SenseJudge: Human-Centric Preference-Driven Judgment Framework
Pith reviewed 2026-06-28 10:51 UTC · model grok-4.3
The pith
SenseJudge is a customizable framework that drives LLM judgments from diverse human preferences instead of fixed training data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
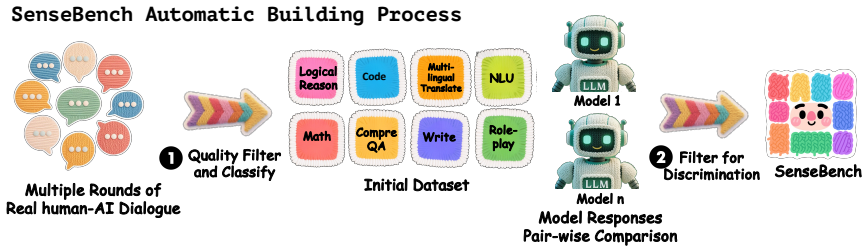
SenseJudge is a human-preference-driven customizable judgment framework, together with SenseBench derived from real-world multi-turn interactions; when applied to LLMs-as-personalized-judges and model-ranking tasks it surpasses other methods and aligns rankings with real human sense.
What carries the argument
SenseJudge framework that customizes judgments by incorporating user-specific preferences extracted from interactions.
Load-bearing premise
Existing judgment approaches often rely on trained judgers using fixed preference data, which tend to overlook diverse user preferences and struggle to adapt to real-world human-AI dialogue scenarios.
What would settle it
Run a fresh set of multi-turn dialogues with new human raters providing explicit preferences; if SenseJudge rankings and judgments no longer match the humans better than baselines or fixed-preference models, the central claim fails.
Figures

read the original abstract
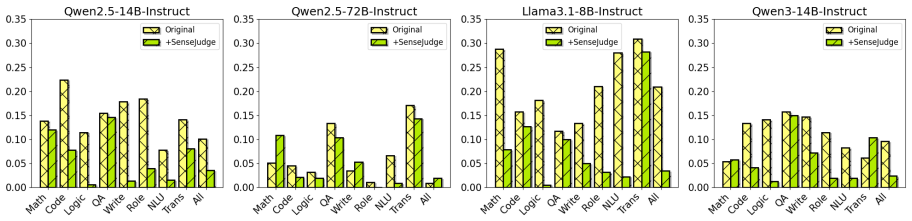
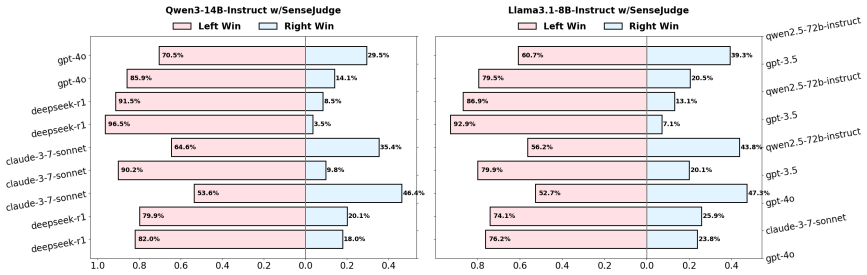
Large Language Models (LLMs) as judges across various scenarios such as assessing model responses is becoming an increasingly accepted paradigm. However, existing judgment approaches often rely on trained judgers using fixed preference data, which tend to overlook diverse user preferences and struggle to adapt to real-world human-AI dialogue scenarios. To address these limitations, we propose SenseJudge, a customizable judgment framework driven by human preferences and SenseBench, a diverse and challenging instruction-following benchmark derived from real-world multi-turn interactions. We applied the automatic judgment framework and benchmark to two tasks: (1) LLMs as personalized judges, and (2) model ranking. We conducted extensive experiments, and the results demonstrate that the SenseJudge framework surpasses other judgment methods and models in the LLMs-as-personalized-judges task and achieves model ranking that aligns with real human sense. Additionally, we conducted analyses on position bias and consistency, alongside ablation studies, which affirmed the robustness of SenseJudge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SenseJudge, a customizable judgment framework driven by human preferences, along with SenseBench, a benchmark derived from real-world multi-turn interactions. It evaluates the framework on two tasks—LLMs as personalized judges and model ranking—claiming via extensive experiments that SenseJudge outperforms other judgment methods and produces model rankings aligned with human sense, with additional analyses on position bias, consistency, and ablations supporting robustness.
Significance. If the empirical claims hold, the work would address a genuine limitation in current LLM-as-judge paradigms by moving beyond fixed preference data toward preference-driven customization, potentially improving adaptability in human-AI dialogue settings. The reported alignment between automated rankings and human sense would constitute a concrete, falsifiable contribution to evaluation methodology.
major comments (1)
- [Abstract] Abstract: the central performance claims (surpassing other methods in the personalized-judges task and achieving human-aligned model ranking) are stated without any accompanying methods details, dataset statistics, error bars, experimental design, or baseline descriptions, rendering the claims unverifiable from the provided manuscript.
Simulated Author's Rebuttal
We thank the referee for their feedback. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claims (surpassing other methods in the personalized-judges task and achieving human-aligned model ranking) are stated without any accompanying methods details, dataset statistics, error bars, experimental design, or baseline descriptions, rendering the claims unverifiable from the provided manuscript.
Authors: Abstracts are intentionally concise summaries and do not contain the full experimental details; this is standard practice. The complete manuscript supplies the requested information: the SenseJudge framework and human-preference mechanism are described in Section 3, SenseBench construction and dataset statistics appear in Section 4, the two evaluation tasks, baselines, experimental design, and results (with error bars where computed) are reported in Section 5 together with position-bias, consistency, and ablation analyses. The performance claims in the abstract are therefore directly supported by the body of the paper. If only the abstract was supplied to the referee, we are happy to provide the full manuscript. revision: no
Circularity Check
No significant circularity identified
full rationale
The paper proposes an empirical framework (SenseJudge) and benchmark (SenseBench) for LLM judgment tasks, then reports experimental results on personalization and model ranking. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described structure. Central claims rest on direct experimental comparisons rather than any chain that reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Xianzhe Fan, Qing Xiao, Xuhui Zhou, Jiaxin Pei, Maarten Sap, Zhicong Lu, and Hong Shen
Can llm be a personalized judge? Preprint, arXiv:2406.11657. Xianzhe Fan, Qing Xiao, Xuhui Zhou, Jiaxin Pei, Maarten Sap, Zhicong Lu, and Hong Shen. 2025. User-driven value alignment: Understanding users’ perceptions and strategies for addressing biased and discriminatory statements in ai companions . Preprint, arXiv:2409.00862. Aaron Grattafiori, Abhimany...
-
[2]
Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437. Humza Naveed, Asad Ullah Khan, Shi Qiu, Muham- mad Saqib, Saeed Anwar, Muhammad Usman, Naveed Akhtar, Nick Barnes, and Ajmal Mian
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
A Comprehensive Overview of Large Language Models
A comprehensive overview of large language models. Preprint, arXiv:2307.06435. Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Car- roll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, an...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Direct preference optimization: Y our lan- guage model is secretly a reward model . Preprint, arXiv:2305.18290. Zhaoxuan Tan, Qingkai Zeng, Yijun Tian, Zheyuan Liu, Bing Yin, and Meng Jiang. 2025. De- mocratizing large language models via person- alized parameter-efficient fine-tuning . Preprint, arXiv:2402.04401. Kimi Team, Angang Du, Bofei Gao, Bowei Xing...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
arXiv preprint arXiv:2411.00027 , year=
Personalization of large language models: A survey. Preprint, arXiv:2411.00027. Wenting Zhao, Xiang Ren, Jack Hessel, Claire Cardie, Y ejin Choi, and Y untian Deng. 2024. Wildchat: 1m chatgpt interaction logs in the wild . Preprint, arXiv:2405.01470. Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Tianle Li, Siyuan Zhuang, Zhanghao Wu, Y onghao Zhuang, Zhuohan...
-
[6]
Judgelm: Fine-tuned large language models are scalable judges.arXiv preprint arXiv:2310.17631, 2023
Judgelm: Fine-tuned large language models are scalable judges. arXiv preprint arXiv:2310.17631. Minjun Zhu, Yixuan Weng, Linyi Y ang, and Y ue Zhang. 2025. Personality alignment of large lan- guage models. Preprint, arXiv:2408.11779. A Appendix A.1 Discussion A.1.1 Details of SenseBench We provide the statistics of SenseBench in Ta- ble 5. We provide the ...
-
[7]
Score each of the two responses based on the user preferences
-
[8]
The final decision is Response A
Based on the scores obtained in the first step, determine which response is better. If Response A is better, output “The final decision is Response A.” If Response B is better, output “The final decision is Response B.” A.3 Preference Case Preference for math tasks extracted from the development set "Based on the comparison, the user’s persona demonstrates t...
-
[9]
They strongly value methodical reasoning that transparently explores multiple approaches and validates failures, prioritizing thorough cognitive processes over conventional solutions
-
[10]
They prefer responses that explicitly build verification frameworks and test edge cases, reject- ing shortcuts that lack demonstrated iterative refinement
-
[11]
They seek pedagogical clarity through structured decomposition of assumptions, showing aversion to answers that prioritize memorized conclusions over original analytical scaffolding. This persona prefers the Chosen Response for its stepwise validation of failed strategies and truth- table proofs, while rejecting the alternative for its faster-to-conclusio...
-
[12]
**Comprehensive Logical Reasoning:** They prefer answers that break down the scenario step-by-step, exploring potential starting points and logical implications, rather than stating a direct conclusion without thorough justification
-
[13]
**Acknowledgement of Edge Cases & Nuance:** They appreciate responses that explicitly consider edge cases (like being the first place initially) and contextual factors, showing awareness that real-world questions often have layers beyond the surface
-
[14]
**Structured and Explicit Answer Presentation:** They favor responses that clearly summa- rize the primary conclusion after presenting the reasoning, making the final answer distinct and easy to identify, rather than leaving it embedded within the explanation. They reject responses perceived as overly simplistic or lacking in explanatory depth.", "Based on...
-
[15]
They value analytical rigor and systematic problem-solving approaches, seeking responses that methodically break down constraints and explore multiple strategies rather than presenting isolated solutions without justification
-
[16]
They prefer responses that optimize for efficiency by testing different scenarios and validating the optimal solution, rejecting approaches that overlook practical time-saving tactics or introduce unnecessary steps
-
[17]
Filtered preference set obtained after selection
Their learning style prioritizes conceptual clarity over fragmented execution, favoring explana- tions that emphasize logical reasoning patterns applicable to similar challenges rather than ad-hoc step sequences.", "Based on the preferred response, the user values thorough, methodical explanations that explic- itly outline academic reasoning processes, in...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.