433,
2021
-
[14]
Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
-
[15]
Nv-embed: Improved techniques for training llms as generalist embedding models
Chankyu Lee, Rajarshi Roy, Mengyao Xu, Jonathan Raiman, Mohammad Shoeybi, Bryan Catanzaro, and Wei Ping. Nv-embed: Improved techniques for training llms as generalist embedding models. InInternational Conference on Learning Representations, volume 2025, pages 79310–79333,
2025
-
[16]
Chaofan Li, Zheng Liu, Shitao Xiao, and Yingxia Shao. Making large language models a better foundation for dense retrieval.arXiv e-prints, pages arXiv–2312, 2023a. Xianming Li, Aamir Shakir, Rui Huang, Tsz-fung Andrew Lee, Julius Lipp, Benjamin Clavié, and Jing Li. Prorank: Prompt warmup via reinforcement learning for small language models reranking. arXi...
-
[17]
Towards general text embeddings with multi-stage contrastive learning.CoRR, abs/2308.03281, 2023b
Zehan Li, Xin Zhang, Yanzhao Zhang, Dingkun Long, Pengjun Xie, and Meishan Zhang. Towards general text embeddings with multi-stage contrastive learning.CoRR, abs/2308.03281, 2023b. Wing Lian, Bleys Goodson, Eugene Pentland, Austin Cook, Chanvichet V ong, and “Teknium”. Openorca: An open dataset of gpt augmented flan reasoning traces.Hugging Face dataset r...
-
[18]
Www’18 open challenge: financial opinion mining and question answering
Macedo Maia, Siegfried Handschuh, André Freitas, Brian Davis, Ross McDermott, Manel Zarrouk, and Alexandra Balahur. Www’18 open challenge: financial opinion mining and question answering. InCompanion proceedings of the the web conference 2018, pages 1941–1942,
2018
-
[19]
Expertqa: Expert-curated questions and attributed answers
Chaitanya Malaviya, Subin Lee, Sihao Chen, Elizabeth Sieber, Mark Yatskar, and Dan Roth. Expertqa: Expert-curated questions and attributed answers. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (V olume 1: Long Papers), pages 3025–3045,
2024
-
[20]
MTEB: massive text embedding benchmark
Niklas Muennighoff, Nouamane Tazi, Loïc Magne, and Nils Reimers. MTEB: massive text embedding benchmark. InEACL, pages 2006–2029. Association for Computational Linguistics,
2006
-
[21]
Webgpt: Browser-assisted question-answering with human feedback.arXiv preprint arXiv:2112.09332,
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, et al. Webgpt: Browser-assisted question-answering with human feedback.arXiv preprint arXiv:2112.09332,
-
[22]
Large dual encoders are generalizable retrievers.arXiv preprint arXiv:2112.07899,
Jianmo Ni, Gustavo Hernández Ábrego, Noah Constant, Ji Ma, Keith Hall, Daniel Cer, and Yinfei Yang. Large dual encoders are generalizable retrievers.arXiv preprint arXiv:2112.07899,
-
[23]
Passage re-ranking with bert.arXiv preprint arXiv:1901.04085,
Rodrigo Nogueira and Kyunghyun Cho. Passage re-ranking with bert.arXiv preprint arXiv:1901.04085,
Pith/arXiv arXiv 1901
-
[24]
Jeffrey Pennington, Richard Socher, and Christopher D Manning
GitHub repository, accessed: 2026-06-17. Jeffrey Pennington, Richard Socher, and Christopher D Manning. Glove: Global vectors for word representation. InProceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pages 1532–1543,
2026
-
[25]
Ronak Pradeep, Sahel Sharifymoghaddam, and Jimmy Lin. Rankvicuna: Zero-shot listwise document reranking with open-source large language models.arXiv preprint arXiv:2309.15088,
-
[26]
Large language models are effective text rankers with pairwise ranking prompting
Zhen Qin, Rolf Jagerman, Kai Hui, Honglei Zhuang, Junru Wu, Le Yan, Jiaming Shen, Tianqi Liu, Jialu Liu, Donald Metzler, et al. Large language models are effective text rankers with pairwise ranking prompting. InFindings of the Association for Computational Linguistics: NAACL 2024, pages 1504–1518,
2024
-
[27]
Squad: 100,000+ questions for machine comprehension of text
15 Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. Squad: 100,000+ questions for machine comprehension of text. InProceedings of the 2016 conference on empirical methods in natural language processing, pages 2383–2392,
2016
-
[28]
Chandan K Reddy, Lluís Màrquez, Fran Valero, Nikhil Rao, Hugo Zaragoza, Sambaran Bandyopad- hyay, Arnab Biswas, Anlu Xing, and Karthik Subbian. Shopping queries dataset: A large-scale esci benchmark for improving product search.arXiv preprint arXiv:2206.06588,
-
[29]
Sentence-bert: Sentence embeddings using siamese bert-networks
Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert-networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing, pages 3982–3992,
2019
-
[30]
Colbertv2: Efficient and effective retrieval via lightweight late interaction
Keshav Santhanam, Omar Khattab, Jon Saad-Falcon, Christopher Potts, and Matei Zaharia. Colbertv2: Efficient and effective retrieval via lightweight late interaction. InProceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 3715–3734,
2022
-
[31]
Drcd: a chinese machine reading comprehension dataset.arXiv preprint arXiv:1806.00920,
Chih Chieh Shao, Trois Liu, Yuting Lai, Yiying Tseng, and Sam Tsai. Drcd: a chinese machine reading comprehension dataset.arXiv preprint arXiv:1806.00920,
-
[32]
Long and diverse text generation with planning-based hierarchical variational model
Zhihong Shao, Minlie Huang, Jiangtao Wen, Wenfei Xu, and Xiaoyan Zhu. Long and diverse text generation with planning-based hierarchical variational model. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3257–3268,
2019
-
[33]
jina-embeddings-v3: Multilingual embeddings with task lora.arXiv preprint arXiv:2409.10173,
Saba Sturua, Isabelle Mohr, Mohammad Kalim Akram, Michael Günther, Bo Wang, Markus Krimmel, Feng Wang, Georgios Mastrapas, Andreas Koukounas, Nan Wang, et al. jina-embeddings-v3: Multilingual embeddings with task lora.arXiv preprint arXiv:2409.10173,
-
[34]
Nandan Thakur, Nils Reimers, Andreas Rücklé, Abhishek Srivastava, and Iryna Gurevych. Beir: A heterogenous benchmark for zero-shot evaluation of information retrieval models.arXiv preprint arXiv:2104.08663,
-
[35]
Fever: a large- scale dataset for fact extraction and verification
James Thorne, Andreas Vlachos, Christos Christodoulopoulos, and Arpit Mittal. Fever: a large- scale dataset for fact extraction and verification. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, V olume 1 (Long Papers), pages 809–819,
2018
-
[36]
Fact or fiction: Verifying scientific claims
David Wadden, Shanchuan Lin, Kyle Lo, Lucy Lu Wang, Madeleine van Zuylen, Arman Cohan, and Hannaneh Hajishirzi. Fact or fiction: Verifying scientific claims. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 7534–7550,
2020
-
[37]
Feng Wang, Yuqing Li, and Han Xiao. Jina-reranker-v3: Last but not late interaction for listwise document reranking.arXiv preprint arXiv:2509.25085,
-
[38]
Text embeddings by weakly-supervised contrastive pre-training.arXiv preprint arXiv:2212.03533,
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, and Furu Wei. Text embeddings by weakly-supervised contrastive pre-training.arXiv preprint arXiv:2212.03533,
-
[39]
Cord-19: The covid-19 open research dataset
Lucy Lu Wang, Kyle Lo, Yoganand Chandrasekhar, Russell Reas, Jiangjiang Yang, Doug Burdick, Darrin Eide, Kathryn Funk, Yannis Katsis, Rodney Michael Kinney, et al. Cord-19: The covid-19 open research dataset. InProceedings of the 1st Workshop on NLP for COVID-19 at ACL 2020,
2020
-
[40]
Refgpt: Dialogue generation of gpt, by gpt, and for gpt
Dongjie Yang, Ruifeng Yuan, Yuantao Fan, Yifei Yang, Zili Wang, Shusen Wang, and Hai Zhao. Refgpt: Dialogue generation of gpt, by gpt, and for gpt. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 2511–2535,
2023
-
[41]
Hotpotqa: A dataset for diverse, explainable multi-hop question answering
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. InProceedings of the 2018 conference on empirical methods in natural language processing, pages 2369–2380,
2018
-
[42]
T5gemma 2: Seeing, reading, and understanding longer.CoRR, abs/2512.14856, 2025a
Biao Zhang, Paul Suganthan, Gaël Liu, Ilya Philippov, Sahil Dua, Ben Hora, Kat Black, Gus Martins, Omar Sanseviero, Shreya Pathak, Cassidy Hardin, Francesco Visin, Jiageng Zhang, Kathleen Kenealy, Qin Yin, Xiaodan Song, Olivier Lacombe, Armand Joulin, Tris Warkentin, and Adam Roberts. T5gemma 2: Seeing, reading, and understanding longer.CoRR, abs/2512.148...
-
[43]
mgte: Generalized long-context text representation and reranking models for multilingual text retrieval
Xin Zhang, Yanzhao Zhang, Dingkun Long, Wen Xie, Ziqi Dai, Jialong Tang, Huan Lin, Baosong Yang, Pengjun Xie, Fei Huang, et al. mgte: Generalized long-context text representation and reranking models for multilingual text retrieval. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track, pages 1393–1412,
2024
-
[44]
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, et al. Qwen3 embedding: Advancing text embedding and reranking through foundation models.arXiv preprint arXiv:2506.05176, 2025c. Ziyin Zhang, Zihan Liao, Hang Yu, Peng Di, and Rui Wang. F2llm-v2: Inclusive, performant, and efficient...
Pith/arXiv arXiv 2024
-
[45]
A Training Data We fine-tune KaLM-Reranker-V1 on retrieval-specific datasets to develop its reranking capability. To improve robustness and generalization, we collect and process large-scale multilingual and multi- domain training data covering diverse retrieval scenarios, such as web search, question answering, 18 Model Params.#LayersHidden Dim. Public M...
2048
-
[46]
The LoRA target modules are q_proj, k_proj, v_proj, and out_proj
B Implementation Details The KaLM-Reranker-V1 series is initialized from the T5Gemma2 encoder–decoder backbone [Zhang et al., 2025a] and trained with LoRA [Hu et al., 2022a], where both the encoder and decoder pa- rameters are fine-tuned. The LoRA target modules are q_proj, k_proj, v_proj, and out_proj. Specif- ically, KaLM-Reranker-V1-Nano, KaLM-Reranker...
2014
-
[47]
C Instruction Templates Tables 9, 10, and 11 summarize the instructions used for evaluation on BEIR, MIRACL, and LMEB, respectively. 6https://huggingface.co/datasets/KaLM-Embedding/KaLM-embedding-finetuning-data 7https://huggingface.co/datasets/Shitao/bge-m3-data 19 Hyperparameter Nano Small Large Training stages 3 3 2 Precision bf16 bf16 bf16 Query max l...
2021
-
[48]
Models Size Cost Avg. ConvoMem LoCoMo LongMemEval MemBench REALTALK TMD First-stage Retriever KaLM-Embedding-V2.5 0.5B – 50.80 62.74 41.88 75.18 69.59 38.60 16.82 Second-stage Reranker Models with more than 4B parameters Qwen3-Reranker-8B 8B 539.7x 66.42 64.64 65.91 78.93 76.31 57.13 55.58 Models with 1B–4B parameters Qwen3-Reranker-4B 4B 236.8x 62.86 66....
arXiv 2024
-
[49]
23 Source Language Size URL KaLM embedding fine-tuning data (retrieval subset) AdvertiseGen [Shao et al., 2019] zh 17,526https://huggingface.co/datasets/shibing624/AdvertiseGenCHEF [Hu et al., 2022b] zh 4,824https://github.com/THU-BPM/CHEFCodeFeedback [Zheng et al., 2024] en 49,090https://huggingface.co/datasets/m-a-p/CodeFeedback-Filtered-InstructionDRCD...
arXiv 2019
-
[50]
“CR” denotes the compression ratio, where a larger value indicates more compressed passage representations. Cost denotes the estimated relative online computation cost derived from the time complexity analysis in §5.1, using |q|= 32 , n= 1024 , K= 1 , and the corresponding compression ratior, withLanddobtained from Table 1, and normalized toNanoatr= 32as ...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.