From Tokens to Faces: Investigating Discrete Speech Representations for 3D Facial Animation
Pith reviewed 2026-06-27 06:44 UTC · model grok-4.3
The pith
Encoding phonetic classes in discrete speech tokens produces accurate 3D facial animation with quality comparable to semantic representations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that encoding phonetic classes is beneficial for accurate facial animation prediction on both semantic and label-based representations with comparable facial animation quality. Probing analyses connect the tokenized representations to phonetic units and articulatory deformations. From these observations they construct an Audio Visual Text-to-Speech pipeline that treats the discrete representations as a shared space for decoding both speech and 3D facial motion.
What carries the argument
Evaluation of four speech representation families for 3D facial synthesis together with probing of tokenized outputs against phonetic units and articulatory deformations; the mechanism is phonetic-class encoding inside discrete tokens.
If this is right
- Phonetic encoding improves prediction accuracy for facial animation across representation types.
- Semantic and label-based representations reach similar animation quality once phonetic information is present.
- Discrete token spaces can serve as a shared representation for simultaneous speech and 3D facial motion synthesis.
- Probing shows direct relations between the tokens and both phonetic categories and physical articulatory changes.
Where Pith is reading between the lines
- A single discrete token stream might support joint training of models that output text, audio, and face motion without separate feature pipelines.
- The same phonetic-token approach could be tested for driving full-body gestures or head motion in addition to facial animation.
- If the benefit of phonetic encoding persists across languages, the method could reduce reliance on language-specific semantic extractors in animation systems.
Load-bearing premise
The chosen objective metrics and perceptual evaluation protocol are sufficient to establish that phonetic encoding produces meaningfully better or equivalent facial animation in practical use cases.
What would settle it
A perceptual test in which listeners consistently rate the naturalness of facial animations driven by phonetic-encoded tokens as lower than those driven by non-phonetic tokens would falsify the claim of comparable quality.
Figures


read the original abstract
The choice of speech representation is critical in speech-driven 3D facial animation. Representations differ in what they encode: SSL features emphasize segmental and semantic cues, neural codecs yield latents optimized for acoustic reconstruction, and ASR-style objectives produce label-based spaces. We evaluate four speech representation families for 3D facial synthesis, comparing their facial reconstruction quality across two facial decoders using objective metrics and a perceptual evaluation. We additionally conduct probing analyses that relate tokenized representations to phonetic units and to articulatory deformations. We found that encoding phonetic classes is beneficial for accurate facial animation prediction on both semantic and label-based representations with comparable facial animation quality. From the latter, we introduce an Audio Visual Text-to-Speech (AVTTS) pipeline that leverages, as a shared space, discrete representations to decode speech and 3D facial motion.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates four speech representation families for 3D facial synthesis using two facial decoders. It compares their reconstruction quality with objective metrics and perceptual evaluation, conducts probing analyses relating tokens to phonetic units and articulatory deformations, and concludes that phonetic class encoding is beneficial for accurate facial animation on semantic and label-based representations with comparable quality. It also introduces an AVTTS pipeline using discrete representations as a shared space.
Significance. If the results are robust, this work would advance the understanding of how different speech representations, particularly those encoding phonetic classes, impact 3D facial animation quality. The introduction of the AVTTS pipeline could have practical implications for audio-visual synthesis systems. The probing analyses provide additional insight into the relationship between discrete tokens and phonetic/articulatory features.
major comments (2)
- [§5] §5 (Experiments): The quality comparison between representations does not include an ablation that holds discretization and training objective fixed while varying phonetic supervision, so the attribution of benefits to phonetic encoding rather than other properties of the discrete spaces remains unsupported.
- [Perceptual evaluation section] Perceptual evaluation section: The protocol's sensitivity, effect sizes, inter-rater reliability, and controls for representation dimensionality or training regime are not shown, weakening the claim that phonetic encoding produces 'comparable' or 'beneficial' animation quality.
minor comments (1)
- The abstract could more explicitly name the four representation families evaluated.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point by point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [§5] §5 (Experiments): The quality comparison between representations does not include an ablation that holds discretization and training objective fixed while varying phonetic supervision, so the attribution of benefits to phonetic encoding rather than other properties of the discrete spaces remains unsupported.
Authors: We agree that the current design compares established representation families that differ along multiple axes (discretization method, training objective, and supervision type), so a direct causal attribution to phonetic encoding alone is not isolated. The probing experiments provide supporting correlational evidence linking tokens to phonetic units, but this does not substitute for a controlled ablation. In the revision we will explicitly qualify the claims to reflect the comparative nature of the evaluation across families and add a limitations paragraph acknowledging the absence of such an ablation. A full controlled ablation would require substantial additional training and is not feasible within the current revision timeline; we therefore treat this as a limitation rather than performing the experiment. revision: partial
-
Referee: [Perceptual evaluation section] Perceptual evaluation section: The protocol's sensitivity, effect sizes, inter-rater reliability, and controls for representation dimensionality or training regime are not shown, weakening the claim that phonetic encoding produces 'comparable' or 'beneficial' animation quality.
Authors: We accept that the perceptual evaluation section is missing these quantitative details. In the revised manuscript we will report effect sizes, inter-rater reliability (e.g., Krippendorff’s alpha), and an assessment of protocol sensitivity. We will also include a brief discussion of dimensionality differences across representations and note that training regimes were held as consistent as possible given the source models. These additions will allow us to support the “comparable quality” statement with appropriate statistical context. revision: yes
Circularity Check
No circularity: empirical evaluation with no derivations or fitted predictions
full rationale
The paper reports an empirical comparison of four speech representation families for 3D facial animation synthesis, using objective metrics, perceptual evaluation, and probing analyses. No equations, derivations, or 'predictions' derived from fitted parameters appear; the central claim is framed as an observation from experiments rather than a quantity obtained by construction from inputs. No self-citation chains, uniqueness theorems, or ansatzes are invoked to justify load-bearing steps. The work is self-contained as a standard experimental study against external benchmarks (metrics and human raters), with any limitations in ablation design falling under evidence strength rather than circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction Speech-driven 3D facial animation aims to synthesize tempo- rally coherent and accurate facial movements directly from speech signals [1, 2, 3, 4]. Central to this task, most recent architectures (Fig. 1) use a speech representation bottleneck, which may capture discrete phonetic class information, continu- ous articulatory dynamics, and pros...
Pith/arXiv arXiv 2026
-
[2]
Method 2.1. Experimental Setup To investigate which speech tokens can serve as effective rep- resentations for speech-driven 3D facial animation, we adopted a comparative experimental framework. The general pipeline of our method is illustrated in Fig. 1. We evaluated four speech encoders: HuBERT (HB) [6], SpeechTokenizer (ST) [14], Wav- Tokenizer (WT) [1...
-
[3]
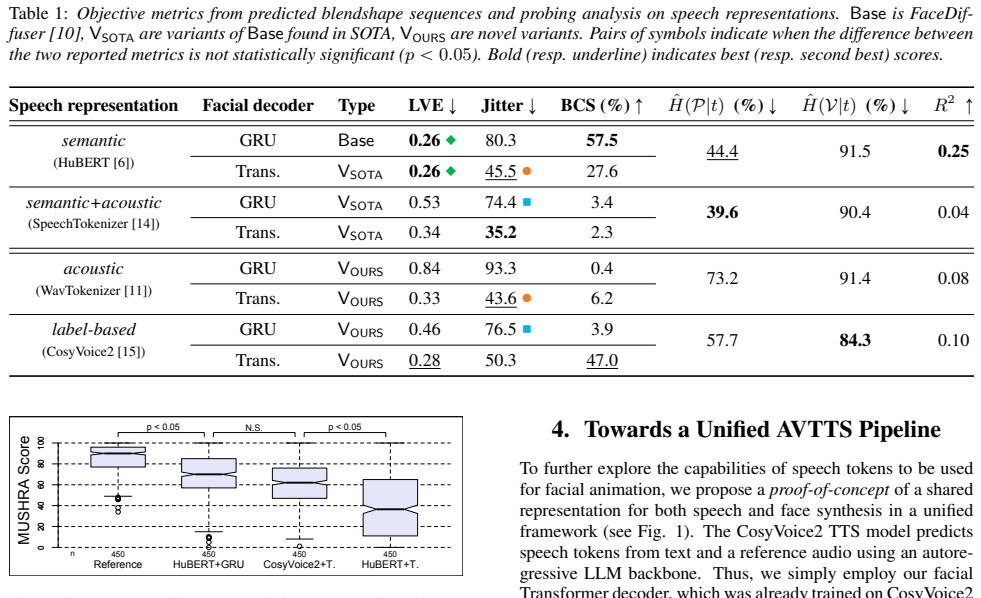
In terms of lips and mouth accuracy (LVE), both Hu- BERT models score higher than the discrete models, although the performance of [CV2+T.] is not far behind
Results and Discussion Objective metrics.Table 1 shows the results for the objec- tive metrics on generated animation sequences by our 8 model variants on the BEAT2 test set (265 stimuli, or approximately 4 hours). In terms of lips and mouth accuracy (LVE), both Hu- BERT models score higher than the discrete models, although the performance of [CV2+T.] is...
-
[4]
Towards a Unified A VTTS Pipeline To further explore the capabilities of speech tokens to be used for facial animation, we propose aproof-of-conceptof a shared representation for both speech and face synthesis in a unified framework (see Fig. 1). The CosyV oice2 TTS model predicts speech tokens from text and a reference audio using an autore- gressive LLM...
-
[5]
Our results demon- strated that bothsemanticandlabel-basedrepresentations are suitable candidates for this task, and that they have similar per- ceptual performance
Conclusion This work presented a systematic comparison ofsemantic,se- mantic+acoustic,acoustic, andlabel-basedspeech representa- tions for 3D facial animation generation. Our results demon- strated that bothsemanticandlabel-basedrepresentations are suitable candidates for this task, and that they have similar per- ceptual performance. Probing analysis rev...
-
[6]
Acknowledgments This work was funded by the S ˜ao Paulo Research Foundation (FAPESP) under grant #2025/09875-7 through a Research In- ternship Abroad (BEPE) scholarship in the GIPSA-lab (Uni- versit´e Grenoble Alpes), supported by FAPESP under grant #2020/09838-0 (BI0S - Brazilian Institute of Data Science), and partially funded by the Coordenac ¸˜ao de A...
2025
-
[7]
The first author is affiliated with the Artificial Intelligence Lab, Recod.ai, and by MIAI Cluster (ANR-23-IACL-0006)
-
[8]
Generative AI Use Disclosure The writing of this paper was supported by generative AI tools, which were used strictly for the refinement of the text to follow correct English grammar, sentence structure, and clarity
-
[9]
Modeling coarticulation in synthetic visual speech,
M. M. Cohen and D. W. Massaro, “Modeling coarticulation in synthetic visual speech,” inModels and Techniques in Computer Animation, N. Thalmann and D. Thalmann, Eds. Springer, 1993, pp. 139–156
1993
-
[10]
Generating facial expressions for speech,
C. Pelachaud, N. I. Badler, and M. Steedman, “Generating facial expressions for speech,”Cognitive Science, vol. 20, no. 1, pp. 1– 46, 1996
1996
-
[11]
Audio- driven facial animation by joint end-to-end learning of pose and emotion,
T. Karras, T. Aila, S. Laine, A. Herva, and J. Lehtinen, “Audio- driven facial animation by joint end-to-end learning of pose and emotion,”ACM Trans. Graph., vol. 36, no. 4, Jul. 2017
2017
-
[12]
MeshTalk: 3D face animation from speech using cross-modality disentanglement,
A. Richard, M. Zollh ¨ofer, Y . Wen, F. de la Torre, and Y . Sheikh, “MeshTalk: 3D face animation from speech using cross-modality disentanglement,” inIEEE/CVF International Conference on Computer Vision (ICCV), October 2021, pp. 1173–1182
2021
-
[13]
wav2vec 2.0: A framework for self-supervised learning of speech representa- tions,
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representa- tions,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 33, 2020, pp. 12 449–12 460
2020
-
[14]
HuBERT: Self-supervised speech representation learning by masked prediction of hidden units,
W.-N. Hsu, B. Bolte, Y .-H. H. Tsai, K. Lakhotia, R. Salakhut- dinov, and A. Mohamed, “HuBERT: Self-supervised speech representation learning by masked prediction of hidden units,” IEEE/ACM Transactions on Audio, Speech, and Language Pro- cessing, vol. 29, pp. 3451–3460, 2021
2021
-
[15]
Robust speech recognition via large-scale weak supervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” inInternational Conference on Machine Learning (ICML). PMLR, 2023, pp. 28 448–28 481
2023
-
[16]
Face- Former: Speech-driven 3d facial animation with transformers,
Y . Fan, Z. Lin, J. Saito, W. Wang, and T. Komura, “Face- Former: Speech-driven 3d facial animation with transformers,” in IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion (CVPR), June 2022, pp. 18 770–18 780
2022
-
[17]
CodeTalker: Speech-driven 3d facial animation with discrete motion prior,
J. Xing, M. Xia, Y . Zhang, X. Cun, J. Wang, and T.-T. Wong, “CodeTalker: Speech-driven 3d facial animation with discrete motion prior,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2023, pp. 12 780–12 790
2023
-
[18]
FaceDiffuser: Speech- driven 3d facial animation synthesis using diffusion,
S. Stan, K. I. Haque, and Z. Yumak, “FaceDiffuser: Speech- driven 3d facial animation synthesis using diffusion,” inACM SIGGRAPH Conference on Motion, Interaction and Games. New York, NY , USA: Association for Computing Machinery, 2023
2023
-
[19]
WavTokenizer: an efficient acoustic discrete codec tokenizer for audio language modeling,
S. Ji, Z. Jiang, W. Wang, Y . Chen, M. Fang, J. Zuo, Q. Yang, X. Cheng, Z. Wang, R. Liet al., “WavTokenizer: an efficient acoustic discrete codec tokenizer for audio language modeling,” inInternational Conference on Learning Representations (ICLR), 2024
2024
-
[20]
BigCodec: Pushing the limits of low-bitrate neural speech codec,
D. Xin, X. Tan, S. Takamichi, and H. Saruwatari, “BigCodec: Pushing the limits of low-bitrate neural speech codec,” 2024
2024
-
[21]
Bringing Interpretability to Neural Audio Codecs,
S. Sadok, J. Hauret, and ´E. Bavu, “Bringing Interpretability to Neural Audio Codecs,” inInterspeech, Rotterdam, The Nether- lands, August 17-21 2025, pp. 5023–5027
2025
-
[22]
SpeechTok- enizer: Unified speech tokenizer for speech language models,
X. Zhang, D. Zhang, S. Li, Y . Zhou, and X. Qiu, “SpeechTok- enizer: Unified speech tokenizer for speech language models,” inInternational Conference on Learning Representations (ICLR), 2024
2024
-
[23]
Cosyvoice 2: Scalable stream- ing speech synthesis with large language models,
Z. Du, Y . Wang, Q. Chen, X. Shi, X. Lv, T. Zhao, Z. Gao, Y . Yang, C. Gao, H. Wanget al., “Cosyvoice 2: Scalable stream- ing speech synthesis with large language models,”arXiv preprint arXiv:2412.10117, 2024
Pith/arXiv arXiv 2024
-
[24]
VQTalker: Towards multilingual talking avatars through facial motion tokenization,
T. Liu, Z. Ma, Q. Chen, F. Chen, S. Fan, X. Chen, and K. Yu, “VQTalker: Towards multilingual talking avatars through facial motion tokenization,”AAAI Conference on Artificial Intelligence, vol. 39, no. 6, pp. 5586–5594, Apr. 2025
2025
-
[25]
SOLAMI: Social vision-language-action modeling for immersive interaction with 3d autonomous charac- ters,
J. Jiang, W. Xiao, Z. Lin, H. Zhang, T. Ren, Y . Gao, Z. Lin, Z. Cai, L. Yang, and Z. Liu, “SOLAMI: Social vision-language-action modeling for immersive interaction with 3d autonomous charac- ters,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2025, pp. 26 887–26 898
2025
-
[26]
Neural codec language models are zero-shot text to speech synthesizers,
S. Chen, C. Wang, Y . Wu, Z. Zhang, L. Zhou, S. Liu, Z. Chen, Y . Liu, H. Wang, J. Li, L. He, S. Zhao, and F. Wei, “Neural codec language models are zero-shot text to speech synthesizers,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 33, pp. 705–718, 2025
2025
-
[27]
FastLips: an end-to-end audiovisual text-to-speech system with lip features prediction for virtual avatars,
M. Lenglet, O. Perrotin, and G. Bailly, “FastLips: an end-to-end audiovisual text-to-speech system with lip features prediction for virtual avatars,” inInterspeech, Kos, Greece, September 1-5 2024, pp. 3450–3454
2024
-
[28]
FastSpeech 2: fast and high-quality end-to-end text to speech,
Y . Ren, C. Hu, X. Tan, T. Qin, S. Zhao, Z. Zhao, and T.-Y . Liu, “FastSpeech 2: fast and high-quality end-to-end text to speech,” inInternational Conference on Learning Representations (ICLR), Virtual, May 3-7 2021
2021
-
[29]
Learning phrase rep- resentations using RNN encoder–decoder for statistical machine translation,
K. Cho, B. Van Merri ¨enboer, C. Gulcehre, D. Bahdanau, F. Bougares, H. Schwenk, and Y . Bengio, “Learning phrase rep- resentations using RNN encoder–decoder for statistical machine translation,” inConference on Empirical Methods in Natural Lan- guage Processing (EMNLP), 2014, pp. 1724–1734
2014
-
[30]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 30, 2017
2017
-
[31]
ProbTalk3D: Non- deterministic emotion controllable speech-driven 3d facial anima- tion synthesis using vq-vae,
S. Wu, K. I. Haque, and Z. Yumak, “ProbTalk3D: Non- deterministic emotion controllable speech-driven 3d facial anima- tion synthesis using vq-vae,” inACM SIGGRAPH Conference on Motion, Interaction, and Games. New York, NY , USA: Associ- ation for Computing Machinery, 2024
2024
-
[32]
EmoTalk: Speech-driven emotional disentanglement for 3d face animation,
Z. Peng, H. Wu, Z. Song, H. Xu, X. Zhu, J. He, H. Liu, and Z. Fan, “EmoTalk: Speech-driven emotional disentanglement for 3d face animation,” inIEEE/CVF International Conference on Computer Vision (ICCV), October 2023, pp. 20 687–20 697
2023
-
[33]
Emage: Towards unified holistic co-speech gesture generation via expressive masked audio gesture modeling,
H. Liu, Z. Zhu, G. Becherini, Y . Peng, M. Su, Y . Zhou, X. Zhe, N. Iwamoto, B. Zheng, and M. J. Black, “Emage: Towards unified holistic co-speech gesture generation via expressive masked audio gesture modeling,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 1144–1154
2024
-
[34]
ARKit face tracking and blendshape locations,
Apple Inc., “ARKit face tracking and blendshape locations,” https://developer.apple.com/arkit/, 2017, apple Developer Docu- mentation
2017
-
[35]
“Wild West
K. I. Haque, A. Pavlou, and Z. Yumak, ““Wild West” of evaluating speech-driven 3d facial animation synthesis: A benchmark study,” Computer Graphics Forum, vol. 44, no. 2, p. e70073, 2025
2025
-
[36]
Beyond fixed topologies: Unregistered training and comprehensive evaluation metrics for 3d talking heads,
F. Nocentini, T. Besnier, C. Ferrari, S. Arguill `ere, S. Berretti, and M. Daoudi, “Beyond fixed topologies: Unregistered training and comprehensive evaluation metrics for 3d talking heads,”CoRR, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.