Zero-Shot Learning in Industrial Scenarios: New Large-Scale Benchmark, Challenges and Baseline
Pith reviewed 2026-06-27 20:00 UTC · model grok-4.3
The pith
A new industrial dataset and refined prompt method let large visual language models detect manufacturing defects without training examples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
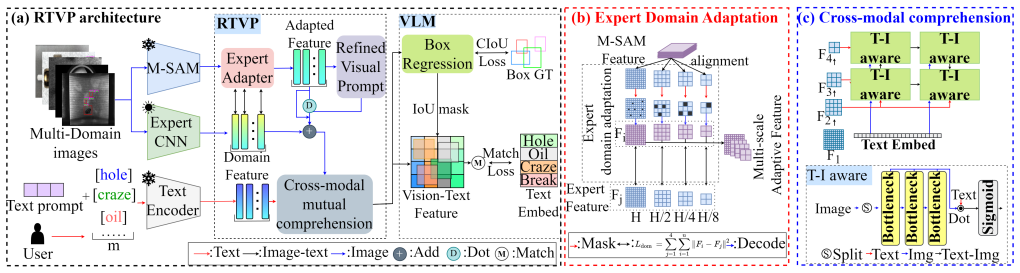
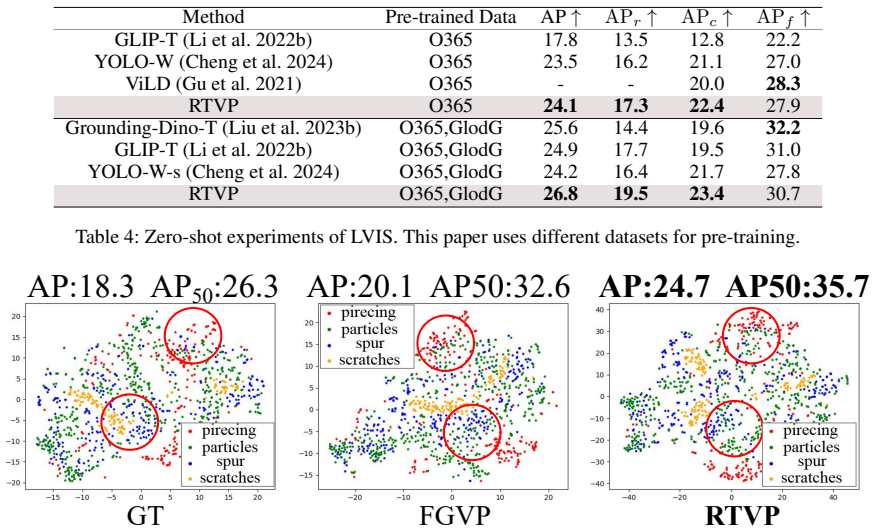
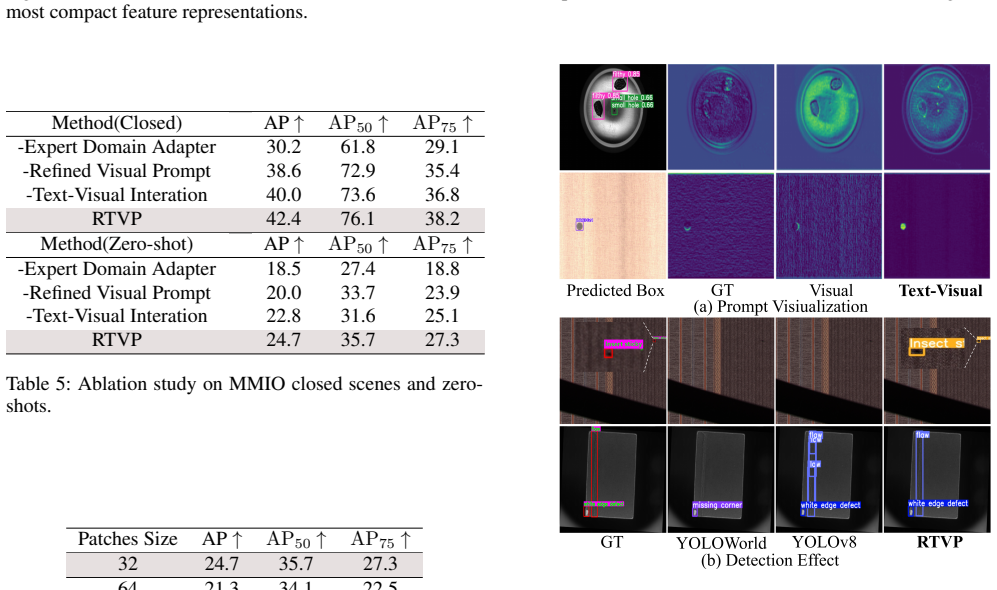
The paper constructs the Multi-Modal Industrial Open Dataset (MMIO) containing 80K+ samples across 6 super categories and 18 subcategories as the first large-scale multi-scenes pre-training dataset for industrial zero-shot learning, and proposes the Refined Text-Visual Prompt (RTVP) method that uses expert-guided large model domain adaptation on Mobile-SAM together with automatic visual prompt generation from images that accounts for text-visual prompt interactions, achieving state-of-the-art 42.2 percent AP in zero-shot scenes and 24.7 percent AP in closed scenes on MMIO.
What carries the argument
Refined Text-Visual Prompt (RTVP), which performs expert-guided domain adaptation of large models using Mobile-SAM and generates visual prompts directly from images while modeling their interactions with text prompts.
If this is right
- MMIO supplies pre-training data that future open models can use for industrial zero-shot tasks.
- Expert-guided domain adaptation improves generalization of large models to manufacturing scenes.
- Automatic visual prompt generation and text-visual interaction modeling raises understanding of both visual and textual content.
- Zero-shot defect detection becomes practical in data-scarce industrial environments.
Where Pith is reading between the lines
- Automated quality control lines could handle entirely new product types by relying on the initial expert guidance rather than repeated labeling campaigns.
- The same adaptation pattern might apply to other narrow domains such as medical or satellite imagery where general models encounter large scene shifts.
- Repeated use of the expert-guided step could gradually reduce the amount of human input required as the model accumulates industrial examples.
Load-bearing premise
The MMIO dataset accurately represents real industrial scenarios and the expert-guided domain adaptation plus text-visual prompt interactions generalize beyond the tested categories without overfitting or bias.
What would settle it
Testing the RTVP method on a new collection of factory images from product categories absent from MMIO and finding that its average precision falls below that of standard large visual language model prompting without any adaptation.
Figures


read the original abstract
Large Visual Language Models (LVLMs) have achieved remarkable success in vision tasks. However, the significant differences between industrial and natural scenes make applying LVLMs challenging. Existing LVLMs rely on user-provided prompts to segment objects. This often leads to suboptimal performance due to the inclusion of irrelevant pixels. In addition, the scarcity of data also makes the application of LVLMs in industrial scenarios remain unexplored. To fill this gap, this paper proposes an open industrial dataset and a Refined Text-Visual Prompt (RTVP) for zero-shot industrial defect detection. First, this paper constructs the Multi-Modal Industrial Open Dataset (MMIO) containing 80K+ samples. MMIO contains diverse industrial categories, including 6 super categories and 18 subcategories. MMIO is the first large-scale multi-scenes pre-training dataset for industrial zero-shot learning, and provides valuable training data for open models in future industrial scenarios. Based on MMIO, this paper provides a RTVP specifically for industrial zero-shot tasks. RTVP has two significant advantages: First, this paper designs an expert-guided large model domain adaptation mechanism and designs an industrial zero-shot method based on Mobile-SAM, which enhances the generalization ability of large models in industrial scenarios. Second, RTVP automatically generates visual prompts directly from images and considers text-visual prompt interactions ignored by previous LVLM, improving visual and textual content understanding. RTVP achieves SOTA with 42.2% and 24.7% AP in zero-shot and closed scenes of MMIO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Multi-Modal Industrial Open Dataset (MMIO) containing over 80K samples across 6 super-categories and 18 sub-categories as the first large-scale multi-scene pre-training resource for industrial zero-shot learning. It proposes the Refined Text-Visual Prompt (RTVP) method that performs expert-guided domain adaptation of Mobile-SAM and automatically generates visual prompts while modeling text-visual prompt interactions. The central empirical claim is that RTVP attains state-of-the-art performance of 42.2% AP (zero-shot scenes) and 24.7% AP (closed scenes) on MMIO.
Significance. If the performance numbers are substantiated by a fully specified evaluation protocol, the MMIO benchmark would constitute a useful public resource for studying domain shift between natural and industrial imagery. The RTVP pipeline's emphasis on automatic prompt generation and domain adaptation supplies a concrete baseline that future industrial zero-shot work can compare against. The work also highlights a practically relevant setting where standard LVLM prompting fails due to irrelevant pixels and data scarcity.
major comments (2)
- [Abstract] Abstract: the reported SOTA figures of 42.2% and 24.7% AP are presented without any description of the evaluation protocol, the precise data splits used for zero-shot versus closed scenes, the set of baselines against which superiority is claimed, or any statistical significance testing. Because these numbers constitute the sole quantitative support for the central claim, the absence of this information is load-bearing.
- [Methods / Results] Methods / Results sections (inferred from abstract): the expert-guided domain-adaptation step on Mobile-SAM and the automatic text-visual prompt generation procedure are described at a high level only; no pseudocode, hyper-parameter values, or ablation isolating the contribution of each component is supplied. This prevents assessment of whether the reported gains are reproducible or attributable to the proposed mechanisms rather than implementation details.
minor comments (2)
- [Abstract] The abstract states that MMIO 'provides valuable training data for open models' but does not clarify whether the dataset is released under an open license or what annotation protocol was followed for the defect labels.
- Notation for the two scenes (zero-shot vs. closed) is used without an explicit definition of what constitutes a 'closed scene' versus a 'zero-shot scene' in the industrial context.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which correctly identifies gaps in transparency that affect the strength of our central claims. We address each major comment below and will incorporate revisions to improve clarity and reproducibility.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported SOTA figures of 42.2% and 24.7% AP are presented without any description of the evaluation protocol, the precise data splits used for zero-shot versus closed scenes, the set of baselines against which superiority is claimed, or any statistical significance testing. Because these numbers constitute the sole quantitative support for the central claim, the absence of this information is load-bearing.
Authors: We agree that the abstract lacks these critical details. In the revised manuscript we will expand the abstract to include a concise description of the evaluation protocol, the exact train/test splits distinguishing zero-shot versus closed scenes on MMIO, the primary baselines used for comparison, and a note on statistical significance testing of the reported AP gains. Full protocol specifications will also be made more explicit in the Experiments section. revision: yes
-
Referee: [Methods / Results] Methods / Results sections (inferred from abstract): the expert-guided domain-adaptation step on Mobile-SAM and the automatic text-visual prompt generation procedure are described at a high level only; no pseudocode, hyper-parameter values, or ablation isolating the contribution of each component is supplied. This prevents assessment of whether the reported gains are reproducible or attributable to the proposed mechanisms rather than implementation details.
Authors: We acknowledge the current description is high-level. The revised manuscript will add (1) pseudocode for the full RTVP pipeline including the expert-guided domain adaptation and automatic visual prompt generation, (2) the specific hyper-parameter values employed, and (3) additional ablation experiments that isolate the contribution of domain adaptation versus text-visual prompt interaction. These changes will appear in the Methods and Experiments sections. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents an empirical contribution: construction of the MMIO dataset (80K+ samples across industrial categories) and the RTVP method (expert-guided domain adaptation on Mobile-SAM plus automatic text-visual prompt generation). Performance is reported as measured AP metrics (42.2% zero-shot, 24.7% closed) on the new benchmark. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claims rest on dataset construction and experimental results rather than any reduction of outputs to inputs by definition or construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Large visual language models can be effectively adapted to industrial domains through expert-guided domain adaptation and refined text-visual prompts.
- domain assumption The constructed MMIO dataset is representative of diverse industrial scenarios for zero-shot learning evaluation.
Reference graph
Works this paper leans on
-
[1]
IEEE Transactions on Industry Applications , volume=
Automated surface defect detection in metals: a comparative review of object detection and semantic segmentation using deep learning , author=. IEEE Transactions on Industry Applications , volume=. 2022 , publisher=
2022
-
[2]
2019 2nd China Symposium on Cognitive Computing and Hybrid Intelligence (CCHI) , pages=
Surface defect detection of solar cells based on feature pyramid network and GA-faster-RCNN , author=. 2019 2nd China Symposium on Cognitive Computing and Hybrid Intelligence (CCHI) , pages=. 2019 , organization=
2019
-
[3]
IEEE Transactions on Instrumentation and Measurement , volume=
RetinaNet with difference channel attention and adaptively spatial feature fusion for steel surface defect detection , author=. IEEE Transactions on Instrumentation and Measurement , volume=. 2020 , publisher=
2020
-
[4]
IEEE Transactions on Instrumentation and Measurement , volume=
Efficient fused-attention model for steel surface defect detection , author=. IEEE Transactions on Instrumentation and Measurement , volume=. 2022 , publisher=
2022
-
[5]
2021 6th International Conference on Robotics and Automation Engineering (ICRAE) , pages=
A Highly Efficient Surface Defect Detection Approach for Hot Rolled Strip Steel Based on Deep Learning , author=. 2021 6th International Conference on Robotics and Automation Engineering (ICRAE) , pages=. 2021 , organization=
2021
-
[6]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
You only look once: Unified, real-time object detection , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[7]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
YOLO9000: Better, Faster, Stronger , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[8]
arXiv preprint arXiv:1804.02767 , year=
YOLOv3: An Incremental Improvement , author=. arXiv preprint arXiv:1804.02767 , year=
-
[9]
arXiv preprint arXiv:2004.10934 , year=
YOLOv4: Optimal Speed and Accuracy of Object Detection , author=. arXiv preprint arXiv:2004.10934 , year=
Pith/arXiv arXiv 2004
-
[10]
[Online]
YOLOv5 , author=. [Online]. Available: https://github.com/ultralytics/yolov5 , year=
-
[11]
arXiv preprint arXiv:2107.08430 , year=
YOLOX: Exceeding YOLO Series in 2021 , author=. arXiv preprint arXiv:2107.08430 , year=
Pith/arXiv arXiv 2021
-
[12]
2020 Chinese Automation Congress (CAC) , year=
Accurate Object Detection with Relation Module on Improved R-FCN , author=. 2020 Chinese Automation Congress (CAC) , year=
2020
-
[13]
Twelfth International Conference on Digital Image Processing , year=
Real-time object detection based on R-FCN network under structured scene of high-speed railway , author=. Twelfth International Conference on Digital Image Processing , year=
-
[14]
Radar & ECM , year=
A target detection method based on FCN model and selective search , author=. Radar & ECM , year=
-
[15]
Information Sciences , volume=
LGCNet: A local-to-global context-aware feature augmentation network for salient object detection , author=. Information Sciences , volume=
-
[16]
ACM , year=
UnitBox: An Advanced Object Detection Network , author=. ACM , year=
-
[17]
2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Generalized Intersection Over Union: A Metric and a Loss for Bounding Box Regression , author=. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
2019
-
[18]
Proceedings of the AAAI conference on artificial intelligence , volume=
Distance-IoU loss: Faster and better learning for bounding box regression , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[19]
Neurocomputing , volume=
Focal and efficient IOU loss for accurate bounding box regression , author=. Neurocomputing , volume=. 2022 , publisher=
2022
-
[20]
arXiv 2021 , author=
Alpha-IoU: A family of power intersection over union losses for bounding box regression. arXiv 2021 , author=. 2023 , journal=
2021
-
[21]
arXiv preprint arXiv:2205.12740 , year=
SIoU loss: More powerful learning for bounding box regression , author=. arXiv preprint arXiv:2205.12740 , year=
-
[22]
IEEE Transactions on Intelligent Transportation Systems , volume=
An efficient hardware implementation of HOG feature extraction for human detection , author=. IEEE Transactions on Intelligent Transportation Systems , volume=. 2013 , publisher=
2013
-
[23]
Signal processing , volume=
Efficient HOG human detection , author=. Signal processing , volume=. 2011 , publisher=
2011
-
[24]
arXiv preprint arXiv:2209.02976 , year=
YOLOv6: A single-stage object detection framework for industrial applications , author=. arXiv preprint arXiv:2209.02976 , year=
-
[25]
Advances in neural information processing systems , volume=
Faster r-cnn: Towards real-time object detection with region proposal networks , author=. Advances in neural information processing systems , volume=
-
[26]
arXiv preprint arXiv:2105.04206 , year=
You only learn one representation: Unified network for multiple tasks , author=. arXiv preprint arXiv:2105.04206 , year=
-
[27]
International Conference on Computer Vision , year=
Mask R-CNN , author=. International Conference on Computer Vision , year=
-
[28]
Proceedings of the IEEE International Conference on Computer Vision (ICCV) , month =
Lin, Tsung-Yi and Goyal, Priya and Girshick, Ross and He, Kaiming and Dollar, Piotr , title =. Proceedings of the IEEE International Conference on Computer Vision (ICCV) , month =
-
[29]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Efficientdet: Scalable and efficient object detection , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[30]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Deep residual learning for image recognition , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[31]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Xie, Saining and Girshick, Ross and Dollar, Piotr and Tu, Zhuowen and He, Kaiming , title =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[32]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
A convnet for the 2020s , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[33]
Convolutional Neural Networks with Swift for Tensorflow: Image Recognition and Dataset Categorization , pages=
EfficientNet , author=. Convolutional Neural Networks with Swift for Tensorflow: Image Recognition and Dataset Categorization , pages=. 2021 , publisher=
2021
-
[34]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Swin transformer: Hierarchical vision transformer using shifted windows , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[35]
arXiv preprint arXiv:1704.04861 , year=
Mobilenets: Efficient convolutional neural networks for mobile vision applications , author=. arXiv preprint arXiv:1704.04861 , year=
-
[36]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Liu, Shu and Qi, Lu and Qin, Haifang and Shi, Jianping and Jia, Jiaya , title =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[37]
, title =
Ghiasi, Golnaz and Lin, Tsung-Yi and Le, Quoc V. , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[38]
Multi-scale Feature Extraction and Fusion for Online Knowledge Distillation , Booktitle =
Zou, Panpan and Teng, Yinglei and Niu, Tao , Editor =. Multi-scale Feature Extraction and Fusion for Online Knowledge Distillation , Booktitle =. 2022 , Volume =. doi:10.1007/978-3-031-15937-4\_11 , ISSN =
-
[39]
IEEE TRANSACTIONS ON INSTRUMENTATION AND MEASUREMENT , Year =
Bao, Yanqi and Song, Kechen and Liu, Jie and Wang, Yanyan and Yan, Yunhui and Yu, Han and Li, Xingjie , Title =. IEEE TRANSACTIONS ON INSTRUMENTATION AND MEASUREMENT , Year =. doi:10.1109/TIM.2021.3083561 , ISSN =
-
[40]
Microsoft coco: Common objects in context,
Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Dollar, Piotr and Zitnick, C. Lawrence , Editor =. Microsoft COCO: Common Objects in Context , Booktitle =. 2014 , Volume =. doi:10.1007/978-3-319-10602-1\_48 , ISSN =
-
[41]
Global Attention Mechanism: Retain Information to Enhance Channel-Spatial Interactions , publisher =
Liu, Yichao and Shao, Zongru and Hoffmann, Nico , keywords =. Global Attention Mechanism: Retain Information to Enhance Channel-Spatial Interactions , publisher =. 2021 , copyright =. doi:10.48550/ARXIV.2112.05561 , url =
-
[42]
NAM: Normalization-based Attention Module , publisher =
Liu, Yichao and Shao, Zongru and Teng, Yueyang and Hoffmann, Nico , keywords =. NAM: Normalization-based Attention Module , publisher =. 2021 , copyright =. doi:10.48550/ARXIV.2111.12419 , url =
-
[43]
PP-YOLOE: An evolved version of YOLO , publisher =
Xu, Shangliang and Wang, Xinxin and Lv, Wenyu and Chang, Qinyao and Cui, Cheng and Deng, Kaipeng and Wang, Guanzhong and Dang, Qingqing and Wei, Shengyu and Du, Yuning and Lai, Baohua , keywords =. PP-YOLOE: An evolved version of YOLO , publisher =. 2022 , copyright =. doi:10.48550/ARXIV.2203.16250 , url =
-
[44]
Information Sciences , volume=
D4Net: De-deformation defect detection network for non-rigid products with large patterns , author=. Information Sciences , volume=. 2021 , publisher=
2021
-
[45]
F1000Research , VOLUME =
Kodytek, P and Bodzas, A and Bilik, P , TITLE =. F1000Research , VOLUME =. 2022 , NUMBER =
2022
-
[46]
Computers in Industry , volume=
Cas-VSwin transformer: A variant swin transformer for surface-defect detection , author=. Computers in Industry , volume=. 2022 , publisher=
2022
-
[47]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Towards scalable multi-domain conversational agents: The schema-guided dialogue dataset , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[48]
arXiv preprint arXiv:2207.02696 , year=
YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors , author=. arXiv preprint arXiv:2207.02696 , year=
-
[49]
arXiv preprint arXiv:2111.00902 , year=
PP-PicoDet: A better real-time object detector on mobile devices , author=. arXiv preprint arXiv:2111.00902 , year=
-
[50]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Centernet: Keypoint triplets for object detection , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[51]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
D2det: Towards high quality object detection and instance segmentation , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[52]
arXiv preprint arXiv:1701.06659 , year=
Dssd: Deconvolutional single shot detector , author=. arXiv preprint arXiv:1701.06659 , year=
-
[53]
An Adaptive Image Segmentation Network for Surface Defect Detection , year=
Liu, Taiheng and He, Zhaoshui and Lin, Zhijie and Cao, Guang-Zhong and Su, Wenqing and Xie, Shengli , journal=. An Adaptive Image Segmentation Network for Surface Defect Detection , year=
-
[54]
EEE-Net: Efficient Edge Enhanced Network for Surface Defect Detection of Glass , year=
Chen, Yongqi and Pan, Jiawei and Lei, Jiayu and Zeng, Deyu and Wu, Zongze and Chen, Changsheng , journal=. EEE-Net: Efficient Edge Enhanced Network for Surface Defect Detection of Glass , year=
-
[55]
International journal of computer vision , volume=
LabelMe: a database and web-based tool for image annotation , author=. International journal of computer vision , volume=. 2008 , publisher=
2008
-
[56]
FDSNeT: An Accurate Real-Time Surface Defect Segmentation Network , year=
Zhang, Jian and Ding, Runwei and Ban, Miaoju and Guo, Tianyu , booktitle=. FDSNeT: An Accurate Real-Time Surface Defect Segmentation Network , year=
-
[57]
MVTec AD — A Comprehensive Real-World Dataset for Unsupervised Anomaly Detection , year=
Bergmann, Paul and Fauser, Michael and Sattlegger, David and Steger, Carsten , booktitle=. MVTec AD — A Comprehensive Real-World Dataset for Unsupervised Anomaly Detection , year=
-
[58]
Computers in Industry , number=
Cas-VSwin transformer: A variant swin transformer for surface-defect detection , author=. Computers in Industry , number=
-
[59]
International journal of intelligent systems , year=
RDAD: A reconstructive and discriminative anomaly detection model based on transformer , author=. International journal of intelligent systems , year=
-
[60]
TransCut: Transparent Object Segmentation from a Light-Field Image , year=
Xu, Yichao and Nagahara, Hajime and Shimada, Atsushi and Taniguchi, Rin-ichiro , booktitle=. TransCut: Transparent Object Segmentation from a Light-Field Image , year=
-
[61]
, booktitle=
Chen, Guanying and Han, Kai and Wong, Kwan-Yee K. , booktitle=. TOM-Net: Learning Transparent Object Matting from a Single Image , year=
-
[62]
Glass Segmentation With RGB-Thermal Image Pairs , year=
Huo, Dong and Wang, Jian and Qian, Yiming and Yang, Yee-Hong , journal=. Glass Segmentation With RGB-Thermal Image Pairs , year=
-
[63]
Wang, Wenguan and Zhao, Shuyang and Shen, Jianbing and Hoi, Steven C. H. and Borji, Ali , booktitle=. Salient Object Detection With Pyramid Attention and Salient Edges , year=
-
[64]
EGNet: Edge Guidance Network for Salient Object Detection , year=
Zhao, Jiaxing and Liu, Jiang-Jiang and Fan, Deng-Ping and Cao, Yang and Yang, Jufeng and Cheng, Ming-Ming , booktitle=. EGNet: Edge Guidance Network for Salient Object Detection , year=
-
[65]
Enhanced Boundary Learning for Glass-like Object Segmentation , year=
He, Hao and Li, Xiangtai and Cheng, Guangliang and Shi, Jianping and Tong, Yunhai and Meng, Gaofeng and Prinet, Véronique and Weng, LuBin , booktitle=. Enhanced Boundary Learning for Glass-like Object Segmentation , year=
-
[66]
https://tianchi.aliyun.com/dataset/110147 , year=
Alibaba , title=. https://tianchi.aliyun.com/dataset/110147 , year=
-
[67]
SSGD: A Smartphone Screen Glass Dataset for Defect Detection , year=
Han, Haonan and Yang, Rui and Li, Shuyan and Hu, Runze and Li, Xiu , booktitle=. SSGD: A Smartphone Screen Glass Dataset for Defect Detection , year=
-
[68]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
MobileOne: An Improved One Millisecond Mobile Backbone , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[69]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Metaformer is actually what you need for vision , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[70]
Advances in Neural Information Processing Systems , volume=
Efficientformer: Vision transformers at mobilenet speed , author=. Advances in Neural Information Processing Systems , volume=
-
[71]
Advances in Neural Information Processing Systems , volume=
Twins: Revisiting the design of spatial attention in vision transformers , author=. Advances in Neural Information Processing Systems , volume=
-
[72]
2022 International Conference on Computers and Artificial Intelligence Technologies (CAIT) , pages=
Conv2NeXt: Reconsidering Conv NeXt Network Design for Image Recognition , author=. 2022 International Conference on Computers and Artificial Intelligence Technologies (CAIT) , pages=. 2022 , organization=
2022
-
[73]
2023 , eprint=
ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders , author=. 2023 , eprint=
2023
-
[74]
and Lo, Wan-Yen and Dollar, Piotr and Girshick, Ross , title =
Kirillov, Alexander and Mintun, Eric and Ravi, Nikhila and Mao, Hanzi and Rolland, Chloe and Gustafson, Laura and Xiao, Tete and Whitehead, Spencer and Berg, Alexander C. and Lo, Wan-Yen and Dollar, Piotr and Girshick, Ross , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =. 2023 , pages =
2023
-
[75]
2023 , eprint=
Fast Segment Anything , author=. 2023 , eprint=
2023
-
[76]
arXiv preprint arXiv:2306.14289 , year=
Faster segment anything: Towards lightweight sam for mobile applications , author=. arXiv preprint arXiv:2306.14289 , year=
-
[77]
arXiv preprint arXiv:2305.13310 , year=
Matcher: Segment anything with one shot using all-purpose feature matching , author=. arXiv preprint arXiv:2305.13310 , year=
-
[78]
arXiv preprint arXiv:2305.03048 , year=
Personalize segment anything model with one shot , author=. arXiv preprint arXiv:2305.03048 , year=
-
[79]
AI Open , volume=
Cpt: Colorful prompt tuning for pre-trained vision-language models , author=. AI Open , volume=. 2024 , publisher=
2024
-
[80]
arXiv preprint arXiv:2204.05991 , year=
Reclip: A strong zero-shot baseline for referring expression comprehension , author=. arXiv preprint arXiv:2204.05991 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.