ReM-MoA: Reasoning Memory Sustains Mixture-of-Agents Scaling
Pith reviewed 2026-06-25 23:35 UTC · model grok-4.3
The pith
ReM-MoA sustains performance gains in mixture-of-agents systems by storing and routing ranked reasoning traces across layers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
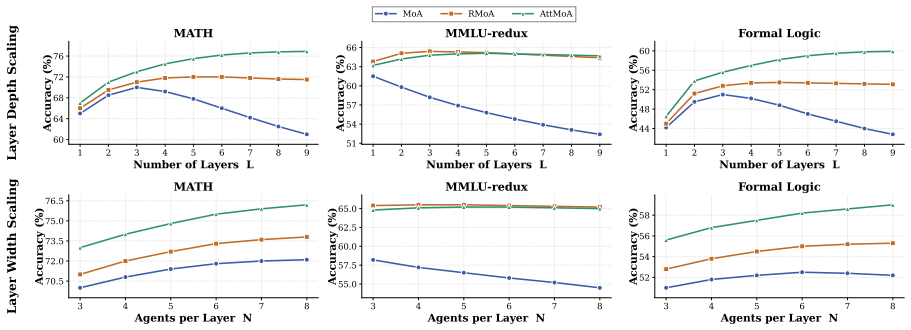
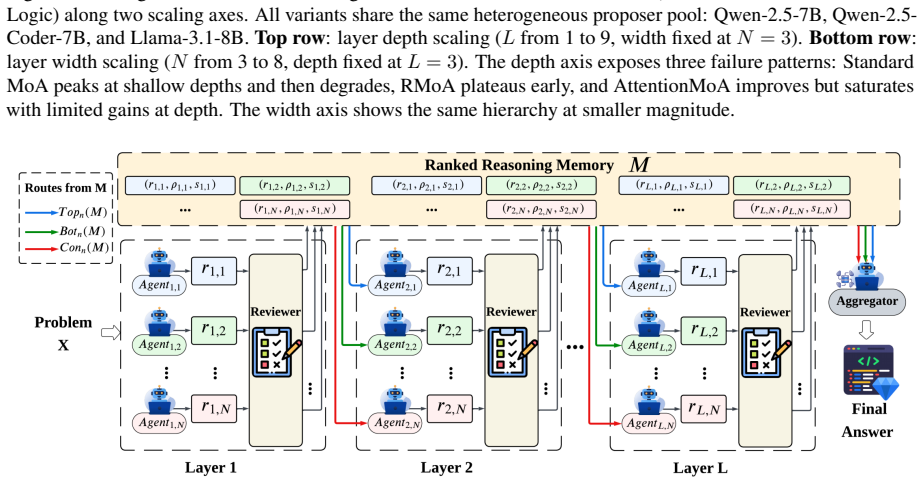
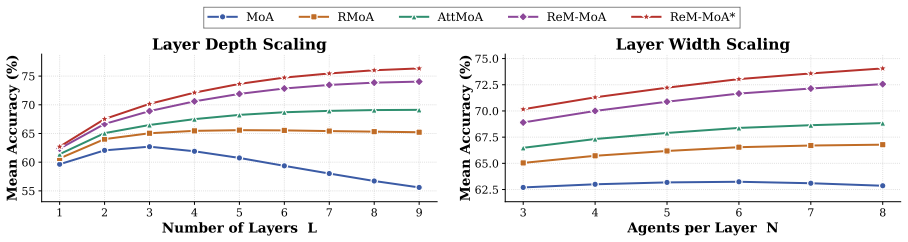
ReM-MoA introduces Ranked Reasoning Memory that persistently stores and ranks reasoning traces from all layers via a comparative Reviewer Agent, paired with Curated Diversified Memory Routing that exposes agents to varied successful and failed traces. This combination allows the system to maintain and widen performance advantages as depth increases, unlike prior MoA variants that degrade or saturate.
What carries the argument
Ranked Reasoning Memory combined with Curated Diversified Memory Routing, where a Reviewer Agent ranks traces and routing diversifies exposure to maintain exploration while propagating quality.
Load-bearing premise
A comparative Reviewer Agent can produce unbiased rankings of reasoning traces that improve agent performance when used for routing.
What would settle it
A controlled test where a standard MoA without memory matches or exceeds ReM-MoA performance at high layer counts on the same benchmarks.
Figures
read the original abstract
Mixture-of-Agents (MoA) architectures improve inference-time scaling by organizing multiple LLM agents into layered reasoning pipelines. However, existing MoA variants fail to sustain gains as depth increases, exhibiting degradation, early plateauing, or saturation. We propose ReM-MoA, a memory-augmented MoA framework that sustains scaling through two mechanisms: (1) a Ranked Reasoning Memory that persistently stores and ranks reasoning traces from all layers using a comparative Reviewer Agent, and (2) a Curated Diversified Memory Routing scheme that exposes different agents to distinct combinations of successful and failed traces, preserving exploration diversity while propagating high-quality reasoning. We further introduce an optional multi-domain Reviewer distillation pipeline that improves ranking quality through frontier-model supervision. Across five reasoning benchmarks spanning math, formal logic, code, knowledge, and commonsense, ReM-MoA consistently outperforms prior MoA variants across both depth and width scaling, and its advantage widens with depth, establishing structured cross-layer reasoning memory as a key missing mechanism for scalable multi-agent inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ReM-MoA, a memory-augmented Mixture-of-Agents (MoA) framework for inference-time scaling. It introduces (1) a Ranked Reasoning Memory that stores and ranks reasoning traces across layers via a comparative Reviewer Agent and (2) Curated Diversified Memory Routing that exposes agents to distinct combinations of successful and failed traces. An optional multi-domain Reviewer distillation pipeline is also described. The central empirical claim is that ReM-MoA consistently outperforms prior MoA variants on five reasoning benchmarks (math, formal logic, code, knowledge, commonsense), with the performance advantage widening as depth increases, thereby establishing structured cross-layer reasoning memory as essential for scalable multi-agent inference.
Significance. If the results and internal validations hold, the work would be significant for identifying a concrete mechanism (persistent ranked memory with diversified routing) that prevents the degradation or plateauing observed in existing MoA depth scaling. The multi-domain benchmark coverage is a positive feature. The optional distillation pipeline and emphasis on preserving exploration diversity are conceptually promising, though their necessity and effectiveness remain to be demonstrated.
major comments (3)
- [Abstract / Methods] Abstract and Methods (implied): The load-bearing claim that the comparative Reviewer Agent produces rankings that reliably boost downstream performance without systematic bias or loss of diversity is asserted but unsupported by any internal validation. No ranking accuracy metrics versus ground truth, no diversity measures (e.g., trace entropy or unique path coverage pre/post-routing), and no ablation isolating the Reviewer Agent are provided, leaving the central assumption untested.
- [Results] Results (implied): The abstract states consistent outperformance and widening gains with depth across five benchmarks, yet the manuscript supplies no quantitative tables, error bars, dataset sizes, statistical tests, or ablation results comparing against prior MoA variants. This absence prevents evaluation of whether the reported advantage is robust or dependent on post-hoc parameter choices such as memory size or routing criteria.
- [Methods (Routing)] § on Curated Diversified Memory Routing: The routing scheme is described as preserving exploration diversity while propagating high-quality traces, but no analysis shows that the combination of ranked memory and routing actually maintains diversity across layers rather than converging on high-ranked traces. This is required for the widening-with-depth claim to hold.
minor comments (2)
- [Methods] Notation for the Reviewer Agent and memory components should be formalized with explicit equations or pseudocode to clarify inputs, outputs, and ranking criteria.
- [Methods] The optional distillation pipeline is mentioned only briefly; its interaction with the core ReM-MoA mechanisms and any ablation showing its contribution should be expanded if retained.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation and validations.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract and Methods (implied): The load-bearing claim that the comparative Reviewer Agent produces rankings that reliably boost downstream performance without systematic bias or loss of diversity is asserted but unsupported by any internal validation. No ranking accuracy metrics versus ground truth, no diversity measures (e.g., trace entropy or unique path coverage pre/post-routing), and no ablation isolating the Reviewer Agent are provided, leaving the central assumption untested.
Authors: We agree that the initial submission would benefit from explicit internal validations of the Reviewer Agent. In the revised manuscript we will add ranking accuracy metrics versus ground truth (on subsets where labels are available), diversity measures including trace entropy and unique path coverage before/after routing, and a dedicated ablation isolating the Reviewer Agent's contribution to overall performance. revision: yes
-
Referee: [Results] Results (implied): The abstract states consistent outperformance and widening gains with depth across five benchmarks, yet the manuscript supplies no quantitative tables, error bars, dataset sizes, statistical tests, or ablation results comparing against prior MoA variants. This absence prevents evaluation of whether the reported advantage is robust or dependent on post-hoc parameter choices such as memory size or routing criteria.
Authors: We acknowledge that the current version lacks sufficiently detailed quantitative reporting. The revision will expand the results section with full tables, error bars, dataset sizes, statistical significance tests, and additional ablations on parameters such as memory size and routing criteria to demonstrate robustness of the reported gains. revision: yes
-
Referee: [Methods (Routing)] § on Curated Diversified Memory Routing: The routing scheme is described as preserving exploration diversity while propagating high-quality traces, but no analysis shows that the combination of ranked memory and routing actually maintains diversity across layers rather than converging on high-ranked traces. This is required for the widening-with-depth claim to hold.
Authors: We agree that an explicit analysis of diversity preservation is needed to support the widening-with-depth claim. The revised manuscript will include layer-wise diversity metrics (e.g., entropy and path coverage) demonstrating that the routing scheme maintains exploration diversity rather than collapsing to high-ranked traces. revision: yes
Circularity Check
No significant circularity; empirical framework with no load-bearing derivations or self-referential reductions
full rationale
The provided abstract and description contain no equations, derivations, or mathematical claims. The core contributions (Ranked Reasoning Memory via Reviewer Agent and Curated Diversified Memory Routing) are presented as architectural proposals validated empirically across benchmarks. No self-citations, fitted parameters renamed as predictions, or ansatzes are visible that would reduce claims to inputs by construction. The paper is self-contained as an empirical proposal without the circular patterns enumerated.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 41st International Conference on Machine Learning (ICML) , year =
Improving Factuality and Reasoning in Language Models through Multiagent Debate , author =. Proceedings of the 41st International Conference on Machine Learning (ICML) , year =
-
[2]
arXiv preprint arXiv:1503.02531 , year =
Distilling the Knowledge in a Neural Network , author =. arXiv preprint arXiv:1503.02531 , year =
-
[3]
Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Liang Wang and Weizhu Chen , booktitle =
Edward J. Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Liang Wang and Weizhu Chen , booktitle =
-
[4]
2025 , publisher =
Dawei Li and Zhen Tan and Peijia Qian and Yifan Li and Kumar Chaudhary and Lijie Hu and Jiayi Shen , booktitle =. 2025 , publisher =
2025
-
[5]
arXiv preprint arXiv:2502.00674 , year =
Rethinking Mixture-of-Agents: Is Mixing Different Large Language Models Beneficial? , author =. arXiv preprint arXiv:2502.00674 , year =
-
[6]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages =
Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate , author =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages =
2024
-
[7]
Hsu and Yanfei Chen and Ke Jiang and Zifeng Wang and Rujun Han and Long T
Siru Ouyang and Jun Yan and I. Hsu and Yanfei Chen and Ke Jiang and Zifeng Wang and Rujun Han and Long T. Le and Shaunak Daruki and Xinyang Tang and Vidisha Tirumalashetty and others , journal =
-
[8]
Heng Ping and Arijit Bhattacharjee and Peiyu Zhang and Shixuan Li and Wei Yang and Anzhe Cheng and Xiaole Zhang and Jesse Thomason and Ali Jannesari and Nesreen Ahmed and Paul Bogdan , journal =
-
[9]
Charlie Snell and Jaehoon Lee and Kelvin Xu and Aviral Kumar , journal =. Scaling
-
[10]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Focused Transformer: Contrastive Training for Context Scaling , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[11]
arXiv preprint arXiv:2203.11171 , year =
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author =. arXiv preprint arXiv:2203.11171 , year =
-
[12]
International Conference on Learning Representations (ICLR) , pages =
Mixture-of-Agents Enhances Large Language Model Capabilities , author =. International Conference on Learning Representations (ICLR) , pages =
-
[13]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[14]
Attention-
Jianyu Wen and Yang Wei and Xiongxi Yu and Changxuan Xiao and Ke Zeng , journal =. Attention-
-
[15]
Zhentao Xie and Chengcheng Han and Jinxin Shi and Wenjun Cui and Wayne Xin Zhao and Xingjiao Wu and Jiabao Zhao , booktitle =
-
[16]
International Conference on Learning Representations (ICLR) , pages =
Diversity Empowers Intelligence: Integrating Expertise of Software Engineering Agents , author =. International Conference on Learning Representations (ICLR) , pages =
-
[17]
Xing and Hao Zhang and others , booktitle =
Lianmin Zheng and Wei-Lin Chiang and Ying Sheng and Siyuan Zhuang and Zhanghao Wu and Yonghao Zhuang and Zi Lin and Zhuohan Li and Dacheng Li and Eric P. Xing and Hao Zhang and others , booktitle =. Judging
-
[18]
Lianghui Zhu and Xinggang Wang and Xinlong Wang , booktitle =
-
[19]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Reflexion: Language Agents with Verbal Reinforcement Learning , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[20]
Hanjun Luo and Shenyu Dai and Chiming Ni and Xinfeng Li and Guibin Zhang and Kun Wang and Tongliang Liu and Hanan Salam , booktitle =
-
[21]
arXiv preprint arXiv:2009.03300 , year =
Measuring Massive Multitask Language Understanding , author =. arXiv preprint arXiv:2009.03300 , year =
Pith/arXiv arXiv 2009
-
[22]
Are We Done with
Aryo Pradipta Gema and Joshua Ong Jun Leang and Giwon Hong and Alessio Devoto and Alberto Carlo Maria Mancino and Rohit Saxena and Xuanli He and Yuhao Zhao and Xiaotang Du and Mohammad Reza Ghasemi Madani and Claire Barale and others , booktitle =. Are We Done with
-
[23]
Measuring Mathematical Problem Solving with the
Dan Hendrycks and Collin Burns and Saurav Kadavath and Akul Arora and Steven Basart and Eric Tang and Dawn Song and Jacob Steinhardt , journal =. Measuring Mathematical Problem Solving with the
-
[24]
arXiv preprint arXiv:2401.03065 , year =
Alex Gu and Baptiste Rozi. arXiv preprint arXiv:2401.03065 , year =
-
[25]
Rowan Zellers and Ari Holtzman and Yonatan Bisk and Ali Farhadi and Yejin Choi , booktitle =
-
[26]
Binyuan Hui and Jian Yang and Zeyu Cui and Jiaxi Yang and Dayiheng Liu and Lei Zhang and Tianyu Liu and Jiajun Zhang and Bowen Yu and Keming Lu and Kai Dang and others , journal =
-
[27]
Aaron Grattafiori and Abhimanyu Dubey and Abhinav Jauhri and Abhinav Pandey and Abhishek Kadian and Ahmad Al-Dahle and Aiesha Letman and Akhil Mathur and Alan Schelten and Amy Yang and others , journal =. The
-
[28]
Efficient Memory Management for Large Language Model Serving with
Woosuk Kwon and Zhuohan Li and Siyuan Zhuang and Ying Sheng and Lianmin Zheng and Cody Hao Yu and Joseph Gonzalez and Hao Zhang and Ion Stoica , booktitle =. Efficient Memory Management for Large Language Model Serving with
-
[29]
An Yang and Baosong Yang and Beichen Zhang and Binyuan Hui and Bo Zheng and Bowen Yu and Chengyuan Li and Dayiheng Liu and Fei Huang and Haoran Wei and Huan Lin and others , journal =
-
[30]
Think You Have Solved Question Answering? Try
Peter Clark and Isaac Cowhey and Oren Etzioni and Tushar Khot and Ashish Sabharwal and Carissa Schoenick and Oyvind Tafjord , journal =. Think You Have Solved Question Answering? Try
-
[31]
Applied Sciences , volume =
What Disease Does This Patient Have? A Large-Scale Open Domain Question Answering Dataset from Medical Exams , author =. Applied Sciences , volume =
-
[32]
arXiv preprint arXiv:2108.07732 , year =
Program Synthesis with Large Language Models , author =. arXiv preprint arXiv:2108.07732 , year =
-
[33]
2025 , organization=
Ping, Heng and Li, Shixuan and Zhang, Peiyu and Cheng, Anzhe and Duan, Shukai and Kanakaris, Nikos and Xiao, Xiongye and Yang, Wei and Nazarian, Shahin and Irimia, Andrei and Bogdan, Paul , booktitle=. 2025 , organization=
2025
-
[34]
Ping, Heng and Zhang, Peiyu and Li, Shixuan and Yang, Wei and Cheng, Anzhe and Duan, Shukai and Zhang, Xiaole and Bogdan, Paul , journal=
-
[35]
Ping, Heng and Zhang, Peiyu and Wang, Zhenkun and Li, Shixuan and Cheng, Anzhe and Yang, Wei and Bogdan, Paul and Nazarian, Shahin , journal=
-
[36]
Auditing Multi-Agent
Yang, Wei and Li, Shixuan and Ping, Heng and Zhang, Peiyu and Bogdan, Paul and Thomason, Jesse , journal=. Auditing Multi-Agent
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.