GRADE: Graph Representation of LLM Agent Dependency and Execution
Pith reviewed 2026-06-26 09:42 UTC · model grok-4.3
The pith
GRADE models any LLM agent run as one graph whose graded dependency edges predict failure independently of run size and transfer across task types.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
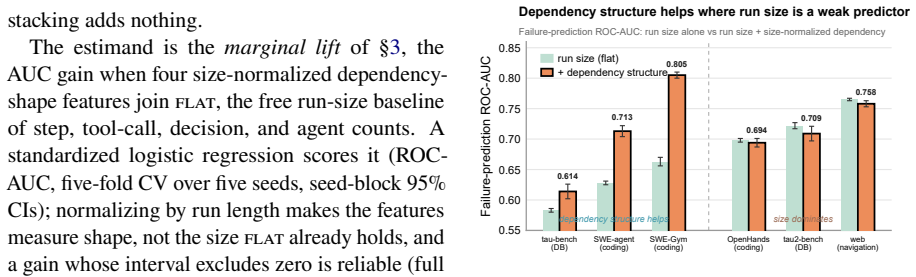
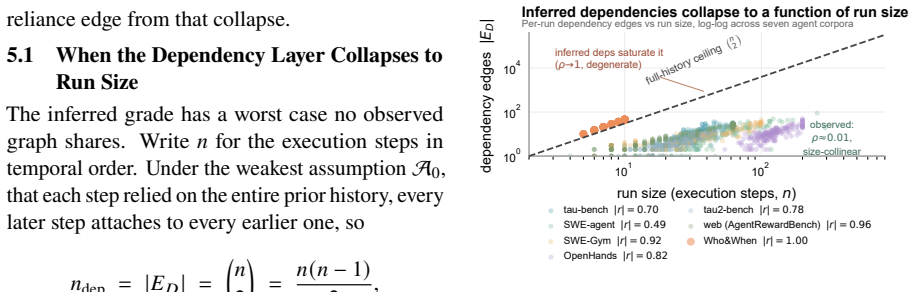
GRADE represents every LLM agent run as one graph over step nodes with two edge layers: execution edges read directly from the trace and dependency edges graded according to whether they are known, observed, declared, or inferred. The dependency layer predicts failure where run size is a weak predictor, remains above chance under leave-one-corpus-out transfer on every held-out class, and the execution layer localizes the faulting step in failed multi-agent runs; feature-based models read the dependency layer more reliably than generic graph neural networks.
What carries the argument
The GRADE graph with execution edges taken from the trace and dependency edges graded by source of knowledge.
If this is right
- The dependency layer predicts failure in LLM agent runs where run size alone is weak.
- The same layer stays above chance on every held-out corpus under leave-one-corpus-out transfer.
- The execution layer identifies the faulting step inside a failed multi-agent trace.
- Feature-based alternatives read the dependency layer more reliably than generic graph neural networks.
Where Pith is reading between the lines
- The same graph could support automated efficiency tuning of agent workflows at larger scale.
- Runtime systems might use the graded edges for live fault detection before a run completes.
- The representation invites comparison with dependency structures in non-LLM planning systems.
Load-bearing premise
That dependency edges can be graded and recovered from traces with enough accuracy and completeness for the resulting layer to carry predictive signal independent of run size.
What would settle it
If, on fresh corpora of LLM agent runs, the graded dependency layer's accuracy at predicting failure drops to chance after controlling for run size, the central claim is falsified.
Figures



read the original abstract
Can one graph represent every kind of LLM agent's run? A trace records what each step did, never what it relied on, the state it read, and the results it reused. GRADE recovers that missing layer: it models any run as one graph over its step nodes with two edge layers, execution edges (what ran in what order) read from the trace for free, and dependency edges (what each step relied on) rarely logged, so each is graded by how it is known, observed, declared, or inferred. One representation, and each layer earns its place. Across six corpora of LLM agents spanning tool use, coding, and the web, the dependency layer can predict failure where run size is weak and, under leave-one-corpus-out transfer, stays above chance on every held-out class while run size fails. Meanwhile, the execution layer localizes the faulting step in a failed multi-agent run. This work also provides a more in-depth analysis of why generic graph neural networks may misread the dependency layer, unlike our feature-based alternative. The same graph representation opens further uses, carrying from failure diagnosis in a single run to efficiency and robustness optimization at scale.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GRADE, a graph representation for LLM agent runs with execution edges (read directly from traces) and graded dependency edges (known/observed/declared/inferred). It claims that across six corpora spanning tool use, coding, and web agents, the dependency layer predicts failure better than run size, generalizes above chance in leave-one-corpus-out transfer (while run size fails), and that the execution layer localizes faults in multi-agent runs. It also analyzes why generic GNNs may misread the dependency layer and suggests broader uses for diagnosis and optimization.
Significance. If the dependency recovery proves accurate and independent of run size, GRADE could offer a reusable structured representation for analyzing and improving LLM agent systems, moving beyond raw traces to model reliance and reuse explicitly. The multi-corpus evaluation and transfer setup are positive features that test generalization.
major comments (2)
- [Methods (edge grading and recovery)] The central claim that the dependency layer carries predictive signal independent of run size (and generalizes in leave-one-corpus-out) rests on the accuracy and completeness of graded edge recovery, yet no precision, recall, or human ground-truth validation of the inference rules for 'inferred' edges is reported. This is load-bearing for the independence assumption.
- [Experiments (§ on corpora and prediction)] Experimental results on failure prediction and transfer: no ablation that removes or down-weights low-confidence inferred edges, nor any analysis checking whether the grading heuristics correlate with corpus-specific failure patterns or trace formats. Without these, the reported superiority over run size cannot be isolated from potential artifacts in the recovery process.
minor comments (2)
- [Abstract] The abstract states empirical results on six corpora but provides no high-level description of the corpora, the exact failure-prediction task, or the feature-based alternative to GNNs; adding one sentence would improve readability.
- [Introduction / §2] Notation for the two edge layers and the four grades (known/observed/declared/inferred) should be introduced with a small table or diagram early in the paper for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the validation of edge recovery and experimental controls. We respond to each major comment below and commit to revisions that directly address the concerns.
read point-by-point responses
-
Referee: [Methods (edge grading and recovery)] The central claim that the dependency layer carries predictive signal independent of run size (and generalizes in leave-one-corpus-out) rests on the accuracy and completeness of graded edge recovery, yet no precision, recall, or human ground-truth validation of the inference rules for 'inferred' edges is reported. This is load-bearing for the independence assumption.
Authors: We agree that the manuscript does not report precision, recall, or human validation for the inferred edges, which is a genuine gap for substantiating the independence claim. The inference rules are deterministic and based on trace semantics (data flow, state reads, and reuse), as specified in the methods. In revision we will add a human evaluation on a sampled subset of inferred edges drawn from all six corpora, reporting precision and recall to quantify recovery accuracy. revision: yes
-
Referee: [Experiments (§ on corpora and prediction)] Experimental results on failure prediction and transfer: no ablation that removes or down-weights low-confidence inferred edges, nor any analysis checking whether the grading heuristics correlate with corpus-specific failure patterns or trace formats. Without these, the reported superiority over run size cannot be isolated from potential artifacts in the recovery process.
Authors: We acknowledge the absence of these controls. The leave-one-corpus-out transfer already provides some evidence against corpus-specific artifacts, but it does not fully isolate the contribution of low-confidence edges. In the revision we will add (1) an ablation that removes or down-weights inferred edges and re-runs both within-corpus and transfer experiments, and (2) a correlation analysis between edge grades and failure rates/trace formats across corpora. These will be reported alongside the existing results. revision: yes
Circularity Check
No circularity; empirical validation stands independent of inputs
full rationale
The manuscript presents a graph-construction procedure (execution edges read directly from traces; dependency edges graded as known/observed/declared/inferred) followed by cross-corpus empirical tests and leave-one-corpus-out transfer. No equations, fitted parameters, or self-citations appear in the supplied text that would reduce any reported prediction to the construction rules themselves. The central claims rest on external performance metrics against run-size baselines, which are falsifiable outside the recovery heuristic.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2307.15043 , year=
Universal and transferable adversarial attacks on aligned language models , author=. arXiv preprint arXiv:2307.15043 , year=
-
[2]
arXiv preprint arXiv:2310.03693 , year=
Fine-tuning aligned language models compromises safety, even when users do not intend to! , author=. arXiv preprint arXiv:2310.03693 , year=
-
[3]
Proceedings of the 41st International Conference on Machine Learning , pages=
HarmBench: a standardized evaluation framework for automated red teaming and robust refusal , author=. Proceedings of the 41st International Conference on Machine Learning , pages=
-
[4]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Safedecoding: Defending against jailbreak attacks via safety-aware decoding , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[5]
arXiv preprint arXiv:2312.06674 , year=
Llama guard: Llm-based input-output safeguard for human-ai conversations , author=. arXiv preprint arXiv:2312.06674 , year=
-
[6]
International Conference on Detection of Intrusions and Malware, and Vulnerability Assessment , pages=
Backstabber’s knife collection: A review of open source software supply chain attacks , author=. International Conference on Detection of Intrusions and Malware, and Vulnerability Assessment , pages=. 2020 , organization=
2020
-
[7]
Proceedings of the Intelligent Robotics FAIR 2025 , pages=
Creating Characteristically Auditable Agentic AI Systems , author=. Proceedings of the Intelligent Robotics FAIR 2025 , pages=
2025
-
[8]
White and Margaret Mitchell and Timnit Gebru and Ben Hutchinson and Jamila Smith-Loud and Daniel Theron and Parker Barnes , title =
Inioluwa Deborah Raji and Andrew Smart and Rebecca N. White and Margaret Mitchell and Timnit Gebru and Ben Hutchinson and Jamila Smith-Loud and Daniel Theron and Parker Barnes , title =. Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency , year =
2020
-
[9]
Auditing Large Language Models: A Three-Layered Approach , journal =
Jakob M\". Auditing Large Language Models: A Three-Layered Approach , journal =. 2023 , volume =
2023
-
[10]
Proceedings of the 2nd IEEE Conference on Secure and Trustworthy Machine Learning , year =
Abeba Birhane and Ryan Steed and Victor Ojewale and Briana Vecchione and Inioluwa Deborah Raji , title =. Proceedings of the 2nd IEEE Conference on Secure and Trustworthy Machine Learning , year =
-
[11]
Maddison and Tatsunori Hashimoto , title =
Yangjun Ruan and Honghua Dong and Andrew Wang and Silviu Pitis and Yongchao Zhou and Jimmy Ba and Yann Dubois and Chris J. Maddison and Tatsunori Hashimoto , title =. Proceedings of the Twelfth International Conference on Learning Representations , year =
-
[12]
Findings of the Association for Computational Linguistics: EMNLP 2024 , year =
Tongxin Yuan and Zhiwei He and Lingzhong Dong and Yiming Wang and Ruijie Zhao and Tian Xia and Lizhen Xu and Binglin Zhou and Fangqi Li and Zhuosheng Zhang and Rui Wang and Gongshen Liu , title =. Findings of the Association for Computational Linguistics: EMNLP 2024 , year =
2024
-
[13]
arXiv preprint arXiv:2412.14470 , year =
Zhexin Zhang and Shiyao Cui and Yida Lu and Jingzhuo Zhou and Junxiao Yang and Hongning Wang and Minlie Huang , title =. arXiv preprint arXiv:2412.14470 , year =
-
[14]
Haoyu Wang and Christopher M. Poskitt and Jun Sun , title =. arXiv preprint arXiv:2503.18666 , year =
-
[15]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics , year =
Weidi Luo and Shenghong Dai and Xiaogeng Liu and Suman Banerjee and Huan Sun and Muhao Chen and Chaowei Xiao , title =. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics , year =
-
[16]
Proceedings of the 42nd International Conference on Machine Learning , year =
Tobin South and Samuele Marro and Thomas Hardjono and Robert Mahari and Cedric Deslandes Whitney and Dazza Greenwood and Alan Chan and Alex Pentland , title =. Proceedings of the 42nd International Conference on Machine Learning , year =
-
[17]
Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency , year =
Alan Chan and Carson Ezell and Max Kaufmann and Kevin Wei and Lewis Hammond and Herbie Bradley and Emma Bluemke and Nitarshan Rajkumar and David Krueger and Noam Kolt and Lennart Heim and Markus Anderljung , title =. Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency , year =
2024
-
[18]
arXiv preprint arXiv:2601.20727 , year =
Victor Ojewale and Harini Suresh and Suresh Venkatasubramanian , title =. arXiv preprint arXiv:2601.20727 , year =
-
[20]
Proceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security , year =
Zachary Newman and John Speed Meyers and Santiago Torres-Arias , title =. Proceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security , year =
2022
-
[21]
Crosby and Dan S
Scott A. Crosby and Dan S. Wallach , title =. Proceedings of the 18th USENIX Security Symposium , year =
-
[22]
Proceedings of the Conference on Fairness, Accountability, and Transparency , year =
Margaret Mitchell and Simone Wu and Andrew Zaldivar and Parker Barnes and Lucy Vasserman and Ben Hutchinson and Elena Spitzer and Inioluwa Deborah Raji and Timnit Gebru , title =. Proceedings of the Conference on Fairness, Accountability, and Transparency , year =
-
[23]
Datasheets for Datasets , journal =
Timnit Gebru and Jamie Morgenstern and Briana Vecchione and Jennifer Wortman Vaughan and Hanna Wallach and Hal Daum\'. Datasheets for Datasets , journal =. 2021 , volume =
2021
-
[24]
2026 , url =
Steinberger, Peter and. 2026 , url =
2026
-
[25]
Lai, Kwei-Herng and Zha, Daochen and Wang, Guanchu and Xu, Junjie and Zhao, Yue and Kumar, Devesh and Chen, Yile and Zumkhawaka, Purav and Wan, Minyang and Martinez, Diego and others , booktitle=
-
[26]
Liu, Kay and Dou, Yingtong and Zhao, Yue and Ding, Xueying and Hu, Xiyang and Zhang, Ruitong and Ding, Kaize and Chen, Canyu and Peng, Hao and Shu, Kai and others , journal=
-
[27]
arXiv preprint arXiv:2302.04549 , year=
Weakly Supervised Anomaly Detection: A Survey , author=. arXiv preprint arXiv:2302.04549 , year=
-
[28]
2020 , organization=
Li, Zheng and Zhao, Yue and Botta, Nicola and Ionescu, Cezar and Hu, Xiyang , booktitle=. 2020 , organization=
2020
-
[29]
2020 , organization=
Lee, Meng-Chieh and Zhao, Yue and Wang, Aluna and Liang, Pierre Jinghong and Akoglu, Leman and Tseng, Vincent S and Faloutsos, Christos , booktitle=. 2020 , organization=
2020
-
[30]
2018 , organization=
Zhao, Yue and Hryniewicki, Maciej K , booktitle=. 2018 , organization=
2018
-
[31]
Pacific-Asia Conference on Knowledge Discovery and Data Mining , pages=
Contrastive Attributed Network Anomaly Detection with Data Augmentation , author=. Pacific-Asia Conference on Knowledge Discovery and Data Mining , pages=. 2022 , organization=
2022
-
[32]
Journal of Machine Learning Research , year =
Yue Zhao and Zain Nasrullah and Zheng Li , title =. Journal of Machine Learning Research , year =
-
[33]
Zhao, Yue and Hu, Xiyang and Cheng, Cheng and Wang, Cong and Wan, Changlin and Wang, Wen and Yang, Jianing and Bai, Haoping and Li, Zheng and Xiao, Cao and Wang, Yunlong and Qiao, Zhi and Sun, Jimeng and Akoglu, Leman , booktitle =
-
[34]
Advances in Neural Information Processing Systems , volume=
Automatic Unsupervised Outlier Model Selection , author=. Advances in Neural Information Processing Systems , volume=
-
[35]
Advances in neural information processing systems , year=
Therapeutics Data Commons: Machine Learning Datasets and Tasks for Drug Discovery and Development , author=. Advances in neural information processing systems , year=
-
[36]
Neural Information Processing Systems (NeurIPS) , year=
Revisiting Time Series Outlier Detection: Definitions and Benchmarks , author=. Neural Information Processing Systems (NeurIPS) , year=
-
[37]
2022 IEEE International Conference on Data Mining (ICDM) , pages=
Toward Unsupervised Outlier Model Selection , author=. 2022 IEEE International Conference on Data Mining (ICDM) , pages=. 2022 , organization=
2022
-
[38]
Nature Chemical Biology , year=
Artificial Intelligence Foundation for Therapeutic Science , author =. Nature Chemical Biology , year=
-
[39]
Han, Songqiao and Hu, Xiyang and Huang, Hailiang and Jiang, Minqi and Zhao, Yue , journal=
-
[40]
2022 , pages=
Li, Zheng and Zhao, Yue and Hu, Xiyang and Botta, Nicola and Ionescu, Cezar and Chen, George , journal=. 2022 , pages=
2022
-
[41]
Zhao, Yue and Zheng, Guoqing and Mukherjee, Subhabrata and McCann, Robert and Awadallah, Ahmed , booktitle=
-
[42]
ACM Computing Surveys , year=
Diffusion Models: A Comprehensive Survey of Methods and Applications , author=. ACM Computing Surveys , year=
-
[43]
2023 , organization=
Yoo, Jaemin and Zhao, Yue and Zhao, Lingxiao and Akoglu, Leman , booktitle=. 2023 , organization=
2023
-
[44]
International Conference on Machine Learning , pages=
Do Not Train It: A Linear Neural Architecture Search of Graph Neural Networks , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[45]
ACM SIGKDD Explorations Newsletter , volume=
The Need for Unsupervised Outlier Model Selection: A Review and Evaluation of Internal Evaluation Strategies , author=. ACM SIGKDD Explorations Newsletter , volume=
-
[46]
Jiang, Minqi and Hou, Chaochuan and Zheng, Ao and Han, Songqiao and Huang, Hailiang and Wen, Qingsong and Hu, Xiyang and Zhao, Yue , journal=
-
[47]
Chen and Zhihao Jia , journal=
Yue Zhao and George H. Chen and Zhihao Jia , journal=
-
[48]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Towards Reproducible, Automated, and Scalable Anomaly Detection , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[49]
International Conference on Automated Machine Learning , publisher=
Hyperparameter Optimization for Unsupervised Outlier Detection , author=. International Conference on Automated Machine Learning , publisher=
-
[50]
International Conference on Machine Learning , year=
Preference Optimization for Molecule Synthesis with Conditional Residual Energy-based Models , author=. International Conference on Machine Learning , year=
-
[51]
Position:
Huang, Yue and Sun, Lichao and Wang, Haoran and Wu, Siyuan and Zhang, Qihui and Li, Yuan and Gao, Chujie and Huang, Yixin and Lyu, Wenhan and Zhang, Yixuan and others , booktitle=. Position:. 2024 , organization=
2024
-
[52]
Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
Fast Unsupervised Deep Outlier Model Selection with Hypernetworks , author=. Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
-
[53]
Dong, Hao and Zhao, Yue and Chatzi, Eleni and Fink, Olga , journal=
-
[54]
IEEE Transactions on Neural Networks and Learning Systems , year=
Dong, Hao and Frusque, Ga. IEEE Transactions on Neural Networks and Learning Systems , year=
-
[55]
Liu, Sizhe and Lu, Yizhou and Chen, Siyu and Hu, Xiyang and Zhao, Jieyu and Fu, Tianfan and Zhao, Yue , booktitle=
-
[56]
Yang, Tiankai and Liu, Junjun and Siu, Wingchun and Wang, Jiahang and Qian, Zhuangzhuang and Song, Chanjuan and Cheng, Cheng and Hu, Xiyang and Zhao, Yue , journal=
-
[57]
Shao, Ruosi and Seraj, Md Shamim and Zhao, Kangyi and Luo, Yingtao and Li, Lincan and Shen, Bolin and Bates, Averi and Zhao, Yue and Pan, Chongle and Hightow-Weidman, Lisa and Chakraborty, Shayok and Dong, Yushun , booktitle=
-
[58]
Proceedings of the Association for Computational Linguistics (ACL) , year=
From Selection to Generation: A Survey of LLM-based Active Learning , author=. Proceedings of the Association for Computational Linguistics (ACL) , year=
-
[59]
Yang, Tiankai and Nian, Yi and Li, Shawn and Xu, Ruiyao and Li, Yuangang and Li, Jiaqi and Hu, Xiyang and Rossi, Ryan and Ding, Kaize and Hu, Xia and Zhao, Yue , booktitle=
-
[60]
Xu, Zerui and Wu, Fang and Zhang, Yuanyuan and Zhao, Yue , journal=
-
[61]
Yi Nian and Shenzhe Zhu and Yuehan Qin and Li Li and Ziyi Wang and Chaowei Xiao and Yue Zhao , booktitle=
-
[62]
Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR) , month =
Li, Shawn and Gong, Huixian and Dong, Hao and Yang, Tiankai and Tu, Zhengzhong and Zhao, Yue , title =. Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR) , month =. 2025 , pages =
2025
-
[63]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Edit Away and My Face Will Not Stay: Personal Biometric Defense against Malicious Generative Editing , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[64]
Li, Yuangang and Li, Jiaqi and Xiao, Zhuo and Yang, Tiankai and Nian, Yi and Hu, Xiyang and Zhao, Yue , journal=
-
[65]
Findings of the Association for Computational Linguistics: EMNLP 2025 , year=
Treble Counterfactual VLMs: A Causal Approach to Hallucination , author=. Findings of the Association for Computational Linguistics: EMNLP 2025 , year=
2025
-
[66]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
Secure On-Device Video OOD Detection Without Backpropagation , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
-
[67]
IEEE International Conference on Data Mining (ICDM), BlueSky Track , year =
Navigating Between Explainability and Extractability in Machine Learning as a Service , author =. IEEE International Conference on Data Mining (ICDM), BlueSky Track , year =
-
[68]
Yuehan Qin and Yichi Zhang and Yi Nian and Xueying Ding and Yue Zhao , booktitle=
-
[69]
Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Lecture-Style Tutorial Track , year=
A Survey on Model Extraction Attacks and Defenses for Large Language Models , author=. Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Lecture-Style Tutorial Track , year=
-
[70]
Wang, Yanbo and Ye, Jiayi and Wu, Siyuan and Gao, Chujie and Huang, Yue and Chen, Xiuying and Zhao, Yue and Zhang, Xiangliang , booktitle=
-
[71]
Wang, Yanbo and Xu, Zixiang and Huang, Yue and Wang, Xiangqi and Song, Zirui and Gao, Lang and Wang, Chenxi and Tang, Xiangru and Zhao, Yue and Cohan, Arman and Zhang, Xiangliang and Chen, Xiuying , journal=
-
[72]
NeurIPS Workshop on Multi-Turn Interactions in Large Language Models (MTI-LLM) , year=
A Personalized Conversational Benchmark: Towards Simulating Personalized Conversations , author=. NeurIPS Workshop on Multi-Turn Interactions in Large Language Models (MTI-LLM) , year=
-
[73]
2025 , note=
Xu, Zixiang and Wang, Yanbo and Huang, Yue and Ye, Jiayi and Zhuang, Haomin and Song, Zirui and Gao, Lang and Wang, Chenxi and Chen, Zhaorun and Zhou, Yujun and Li, Sixian and Pan, Wang and Zhao, Yue and Zhao, Jieyu and Zhang, Xiangliang and Chen, Xiuying , booktitle=. 2025 , note=
2025
-
[74]
Proceedings of the European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML PKDD) , year =
Few-Shot Graph Out-of-Distribution Detection with LLMs , author =. Proceedings of the European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML PKDD) , year =
-
[75]
Li, Lincan and Ozguven, Eren Erman and Zhao, Yue and Wang, Guang and Xie, Yiqun and Dong, Yushun , journal=
-
[76]
Xu, Haoyan and Liu, Kay and Yao, Zhengtao and Yu, Philip S and Ding, Kaize and Zhao, Yue , journal=
-
[77]
Sihan Chen and Zhuangzhuang Qian and Wingchun Siu and Xingcan Hu and Jiaqi Li and Shawn Li and Yuehan Qin and Tiankai Yang and Zhuo Xiao and Wanghao Ye and Yichi Zhang and Yushun Dong and Yue Zhao , booktitle=
-
[78]
Proceedings of the AAAI Conference on Artificial Intelligence , year=
Mitigating Hallucinations in Large Language Models via Causal Reasoning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , year=
-
[79]
Conference of the European Chapter of the Association for Computational Linguistics (EACL) , year=
A Survey on LLM-based Conversational User Simulation , author=. Conference of the European Chapter of the Association for Computational Linguistics (EACL) , year=
-
[80]
International Conference on Learning Representations (ICLR) , year=
Charts Are Not Images: On the Challenges of Scientific Chart Editing , author=. International Conference on Learning Representations (ICLR) , year=
-
[81]
Qian, Chengxuan and Xing, Shuo and Li, Shawn and Zhao, Yue and Tu, Zhengzhong , booktitle=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.