SMGFM: Spectral Multimodal Graph Pretraining for Multimodal-Attributed Graphs
Pith reviewed 2026-06-27 07:30 UTC · model grok-4.3
The pith
Decomposing each modality signal into graph-frequency bands assigns semantic roles before cross-modal fusion on multimodal-attributed graphs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
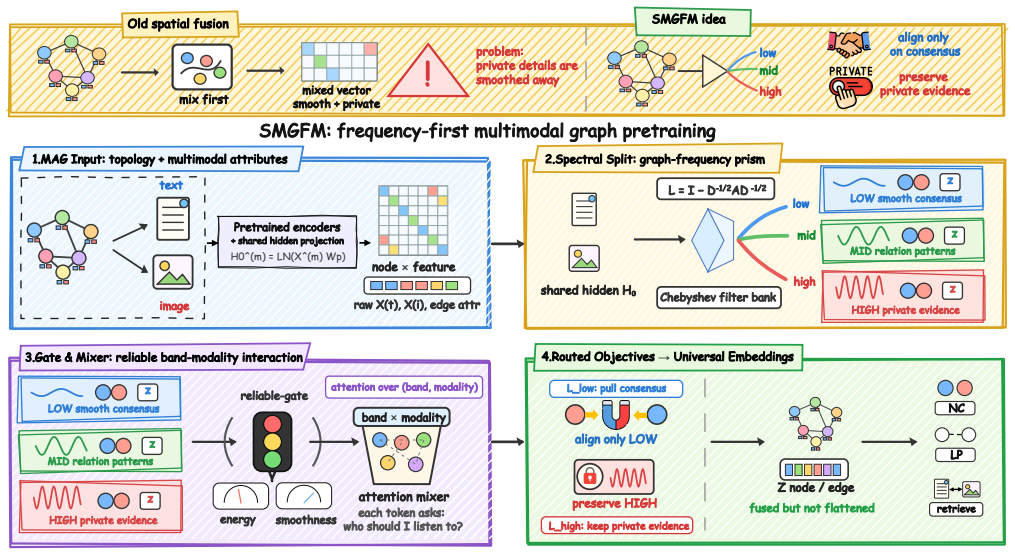
SMGFM decomposes each modality-specific node signal into graph-frequency bands, constructs frequency-resolved modality tokens with scalable Chebyshev filters, estimates their coupling reliability through topology-conditioned routing, and performs band-modality interaction before fusion; its frequency-routed objectives align smooth consensus routes while preserving modality-specific routes, mitigating spatial-domain entanglement and uniform cross-modal alignment.
What carries the argument
frequency-resolved modality tokens built with Chebyshev filters plus topology-conditioned routing for band-modality interaction
If this is right
- Achieves state-of-the-art performance across graph-level and modality-level tasks on MAG datasets
- Aligns smooth consensus routes while preserving modality-specific routes
- Mitigates spatial-domain entanglement and uniform cross-modal alignment
Where Pith is reading between the lines
- The same frequency separation might be applied to graphs with temporal modalities to separate persistent structure from transient signals
- The routing step could be replaced by learned attention without the frequency prior to test whether the prior itself drives the gains
- The approach might extend to node-level prediction where modality-specific details matter more than global topology
Load-bearing premise
Low-frequency graph components capture topology-consistent semantics and high-frequency components preserve modality-specific semantics.
What would settle it
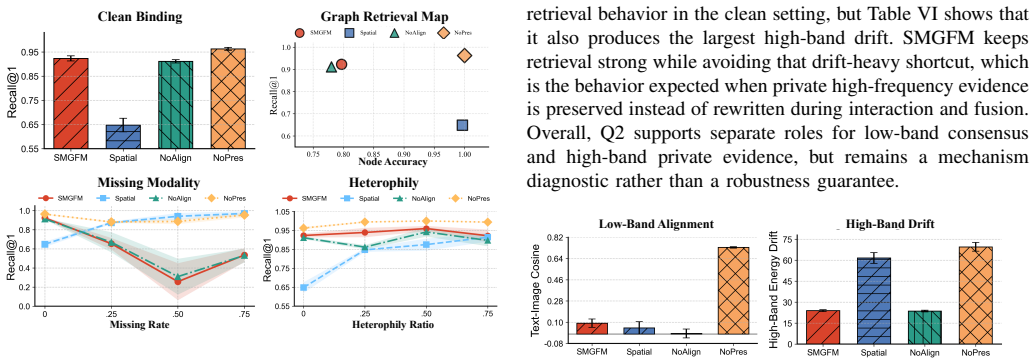
A dataset of synthetic multimodal-attributed graphs in which modality-specific semantics are deliberately placed in low-frequency bands and high-frequency bands hold only topology-consistent information; on this data SMGFM should underperform a standard non-frequency multimodal baseline.
Figures
read the original abstract
Multimodal-attributed graphs (MAGs) couple graph topology with node semantics from text, images, and other modalities. Traditional graph learning contextualizes node semantics by coupling topology with node features. However, this coupling design becomes troublesome in MAGs, where structure-induced and modality-intrinsic semantics may contribute differently to downstream tasks. Structure-induced semantics promote relational consistency through smooth topological variation, whereas modality-intrinsic semantics often encode local, fine-grained distinctions that should not be uniformly smoothed or aligned. Therefore, the key challenge is to identify semantic roles before cross-modal fusion. To this end, we leverage graph-frequency variation as a prior, where low-frequency components capture topology-consistent semantics and high-frequency components preserve modality-specific semantics. Based on this intuition, we propose SMGFM, a spectral multimodal graph pretraining framework that decomposes each modality-specific node signal into graph-frequency bands and assigns band-level semantic roles before cross-modal interaction. Concretely, SMGFM constructs frequency-resolved modality tokens with scalable Chebyshev filters, estimates their coupling reliability through topology-conditioned routing, and performs band-modality interaction before fusion. Its frequency-routed objectives align smooth consensus routes while preserving modality-specific routes, mitigating spatial-domain entanglement and uniform cross-modal alignment. Extensive experiments conducted on the MAG datasets demonstrate that SMGFM achieves state-of-the-art performance across graph-level and modality-level tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SMGFM, a spectral multimodal graph pretraining framework for multimodal-attributed graphs (MAGs). It decomposes each modality-specific node signal into graph-frequency bands via scalable Chebyshev filters, assigns band-level semantic roles (low-frequency for topology-consistent semantics, high-frequency for modality-specific semantics) based on graph-frequency variation as a prior, estimates coupling reliability via topology-conditioned routing, and performs band-modality interaction before fusion. Frequency-routed objectives are used to align smooth consensus routes while preserving modality-specific routes. The central claim is that this mitigates spatial-domain entanglement and uniform cross-modal alignment, yielding state-of-the-art performance on graph-level and modality-level tasks across MAG datasets.
Significance. If the results and the frequency-role prior hold under rigorous validation, the work could advance multimodal graph learning by providing a spectral mechanism to differentiate structure-induced from modality-intrinsic semantics before fusion, extending standard graph signal processing techniques to the multimodal setting. The scalable Chebyshev construction and routing mechanism are concrete strengths that could be reusable if the empirical gains are reproducible.
major comments (2)
- [Abstract] Abstract (paragraph on graph-frequency variation as prior): The premise that low-frequency components capture topology-consistent semantics while high-frequency components preserve modality-specific semantics is presented as an untested intuition without supporting analysis, citations to prior GSP work on attributed graphs, or ablation studies; this assumption is load-bearing for the frequency-resolved modality tokens, band-modality interaction, and the claimed mitigation of uniform alignment.
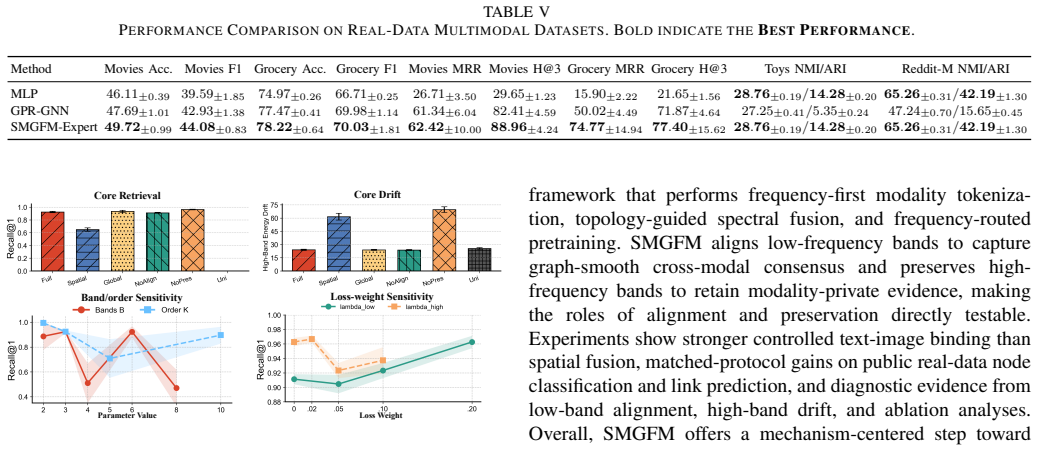
- [Experiments] The SOTA claim on MAG datasets requires explicit reporting of dataset statistics, number of modalities per dataset, baseline implementations, and statistical significance (error bars, multiple runs); without these in the experiments section the performance advantage cannot be assessed as load-bearing evidence for the framework.
minor comments (2)
- [Method] Notation for frequency bands and routing should be formalized with explicit equations rather than descriptive text to improve reproducibility.
- [Figure 1] Figure captions for the overall architecture should include explicit references to the Chebyshev filter order and routing module to aid readers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the frequency-role prior and experimental reporting. We address each major comment below with proposed revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph on graph-frequency variation as prior): The premise that low-frequency components capture topology-consistent semantics while high-frequency components preserve modality-specific semantics is presented as an untested intuition without supporting analysis, citations to prior GSP work on attributed graphs, or ablation studies; this assumption is load-bearing for the frequency-resolved modality tokens, band-modality interaction, and the claimed mitigation of uniform alignment.
Authors: The frequency-role assignment draws from established graph signal processing principles, where low-frequency components exhibit smooth variation aligned with topology (structure-induced semantics) and high-frequency components capture localized distinctions (modality-intrinsic semantics). We will revise the abstract and introduction to include citations to prior GSP works on attributed graphs (e.g., on graph Fourier analysis for node features) and add a short supporting paragraph with references to empirical patterns observed in related multimodal settings. For ablations, we will expand the experiments section with a targeted sensitivity study on band assignments if space allows under major revision. revision: partial
-
Referee: [Experiments] The SOTA claim on MAG datasets requires explicit reporting of dataset statistics, number of modalities per dataset, baseline implementations, and statistical significance (error bars, multiple runs); without these in the experiments section the performance advantage cannot be assessed as load-bearing evidence for the framework.
Authors: We agree that comprehensive reporting is necessary to substantiate the SOTA claims. The revised experiments section will explicitly tabulate dataset statistics (nodes, edges, features), specify the number of modalities for each dataset, detail baseline implementations (including any adaptations), and report mean performance with standard deviations from multiple independent runs to demonstrate statistical significance. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents its core premise as an external prior from graph signal processing (low-frequency components capture topology-consistent semantics; high-frequency preserve modality-specific semantics), invoked explicitly as 'intuition' rather than derived internally. No equations, fitted parameters, or predictions are shown that reduce by construction to inputs. No self-citations are load-bearing in the provided text, no uniqueness theorems are invoked from prior author work, and no ansatz is smuggled via citation. The construction of Chebyshev filters, routing, and band-modality interaction follows once the standard GSP prior is granted, but does not create a self-referential loop. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Low-frequency components capture topology-consistent semantics while high-frequency components preserve modality-specific semantics
invented entities (1)
-
frequency-resolved modality tokens
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Mmgcn: Multi-modal graph convolution network for personalized recommenda- tion of micro-video,
Y . Wei, X. Wang, L. Nie, X. He, R. Hong, and T.-S. Chua, “Mmgcn: Multi-modal graph convolution network for personalized recommenda- tion of micro-video,” inProceedings of the 27th ACM International Conference on Multimedia, 2019, pp. 1437–1445
2019
-
[2]
Mgat: Multimodal graph attention network for recommendation,
Z. Tao, Y . Wei, X. Wang, X. He, X. Huang, and T.-S. Chua, “Mgat: Multimodal graph attention network for recommendation,”Information Processing and Management, vol. 57, no. 5, p. 102277, 2020
2020
-
[3]
Lgmrec: Local and global graph learning for multimodal recommendation,
Z. Guo, J. Li, G. Li, C. Wang, S. Shi, and B. Ruan, “Lgmrec: Local and global graph learning for multimodal recommendation,” inProceedings of the AAAI Conference on Artificial Intelligence, 2024, pp. 8454–8462
2024
-
[4]
Modality-independent graph neural networks with global transformers for multimodal recommendation,
J. Hu, B. Hooi, B. He, and Y . Wei, “Modality-independent graph neural networks with global transformers for multimodal recommendation,” in Proceedings of the AAAI Conference on Artificial Intelligence, 2025, pp. 11 790–11 798
2025
-
[5]
Multi- modal learning with graphs,
Y . Ektefaie, G. Dasoulas, A. Noori, M. Farhat, and M. Zitnik, “Multi- modal learning with graphs,”Nature Machine Intelligence, vol. 5, no. 4, pp. 340–350, 2023
2023
-
[6]
Mo- saic of modalities: A comprehensive benchmark for multimodal graph learning,
J. Zhu, Y . Zhou, S. Qian, Z. He, T. Zhao, N. Shah, and D. Koutra, “Mo- saic of modalities: A comprehensive benchmark for multimodal graph learning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025, pp. 14 215–14 224
2025
-
[7]
Cellular Infrastructure Sharing for Network Robustness: A Citywide Empirical Study ,
Z. Fang, G. Yang, W. Lyu, and e. a. Hong, “ Cellular Infrastructure Sharing for Network Robustness: A Citywide Empirical Study ,”IEEE Transactions on Mobile Computing, vol. 24, no. 11, pp. 11 386–11 400, Nov. 2025. [Online]. Available: https://doi.ieeecomputersociety.org/10. 1109/TMC.2025.3580605
arXiv 2025
-
[8]
Openmag: A comprehensive benchmark for multimodal- attributed graph,
C. Wan, X. Li, Y . Zuo, H. Deng, S. Li, B. Fan, H. Qin, R. Li, and G. Wang, “Openmag: A comprehensive benchmark for multimodal- attributed graph,”arXiv preprint arXiv:2602.05576, 2026
arXiv 2026
-
[9]
Benchmarking graph foundation models,
J. Yang, L. Yang, Z. Guo, J. Gao, J. Wu, T. Chai, H. Huang, C. Yang, and C. Shi, “Benchmarking graph foundation models,” inProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2025, pp. 5866–5875
2025
-
[10]
Unigraph: Learning a unified cross- domain foundation model for text-attributed graphs,
Y . He, Y . Sui, X. He, and B. Hooi, “Unigraph: Learning a unified cross- domain foundation model for text-attributed graphs,” inProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2025, pp. 448–459
2025
-
[11]
Graphclip: Enhancing transferability in graph foundation models for text-attributed graphs,
Y . Zhu, H. Shi, X. Wang, Y . Liu, Y . Wang, B. Peng, C. Hong, and S. Tang, “Graphclip: Enhancing transferability in graph foundation models for text-attributed graphs,” inProceedings of the ACM on Web Conference, 2025, pp. 2183–2197
2025
-
[12]
Gft: Graph foundation model with transferable tree vocabulary,
Z. Wang, Z. Zhang, N. V . Chawla, C. Zhang, and Y . Ye, “Gft: Graph foundation model with transferable tree vocabulary,” inAdvances in Neural Information Processing Systems, vol. 37, 2024, pp. 107 403– 107 443
2024
-
[13]
Unigraph2: Learning a unified embedding space to bind multimodal graphs,
Y . He, Y . Sui, X. He, Y . Liu, Y . Sun, and B. Hooi, “Unigraph2: Learning a unified embedding space to bind multimodal graphs,”Proceedings of the ACM on the Web Conference 2025, pp. 1759–1770, 2025
2025
-
[14]
Toward effective multimodal graph foundation model: A divide-and-conquer based approach,
S. Liu, X. Li, D. Su, R. Zhang, H. Qin, R. Li, and G. Wang, “Toward effective multimodal graph foundation model: A divide-and-conquer based approach,”arXiv preprint arXiv:2602.04116, 2026
arXiv 2026
-
[15]
Multimodal heterogeneous graph attention network,
X. Jia, M. Jiang, Y . Dong, F. Zhu, H. Lin, Y . Xin, and H. Chen, “Multimodal heterogeneous graph attention network,”Neural Computing and Applications, vol. 35, no. 4, pp. 3357–3372, 2023
2023
-
[16]
Graph4mm: Weaving multi- modal learning with structural information,
X. Ning, D. Fu, T. Wei, W. Xu, and J. He, “Graph4mm: Weaving multi- modal learning with structural information,” inInternational Conference on Machine Learning, 2025
2025
-
[17]
Graphgpt- o: Synergistic multimodal comprehension and generation on graphs,
Y . Fang, B. Jin, J. Shen, S. Ding, Q. Tan, and J. Han, “Graphgpt- o: Synergistic multimodal comprehension and generation on graphs,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025, pp. 19 467–19 476
2025
-
[18]
Beyond homophily in graph neural networks: Current limitations and effective designs,
J. Zhu, Y . Yan, L. Zhao, M. Heimann, L. Akoglu, and D. Koutra, “Beyond homophily in graph neural networks: Current limitations and effective designs,” inAdvances in Neural Information Processing Sys- tems, 2020
2020
-
[19]
Graph con- trastive learning with augmentations,
Y . You, T. Chen, Y . Sui, T. Chen, Z. Wang, and Y . Shen, “Graph con- trastive learning with augmentations,” inAdvances in Neural Information Processing Systems, 2020
2020
-
[20]
Gcc: Graph contrastive coding for graph neural network pre-training,
J. Qiu, Q. Chen, Y . Dong, J. Zhang, H. Yang, M. Ding, K. Wang, and J. Tang, “Gcc: Graph contrastive coding for graph neural network pre-training,” inProceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2020, pp. 1150– 1160
2020
-
[21]
Graphmae2: A decoding-enhanced masked self-supervised graph learner,
Z. Hou, Y . He, Y . Cen, X. Liu, Y . Dong, E. Kharlamov, and J. Tang, “Graphmae2: A decoding-enhanced masked self-supervised graph learner,” inProceedings of the ACM Web Conference, 2023
2023
-
[22]
Convolutional neural networks on graphs with fast localized spectral filtering,
M. Defferrard, X. Bresson, and P. Vandergheynst, “Convolutional neural networks on graphs with fast localized spectral filtering,” inAdvances in Neural Information Processing Systems, 2016
2016
-
[23]
When graph meets multimodal: Benchmarking and meditating on multimodal attributed graphs learning,
H. Yan, C. Li, J. Yin, Z. Yu, W. Han, M. Li, Z. Zeng, H. Sun, and S. Wang, “When graph meets multimodal: Benchmarking and meditating on multimodal attributed graphs learning,”arXiv preprint arXiv:2410.09132, 2024
arXiv 2024
-
[24]
The emerging field of signal processing on graphs: Ex- tending high-dimensional data analysis to networks and other irregular domains,
D. I. Shuman, S. K. Narang, P. Frossard, A. Ortega, and P. Van- dergheynst, “The emerging field of signal processing on graphs: Ex- tending high-dimensional data analysis to networks and other irregular domains,”IEEE Signal Processing Magazine, vol. 30, no. 3, pp. 83–98, 2013
2013
-
[25]
A tutorial on spectral clustering,
U. von Luxburg, “A tutorial on spectral clustering,”Statistics and Computing, vol. 17, no. 4, pp. 395–416, 2007
2007
-
[26]
Sim- plifying graph convolutional networks,
F. Wu, A. Souza, T. Zhang, C. Fifty, T. Yu, and K. Weinberger, “Sim- plifying graph convolutional networks,” inInternational Conference on Machine Learning, 2019
2019
-
[27]
Predict then propagate: Graph neural networks meet personalized pagerank,
J. Klicpera, A. Bojchevski, and S. G ¨unnemann, “Predict then propagate: Graph neural networks meet personalized pagerank,” inInternational Conference on Learning Representations, 2019
2019
-
[28]
Simple and deep graph convolutional networks,
M. Chen, Z. Wei, Z. Huang, B. Ding, and Y . Li, “Simple and deep graph convolutional networks,” inInternational Conference on Machine Learning, 2020
2020
-
[29]
Simple spectral graph convolution,
H. Zhu and P. Koniusz, “Simple spectral graph convolution,” inInter- national Conference on Learning Representations, 2021
2021
-
[30]
Nafs: A simple yet tough-to-beat baseline for graph representation learning,
W. Zhang, Z. Sheng, M. Yang, Y . Li, Y . Shen, Z. Yang, and B. Cui, “Nafs: A simple yet tough-to-beat baseline for graph representation learning,” inInternational Conference on Machine Learning, 2022, pp. 26 467–26 483
2022
-
[31]
Adaptive universal generalized pagerank graph neural network,
E. Chien, J. Peng, P. Li, and O. Milenkovic, “Adaptive universal generalized pagerank graph neural network,” inInternational Conference on Learning Representations, 2021
2021
-
[32]
Bernnet: Learning arbitrary graph spectral filters via bernstein approximation,
M. He, Z. Wei, Z. Huang, and H. Xu, “Bernnet: Learning arbitrary graph spectral filters via bernstein approximation,” inAdvances in Neural Information Processing Systems, 2021
2021
-
[33]
Adagnn: Graph neural networks with adaptive frequency response filter,
Y . Dong, K. Ding, B. Jalaian, S. Ji, and J. Li, “Adagnn: Graph neural networks with adaptive frequency response filter,” inProceedings of the 30th ACM International Conference on Information and Knowledge Management, 2021
2021
-
[34]
How powerful are spectral graph neural networks,
X. Wang and M. Zhang, “How powerful are spectral graph neural networks,” inInternational Conference on Machine Learning, 2022
2022
-
[35]
Graph neural networks with learnable and optimal polynomial bases,
Y . Guo and Z. Wei, “Graph neural networks with learnable and optimal polynomial bases,” inInternational Conference on Machine Learning, 2023
2023
-
[36]
Node-oriented spectral filtering for graph neural networks,
S. Zheng, Z. Zhu, Z. Liu, Y . Li, and Y . Zhao, “Node-oriented spectral filtering for graph neural networks,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023
2023
-
[37]
Specformer: Spectral graph neural networks meet transformers,
D. Bo, C. Shi, L. Wang, and R. Liao, “Specformer: Spectral graph neural networks meet transformers,” inInternational Conference on Learning Representations, 2023
2023
-
[38]
Rethinking graph transformers with spectral attention,
D. Kreuzer, D. Beaini, W. Hamilton, V . L ´etourneau, and P. Tossou, “Rethinking graph transformers with spectral attention,” inAdvances in Neural Information Processing Systems, 2021
2021
-
[39]
Recipe for a general, powerful, scalable graph transformer,
L. Ramp ´aˇsek, M. Galkin, V . P. Dwivedi, A. T. Luu, G. Wolf, and D. Beaini, “Recipe for a general, powerful, scalable graph transformer,” inAdvances in Neural Information Processing Systems, 2022
2022
-
[40]
Gbk-gnn: Gated bi-kernel graph neural networks for modeling both homophily and heterophily,
L. Du, X. Shi, Q. Fu, X. Ma, H. Liu, S. Han, and D. Zhang, “Gbk-gnn: Gated bi-kernel graph neural networks for modeling both homophily and heterophily,” inProceedings of the ACM Web Conference, 2022, pp. 1550–1558
2022
-
[41]
Ordered gnn: Ordering message passing to deal with heterophily and over-smoothing,
Y . Song, C. Zhou, X. Wang, and Z. Lin, “Ordered gnn: Ordering message passing to deal with heterophily and over-smoothing,” inInternational Conference on Learning Representations, 2023
2023
-
[42]
Learning transferable visual models from natural language supervi- sion,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervi- sion,” inInternational Conference on Machine Learning, 2021
2021
-
[43]
Imagebind: One embedding space to bind them all,
R. Girdhar, A. El-Nouby, Z. Liu, M. Singh, K. V . Alwala, A. Joulin, and I. Misra, “Imagebind: One embedding space to bind them all,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 15 180–15 190
2023
-
[44]
Graph structured network for image-text matching,
C. Liu, Z. Mao, T. Zhang, H. Xie, B. Wang, and Y . Zhang, “Graph structured network for image-text matching,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 10 918–10 927
2020
-
[45]
Revisiting graph contrastive learning from the perspective of graph spectrum,
N. Liu, X. Wang, D. Bo, C. Shi, and J. Pei, “Revisiting graph contrastive learning from the perspective of graph spectrum,” inAdvances in Neural Information Processing Systems, 2022
2022
-
[46]
Simple unsupervised graph representation learning,
Y . Mo, L. Peng, J. Xu, X. Shi, and X. Zhu, “Simple unsupervised graph representation learning,” inAAAI Conference on Artificial Intelligence, 2022
2022
-
[47]
Wavelets on graphs via spectral graph theory,
D. K. Hammond, P. Vandergheynst, and R. Gribonval, “Wavelets on graphs via spectral graph theory,”Applied and Computational Harmonic Analysis, vol. 30, no. 2, pp. 129–150, 2011
2011
-
[48]
Roberta: A robustly optimized bert pretraining approach,
Y . Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V . Stoyanov, “Roberta: A robustly optimized bert pretraining approach,” 2019
2019
-
[49]
Inductive representation learning on large graphs,
W. L. Hamilton, R. Ying, and J. Leskovec, “Inductive representation learning on large graphs,” inAdvances in Neural Information Processing Systems, 2017
2017
-
[50]
Graph attention networks,
P. Veli ˇckovi´c, G. Cucurull, A. Casanova, A. Romero, P. Li `o, and Y . Bengio, “Graph attention networks,” inInternational Conference on Learning Representations, 2018
2018
-
[51]
Representation learning with contrastive predictive coding,
A. v. d. Oord, Y . Li, and O. Vinyals, “Representation learning with contrastive predictive coding,”arXiv preprint arXiv:1807.03748, 2018
Pith/arXiv arXiv 2018
-
[52]
Smil: Multimodal learning with severely missing modality,
M. Ma, J. Ren, L. Zhao, S. Tulyakov, C. Wu, and X. Peng, “Smil: Multimodal learning with severely missing modality,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 3, 2021, pp. 2302–2310
2021
-
[53]
Are multi- modal transformers robust to missing modality?
M. Ma, J. Ren, L. Zhao, D. Testuggine, and X. Peng, “Are multi- modal transformers robust to missing modality?” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 18 177–18 186
2022
-
[54]
Multi-modal learning with missing modality via shared-specific feature modelling,
H. Wang, Y . Chen, C. Ma, J. Avery, L. Hull, and G. Carneiro, “Multi-modal learning with missing modality via shared-specific feature modelling,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 15 878–15 887
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.