CoreUnlearn: Rethinking Concept Unlearning through Disentangled Component-Level Erasure in Text-guided Diffusion Models
Pith reviewed 2026-06-28 14:26 UTC · model grok-4.3
The pith
CoreUnlearn removes only the erasure-critical component of a concept embedding to unlearn it from diffusion models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
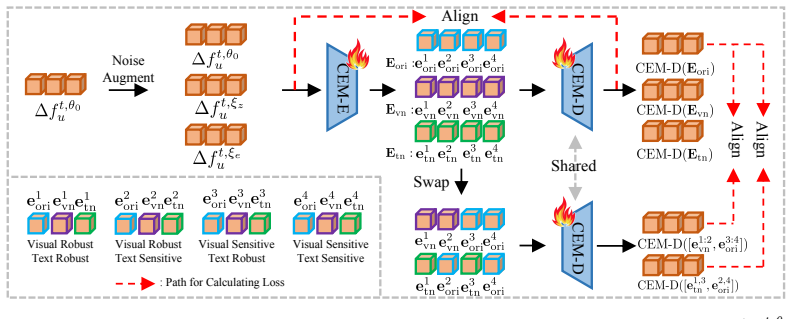
CoreUnlearn comprises a Component Extraction Module (CEM) and a Swap Disentangling Strategy (SDS). Guided by SDS, CEM is pre-trained to decompose concept embeddings into distinct component types. Leveraging this decomposition, CoreUnlearn then removes the erasure-critical component while retaining non-critical ones by fine-tuning model weights.
What carries the argument
The Component Extraction Module pre-trained with the Swap Disentangling Strategy, which breaks concept embeddings into component types so that only the critical one can be isolated and erased.
If this is right
- Unlearning no longer requires careful selection of erasure reference texts.
- The model retains more of its original generation ability after the concept is removed.
- Erasure succeeds while overall performance degradation stays minimal.
- Fine-tuning focuses only on the identified critical component rather than the full concept.
Where Pith is reading between the lines
- The same decomposition step could be tested on unlearning tasks in other generative architectures.
- Running the method on a broader set of concepts would show whether the component separation holds in more cases.
- If the separation proves stable, safety filters in deployed diffusion systems could use lighter updates.
Load-bearing premise
The Component Extraction Module, after pre-training with the Swap Disentangling Strategy, can reliably split concept embeddings so that exactly one component is the one that must be erased.
What would settle it
A test in which the model continues to generate the target concept after the procedure or shows clear drops in image quality on unrelated prompts.
Figures




read the original abstract
Text guided diffusion models have revolutionized image synthesis but also raise ethical concerns, such as privacy violation and harmful content generation. To mitigate these issues, prevailing methods typically leverage an alignment mechanism, with predefined erasure references, to fine-tune pretrained model weights. However, these techniques are intrinsically limited by the representational capacity of textual space and display high sensitivity to the choice of predefined erasure references, e.g., suboptimal references may significantly affect the model utility preservation during erasure. To overcome these limitations, we introduce CoreUnlearn, aiming to disentangle and remove the erasure-critical component of the undesirable concept. Specifically, CoreUnlearn comprises a Component Extraction Module (CEM) and a Swap Disentangling Strategy (SDS). Guided by SDS, CEM is pre-trained to decompose concept embeddings into distinct component types. Leveraging this decomposition, CoreUnlearn then removes the erasure-critical component while retaining non-critical ones by fine-tuning model weights. Extensive experiments demonstrate that CoreUnlearn achieves effective concept erasure with minimal impact on overall model performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CoreUnlearn for concept unlearning in text-guided diffusion models. It proposes a Component Extraction Module (CEM) pre-trained via the Swap Disentangling Strategy (SDS) to decompose concept embeddings into distinct component types, followed by targeted removal of only the erasure-critical component during fine-tuning of model weights. This is positioned as addressing the sensitivity of prior alignment-based methods to erasure reference choice, with the claim that extensive experiments show effective erasure and minimal impact on overall model performance.
Significance. If the decomposition reliably isolates an erasure-critical component, the method could offer a more robust alternative to reference-dependent unlearning techniques, improving utility preservation in diffusion models while mitigating privacy and safety risks.
major comments (2)
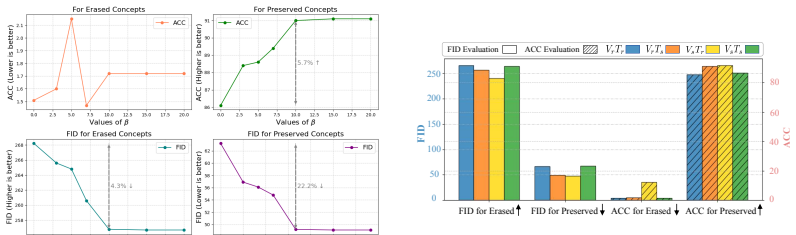
- [Component Extraction Module and Swap Disentangling Strategy description] The load-bearing assumption that SDS pre-training enables the CEM to produce a decomposition in which exactly one component is erasure-critical (and the others non-critical) lacks supporting quantitative validation such as component similarity metrics or ablation on component count; this directly affects whether the method avoids the reference-sensitivity problem it targets.
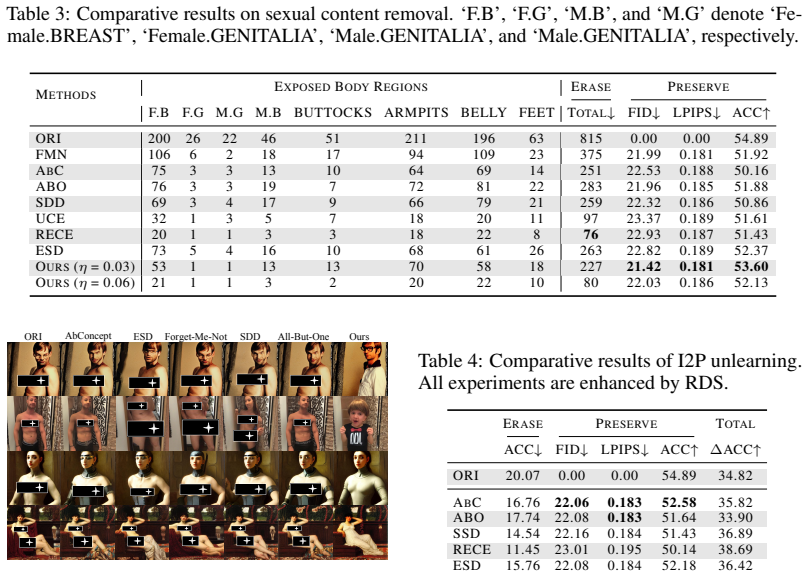
- [Experiments] The experiments section claims effective erasure with minimal utility loss but does not report direct comparisons against prior methods using deliberately suboptimal erasure references, which is required to substantiate the reduced-sensitivity advantage.
minor comments (2)
- The abstract would be strengthened by including at least one key quantitative result (e.g., a utility or erasure metric) rather than qualitative statements only.
- Notation for the distinct component types produced by CEM should be introduced with an accompanying diagram or explicit mathematical definition for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the recommendation of minor revision. Below we address each major comment point by point, indicating the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Component Extraction Module and Swap Disentangling Strategy description] The load-bearing assumption that SDS pre-training enables the CEM to produce a decomposition in which exactly one component is erasure-critical (and the others non-critical) lacks supporting quantitative validation such as component similarity metrics or ablation on component count; this directly affects whether the method avoids the reference-sensitivity problem it targets.
Authors: We agree that explicit quantitative validation of the component decomposition would strengthen the central claim. In the revised manuscript we will add (i) pairwise cosine similarity metrics between the extracted components to demonstrate their distinctness and (ii) an ablation study varying the number of components, reporting erasure efficacy and utility metrics for each choice. These additions will directly support that SDS pre-training isolates an erasure-critical component while leaving non-critical ones intact. revision: yes
-
Referee: [Experiments] The experiments section claims effective erasure with minimal utility loss but does not report direct comparisons against prior methods using deliberately suboptimal erasure references, which is required to substantiate the reduced-sensitivity advantage.
Authors: While CoreUnlearn avoids explicit dependence on erasure-reference selection by operating at the component level, we acknowledge that a head-to-head comparison under deliberately suboptimal references would more clearly demonstrate the claimed robustness. We will therefore add such experiments in the revision, evaluating representative prior alignment-based methods with both optimal and suboptimal references and contrasting their utility degradation against CoreUnlearn. revision: yes
Circularity Check
No significant circularity identified
full rationale
The provided abstract and text describe CoreUnlearn as an engineering method: CEM is pre-trained via SDS to decompose embeddings, after which the erasure-critical component is removed by fine-tuning. No equations, fitted parameters renamed as predictions, self-citation load-bearing premises, or uniqueness theorems appear. The central claim rests on experimental demonstration of effective erasure with minimal utility loss rather than any reduction of outputs to inputs by construction. This is the expected non-finding for a methods paper whose derivation chain does not collapse to self-definition or fitted-input renaming.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Nudenet: Neural nets for nudity classification, detection and selective censoring, 2019
P Bedapudi. Nudenet: Neural nets for nudity classification, detection and selective censoring, 2019
2019
-
[2]
Sega: Instructing text-to-image models using semantic guidance.Advances in Neural Information Processing Systems, 36:25365–25389, 2023
Manuel Brack, Felix Friedrich, Dominik Hintersdorf, Lukas Struppek, Patrick Schramowski, and Kristian Kersting. Sega: Instructing text-to-image models using semantic guidance.Advances in Neural Information Processing Systems, 36:25365–25389, 2023
2023
-
[3]
Anh Bui, Long Vuong, Khanh Doan, Trung Le, Paul Montague, Tamas Abraham, and Dinh Phung. Erasing undesirable concepts in diffusion models with adversarial preservation.arXiv preprint arXiv:2410.15618, 2024
arXiv 2024
-
[4]
Ruchika Chavhan, Da Li, and Timothy Hospedales. Conceptprune: Concept editing in diffusion models via skilled neuron pruning.arXiv preprint arXiv:2405.19237, 2024
arXiv 2024
-
[5]
Prompt- ing4debugging: Red-teaming text-to-image diffusion models by finding problematic prompts
Zhi-Yi Chin, Chieh-Ming Jiang, Ching-Chun Huang, Pin-Yu Chen, and Wei-Chen Chiu. Prompt- ing4debugging: Red-teaming text-to-image diffusion models by finding problematic prompts. arXiv preprint arXiv:2309.06135, 2023
arXiv 2023
-
[6]
Intrigu- ing properties of synthetic images: from generative adversarial networks to diffusion models
Riccardo Corvi, Davide Cozzolino, Giovanni Poggi, Koki Nagano, and Luisa Verdoliva. Intrigu- ing properties of synthetic images: from generative adversarial networks to diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 973–982, 2023
2023
-
[7]
Diffusion models in vision: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(9):10850–10869, 2023
Florinel-Alin Croitoru, Vlad Hondru, Radu Tudor Ionescu, and Mubarak Shah. Diffusion models in vision: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(9):10850–10869, 2023
2023
-
[8]
Adad- iffsr: Adaptive region-aware dynamic acceleration diffusion model for real-world image super- resolution
Yuanting Fan, Chengxu Liu, Nengzhong Yin, Changlong Gao, and Xueming Qian. Adad- iffsr: Adaptive region-aware dynamic acceleration diffusion model for real-world image super- resolution. InEuropean Conference on Computer Vision, pages 396–413. Springer, 2025
2025
-
[9]
Masane Fuchi and Tomohiro Takagi. Erasing concepts from text-to-image diffusion models with few-shot unlearning.arXiv preprint arXiv:2405.07288, 2024
arXiv 2024
-
[10]
Erasing concepts from diffusion models
Rohit Gandikota, Joanna Materzynska, Jaden Fiotto-Kaufman, and David Bau. Erasing concepts from diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2426–2436, 2023
2023
-
[11]
Unified concept editing in diffusion models
Rohit Gandikota, Hadas Orgad, Yonatan Belinkov, Joanna Materzy´nska, and David Bau. Unified concept editing in diffusion models. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 5111–5120, 2024
2024
-
[12]
Hongcheng Gao, Tianyu Pang, Chao Du, Taihang Hu, Zhijie Deng, and Min Lin. Meta- unlearning on diffusion models: Preventing relearning unlearned concepts.arXiv preprint arXiv:2410.12777, 2024
arXiv 2024
-
[13]
Reliable and efficient concept erasure of text-to-image diffusion models
Chao Gong, Kai Chen, Zhipeng Wei, Jingjing Chen, and Yu-Gang Jiang. Reliable and efficient concept erasure of text-to-image diffusion models. InEuropean Conference on Computer Vision, pages 73–88. Springer, 2024
2024
-
[14]
Reliable and efficient concept erasure of text-to-image diffusion models
Chao Gong, Kai Chen, Zhipeng Wei, Jingjing Chen, and Yu-Gang Jiang. Reliable and efficient concept erasure of text-to-image diffusion models. InEuropean Conference on Computer Vision, pages 73–88. Springer, 2025
2025
-
[15]
Continuous concepts removal in text-to-image diffusion models.arXiv preprint arXiv:2412.00580, 2024
Tingxu Han, Weisong Sun, Yanrong Hu, Chunrong Fang, Yonglong Zhang, Shiqing Ma, Tao Zheng, Zhenyu Chen, and Zhenting Wang. Continuous concepts removal in text-to-image diffusion models.arXiv preprint arXiv:2412.00580, 2024
arXiv 2024
-
[16]
Conceptexpress: Harnessing diffusion models for single-image unsupervised concept extraction
Shaozhe Hao, Kai Han, Zhengyao Lv, Shihao Zhao, and Kwan-Yee K Wong. Conceptexpress: Harnessing diffusion models for single-image unsupervised concept extraction. InEuropean Conference on Computer Vision, pages 215–233. Springer, 2025
2025
-
[17]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
2016
-
[18]
Gans trained by a two time-scale update rule converge to a local nash equilibrium.Adv
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Adv. Neural Inform. Process. Syst., 30, 2017. 10
2017
-
[19]
All but one: Surgical concept erasing with model preservation in text-to-image diffusion models
Seunghoo Hong, Juhun Lee, and Simon S Woo. All but one: Surgical concept erasing with model preservation in text-to-image diffusion models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 21143–21151, 2024
2024
-
[20]
Fastai: A layered api for deep learning.Information, 11(2):108, 2020
Jeremy Howard and Sylvain Gugger. Fastai: A layered api for deep learning.Information, 11(2):108, 2020
2020
-
[21]
Receler: Reliable concept erasing of text-to-image diffusion models via lightweight erasers
Chi-Pin Huang, Kai-Po Chang, Chung-Ting Tsai, Yung-Hsuan Lai, and Yu-Chiang Frank Wang. Receler: Reliable concept erasing of text-to-image diffusion models via lightweight erasers. arXiv preprint arXiv:2311.17717, 2023
arXiv 2023
-
[22]
Trasce: Trajectory steering for concept erasure.arXiv preprint arXiv:2412.07658, 2024
Anubhav Jain, Yuya Kobayashi, Takashi Shibuya, Yuhta Takida, Nasir Memon, Julian To- gelius, and Yuki Mitsufuji. Trasce: Trajectory steering for concept erasure.arXiv preprint arXiv:2412.07658, 2024
arXiv 2024
-
[23]
Race: Robust adversarial concept erasure for secure text-to-image diffusion model
Changhoon Kim, Kyle Min, and Yezhou Yang. Race: Robust adversarial concept erasure for secure text-to-image diffusion model. InEuropean Conference on Computer Vision, pages 461–478. Springer, 2025
2025
-
[24]
Sanghyun Kim, Seohyeon Jung, Balhae Kim, Moonseok Choi, Jinwoo Shin, and Juho Lee. Towards safe self-distillation of internet-scale text-to-image diffusion models.arXiv preprint arXiv:2307.05977, 2023
arXiv 2023
-
[25]
Ablating concepts in text-to-image diffusion models
Nupur Kumari, Bingliang Zhang, Sheng-Yu Wang, Eli Shechtman, Richard Zhang, and Jun-Yan Zhu. Ablating concepts in text-to-image diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22691–22702, 2023
2023
-
[26]
{PrivImage}: Differentially private synthetic image generation using diffusion models with {Semantic-Aware} pretraining
Kecen Li, Chen Gong, Zhixiang Li, Yuzhong Zhao, Xinwen Hou, and Tianhao Wang. {PrivImage}: Differentially private synthetic image generation using diffusion models with {Semantic-Aware} pretraining. In33rd USENIX Security Symposium (USENIX Security 24), pages 4837–4854, 2024
2024
-
[27]
Q-diffusion: Quantizing diffusion models
Xiuyu Li, Yijiang Liu, Long Lian, Huanrui Yang, Zhen Dong, Daniel Kang, Shanghang Zhang, and Kurt Keutzer. Q-diffusion: Quantizing diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 17535–17545, 2023
2023
-
[28]
Structure matters: Tackling the semantic discrepancy in diffusion models for image inpainting
Haipeng Liu, Yang Wang, Biao Qian, Meng Wang, and Yong Rui. Structure matters: Tackling the semantic discrepancy in diffusion models for image inpainting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8038–8047, 2024
2024
-
[29]
Yufan Liu, Jinyang An, Wanqian Zhang, Ming Li, Dayan Wu, Jingzi Gu, Zheng Lin, and Weiping Wang. Realera: Semantic-level concept erasure via neighbor-concept mining.arXiv preprint arXiv:2410.09140, 2024
arXiv 2024
-
[30]
Zhili Liu, Kai Chen, Yifan Zhang, Jianhua Han, Lanqing Hong, Hang Xu, Zhenguo Li, Dit-Yan Yeung, and James Kwok. Geom-erasing: Geometry-driven removal of implicit concept in diffusion models.arXiv preprint arXiv:2310.05873, 2023
arXiv 2023
-
[31]
Implicit concept removal of diffusion models
Zhili Liu, Kai Chen, Yifan Zhang, Jianhua Han, Lanqing Hong, Hang Xu, Zhenguo Li, Dit- Yan Yeung, and James T Kwok. Implicit concept removal of diffusion models. InEuropean Conference on Computer Vision, pages 457–473. Springer, 2025
2025
-
[32]
Mace: Mass concept erasure in diffusion models
Shilin Lu, Zilan Wang, Leyang Li, Yanzhu Liu, and Adams Wai-Kin Kong. Mace: Mass concept erasure in diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6430–6440, 2024
2024
-
[33]
Mengyao Lyu, Yuhong Yang, Haiwen Hong, Hui Chen, Xuan Jin, Yuan He, Hui Xue, Jungong Han, and Guiguang Ding. One-dimensional adapter to rule them all: Concepts, diffusion models and erasing applications.arXiv preprint arXiv:2312.16145, 2023
arXiv 2023
-
[34]
One-dimensional adapter to rule them all: Concepts diffusion models and erasing applications
Mengyao Lyu, Yuhong Yang, Haiwen Hong, Hui Chen, Xuan Jin, Yuan He, Hui Xue, Jungong Han, and Guiguang Ding. One-dimensional adapter to rule them all: Concepts diffusion models and erasing applications. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7559–7568, 2024
2024
-
[35]
Deepcache: Accelerating diffusion models for free
Xinyin Ma, Gongfan Fang, and Xinchao Wang. Deepcache: Accelerating diffusion models for free. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15762–15772, 2024. 11
2024
-
[36]
Towards robust concept erasure in diffusion models: Unlearning identity, nudity and artistic styles
Umakanta Maharana, Aakash Sen Sharma, Yash Sinha, Ankur Mali, Mohan Kankanhalli, and Murari Mandal. Towards robust concept erasure in diffusion models: Unlearning identity, nudity and artistic styles
-
[37]
On distillation of guided diffusion models
Chenlin Meng, Robin Rombach, Ruiqi Gao, Diederik Kingma, Stefano Ermon, Jonathan Ho, and Tim Salimans. On distillation of guided diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14297–14306, 2023
2023
-
[38]
Saemi Moon, Minjong Lee, Sangdon Park, and Dongwoo Kim. Holistic unlearning bench- mark: A multi-faceted evaluation for text-to-image diffusion model unlearning.arXiv preprint arXiv:2410.05664, 2024
arXiv 2024
-
[39]
Yong-Hyun Park, Sangdoo Yun, Jin-Hwa Kim, Junho Kim, Geonhui Jang, Yonghyun Jeong, Junghyo Jo, and Gayoung Lee. Direct unlearning optimization for robust and safe text-to-image models.arXiv preprint arXiv:2407.21035, 2024
arXiv 2024
-
[40]
Circumventing concept erasure methods for text-to-image generative models
Minh Pham, Kelly O Marshall, Niv Cohen, Govind Mittal, and Chinmay Hegde. Circumventing concept erasure methods for text-to-image generative models. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[41]
Robust concept erasure using task vectors.arXiv preprint arXiv:2404.03631, 2024
Minh Pham, Kelly O Marshall, Chinmay Hegde, and Niv Cohen. Robust concept erasure using task vectors.arXiv preprint arXiv:2404.03631, 2024
arXiv 2024
-
[42]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
2022
-
[43]
Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22500–22510, 2023
2023
-
[44]
Photorealistic text-to-image diffusion models with deep language understanding.Advances in neural information processing systems, 35:36479–36494, 2022
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding.Advances in neural information processing systems, 35:36479–36494, 2022
2022
-
[45]
Safe latent diffusion: Mitigating inappropriate degeneration in diffusion models
Patrick Schramowski, Manuel Brack, Björn Deiseroth, and Kristian Kersting. Safe latent diffusion: Mitigating inappropriate degeneration in diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22522–22531, 2023
2023
-
[46]
Gener- ative unlearning for any identity
Juwon Seo, Sung-Hoon Lee, Tae-Young Lee, Seungjun Moon, and Gyeong-Moon Park. Gener- ative unlearning for any identity. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9151–9161, 2024
2024
-
[47]
Aakash Sen Sharma, Niladri Sarkar, Vikram Chundawat, Ankur A Mali, and Murari Mandal. Unlearning or concealment? a critical analysis and evaluation metrics for unlearning in diffusion models.arXiv preprint arXiv:2409.05668, 2024
arXiv 2024
-
[48]
Diffu- sion art or digital forgery? investigating data replication in diffusion models
Gowthami Somepalli, Vasu Singla, Micah Goldblum, Jonas Geiping, and Tom Goldstein. Diffu- sion art or digital forgery? investigating data replication in diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6048–6058, 2023
2023
-
[49]
Deepak Sridhar and Nuno Vasconcelos. Prompt sliders for fine-grained control, editing and erasing of concepts in diffusion models.arXiv preprint arXiv:2409.16535, 2024
arXiv 2024
-
[50]
Wenhao Sun, Benlei Cui, Jingqun Tang, and Xue-Mei Dong. Attentive eraser: Unleashing diffusion model’s object removal potential via self-attention redirection guidance.arXiv preprint arXiv:2412.12974, 2024
arXiv 2024
-
[51]
Yu-Lin Tsai, Chia-Yi Hsu, Chulin Xie, Chih-Hsun Lin, Jia-You Chen, Bo Li, Pin-Yu Chen, Chia-Mu Yu, and Chun-Ying Huang. Ring-a-bell! how reliable are concept removal methods for diffusion models?arXiv preprint arXiv:2310.10012, 2023
arXiv 2023
-
[52]
Yongliang Wu, Shiji Zhou, Mingzhuo Yang, Lianzhe Wang, Wenbo Zhu, Heng Chang, Xiao Zhou, and Xu Yang. Unlearning concepts in diffusion model via concept domain correction and concept preserving gradient.arXiv preprint arXiv:2405.15304, 2024. 12
arXiv 2024
-
[53]
Svgdreamer: Text guided svg generation with diffusion model
Ximing Xing, Haitao Zhou, Chuang Wang, Jing Zhang, Dong Xu, and Qian Yu. Svgdreamer: Text guided svg generation with diffusion model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4546–4555, 2024
2024
-
[54]
A survey on video diffusion models.ACM Computing Surveys, 57(2):1–42, 2024
Zhen Xing, Qijun Feng, Haoran Chen, Qi Dai, Han Hu, Hang Xu, Zuxuan Wu, and Yu-Gang Jiang. A survey on video diffusion models.ACM Computing Surveys, 57(2):1–42, 2024
2024
-
[55]
Diffusion models: A comprehensive survey of methods and applications.ACM Computing Surveys, 56(4):1–39, 2023
Ling Yang, Zhilong Zhang, Yang Song, Shenda Hong, Runsheng Xu, Yue Zhao, Wentao Zhang, Bin Cui, and Ming-Hsuan Yang. Diffusion models: A comprehensive survey of methods and applications.ACM Computing Surveys, 56(4):1–39, 2023
2023
-
[56]
Federated unlearning with diffusion models
Mingzhao Yang, Bin Li, and Xiangyang Xue. Federated unlearning with diffusion models
-
[57]
Pruning for robust concept erasing in diffusion models
Tianyun Yang, Juan Cao, and Chang Xu. Pruning for robust concept erasing in diffusion models. arXiv preprint arXiv:2405.16534, 2024
arXiv 2024
-
[58]
Mma- diffusion: Multimodal attack on diffusion models
Yijun Yang, Ruiyuan Gao, Xiaosen Wang, Tsung-Yi Ho, Nan Xu, and Qiang Xu. Mma- diffusion: Multimodal attack on diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7737–7746, 2024
2024
-
[59]
Resshift: Efficient diffusion model for image super-resolution by residual shifting.Advances in Neural Information Processing Systems, 36, 2024
Zongsheng Yue, Jianyi Wang, and Chen Change Loy. Resshift: Efficient diffusion model for image super-resolution by residual shifting.Advances in Neural Information Processing Systems, 36, 2024
2024
-
[60]
Forget-me- not: Learning to forget in text-to-image diffusion models
Gong Zhang, Kai Wang, Xingqian Xu, Zhangyang Wang, and Humphrey Shi. Forget-me- not: Learning to forget in text-to-image diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1755–1764, 2024
2024
-
[61]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 3836–3847, 2023
2023
-
[62]
The unrea- sonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unrea- sonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018
2018
-
[63]
Defensive unlearning with adversarial training for robust concept erasure in diffusion models.Advances in Neural Information Processing Systems, 37:36748–36776, 2024
Yimeng Zhang, Xin Chen, Jinghan Jia, Yihua Zhang, Chongyu Fan, Jiancheng Liu, Mingyi Hong, Ke Ding, and Sijia Liu. Defensive unlearning with adversarial training for robust concept erasure in diffusion models.Advances in Neural Information Processing Systems, 37:36748–36776, 2024
2024
-
[64]
To generate or not? safety-driven unlearned diffusion models are still easy to generate unsafe images
Yimeng Zhang, Jinghan Jia, Xin Chen, Aochuan Chen, Yihua Zhang, Jiancheng Liu, Ke Ding, and Sijia Liu. To generate or not? safety-driven unlearned diffusion models are still easy to generate unsafe images... for now. InEuropean Conference on Computer Vision, pages 385–403. Springer, 2024
2024
-
[65]
Artbank: Artistic style transfer with pre- trained diffusion model and implicit style prompt bank
Zhanjie Zhang, Quanwei Zhang, Wei Xing, Guangyuan Li, Lei Zhao, Jiakai Sun, Zehua Lan, Junsheng Luan, Yiling Huang, and Huaizhong Lin. Artbank: Artistic style transfer with pre- trained diffusion model and implicit style prompt bank. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 7396–7404, 2024
2024
-
[66]
Mengnan Zhao, Lihe Zhang, Xingyi Yang, Tianhang Zheng, and Baocai Yin. Advanchor: En- hancing diffusion model unlearning with adversarial anchors.arXiv preprint arXiv:2501.00054, 2024
arXiv 2024
-
[67]
Separable multi- concept erasure from diffusion models.arXiv preprint arXiv:2402.05947, 2024
Mengnan Zhao, Lihe Zhang, Tianhang Zheng, Yuqiu Kong, and Baocai Yin. Separable multi- concept erasure from diffusion models.arXiv preprint arXiv:2402.05947, 2024
arXiv 2024
-
[68]
Jianing Zhu, Bo Han, Jiangchao Yao, Jianliang Xu, Gang Niu, and Masashi Sugiyama. Decoupling the class label and the target concept in machine unlearning.arXiv preprint arXiv:2406.08288, 2024
arXiv 2024
-
[69]
Watermark-embedded adversarial examples for copyright protection against diffusion models
Peifei Zhu, Tsubasa Takahashi, and Hirokatsu Kataoka. Watermark-embedded adversarial examples for copyright protection against diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24420–24430, 2024. 13
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.