AGE: Adaptive-masking for Graph Embedding in Graph Retrieval-Augmented Generation
Pith reviewed 2026-07-02 17:58 UTC · model grok-4.3
The pith
AGE aligns graph and text embeddings via adaptive masking that skips key nodes in self-supervised training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
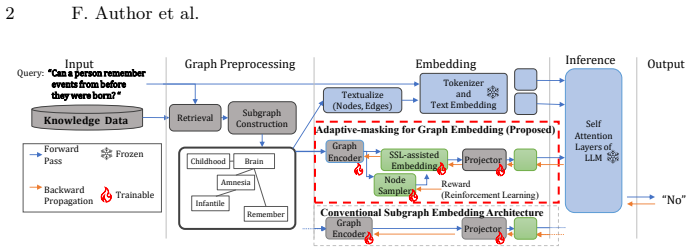
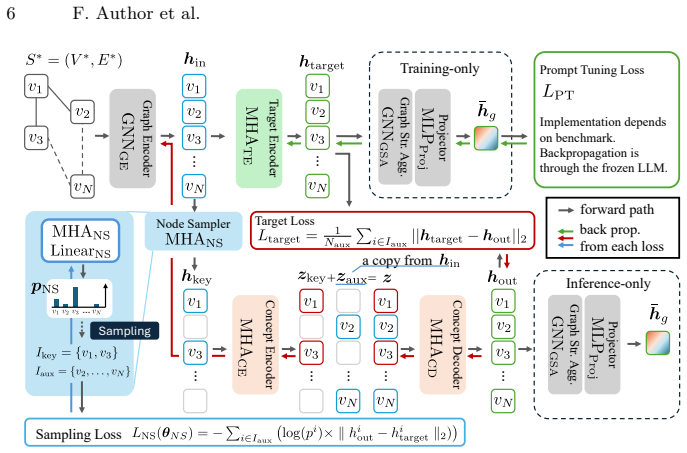
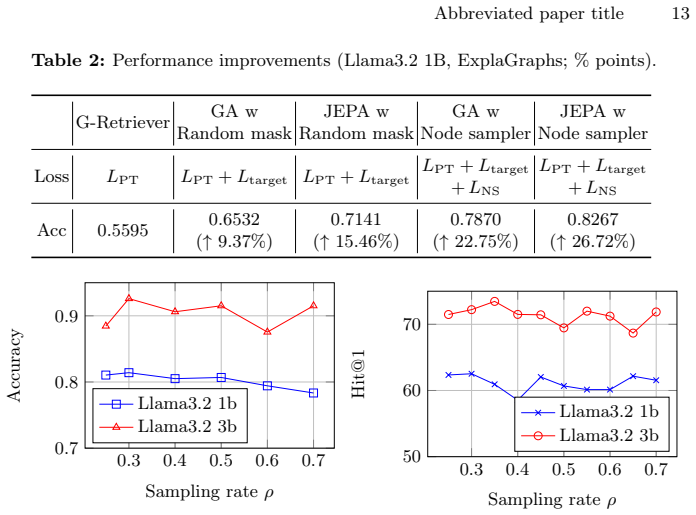
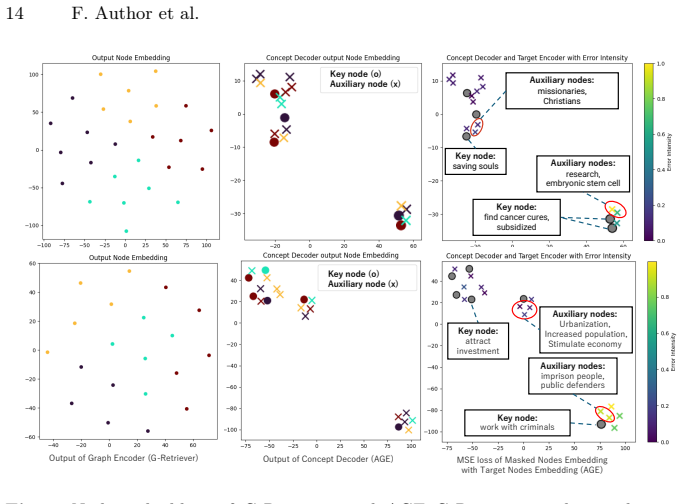
AGE employs a Transformer in a mask-based self-supervised learning approach designed to match text embedding encoders, with a learnable node sampler that focuses prediction on nodes apart from key nodes holding dominant contextual information, yielding graph embeddings that reduce latent feature misalignment and improve accuracy in GraphQA tasks.
What carries the argument
The learnable node sampler that selects non-key nodes for masking in the SSL objective.
If this is right
- Non-parametric search components in GraphRAG achieve higher accuracy on GraphQA tasks.
- The method works across four benchmark datasets with distinct characteristics.
- Graph embeddings become usable with frozen LLMs without additional fine-tuning of the language model.
- Self-supervised signals from non-key nodes suffice to close the latent space gap.
Where Pith is reading between the lines
- The approach could extend to other structured data modalities that also contain a small set of high-information elements.
- If the sampler generalizes, it might reduce the need for hand-crafted masking strategies in graph SSL.
- Performance gains may compound when AGE embeddings are combined with parametric retrieval methods.
Load-bearing premise
Misalignment between graph and text encoders is the core bottleneck, and a learnable sampler can avoid key nodes without introducing sampling bias or overfitting.
What would settle it
Running the four GraphQA benchmarks with AGE embeddings inserted into the non-parametric search component and finding no accuracy gain over the same baselines without AGE.
Figures
read the original abstract
GraphRAG is an extension of retrieval-augmented generation (RAG) that supports large language models (LLMs) by referring to graph-structured data as external knowledge. While this technique ideally captures intricate relationships, it often struggles with graph representations for LLMs, particularly for frozen LLMs, due to the misalignment between graph-based and text-based latent features. We tackle this issue by introducing the {\it Adaptive-masking for Graph Embedding (AGE)}. AGE employs a Transformer in a mask-based self-supervised learning (SSL) approach. We designed the architecture similar to text embedding encoders, addressing the latent feature misalignment. In contrast to natural language texts, graphs are concise representations, and there exist {\it key nodes} that hold dominant contextual information, which are challenging to predict from their surroundings. Masking such key nodes leads to inefficiency in the SSL process. Therefore, AGE focuses on predicting nodes apart from key nodes, utilizing a learnable node sampler. Our experimental results indicate that AGE significantly improves approaches using non-parametric search component in GraphQA tasks, achieving superior accuracy across four benchmark datasets with distinct characteristics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents AGE (Adaptive-masking for Graph Embedding), a method to improve graph embeddings for GraphRAG by using a Transformer in mask-based SSL. It employs a learnable node sampler to avoid masking key nodes that hold dominant contextual information, aiming to address misalignment between graph and text latent features. The authors report that this approach significantly improves accuracy on GraphQA tasks across four benchmark datasets with distinct characteristics.
Significance. If validated, AGE could offer a practical way to enhance non-parametric search in GraphRAG by producing better aligned graph embeddings. The idea of adaptive masking to handle key nodes in graphs is a reasonable response to the differences between graph and text structures. However, the lack of detailed experimental evidence, ablations, and method specifics in the manuscript makes it challenging to determine the true significance or generalizability of the results.
major comments (2)
- [Abstract] Abstract: The claim that AGE achieves superior accuracy across four benchmark datasets is not supported by any reported baselines, metrics, error bars, dataset details, or ablation studies, which is load-bearing for the central experimental claim.
- [Method] Method description of learnable node sampler: No mechanism, loss terms, regularization, or training procedure is provided for the sampler, leaving open whether it avoids sampling bias or produces effective SSL signals; this is load-bearing because the sampler's selective avoidance of key nodes is presented as the key fix for latent misalignment.
minor comments (1)
- [Abstract] Abstract: The phrase 'non-parametric search component' is used without definition or citation, reducing clarity for readers.
Simulated Author's Rebuttal
We appreciate the referee's constructive feedback on our manuscript. Below, we provide point-by-point responses to the major comments and outline the revisions we plan to make.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that AGE achieves superior accuracy across four benchmark datasets is not supported by any reported baselines, metrics, error bars, dataset details, or ablation studies, which is load-bearing for the central experimental claim.
Authors: We thank the referee for pointing this out. The abstract is intended as a high-level overview, and the detailed experimental results—including baselines, metrics, error bars, dataset details, and ablation studies—are presented in the Experiments section of the manuscript. To strengthen the abstract, we will revise it to briefly mention the key performance improvements and the four datasets used. We will also ensure that the experimental section explicitly highlights these elements for clarity. revision: yes
-
Referee: [Method] Method description of learnable node sampler: No mechanism, loss terms, regularization, or training procedure is provided for the sampler, leaving open whether it avoids sampling bias or produces effective SSL signals; this is load-bearing because the sampler's selective avoidance of key nodes is presented as the key fix for latent misalignment.
Authors: We agree that additional details on the learnable node sampler are necessary. In the revised version, we will expand the method section to include: the mechanism (a neural network that scores nodes based on their contextual importance to decide masking probability), the loss terms (the primary SSL reconstruction loss combined with a regularization term to encourage diversity in sampling and avoid over-focusing on non-key nodes), and the training procedure (joint optimization with the Transformer encoder using gradient descent). This will demonstrate how the sampler avoids sampling bias and generates effective self-supervised signals. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The abstract and provided text describe AGE as an independent architectural design: a Transformer-based masked SSL setup with a learnable node sampler that avoids key nodes to address latent misalignment between graph and text encoders. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains are shown that would reduce the claimed improvements or the sampler's effect to the inputs by construction. The method is presented as a self-contained choice validated on four external benchmarks, with no load-bearing steps that collapse to self-definition or prior author work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
AI, M.: Llama 3.2 connect 2024: Vision and edge for mobile devices (2024)
2024
-
[2]
Technical Re- port (2023),https : / / www - cdn
Anthropic: Model card and evaluations for claude models. Technical Re- port (2023),https : / / www - cdn . anthropic . com / files / 4zrzovbb / website / bd2a28d2535bfb0494cc8e2a3bf135d2e7523226.pdf
2023
-
[3]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Assran, M., Duval, Q., Misra, I., Bojanowski, P., Vincent, P., Rabbat, M., LeCun, Y., Ballas, N.: Self-supervised learning from images with a joint-embedding pre- dictive architecture. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 15619–15629 (June 2023)
2023
-
[4]
Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, and Michael Auli
Baevski, A., Hsu, W.N., Xu, Q., Babu, A., Gu, J., Auli, M.: data2vec: A gen- eral framework for self-supervised learning in speech, vision and language. arXiv preprint arXiv:2202.03555 (2022)
-
[5]
Author et al
Bardes, A., Garrido, Q., Ponce, J., Chen, X., Rabbat, M., LeCun, Y., Assran, M., Ballas, N.: Revisiting feature prediction for learning visual representations from video (2024) 16 F. Author et al
2024
-
[6]
VICReg: Variance-Invariance-Covariance Regularization for Self-Supervised Learning
Bardes, A., Ponce, J., LeCun, Y.: Vicreg: Variance-invariance-covariance regular- ization for self-supervised learning. arXiv preprint arXiv:2105.04906 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
Mathematical Programming pp
Bienstock, D., Goemans, M.X., Simchi-Levi, D., Williamson, D.: A note on the prize collecting traveling salesman problem. Mathematical Programming pp. 413– 420 (1993)
1993
-
[8]
Master’s thesis, ETH Zurich (2024),https://mds.inf
Bizeul, A.: Masking Principal Components for Discriminative Self-Supervised Rep- resentation Learning. Master’s thesis, ETH Zurich (2024),https://mds.inf. ethz.ch/fileadmin/user_upload/principal_component_masking_for_self_ supervised_learning.pdf
2024
-
[9]
arXiv preprint arXiv:2411.05844 (2025)
Cao, Y., Gao, Z., Li, Z., Xie, X., Zhou, K., Xu, J.: Lego-graphrag: Modularizing graph-based retrieval-augmented generation for design space exploration. arXiv preprint arXiv:2411.05844 (2025)
-
[10]
arXiv preprint arXiv:2006.09882 (2020)
Caron, M., Misra, I., Mairal, J., Goyal, P., Bojanowski, P., Joulin, A.: Unsuper- vised learning of visual features by contrasting cluster assignments. arXiv preprint arXiv:2006.09882 (2020)
-
[11]
In: The Thirteenth International Conference on Learning Represen- tations (2025)
Chen, D., Hu, J., Wei, X., Wu, E.: Denoising with a joint-embedding predictive architecture. In: The Thirteenth International Conference on Learning Represen- tations (2025)
2025
-
[12]
arXiv preprint arXiv:2410.23875 (2024)
Chen,L.,Tong,P.,Jin,Z.,Sun,Y.,Ye,J.,Xiong,H.:Plan-on-graph:Self-correcting adaptive planning of large language model on knowledge graphs. arXiv preprint arXiv:2410.23875 (2024)
-
[13]
arXiv preprint arXiv:2402.08170 (2024)
Chen, R., Zhao, T., Jaiswal, A., Shah, N., Wang, Z.: Llaga: Large language and graph assistant. arXiv preprint arXiv:2402.08170 (2024)
-
[14]
In: International Conference on Learning Representations (ICLR) (2022)
Chien, E., Chang, W.C., Hsieh, C.J., Yu, H.F., Zhang, J., Milenkovic, O., Dhillon, I.S.: Node feature extraction by self-supervised multi-scale neighborhood predic- tion. In: International Conference on Learning Representations (ICLR) (2022)
2022
-
[15]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)
Chin, Z.Y., Jiang, C.M., Huang, C.C., Chen, P.Y., Chiu, W.C.: Masking improves contrastive self-supervised learning for convnets, and saliency tells you where. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). pp. 2761–2770 (2024)
2024
-
[16]
Imaging Neuroscience2, 1–22 (2024)
Cox, C.R., Rogers, T.T., Shimotake, A., Kikuchi: Representational similarity learn- ing reveals a graded multidimensional semantic space in the human anterior tem- poral cortex. Imaging Neuroscience2, 1–22 (2024)
2024
-
[17]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Devlin,J.,Chang,M.W.,Lee,K.,Toutanova,K.:Bert:Pre-trainingofdeepbidirec- tional transformers for language understanding. arXiv preprint arXiv:1810.04805 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[18]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
Edge, D., Trinh, H., Cheng, N., Bradley, J., Chao, A., Mody, A., Truitt, S., Metropolitansky, D., Ness, R.O., Larson, J.: From local to global: A graph rag approach to query-focused summarization. arXiv preprint arXiv:2404.16130 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
In: Proceedings of the Annual Meeting of the Cognitive Science Society (2019)
Edmonds, M., Qi, S., Zhu, Y., Kubricht, J., Zhu, S.C., Lu, H.: Decomposing human causal learning: Bottom-up associative learning and top-down schema reasoning. In: Proceedings of the Annual Meeting of the Cognitive Science Society (2019)
2019
-
[20]
arXiv preprint arXiv:2405.06211 (2024)
Fan, W., Ding, Y., Ning, L., Wang, S., Li, H., Yin, D., Chua, T.S., Li, Q.: A survey on rag meeting llms: Towards retrieval-augmented large language models. arXiv preprint arXiv:2405.06211 (2024)
-
[21]
In: The Twelfth International Conference on Learning Represen- tations (2024)
Fatemi, B., Halcrow, J., Perozzi, B.: Talk like a graph: Encoding graphs for large language models. In: The Twelfth International Conference on Learning Represen- tations (2024)
2024
-
[22]
arXiv preprint arXiv:2311.15830 (2023) Abbreviated paper title 17
Fei, Z., Fan, M., Huang, J.: A-jepa: Joint-embedding predictive architecture can listen. arXiv preprint arXiv:2311.15830 (2023) Abbreviated paper title 17
-
[23]
Retrieval-Augmented Generation for Large Language Models: A Survey
Gao, Y., Xiong, Y., Gao, X., Jia, K., Pan, J., Bi, Y., Dai, Y., Sun, J., Wang, M., Wang, H.: Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv:2312.10997 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Grattafiori, A., Dubey, A., Abhinav Jauhri, .: The llama 3 herd of models (2024)
2024
- [25]
-
[26]
arXiv preprint arXiv:2305.15066 (2023)
Guo, J., Du, L., Liu, H., Zhou, M., He, X., Han, S.: Gpt4graph: Can large language modelsunderstandgraphstructureddata?anempiricalevaluationandbenchmark- ing. arXiv preprint arXiv:2305.15066 (2023)
-
[27]
arXiv preprint arXiv:2503.13804 (2025)
Guo, K., Shomer, H., Zeng, S., Han, H., Wang, Y., Tang, J.: Empowering graphrag with knowledge filtering and integration. arXiv preprint arXiv:2503.13804 (2025)
-
[28]
graphrag: A systematic evaluation and key insights
Han, H., Shomer, H., Wang, Y., Lei, Y., Guo, K., Hua, Z., Long, B., Liu, H., Tang, J.: Rag vs. graphrag: A systematic evaluation and key insights. arXiv preprint arXiv:2502.11371 (2025)
-
[29]
Retrieval-Augmented Generation with Graphs (GraphRAG)
Han,H.,Wang,Y.,Shomer,H.,Guo,K.,Ding,J.,Lei,Y.,Halappanavar,M.,Rossi, R.A.,Mukherjee,S.,Tang,X.,He,Q.,Hua,Z.,Long,B.,Zhao,T.,Shah,N.,Javari, A., Xia, Y., Tang, J.: Retrieval-augmented generation with graphs (graphrag). arXiv preprint arXiv:2501.00309 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
In: Proceed- ings of the 14th ACM International Conference on Web Search and Data Mining
He, G., Lan, Y., Jiang, J., Zhao, W.X., Wen, J.R.: Improving multi-hop knowledge base question answering by learning intermediate supervision signals. In: Proceed- ings of the 14th ACM International Conference on Web Search and Data Mining. p. 553 561. WSDM ’21, Association for Computing Machinery (2021)
2021
-
[31]
Masked Autoencoders Are Scalable Vision Learners
He, K., Chen, X., Xie, S., Li, Y., Dollár, P., Girshick, R.: Masked autoencoders are scalable vision learners. arXiv:2111.06377 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[32]
CoRR (2024)
He, X., Tian, Y., Sun, Y., Chawla, N.V., Laurent, T., LeCun, Y., Bresson, X., Hooi, B.: G-retriever: Retrieval-augmented generation for textual graph understanding and question answering. CoRR (2024)
2024
-
[33]
In: Proceedings of the ACM Web Conference 2023
Hou, Z., He, Y., Cen, Y., Liu, X., Dong, Y., Kharlamov, E., Tang, J.: Graphmae2: A decoding-enhanced masked self-supervised graph learner. In: Proceedings of the ACM Web Conference 2023. pp. 737–746 (2023)
2023
-
[34]
In: Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining
Hou, Z., Liu, X., Cen, Y., Dong, Y., Yang, H., Wang, C., Tang, J.: Graphmae: Self- supervised masked graph autoencoders. In: Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. pp. 594–604 (2022)
2022
-
[35]
LoRA: Low-Rank Adaptation of Large Language Models
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W.: Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[36]
arXiv preprint arXiv:2405.16506 (2024)
Hu, Y., Lei, Z., Zhang, Z., Pan, B., Ling, C., Zhao, L.: Grag: Graph retrieval- augmented generation. arXiv preprint arXiv:2405.16506 (2024)
-
[37]
arXiv preprint arXiv:2309.16595 (2023)
Huang,J.,Zhang,X.,Mei,Q.,Ma,J.:Canllmseffectivelyleveragegraphstructural information: when and why. arXiv preprint arXiv:2309.16595 (2023)
-
[38]
In: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition
Hudson, D.A., Manning, C.D.: Gqa: A new dataset for real-world visual reasoning and compositional question answering. In: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition. pp. 6700–6709 (2019)
2019
-
[39]
NeuroImage170, 385–399 (2018)
Jackson, R.L., Bajada, C.J., Rice, G.E., Cloutman, L.L., Lambon Ralph, M.A.: An emergent functional parcellation of the temporal cortex. NeuroImage170, 385–399 (2018)
2018
-
[40]
arXiv preprint arXiv:2410.10743 (2024) 18 F
Ji, Y., Liu, C., Chen, X., Ding, Y., Luo, D., Li, M., Lin, W., Lu, H.: Nt-llm: A novel node tokenizer for integrating graph structure into large language models. arXiv preprint arXiv:2410.10743 (2024) 18 F. Author et al
-
[41]
arXiv preprint arXiv:2404.07103 (2024)
Jin, B., Xie, C., Zhang, J., Roy, K.K., Zhang, Y., Li, Z., Li, R., Tang, X., Wang, S., Meng, Y., Han, J.: Graph chain-of-thought: Augmenting large language models by reasoning on graphs. arXiv preprint arXiv:2404.07103 (2024)
-
[42]
arXiv preprint arXiv:2110.09348 (2021)
Jing, L., Vincent, P., LeCun, Y., Tian, Y.: Understanding dimensional collapse in contrastive self-supervised learning. arXiv preprint arXiv:2110.09348 (2021)
-
[43]
Kipf, T.N., Welling, M.: Semi-supervised classification with graph convolutional networks (2016)
2016
-
[44]
In: Dimensionality Reduction with Unsuper- vised Nearest Neighbors, Intelligent Systems Reference Library, vol
Kramer, O.: K-nearest neighbors. In: Dimensionality Reduction with Unsuper- vised Nearest Neighbors, Intelligent Systems Reference Library, vol. 51, pp. 13–23. Springer, Berlin, Heidelberg (2013)
2013
-
[45]
LeCun, Y., Courant: A path towards autonomous machine intelligence version 0.9.2, 2022-06-27 (2022)
2022
-
[46]
arXiv preprint arXiv:2503.08203 (2025)
Lee, C., Oh, J., Lee, K., yong Sohn, J.: A theoretical framework for preventing class collapse in supervised contrastive learning. arXiv preprint arXiv:2503.08203 (2025)
-
[47]
arXiv preprint arXiv:2402.04978 (2024)
Li, Y., Zhang, R., Liu, J.: An enhanced prompt-based llm reasoning scheme via knowledge graph-integrated collaboration. arXiv preprint arXiv:2402.04978 (2024)
-
[48]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L., Stoyanov, V.: Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[49]
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization (2017)
2017
-
[50]
arXiv preprint arXiv:2310.01061 (2024)
Luo, L., Li, Y.F., Haffari, G., Pan, S.: Reasoning on graphs: Faithful and inter- pretable large language model reasoning. arXiv preprint arXiv:2310.01061 (2024)
-
[51]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Ma, J., Gao, Z., Chai, Q., Sun, W., Wang, P., Pei, H., Tao, J., Song, L., Liu, J., Zhang, C., Cui, L.: Debate on graph: A flexible and reliable reasoning framework for large language models. In: Proceedings of the AAAI Conference on Artificial Intelligence. pp. 24768–24776 (2025)
2025
-
[52]
Ma, L., Rabbany, R., Romero-Soriano, A.: Graph attention networks with posi- tional embeddings (2021)
2021
-
[53]
Journal of Machine Learning Research9, 2579–2605 (2008)
van der Maaten, L., Hinton, G.: Visualizing data using t-sne. Journal of Machine Learning Research9, 2579–2605 (2008)
2008
-
[54]
In: Findings of the Association for Computational Lin- guistics: EMNLP 2022
Mavromatis, C., Karypis, G.: ReaRev: Adaptive reasoning for question answering over knowledge graphs. In: Findings of the Association for Computational Lin- guistics: EMNLP 2022. pp. 2447–2458. Association for Computational Linguistics (2022)
2022
-
[55]
arXiv preprint arXiv:2405.20139 (2024)
Mavromatis, C., Karypis, G.: Gnn-rag: Graph neural retrieval for large language model reasoning. arXiv preprint arXiv:2405.20139 (2024)
-
[56]
arXiv preprint arXiv:2006.16981 (2020)
Mittal, S., Lamb, A., Goyal, A., Voleti, V., Shanahan, M., Lajoie, G., Mozer, M., Bengio, Y.: Learning to combine top-down and bottom-up signals in recurrent neu- ral networks with attention over modules. arXiv preprint arXiv:2006.16981 (2020)
-
[57]
OpenAI: New embedding models and api updates.https://openai.com/blog/ new-embedding-models/(2022)
2022
-
[58]
OpenAI: Gpt-4 technical report (2024)
2024
-
[59]
OpenAI: Openai gpt-5 system card. arXiv preprint arXiv:2601.03267 (2025), https://arxiv.org/abs/2601.03267
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[60]
Technical Report SIDL-WP-1999-0120, Stanford Digital Library Technologies Project (1998)
Page, L., Brin, S., Motwani, R., Winograd, T.: The pagerank citation ranking: Bringing order to the web. Technical Report SIDL-WP-1999-0120, Stanford Digital Library Technologies Project (1998)
1999
-
[61]
Perozzi, B., Fatemi, B., Zelle, D., Tsitsulin, A., Kazemi, M., Al-Rfou, R., Halcrow, J.: Let your graph do the talking: Encoding structured data for llms (2024) Abbreviated paper title 19
2024
-
[62]
In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing
Reimers, N., Gurevych, I.: Sentence-bert: Sentence embeddings using siamese bert- networks. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. pp. 3982–3992. Association for Computational Linguistics (2019)
2019
-
[63]
arXiv preprint arXiv:2104.07644 (2021)
Saha, S., Yadav, P., Bauer, L., Bansal, M.: Explagraphs: An explanation graph generation task for structured commonsense reasoning. arXiv preprint arXiv:2104.07644 (2021)
-
[64]
arXiv preprint arXiv:2506.10582 (2025)
Seong, J., Han, H.: Rethinking random masking in self-distillation on vit. arXiv preprint arXiv:2506.10582 (2025)
-
[65]
Shi, Y., Huang, Z., Feng, S., Zhong, H., Wang, W., Sun, Y.: Masked label predic- tion: Unified message passing model for semi-supervised classification (2020)
2020
-
[66]
arXiv preprint arXiv:2307.07697 (2024)
Sun, J., Xu, C., Tang, L., Wang, S., Lin, C., Gong, Y., Ni, L.M., Shum, H.Y., Guo, J.: Think-on-graph: Deep and responsible reasoning of large language model on knowledge graph. arXiv preprint arXiv:2307.07697 (2024)
-
[67]
In: Advances in Neural Information Processing Systems (NeurIPS)
Sutton, R.S., McAllester, D., Singh, S., Mansour, Y.: Policy gradient methods for reinforcement learning with function approximation. In: Advances in Neural Information Processing Systems (NeurIPS). pp. 1057–1063 (2000)
2000
-
[68]
In: Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers)
Talmor, A., Berant, J.: The web as a knowledge base for answering complex ques- tions. In: Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). pp. 641–651. Association for Computational Linguistics (2018)
2018
-
[69]
Tan,X.,Wang,X.,Liu,Q.,Xu,X.,Yuan,X.,Zhang,W.:Paths-over-graph:Knowl- edgegraphempoweredlargelanguagemodelreasoning.In:ProceedingsoftheACM Web Conference 2025. pp. 3505–3522 (2025)
2025
-
[70]
In: Independent Component Analysis and Signal Separation
Tang, A.C., Sutherland, M.T., Sun, P., Zhang, Y., Nakazawa, M., Korzekwa, A., Yang, Z., Ding, M.: Top-down versus bottom-up processing in the human brain: Distinct directional influences revealed by integrating sobi and granger causality. In: Independent Component Analysis and Signal Separation. pp. 802–809. Springer (2007)
2007
-
[71]
Team, G., Anil, R., Borgeaud, S., Wu, Y., Alayrac, J.B., Yu, J., Soricut, R., Schalk- wyk,J.,Dai,A.M.,Hauth,A.,etal.:Gemini:afamilyofhighlycapablemultimodal models (2023)
2023
-
[72]
Journal of Neuroscience pp
Theves, S., Neville, D.A., Fernández, G., Doeller, C.F.: Learning and represen- tation of hierarchical concepts in hippocampus and prefrontal cortex. Journal of Neuroscience pp. 7675–7686 (2021)
2021
-
[73]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bash- lykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[74]
Veličković, P., Cucurull, G., Casanova, A., Romero, A., Liò, P., Bengio, Y.: Graph attention networks (2017)
2017
-
[75]
arXiv preprint arXiv:2408.14512 (2024)
Wang, D., Zuo, Y., Li, F., Wu, J.: Llms as zero-shot graph learners: Alignment of gnn representations with llm token embeddings. arXiv preprint arXiv:2408.14512 (2024)
- [76]
-
[77]
In: The Thirteenth Interna- tional Conference on Learning Representations (2025) 20 F
Wang, S., Lin, J., Guo, X., Shun, J., Li, J., Zhu, Y.: Reasoning of large language models over knowledge graphs with super-relations. In: The Thirteenth Interna- tional Conference on Learning Representations (2025) 20 F. Author et al
2025
-
[78]
arXiv preprint arXiv:2503.23513 (2025)
Wang, Z., Yu, J., Ma, D., Chen, Z., Wang, Y., Li, Z., Xiong, F., Wang, Y., E, W., Tang, L., Zhang, W.: Rare: Retrieval-augmented reasoning modeling. arXiv preprint arXiv:2503.23513 (2025)
-
[79]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Wei, C., Fan, H., Xie, S., Wu, C.Y., Yuille, A., Feichtenhofer, C.: Masked feature prediction for self-supervised visual pre-training. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 14668– 14678 (2022)
2022
-
[80]
Retrieval-Augmented Generation for Natural Language Processing: A Survey
Wu, S., Xiong, Y., Cui, Y., Wu, H., Chen, C., Yuan, Y., Huang, L., Liu, X., Kuo, T.W., Guan, N., Xue, C.J.: Retrieval-augmented generation for natural language processing: A survey. arXiv preprint arXiv:2407.13193 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.