A Dual-Path Architecture for Scaling Compute and Capacity in LLMs
Pith reviewed 2026-06-29 07:40 UTC · model grok-4.3
The pith
A dual-path layer in transformers combines repeated deep computation with one wide step, outperforming iso-FLOP models while using fewer parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
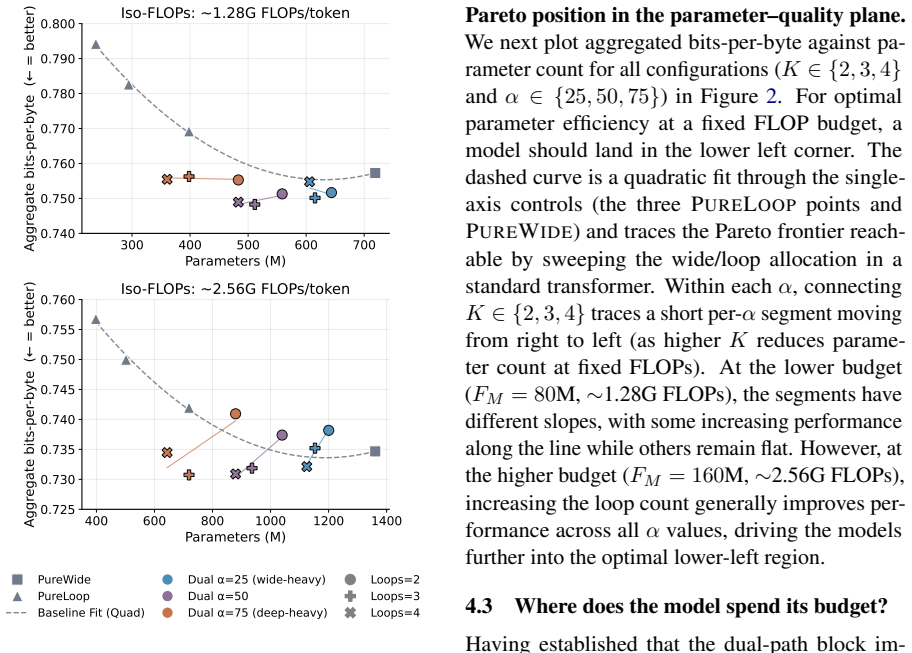
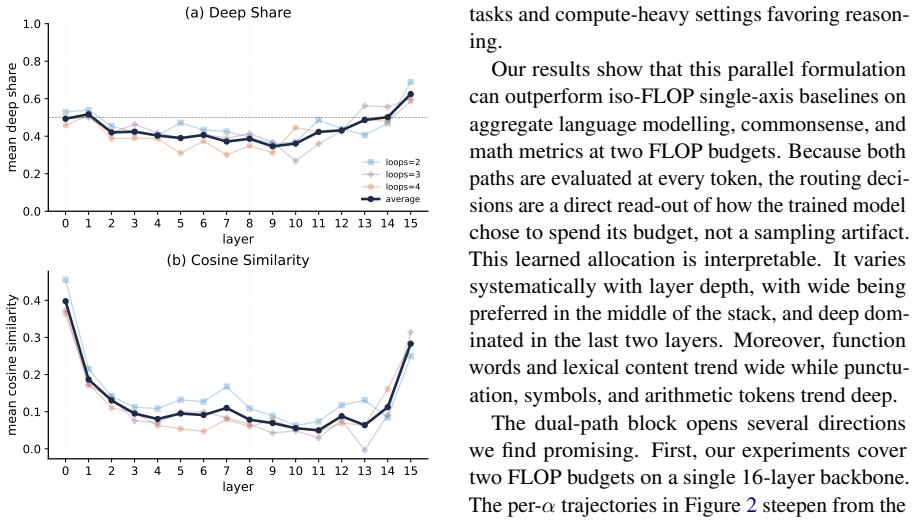
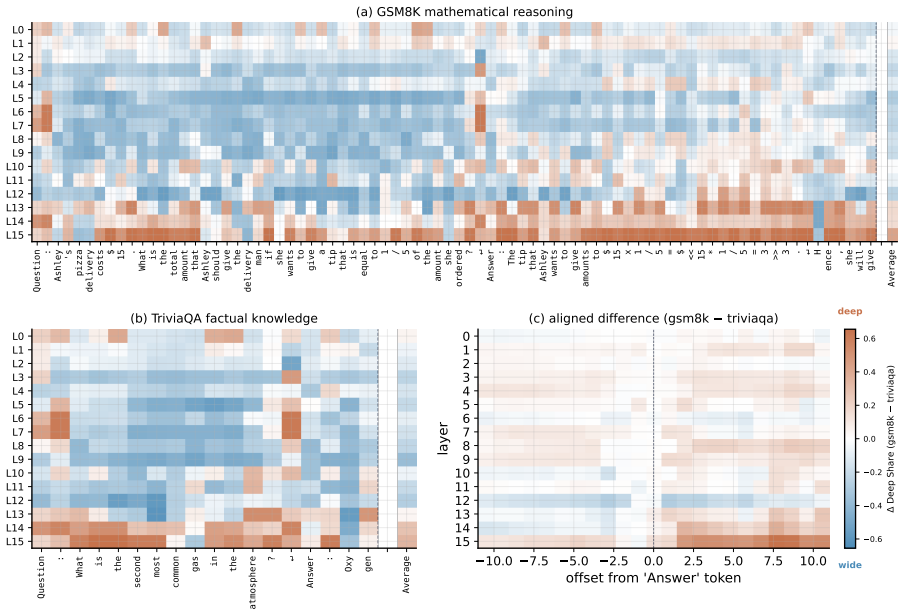
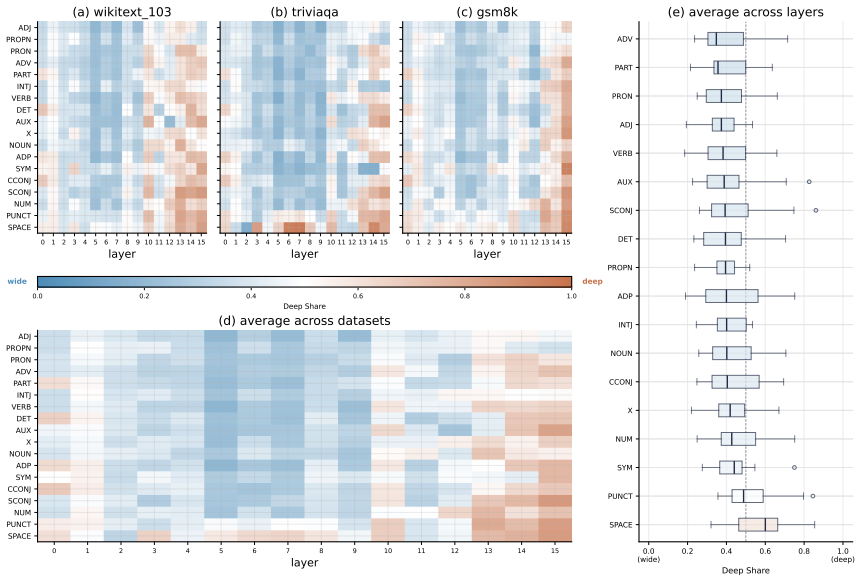
The dual-path architecture surpasses iso-FLOP matched models on language modeling and downstream evaluations while using fewer parameters than the baseline at matched FLOPs, with learned gates showing systematic per-token allocation where function words and lexical content trend wide and punctuation, symbols, and arithmetic tokens trend deep.
What carries the argument
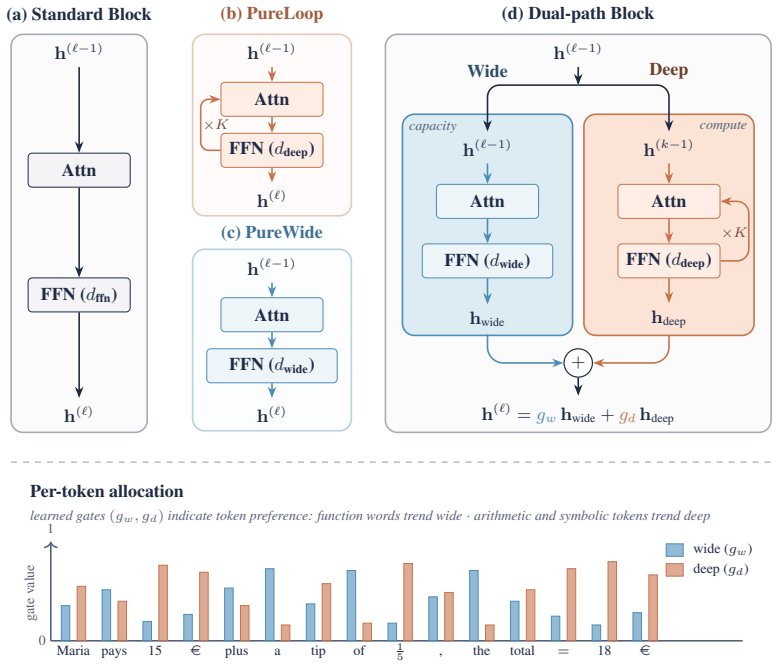
The dual-path block, which exposes compute and capacity as parallel pathways within a single layer: a deep sublayer re-applied K times with shared parameters and a wide sublayer with an enlarged feed-forward network applied once, combined by independent per-token gates.
If this is right
- Surpasses iso-FLOP matched models on language modeling evaluations.
- Surpasses iso-FLOP matched models on downstream evaluations.
- Uses fewer parameters than the baseline at matched FLOPs.
- The learned gates provide direct interpretability of per-token routing decisions.
Where Pith is reading between the lines
- Such routing could be extended to decide compute allocation dynamically during inference for efficiency gains.
- Patterns in token routing might generalize across different model scales or training data.
- The approach could inspire similar dual axes in other architectures like vision or multimodal models.
Load-bearing premise
That the per-token gates can be trained stably to allocate between the deep and wide paths in a way that delivers net performance gains without the model defaulting to one path or requiring extra regularization that cancels the efficiency benefit.
What would settle it
Training runs where the gates fail to learn meaningful allocations, causing the model to perform no better than or worse than a standard transformer at the same FLOPs, would falsify the claim.
Figures


read the original abstract
Looped transformers apply a shared block multiple times and have emerged as a parameter-efficient route to scaling compute in language models. However, at fixed FLOPs a looped model has strictly less capacity than a baseline transformer. We propose a novel dual-path block that can flexibly scale compute, the number of sequential operations applied to a hidden state, and capacity, the parameters available at a single step. For this we expose both axes as parallel pathways within a single layer: a deep sublayer re-applied K times with shared parameters, and a wide sublayer with an enlarged feed-forward network applied once. Independent per-token gates combine both axes and allow detailed per-token routing analyses. We show that across two FLOP budgets, our dual-path model surpasses iso-FLOP matched models on language modeling and downstream evaluations, while using fewer parameters than the baseline at matched FLOPs. The learned gates are directly interpretable and show systematic per-token allocation with function words and lexical content trend wide, while punctuation, symbols, and arithmetic tokens trend deep.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a dual-path transformer block that exposes compute (via a shared-parameter deep loop applied K times) and capacity (via a single enlarged FFN) as parallel pathways within one layer, combined by independent per-token gates. It claims that across two FLOP budgets the resulting model outperforms iso-FLOP-matched standard transformers on language-modeling and downstream tasks while using fewer parameters than the baseline, and that the learned gates exhibit systematic, interpretable per-token allocation (function words and lexical content routed wide; punctuation, symbols, and arithmetic tokens routed deep).
Significance. If the empirical claims hold, the architecture supplies a concrete mechanism for jointly scaling depth and width on a per-token basis, addressing the capacity deficit of pure looped transformers at fixed FLOPs. The direct interpretability of the gates is a genuine strength, offering a falsifiable window into routing behavior that could inform future routing designs. No machine-checked proofs or parameter-free derivations are present, but the per-token routing analysis constitutes a reproducible empirical contribution if the underlying training runs and gate statistics are released.
major comments (1)
- [Abstract / Experiments] The central claim that the dual-path model delivers net gains at matched FLOPs with fewer parameters rests on the assumption that the per-token gates allocate tokens stably between the deep loop and wide FFN without collapse or the need for auxiliary losses whose cost offsets the efficiency benefit. The abstract reports systematic trends but supplies no ablations on gate entropy, path-collapse frequency, or regularization variants; without these, it is impossible to verify that the observed gains are not an artifact of the training procedure defaulting to one path.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract / Experiments] The central claim that the dual-path model delivers net gains at matched FLOPs with fewer parameters rests on the assumption that the per-token gates allocate tokens stably between the deep loop and wide FFN without collapse or the need for auxiliary losses whose cost offsets the efficiency benefit. The abstract reports systematic trends but supplies no ablations on gate entropy, path-collapse frequency, or regularization variants; without these, it is impossible to verify that the observed gains are not an artifact of the training procedure defaulting to one path.
Authors: The manuscript already supplies direct evidence against path collapse via the per-token routing analysis, which shows consistent, token-type-specific allocation (function words and lexical content routed wide; punctuation, symbols, and arithmetic tokens routed deep). These systematic, interpretable patterns are incompatible with uniform defaulting to a single path. We agree, however, that the paper does not contain explicit ablations on gate entropy, collapse frequency across runs, or regularization variants. We will add these analyses in the revised version to further substantiate training stability. revision: yes
Circularity Check
No derivation chain; purely empirical claims
full rationale
The paper reports experimental results on language modeling and downstream tasks for a dual-path architecture, with no equations, first-principles derivations, or predictions that could reduce to inputs by construction. Claims rest on observed performance at matched FLOPs and gate interpretability trends, which are falsifiable via external benchmarks rather than self-referential. No self-citation load-bearing steps or fitted inputs presented as predictions appear in the provided text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation
Mixture-of-recursions: Learning dynamic re- cursive depths for adaptive token-level computation. arXiv preprint arXiv:2507.10524. Andrea Banino, Jan Balaguer, and Charles Blundell
-
[2]
Pondernet: Learning to ponder.arXiv preprint arXiv:2107.05407. Mostafa Dehghani, Josip Djolonga, Basil Mustafa, Pi- otr Padlewski, Jonathan Heek, Justin Gilmer, An- dreas Peter Steiner, Mathilde Caron, Robert Geirhos, Ibrahim Alabdulmohsin, and 1 others. 2023. Scaling 8 vision transformers to 22 billion parameters. InIn- ternational Conference on Machine ...
-
[3]
Jonas Geiping, Sean McLeish, Neel Jain, John Kirchen- bauer, Siddharth Singh, Brian R Bartoldson, Bhavya Kailkhura, Abhinav Bhatele, and Tom Goldstein
Adaptive loops and memory in transformers: Think harder or know more? InLatent & Implicit Thinking Workshop @ ICLR. Jonas Geiping, Sean McLeish, Neel Jain, John Kirchen- bauer, Siddharth Singh, Brian R Bartoldson, Bhavya Kailkhura, Abhinav Bhatele, and Tom Goldstein
-
[4]
Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach
Scaling up test-time compute with latent rea- soning: A recurrent depth approach.arXiv preprint arXiv:2502.05171. Alex Graves. 2016. Adaptive computation time for recurrent neural networks.arXiv preprint arXiv:1603.08983. Yuling Gu, Oyvind Tafjord, Bailey Kuehl, Dany Had- dad, Jesse Dodge, and Hannaneh Hajishirzi. 2025. Olmes: A standard for language mode...
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[5]
arXiv preprint arXiv:2602.11451
Loopformer: Elastic-depth looped transform- ers for latent reasoning via shortcut modulation. arXiv preprint arXiv:2602.11451. Guillaume Lample, Alexandre Sablayrolles, Marc’Aurelio Ranzato, Ludovic Denoyer, and Hervé Jégou. 2019. Large memory layers with product keys.Advances in Neural Information Processing Systems, 32. Max Lübbering, Timm Ruland, Richa...
-
[6]
Mixture-of-Depths: Dynamically allocating compute in transformer-based language models
Universal dependencies v1: A multilingual treebank collection. InProceedings of the Tenth In- ternational Conference on Language Resources and Evaluation (LREC’16), pages 1659–1666. Slav Petrov, Dipanjan Das, and Ryan McDonald. 2012. A universal part-of-speech tagset. InProceedings of the Eighth International Conference on Language Resources and Evaluatio...
work page internal anchor Pith review Pith/arXiv arXiv 2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.