CD-RCM: Generalizable Continuous-Depth Novel View Synthesis for Reflectance Confocal Microscopy
Pith reviewed 2026-06-27 09:42 UTC · model grok-4.3
The pith
A feedforward network synthesizes realistic unseen depths from sparse RCM skin stacks to create isotropic 3D volumes without per-patient retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
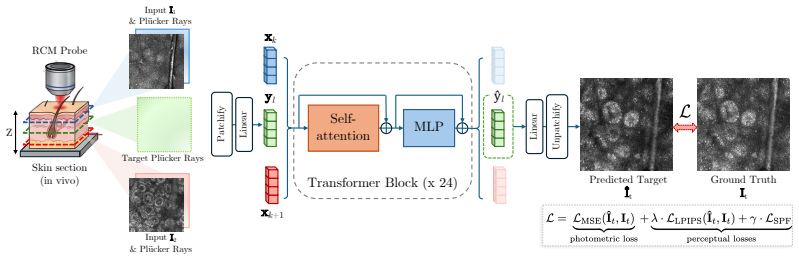
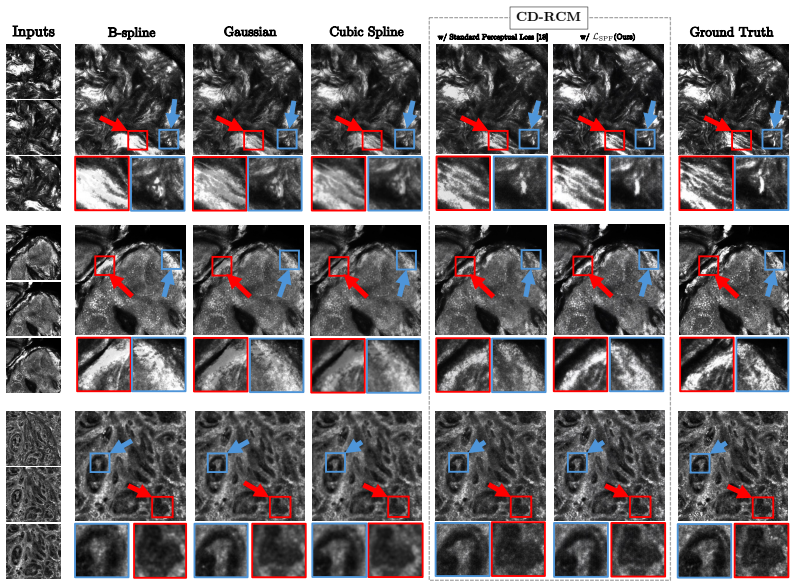
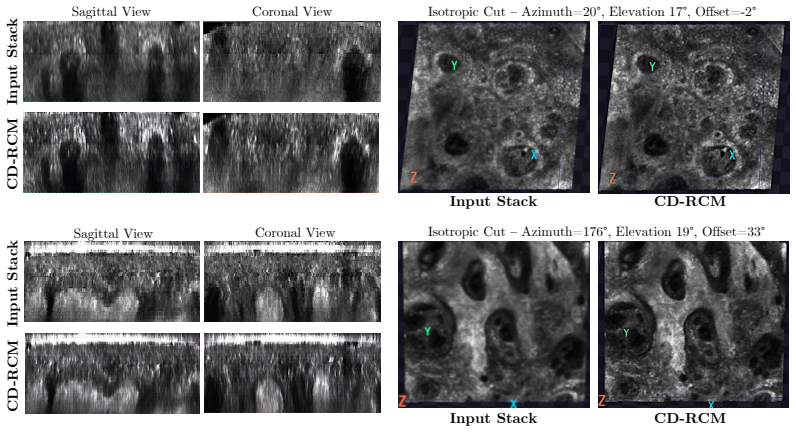
CD-RCM is a feedforward model that predicts realistic unseen depths from sparsely sampled RCM stacks by explicitly modeling the depth-resolved and occlusive nature of RCM imaging, enabling continuous-depth visualization and isotropic 3D volumes from en-face images while achieving sub-second inference without per-patient optimization.
What carries the argument
A feedforward neural network architecture trained to account for RCM's depth-resolved occlusive imaging physics, which predicts novel intermediate depths from sparse axial stacks.
If this is right
- The resulting volumes become isotropic, removing the sixfold difference between lateral and axial resolution.
- Arbitrary-direction sectioning becomes possible, including histopathology-like cross-sections.
- Novel-view synthesis runs in sub-second time on standard hardware.
- No per-patient optimization is required once the network is trained on representative data.
Where Pith is reading between the lines
- The same depth-resolved occlusion modeling might apply to other optical sectioning techniques that acquire en-face planes at successive depths.
- Clinical workflows could shift from dense axial sampling to sparser stacks followed by synthesis, reducing total acquisition time.
- If the synthesized depths preserve cellular detail, they could support quantitative measurements such as cell counting or layer thickness across continuous depths.
Load-bearing premise
A single network trained on RCM data will generalize to new patients and produce accurate interpolations without per-patient optimization.
What would settle it
Test CD-RCM on RCM stacks from patients held out from training, synthesize depths at locations where real images were acquired, and measure reconstruction error; high error rates would show the generalization fails.
Figures
read the original abstract
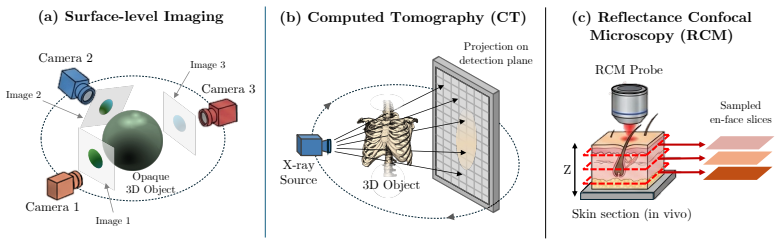
Reflectance confocal microscopy (RCM) provides noninvasive, cellular-resolution "optical biopsies" of human skin \emph{in vivo} by acquiring en-face images at successive depths, forming a sparse z-stack. Due to optical limitations, these stacks are anisotropic 3D volumes with lateral resolution (0.5 $\mu$m) $\sim$6 times higher compared to axial resolution, which is defined by the optical sectioning (3 $\mu$m), limiting the interpretation of tissue. Our goal is to provide continuous-depth visualization by interpolating intermediate sections and making the 3D volume isotropic. Such a representation permits arbitrary-direction sectioning, including histopathology-like cross-sectional examination, without requiring per-patient optimization. To that end, we introduce the first RCM-specific novel-view synthesis (NVS) approach, CD-RCM, a feedforward model that predicts realistic, unseen depths from sparsely sampled RCM stacks. Classical neural rendering methods focus on reconstruction from surface-level multi-view observations. In contrast to surface-level camera views, RCM can acquire optically sectioned en-face images of tissue beyond the surface up to 200 $\mu$m. However, during visualization of the RCM stacks, observations of the shallower sections (towards the surface) obscure the deeper ones. This unique axial imaging geometry and layer-dependent anatomical organization motivated our development of a tailored architectural and training framework that explicitly accounts for RCM's depth-resolved, occlusive imaging physics. Experiments demonstrate that CD-RCM achieves high-fidelity novel-view synthesis with sub-second inference time.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CD-RCM, the first RCM-specific novel-view synthesis method: a feedforward network that interpolates unseen depths in sparse RCM z-stacks to produce continuous, isotropic 3D volumes. It explicitly models the depth-resolved occlusive axial imaging physics of RCM (en-face sections up to 200 μm) rather than surface multi-view geometry, enabling arbitrary-direction sectioning without per-patient optimization and claiming high-fidelity results at sub-second inference time.
Significance. If the generalization and fidelity claims hold, the work would provide a practical tool for converting anisotropic RCM stacks into histopathology-like cross-sections, improving in-vivo tissue interpretation in dermatology. The feedforward design and explicit handling of RCM occlusion are notable strengths for clinical deployment; the absence of per-patient fine-tuning distinguishes it from typical neural rendering pipelines.
major comments (2)
- [Abstract] Abstract: the statement that 'experiments demonstrate that CD-RCM achieves high-fidelity novel-view synthesis' supplies no datasets, quantitative metrics, baselines, patient counts, or error analysis, leaving the central empirical claim without visible support.
- [Abstract] Abstract: the title and abstract assert generalizability to new patients without per-patient optimization, yet no information is given on the number of patients, skin-type/pigmentation diversity, layer-thickness variation, or whether evaluation used patient-wise hold-out splits (versus intra-patient splits); this directly affects whether the training distribution captures the claimed anatomical and optical variations.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that additional details would strengthen the presentation of our claims and will revise the abstract accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the statement that 'experiments demonstrate that CD-RCM achieves high-fidelity novel-view synthesis' supplies no datasets, quantitative metrics, baselines, patient counts, or error analysis, leaving the central empirical claim without visible support.
Authors: We agree that the abstract does not include these supporting details. The manuscript body reports the full experimental protocol, including the RCM datasets, quantitative metrics, baselines, and error analysis. We will revise the abstract to add a concise clause summarizing the evaluation setup and key fidelity results. revision: yes
-
Referee: [Abstract] Abstract: the title and abstract assert generalizability to new patients without per-patient optimization, yet no information is given on the number of patients, skin-type/pigmentation diversity, layer-thickness variation, or whether evaluation used patient-wise hold-out splits (versus intra-patient splits); this directly affects whether the training distribution captures the claimed anatomical and optical variations.
Authors: We agree that the abstract omits these dataset characteristics. The manuscript uses patient-wise hold-out evaluation on a multi-patient cohort that includes variation in skin types and layer thicknesses. We will revise the abstract to briefly note the patient cohort size, diversity considerations, and patient-wise splits to better support the generalizability claim. revision: yes
Circularity Check
No significant circularity; empirical feedforward model is self-contained
full rationale
The paper introduces CD-RCM as a neural network architecture trained on RCM stacks to perform novel-view synthesis, with claims resting on empirical training and held-out evaluation rather than any closed mathematical derivation. No equations reduce a prediction to a fitted input by construction, no self-citations serve as load-bearing uniqueness theorems, and no ansatzes are smuggled via prior work. The central generalization claim is presented as an empirical result evaluated on data, not a definitional identity, making the derivation chain independent of its own outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A feedforward neural network trained on RCM stacks will generalize across patients without per-patient optimization.
Reference graph
Works this paper leans on
-
[1]
Training Deep Nets with Sublinear Memory Cost
Tianqi Chen, Bing Xu, Chiyuan Zhang, and Carlos Guestrin. Training deep nets with sublinear memory cost.arXiv preprint arXiv:1604.06174,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Alex Henry, Prudhvi Raj Dachapally, Shubham Shantaram Pawar, and Yuxuan Chen
doi: 10.3109/9780203091562. Alex Henry, Prudhvi Raj Dachapally, Shubham Shantaram Pawar, and Yuxuan Chen. Query-key normalization for transformers. InFindings of the Association for Computational Linguistics: EMNLP 2020, pages 4246–4253,
-
[3]
ISSN 0022-202X. doi: https://doi. org/10.1046/j.0022-202x.2001.01337.x. URL https://www.sciencedirect.com/science/ article/pii/S0022202X15412552. Tooba Imtiaz, Lucy Chai, Kathryn Heal, Xuan Luo, Jungyeon Park, Jennifer Dy, and John Flynn. Lvt: Large-scale scene reconstruction via local view transformers. InProceedings of the SIGGRAPH Asia 2025 Conference ...
-
[4]
ISSN 2075-1729. doi: 10.3390/life13122268. URL https: //www.mdpi.com/2075-1729/13/12/2268. Thomas Martin Lehmann, Claudia Gonner, and Klaus Spitzer. Survey: Interpolation methods in medical image processing.IEEE transactions on medical imaging, 18(11):1049–1075,
-
[5]
Liu, Adam K
Jonathan T.C. Liu, Adam K. Glaser, Chetan Poudel, and Joshua C. Vaughan. Nondestructive 3d pathology with light-sheet fluorescence microscopy for translational research and clinical assays.Annual Review of Analytical Chemistry, 16(V olume 16, 2023):231–252,
2023
-
[6]
Decoupled Weight Decay Regularization
ISSN 1936-1335. doi: https://doi.org/10.1146/annurev-anchem-091222-092734. URL https://www. annualreviews.org/content/journals/10.1146/annurev-anchem-091222-092734. Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1146/annurev-anchem-091222-092734 1936
-
[7]
URL https://onlinelibrary.wiley.com/doi/abs/10.1002/lsm.22600
doi: https://doi.org/10.1002/lsm.22600. URL https://onlinelibrary.wiley.com/doi/abs/10.1002/lsm.22600. N. A. Richarz, A. Boada, A. Jaka, J. Bassas, C. Ferrándiz, J. M. Carrascosa, and O. Yélamos. Challenges for new adopters in pre-surgical margin assessment by handheld reflectance confocal microscope of basal cell carcinoma: A prospective single-center st...
-
[8]
doi: 10.5826/dpc.1204a162. Johannes Schindelin, Ignacio Arganda-Carreras, Erwin Frise, Verena Kaynig, Mark Longair, Tobias Pietzsch, Stephan Preibisch, Curtis Rueden, Stephan Saalfeld, Benjamin Schmid, et al. Fiji: an open-source platform for biological-image analysis.Nature methods, 9(7):676–682,
-
[9]
Oriane Siméoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, et al. Dinov3.arXiv preprint arXiv:2508.10104,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
doi: https://doi.org/10
ISSN 0092-8674. doi: https://doi.org/10. 1016/j.cell.2024.03.035. URL https://www.sciencedirect.com/science/article/pii/ S0092867424003519. Monika Wojarska, Klaudia Kokot, Paulina Bernecka, Natalia Doma´nska, Agata Libik, Dana Bunevich, Dominika Nowakowska, Magdalena Dzido, Wiktoria Borzyszkowska, Wojciech Kazimierczak, and Jerzy Jankau. In vivo confocal ...
2024
-
[11]
doi: 10.3390/ jcm14165779
ISSN 2077-0383. doi: 10.3390/ jcm14165779. URLhttps://www.mdpi.com/2077-0383/14/16/5779. Ruyi Zha, Tao Jun Lin, Yuanhao Cai, Jiwen Cao, Yanhao Zhang, and Hongdong Li. R2-gaussian: Rectifying radiative gaussian splatting for tomographic reconstruction. InAdvances in Neural Information Processing Systems (NeurIPS),
2077
-
[12]
We employ a cosine learning rate schedule with linear warmup, using 2000 warmup steps and a peak learning rate of 4×10 −4 for both training resolutions
with β1 = 0.9, β2 = 0.95, and a weight decay of 0.05 applied to all parameters except LayerNorm layers. We employ a cosine learning rate schedule with linear warmup, using 2000 warmup steps and a peak learning rate of 4×10 −4 for both training resolutions. The loss weights in Eq. 12 are set to λ= 0.5 and γ= 0.05 . The full model has 170.8M trainable param...
2000
-
[13]
[2016], and mixed-precision training with BF16 data type
within the attention blocks, gradient checkpointing Chen et al. [2016], and mixed-precision training with BF16 data type. B Baselines Methods We adopt three well-established classical interpolation techniques widely adopted for processing medical imaging data as the baselines in our experiments Enjilela et al. [2019], Lehmann et al. [2002]. Note that simp...
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.