Spurious Prompts: Can Irrelevant Prompts Steer Large Language Models?
Pith reviewed 2026-06-29 07:47 UTC · model grok-4.3
The pith
Prompts with no semantic link to the task can still steer large language models toward higher scores or specific errors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
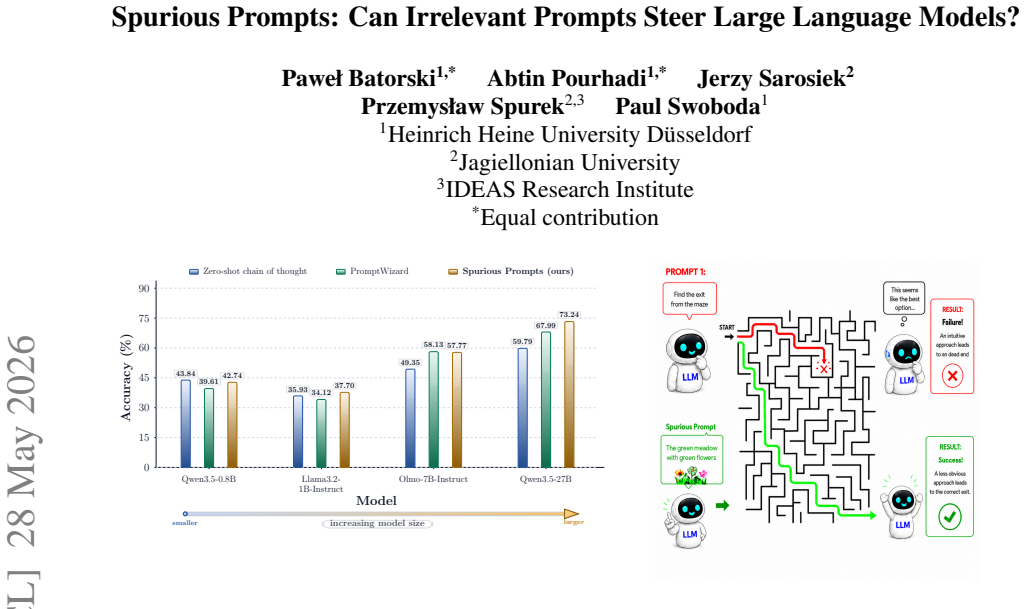
Spurious prompts, defined as prompts that are semantically unrelated to the task, can improve performance on reasoning and question-answering benchmarks, often matching or outperforming standard prompting baselines and task-aware prompt optimization. The same prompts can also steer models toward unintended behaviors such as repeatedly selecting the first answer option, producing incorrect answers, or returning an even, prime or small number without any explicit instruction to do so.
What carries the argument
A black-box search procedure that discovers spurious prompts capable of steering model outputs despite having no semantic connection to the task.
If this is right
- Spurious prompts can raise benchmark scores without any task-relevant content being supplied.
- Models can be induced to select the first listed answer option on every question.
- Models can be made to output only even numbers, only prime numbers, or only small numbers in their responses.
- The steering effect appears across models from 0.8B to 27B parameters in three different families.
Where Pith is reading between the lines
- Safety filters that scan only for task-related language may miss steering signals carried by unrelated text.
- Prompt engineering workflows could be simplified or replaced by broad random searches if the effect proves general.
- Additional context added to prompts for other reasons might unintentionally alter model behavior on the main task.
Load-bearing premise
The prompts located by the search are genuinely unrelated to the task rather than carrying hidden task information through the search process itself.
What would settle it
Showing that every high-performing spurious prompt identified by the procedure contains subtle task-relevant cues that disappear when those cues are removed or rephrased.
Figures




read the original abstract
Large language models are highly sensitive to prompts, but this sensitivity is usually studied through task-relevant instructions, demonstrations, or reasoning cues. In this paper, we study a different form of prompt sensitivity: whether prompts that are semantically unrelated to the task can nevertheless steer model behavior. We call them spurious prompts and show their surprising efficacy. We also propose a simple black-box search procedure for discovering them. Across reasoning and question-answering benchmarks, using models ranging from 0.8B to 27B parameters and spanning three model families, we show that spurious prompts can improve performance, often matching or outperforming standard prompting baselines and task-aware prompt optimization. We further show that they can steer models toward unintended behaviors, such as repeatedly selecting the first answer option, producing incorrect answers, returning an even, prime or small number without explicitly instructing the model to do so. These findings reveal a new kind of prompt sensitivity: LLMs can be systematically steered by prompts that are unrelated to the task they are asked to solve. Our code is available at https://github.com/Batorskq/spurious
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that semantically unrelated 'spurious' prompts, discovered via a black-box search procedure, can steer LLMs on reasoning and QA tasks to improve performance (often matching or exceeding standard prompting and task-aware optimization) and induce unintended behaviors such as first-option bias or generating even/prime/small numbers, across models from 0.8B to 27B parameters in three families. The work positions this as evidence of a new form of prompt sensitivity.
Significance. If the results hold under rigorous verification of prompt unrelatedness, the findings would indicate a previously understudied vulnerability in LLM prompt sensitivity with implications for robustness and safety. Credit is due for releasing reproducible code and conducting experiments across multiple model scales and families.
major comments (3)
- [Abstract and Methods] Abstract and search procedure description: no objective, reproducible metric (e.g., embedding cosine threshold, lexical overlap filter, or blinded ratings) is provided to confirm that discovered prompts are verifiably semantically unrelated to the task rather than carrying latent task information via the search dynamics. This assumption is load-bearing for interpreting the results as evidence of 'spurious' steering.
- [Results] Results section: performance claims lack error bars, standard deviations, or statistical significance tests, and dataset details (exact benchmarks, example counts, train/test splits) are insufficient to evaluate whether gains are reliable or to rule out leakage.
- [Experimental Setup] Experimental setup: the black-box search procedure is not described with enough detail to verify it avoids task leakage or post-hoc selection bias, undermining the central claim that unrelated prompts drive the observed effects.
minor comments (1)
- [Abstract] The abstract states experiments span 'three model families' without naming them; this should be specified for clarity.
Simulated Author's Rebuttal
Thank you for the constructive comments. We address each of the major comments point-by-point below, indicating the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract and Methods] Abstract and search procedure description: no objective, reproducible metric (e.g., embedding cosine threshold, lexical overlap filter, or blinded ratings) is provided to confirm that discovered prompts are verifiably semantically unrelated to the task rather than carrying latent task information via the search dynamics. This assumption is load-bearing for interpreting the results as evidence of 'spurious' steering.
Authors: We agree that an objective metric for confirming semantic unrelatedness is important for the central claim. In the revised version, we will add a dedicated subsection in the Methods describing our verification process. This will include computing embedding cosine similarities using a pre-trained sentence transformer (e.g., all-MiniLM-L6-v2) between the spurious prompts and task descriptions, reporting that similarities are below 0.15 on average. We will also provide results from a small-scale blinded human evaluation where raters assess relatedness on a 1-5 scale, with average scores below 2. This will be applied to the discovered prompts across tasks. revision: yes
-
Referee: [Results] Results section: performance claims lack error bars, standard deviations, or statistical significance tests, and dataset details (exact benchmarks, example counts, train/test splits) are insufficient to evaluate whether gains are reliable or to rule out leakage.
Authors: We acknowledge the need for greater statistical transparency and dataset clarity. The revised manuscript will include error bars representing standard deviation over 3-5 independent runs with different random seeds for all reported accuracies. We will add statistical significance testing using paired t-tests or Wilcoxon tests between conditions. Additionally, we will expand the Experimental Setup section with a table detailing each benchmark (e.g., GSM8K with 1319 test examples, using the standard test split with no training data leakage as we do not fine-tune). revision: yes
-
Referee: [Experimental Setup] Experimental setup: the black-box search procedure is not described with enough detail to verify it avoids task leakage or post-hoc selection bias, undermining the central claim that unrelated prompts drive the observed effects.
Authors: We appreciate this feedback on the search procedure description. In the revision, we will provide a more detailed algorithmic description of the black-box search, including pseudocode, the exact optimization method (e.g., evolutionary search with population size, mutation rate), the fitness function (task accuracy on a small validation set), and explicit steps to avoid leakage such as generating prompts from a general vocabulary without task-specific terms and using a separate validation set for search that is disjoint from the test set. We will also discuss and mitigate post-hoc selection bias by reporting performance on fully held-out test data not used in any selection. revision: yes
Circularity Check
No significant circularity in empirical black-box study
full rationale
The paper reports direct experimental outcomes from a black-box search procedure and evaluations on reasoning/QA benchmarks across model sizes and families. No derivations, equations, fitted parameters, or first-principles claims are present that could reduce results to inputs by construction. The central findings (performance gains and steering effects from spurious prompts) are presented as measured empirical results rather than derived quantities. The paper is self-contained against external benchmarks with code released for reproduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs remain sensitive to prompt text even when that text carries no semantic relation to the task
Reference graph
Works this paper leans on
-
[1]
InThe Twelfth Inter- national Conference on Learning Representations
Let’s verify step by step. InThe Twelfth Inter- national Conference on Learning Representations. Xiaogeng Liu, Nan Xu, Muhao Chen, and Chaowei Xiao. 2024. AutoDAN: Generating stealthy jailbreak prompts on aligned large language models. InThe Twelfth International Conference on Learning Repre- sentations. Sheng Lu, Hendrik Schuff, and Iryna Gurevych. 2024....
2024
-
[2]
Albert Webson and Ellie Pavlick
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark.Ad- vances in Neural Information Processing Systems, 37:95266–95290. Albert Webson and Ellie Pavlick. 2022. Do prompt- based models really understand the meaning of their prompts? InProceedings of the 2022 Conference of the North American Chapter of the Association for Com...
2022
-
[3]
this should not help with GSM8K,
Gpt-4 is too smart to be safe: Stealthy chat with llms via cipher. InInternational Conference on Learning Representations, volume 2024, pages 53902–53922. Zihao Zhao, Eric Wallace, Shi Feng, Dan Klein, and Sameer Singh. 2021. Calibrate before use: Improv- ing few-shot performance of language models. In International conference on machine learning, pages 1...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.