Event Ontology Expansion via LLM-Based Conceptualization
Pith reviewed 2026-06-26 14:52 UTC · model grok-4.3
The pith
LLM-generated concept names and descriptions improve event ontology expansion by enabling concept-level reasoning over contextualized triggers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
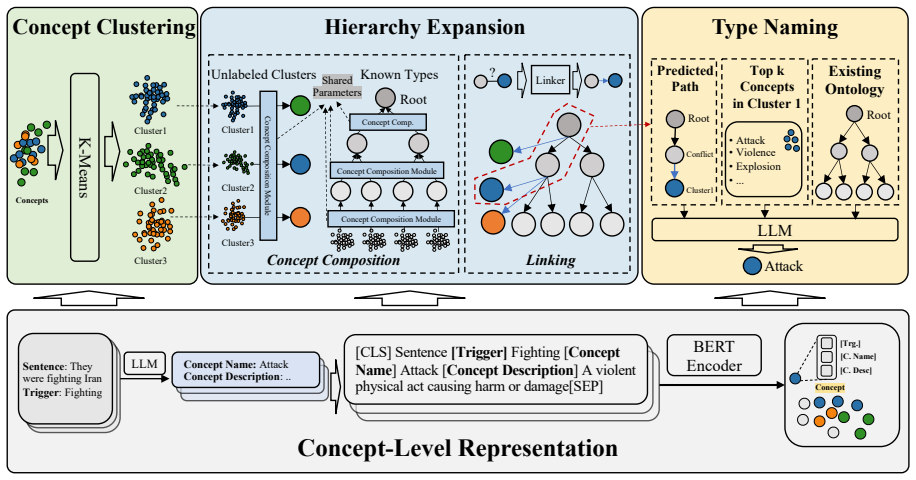
ConceptE first derives concept-level semantics by prompting an LLM with the sentence and event trigger to produce a concise concept name and natural-language description. It then jointly encodes these semantics with trigger information to build concept-enhanced representations aligned with ontology-level reasoning. This design supports more coherent event clustering, more reliable hierarchy expansion, and ontology-consistent type naming.
What carries the argument
LLM-based conceptualization step that produces a concept name and natural-language description to replace or augment contextualized trigger representations for clustering and hierarchy tasks.
If this is right
- Event clustering measured by BCubed-F1 becomes more coherent because concept names abstract away sentence-specific wording.
- Hierarchy expansion measured by Taxo_F1 becomes more reliable because the representations match the level at which ontology edges are defined.
- Induced event types receive names that remain consistent with the existing ontology vocabulary.
- The same joint encoding of concept and trigger information applies across the subtasks of clustering, hierarchy attachment, and naming.
Where Pith is reading between the lines
- The same LLM conceptualization step could be tested on entity or relation ontology expansion where instance representations also mix context with type semantics.
- If the gain comes from moving to concept-level text, similar prompting might help any task that must aggregate many surface mentions into a single abstract category.
- A direct follow-up would measure how often the LLM concept name matches an existing ontology node versus inventing a new label, to see whether naming consistency is the main driver of the Taxo_F1 lift.
Load-bearing premise
The LLM outputs for concept names and descriptions reliably reflect stable, ontology-aligned semantics rather than introducing their own noise or misalignment.
What would settle it
A controlled run on ACE, ERE, or MAVEN where representations built only from raw trigger embeddings produce higher BCubed-F1 or Taxo_F1 scores than the LLM-augmented versions.
Figures



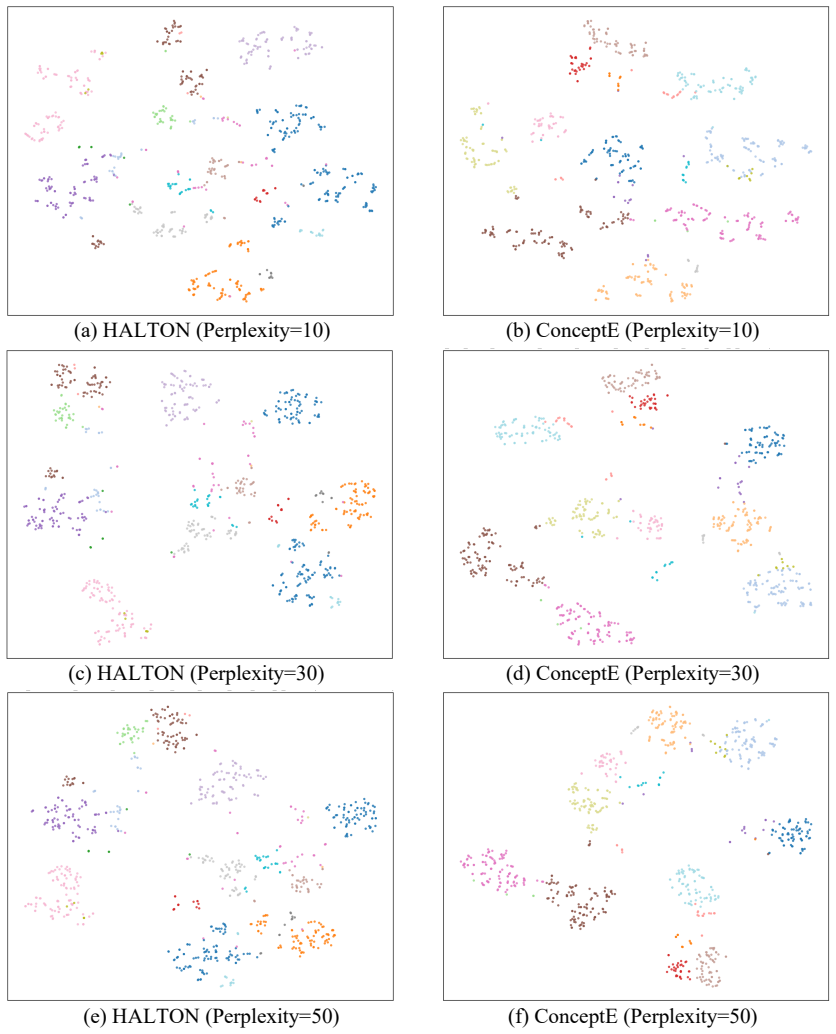
read the original abstract
Event ontology expansion aims to discover emerging event types from data and extend them to appropriate positions in the existing event ontology.. Existing methods typically cluster contextualized trigger representations and attach induced clusters to the ontology based on instance-level similarity. However, ontology expansion requires concept-level semantics that characterize event types, whereas contextualized trigger representations often conflate these semantics with surface contextual variation, leading to unstable clustering and unreliable hierarchy expansion. To address this issue, we propose ConceptE, a conceptualization-enhanced framework for event ontology expansion. ConceptE first derives concept-level semantics by prompting an LLM with the sentence and event trigger, producing a concise concept name and a natural-language description. It then jointly encodes these semantics with trigger information to build concept-enhanced representations aligned with ontology-level reasoning. This representation design supports more coherent event clustering, more reliable hierarchy expansion, and ontology-consistent type naming. Experiments on ACE, ERE, and MAVEN demonstrate that ConceptE consistently outperforms state-of-the-art approaches across all subtasks of event ontology expansion. In particular, it achieves improvements of up to 12.37\% in BCubed-F1 for event clustering and 6.48\% in Taxo\_F1 for hierarchy expansion, demonstrating the effectiveness of the proposed ConceptE method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ConceptE, an LLM-based framework for event ontology expansion. It generates concept names and natural-language descriptions from event triggers and sentences via prompting, jointly encodes them with trigger representations to produce concept-enhanced embeddings, and uses these for event clustering and hierarchy expansion. Experiments on ACE, ERE, and MAVEN report consistent outperformance over prior SOTA methods, with gains of up to 12.37% BCubed-F1 on clustering and 6.48% Taxo_F1 on hierarchy expansion.
Significance. If the central claim holds, the work offers a concrete mechanism for injecting concept-level semantics into event ontology tasks, addressing the instability of purely contextualized trigger representations. The multi-dataset evaluation and focus on both clustering and taxonomic attachment are positive features of the empirical design.
major comments (2)
- [Experiments (ACE/ERE/MAVEN results)] The abstract and method description state that LLM-generated concept names and descriptions supply ontology-aligned semantics that drive the reported gains, yet the experimental evaluation provides no ablation that holds the joint-encoding pipeline fixed while replacing the LLM outputs with non-semantic controls (random strings, template paraphrases, or trigger-only input). Without this isolation, the numeric improvements cannot be attributed specifically to conceptualization rather than richer input representations in general.
- [Method and Experiments] The paper claims the joint encoding produces representations 'aligned with ontology-level reasoning,' but reports no human evaluation or inter-annotator agreement on whether the LLM-generated concept names/descriptions are in fact more stable or ontology-consistent than the original triggers on the same instances used for the BCubed-F1 and Taxo_F1 measurements.
minor comments (1)
- [Abstract] The abstract does not name the specific LLM, prompting template, or temperature settings used for concept generation; these details are needed for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: The abstract and method description state that LLM-generated concept names and descriptions supply ontology-aligned semantics that drive the reported gains, yet the experimental evaluation provides no ablation that holds the joint-encoding pipeline fixed while replacing the LLM outputs with non-semantic controls (random strings, template paraphrases, or trigger-only input). Without this isolation, the numeric improvements cannot be attributed specifically to conceptualization rather than richer input representations in general.
Authors: We agree that an explicit ablation isolating the semantic contribution of the LLM outputs would strengthen attribution of the gains. In the revised manuscript we will add experiments that keep the joint-encoding pipeline fixed while replacing the LLM-generated concept names and descriptions with random strings, template paraphrases, and trigger-only inputs. These controls will help demonstrate that the observed improvements stem specifically from the conceptualization step rather than from richer input representations alone. revision: yes
-
Referee: The paper claims the joint encoding produces representations 'aligned with ontology-level reasoning,' but reports no human evaluation or inter-annotator agreement on whether the LLM-generated concept names/descriptions are in fact more stable or ontology-consistent than the original triggers on the same instances used for the BCubed-F1 and Taxo_F1 measurements.
Authors: We acknowledge that direct human evaluation with inter-annotator agreement would provide valuable corroboration of the ontology alignment and stability claims. Our current evidence rests on consistent quantitative gains across three datasets and two subtasks. In the revision we will add a qualitative analysis section with representative examples comparing LLM-generated concepts to original triggers, and we will explore the feasibility of a small-scale human study on a subset of instances; if resource constraints prevent a full IAA study, the qualitative examples will still be included. revision: partial
Circularity Check
No derivation chain present; empirical evaluation is self-contained.
full rationale
The paper presents a framework (ConceptE) that uses LLM prompting to generate concept names and descriptions, then jointly encodes them for clustering and hierarchy expansion. All claims rest on reported experimental metrics (BCubed-F1, Taxo_F1) across fixed datasets (ACE, ERE, MAVEN). No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The performance numbers are external measurements, not quantities defined by the method itself, so no reduction to inputs by construction occurs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Prompting an LLM with sentence and event trigger produces a concise concept name and natural-language description that capture concept-level semantics better than contextualized embeddings.
Reference graph
Works this paper leans on
-
[1]
InCOLING 1998 Volume 1: The 17th Inter- national Conference on Computational Linguistics
Entity-based cross-document coreferencing using the vector space model. InCOLING 1998 Volume 1: The 17th Inter- national Conference on Computational Linguistics. Pengfei Cao, Yupu Hao, Yubo Chen, Kang Liu, Jiexin Xu, Huaijun Li, Xiaojian Jiang, and Jun Zhao
1998
-
[2]
InProceedings of the 2023 Conference on Empirical Methods in Natural Lan- guage Processing, pages 306–320, Singapore
Event ontology completion with hierarchical struc- ture evolution networks. InProceedings of the 2023 Conference on Empirical Methods in Natural Lan- guage Processing, pages 306–320, Singapore. Asso- ciation for Computational Linguistics. David F Crouse
2023
-
[3]
BERT: Pre-training of deep bidirectional transformers for language under- standing. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Tech- nologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota. Association for Computational Linguistics. George ...
2019
-
[4]
InProceed- ings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 718–724, Online
Semi-supervised new event type induction and event detection. InProceed- ings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 718–724, Online. Association for Computational Lin- guistics. Lawrence Hubert and Phipps Arabie
2020
-
[5]
InProceedings of the 2021 Conference of the North American Chapter of the Association for Computa- tional Linguistics: Human Language Technologies, pages 894–908, Online
Document-level event argument extraction by conditional generation. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computa- tional Linguistics: Human Language Technologies, pages 894–908, Online. Association for Computa- tional Linguistics. Chin-Yew Lin
2021
-
[6]
InProceedings of The Web Conference 2020, WWW ’20, page 2044–2054, New York, NY , USA
Expanding taxonomies with im- plicit edge semantics. InProceedings of The Web Conference 2020, WWW ’20, page 2044–2054, New York, NY , USA. Association for Computing Machin- ery. Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu
2020
-
[7]
InProceed- ings of The Web Conference 2020, WWW ’20, page 486–497, New York, NY , USA
Tax- oexpan: Self-supervised taxonomy expansion with position-enhanced graph neural network. InProceed- ings of The Web Conference 2020, WWW ’20, page 486–497, New York, NY , USA. Association for Com- puting Machinery. Jiaming Shen, Yunyi Zhang, Heng Ji, and Jiawei Han
2020
-
[8]
InProceedings of the 2021 Conference on Em- pirical Methods in Natural Language Processing, pages 5427–5440, Online and Punta Cana, Domini- can Republic
Corpus-based open-domain event type induc- tion. InProceedings of the 2021 Conference on Em- pirical Methods in Natural Language Processing, pages 5427–5440, Online and Punta Cana, Domini- can Republic. Association for Computational Lin- guistics. Zhiyi Song, Ann Bies, Stephanie Strassel, Tom Riese, Justin Mott, Joe Ellis, Jonathan Wright, Seth Kulick, Ne...
2021
-
[9]
InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1652– 1671, Online
MA VEN: A Massive General Domain Event Detection Dataset. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1652– 1671, Online. Association for Computational Linguis- tics. Xindong Wu, Jia Wu, Xiaoyi Fu, Jiachen Li, Peng Zhou, and Xu Jiang
2020
-
[10]
In2019 IEEE International Conference on Data Mining (ICDM), pages 1540–1545
Automatic knowledge graph construction: A report on the 2019 icdm/icbk con- test. In2019 IEEE International Conference on Data Mining (ICDM), pages 1540–1545. Nan Xu, Hongming Zhang, and Jianshu Chen
2019
-
[11]
InFindings of the Association for Compu- tational Linguistics: EACL 2024, pages 946–964, St
CEO: Corpus-based open-domain event ontology in- duction. InFindings of the Association for Compu- tational Linguistics: EACL 2024, pages 946–964, St. Julian’s, Malta. Association for Computational Linguistics. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, and 1 others
2024
-
[12]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Presents the Qwen3 series, including dense and MoE mod- els, hybrid thinking mode, and the thinking budget mechanism. Yue Yu, Yinghao Li, Jiaming Shen, Hao Feng, Jimeng Sun, and Chao Zhang
-
[13]
InFindings of the Association for Computational Linguistics: ACL 2025, pages 4131–4144, Vienna, Austria
Code- Taxo: Enhancing taxonomy expansion with limited examples via code language prompts. InFindings of the Association for Computational Linguistics: ACL 2025, pages 4131–4144, Vienna, Austria. Associa- tion for Computational Linguistics. Tianyi Zhang*, Varsha Kishore*, Felix Wu*, Kilian Q. Weinberger, and Yoav Artzi
2025
-
[14]
InInternational Conference on Learning Representations
Bertscore: Eval- uating text generation with bert. InInternational Conference on Learning Representations. A Dataset Statistics Table 6 reports the split of known and unknown event types used in our experiments. Following HALTON (Cao et al., 2023), we simulate the real- istic ontology expansion scenario where only fre- quent event types are covered by the...
2023
-
[15]
We train the clustering module with Adam using a learning rate of 1×10 −4, batch size 64, and 60 epochs
Trigger spans and concept spans are pooled with max pool- ing. We train the clustering module with Adam using a learning rate of 1×10 −4, batch size 64, and 60 epochs. The supervised contrastive temper- ature is 0.07, and the center loss weight is 0.005. For unlabeled neighborhood mining, K= 2 for ACE and ERE and K= 15 for MA VEN. Thek- means pseudo label...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.