The Topology of Ill-Posed Questions: Persistent Homology for Detection and Steering in LLMs
Pith reviewed 2026-06-26 08:30 UTC · model grok-4.3
The pith
Persistent homology on per-layer hidden-state point clouds detects ill-posed questions more accurately than prompt or pooled baselines and supplies steering vectors that raise acceptable response rates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
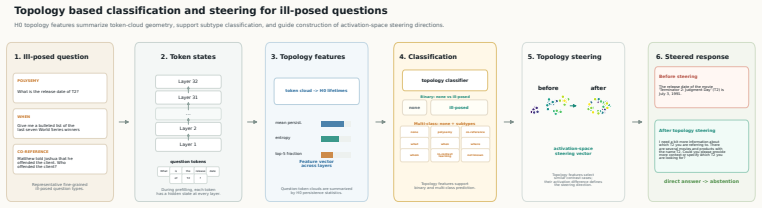
Diverse sources of ill-posedness produce a shared topological structure in the zero-dimensional persistent homology of per-layer point clouds formed by prompt-token hidden states; three summary statistics of that structure suffice both to classify the question and to retrieve useful examples for activation steering.
What carries the argument
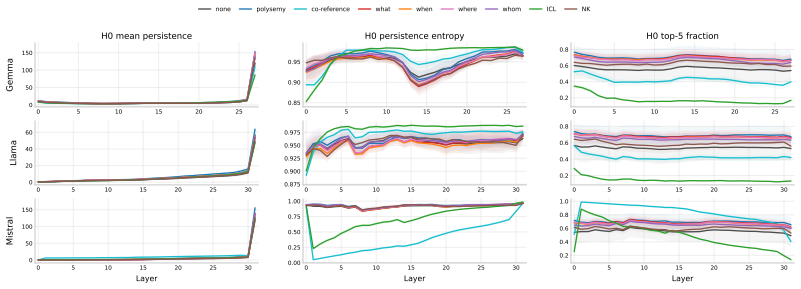
Three compact descriptors (mean finite lifetime, normalized lifetime entropy, largest-lifetime concentration) extracted from zero-dimensional persistent homology on per-layer point clouds of prompt-token hidden states, concatenated across layers to form the input representation.
If this is right
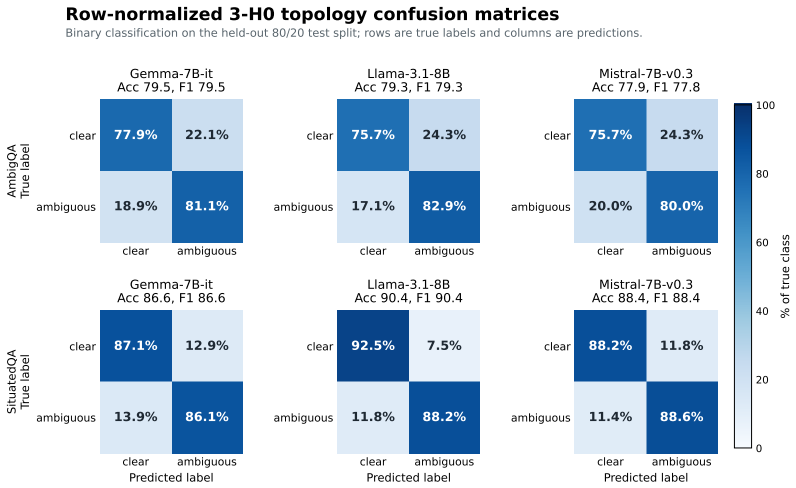
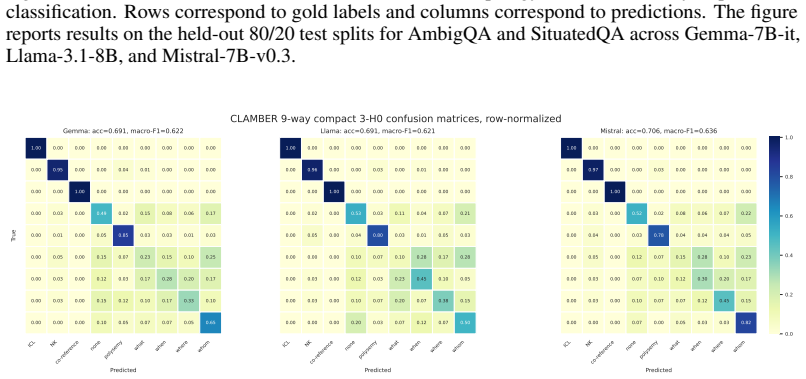
- Topology features raise average classification accuracy from 67.4% to 78.9% on AmbigQA, from 79.9% to 88.5% on SituatedQA, and from 57.6% to 69.6% on CLAMBER 9-way classification.
- Topology-conditioned activation steering lifts average total acceptable response rate from 61.4% to 70.6% and grounded acceptable responses from 11.9% to 16.4%.
- The same representation works across three different open-weight LLMs without task-specific retraining.
- The method supplies both a classifier and a concrete steering procedure that uses the retrieved examples to construct query-specific activation interventions.
Where Pith is reading between the lines
- The same per-layer lifetime statistics could be tested on other model behaviors such as hallucination or refusal.
- Replacing the three summary numbers with the full persistence diagram might yield still richer steering signals.
- The approach could be combined with existing uncertainty-estimation techniques to decide when clarification is worth requesting.
Load-bearing premise
The three descriptors extracted from zero-dimensional persistent homology are assumed to capture a single transferable signature that covers many different sources of ill-posedness.
What would settle it
A new collection of contradictory or underspecified questions on which the three topology descriptors produce no accuracy gain over prompt-based and pooled-hidden-state baselines would falsify the unified-representation claim.
Figures

read the original abstract
Ill-posed questions, including ambiguous, underspecified, or contradictory queries, may admit no valid answer or multiple plausible answers, posing a challenge for large language models (LLMs). Existing approaches largely analyze ill-posedness through model outputs and often focus on specific subclasses. We investigate whether diverse sources of ill-posedness can be represented within a unified topology of LLM internal states and whether this structure can be used to steer response behavior. We model the contextual hidden states of prompt tokens at each transformer layer as a point cloud and characterize its geometry using finite zero-dimensional persistent homology. Each layer is summarized by three compact descriptors: mean finite lifetime, normalized lifetime entropy, and largest-lifetime concentration. Concatenating these descriptors across layers yields a topology representation of the question. We further introduce topology-conditioned activation steering, which retrieves topologically similar examples and constructs query-specific activation interventions that encourage source-aware clarification or abstention. Across three open-weight LLMs, topology features consistently outperform prompt-based and pooled-hidden-state baselines for ill-posedness classification, improving average accuracy from \(67.4\%\) to \(78.9\%\) on AmbigQA, from \(79.9\%\) to \(88.5\%\) on SituatedQA, and from \(57.6\%\) to \(69.6\%\) on CLAMBER 9-way classification. Topology-conditioned steering increases the average total acceptable response rate from \(61.4\%\) to \(70.6\%\) and grounded acceptable responses from \(11.9\%\) to \(16.4\%\). These results show that persistent homology provides both an interpretable representation of ill-posedness and an effective mechanism for targeted response steering.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that zero-dimensional persistent homology applied to per-layer point clouds of prompt-token hidden states in LLMs yields three compact descriptors (mean finite lifetime, normalized lifetime entropy, largest-lifetime concentration) whose concatenation across layers forms an effective representation of ill-posedness; this representation outperforms prompt-based and pooled-hidden-state baselines on classification of ambiguous/underspecified queries (AmbigQA, SituatedQA, CLAMBER) and enables topology-conditioned activation steering that raises acceptable response rates.
Significance. If the empirical gains hold under proper statistical controls and ablations, the work supplies a novel, interpretable topological lens on LLM internal states for detecting and mitigating ill-posed inputs, extending TDA techniques into activation steering with potential transferability across models and query types.
major comments (2)
- [Abstract, §4] Abstract and §4 (results): the reported accuracy lifts (67.4%→78.9%, 79.9%→88.5%, 57.6%→69.6%) and steering improvements (61.4%→70.6%, 11.9%→16.4%) are presented without reported standard deviations, number of runs, or significance tests; this leaves open whether the gains are robust or sensitive to random seeds and baseline re-implementations.
- [Abstract] Abstract (weakest assumption): the three descriptors are concatenated and treated as a single transferable representation of diverse ill-posedness sources for both the classifier and the steering retrieval step; no ablation is referenced showing that the joint vector is required or that the descriptors separately capture distinct sources (ambiguity vs. contradiction vs. underspecification).
minor comments (2)
- [Abstract] The abstract states improvements on three datasets but does not specify the exact train/test splits or whether any hyper-parameters were tuned on the test sets; a methods subsection should clarify this to rule out leakage.
- [§3] Notation for the three descriptors (mean finite lifetime, normalized lifetime entropy, largest-lifetime concentration) is introduced without an equation reference; adding explicit formulas in §3 would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to incorporate the requested statistical reporting and ablation analysis.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (results): the reported accuracy lifts (67.4%→78.9%, 79.9%→88.5%, 57.6%→69.6%) and steering improvements (61.4%→70.6%, 11.9%→16.4%) are presented without reported standard deviations, number of runs, or significance tests; this leaves open whether the gains are robust or sensitive to random seeds and baseline re-implementations.
Authors: We agree that standard deviations, run counts, and significance tests are necessary to establish robustness. In the revised manuscript we will report all classification and steering results as means over at least five independent runs (different random seeds for data splits and model inference), include standard deviations, and add paired statistical tests (McNemar for classification, bootstrap for steering rates) against the baselines. revision: yes
-
Referee: [Abstract] Abstract (weakest assumption): the three descriptors are concatenated and treated as a single transferable representation of diverse ill-posedness sources for both the classifier and the steering retrieval step; no ablation is referenced showing that the joint vector is required or that the descriptors separately capture distinct sources (ambiguity vs. contradiction vs. underspecification).
Authors: The three descriptors are motivated by complementary geometric properties (mean lifetime for scale, entropy for lifetime diversity, concentration for feature dominance). The original submission did not contain an explicit ablation of the concatenated vector versus its components. We will add this ablation in revision, evaluating single-descriptor and pairwise subsets on each dataset and showing that the full concatenation yields the highest accuracy and steering gains, thereby confirming that the descriptors supply non-redundant information across ill-posedness types. revision: yes
Circularity Check
No significant circularity
full rationale
The paper reports empirical classification accuracies and steering improvements using zero-dimensional persistent homology descriptors (mean finite lifetime, normalized lifetime entropy, largest-lifetime concentration) extracted from per-layer hidden-state point clouds, evaluated against prompt-based and pooled-hidden-state baselines on public datasets (AmbigQA, SituatedQA, CLAMBER). No equation or derivation reduces these descriptors or the steering vectors to quantities fitted on the target test data; the topology representation is constructed directly from model internals without self-referential fitting or self-citation load-bearing steps. The central claims rest on external performance comparisons rather than any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sur les problèmes aux dérivées partielles et leur signification physique
Jacques Hadamard. Sur les problèmes aux dérivées partielles et leur signification physique. In Princeton University Bulletin, page 49–52, 1902
1902
-
[2]
Ambigqa: Answering ambiguous open-domain questions
Sewon Min, Julian Michael, Hannaneh Hajishirzi, and Luke Zettlemoyer. Ambigqa: Answering ambiguous open-domain questions. InProceedings of the 2020 conference on empirical methods in natural language processing (EMNLP), pages 5783–5797, 2020
2020
-
[3]
Asqa: Factoid questions meet long-form answers
Ivan Stelmakh, Yi Luan, Bhuwan Dhingra, and Ming-Wei Chang. Asqa: Factoid questions meet long-form answers. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 8273–8288, 2022
2022
-
[4]
Clamber: A benchmark of identifying and clarifying ambiguous information needs in large language models
Tong Zhang, Peixin Qin, Yang Deng, Chen Huang, Wenqiang Lei, Junhong Liu, Dingnan Jin, Hongru Liang, and Tat-Seng Chua. Clamber: A benchmark of identifying and clarifying ambiguous information needs in large language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10746–10766, 2024
2024
-
[5]
Situatedqa: Incorporating extra-linguistic contexts into qa
Michael Zhang and Eunsol Choi. Situatedqa: Incorporating extra-linguistic contexts into qa. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 7371–7387, 2021
2021
-
[6]
Large language models struggle with unreasonability in math problems
Jingyuan Ma, Damai Dai, Zihang Yuan, Rui Li, Weilin Luo, Bin Wang, Qun Liu, Lei Sha, and Zhifang Sui. Large language models struggle with unreasonability in math problems. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 32428–32436, 2026
2026
-
[7]
Boyang Xue, Qi Zhu, Rui Wang, Sheng Wang, Hongru Wang, Minda Hu, Fei Mi, Yasheng Wang, Lifeng Shang, Qun Liu, et al. Reliablemath: Benchmark of reliable mathematical reasoning on large language models.arXiv preprint arXiv:2507.03133, 2025
-
[8]
Selectively answering ambiguous questions
Jeremy Cole, Michael Zhang, Dan Gillick, Julian Eisenschlos, Bhuwan Dhingra, and Jacob Eisenstein. Selectively answering ambiguous questions. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 530–543, 2023
2023
-
[9]
Asking clarifying questions in open-domain information-seeking conversations
Mohammad Aliannejadi, Hamed Zamani, Fabio Crestani, and W Bruce Croft. Asking clarifying questions in open-domain information-seeking conversations. InProceedings of the 42nd international acm sigir conference on research and development in information retrieval, pages 475–484, 2019
2019
-
[10]
Asking clarification questions to handle ambiguity in open-domain qa
Dongryeol Lee, Segwang Kim, Minwoo Lee, Hwanhee Lee, Joonsuk Park, Sang-Woo Lee, and Kyomin Jung. Asking clarification questions to handle ambiguity in open-domain qa. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 11526–11544, 2023
2023
-
[11]
Zeyu Fang, Tian Lan, and Mahdi Imani. Mint: Minimal information neuro-symbolic tree for objective-driven knowledge-gap reasoning and active elicitation.arXiv preprint arXiv:2602.05048, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
Inference- time intervention: Eliciting truthful answers from a language model.Advances in Neural Information Processing Systems, 36:41451–41530, 2023
Kenneth Li, Oam Patel, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg. Inference- time intervention: Eliciting truthful answers from a language model.Advances in Neural Information Processing Systems, 36:41451–41530, 2023
2023
-
[13]
Representation Engineering: A Top-Down Approach to AI Transparency
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, et al. Representation engineering: A top-down approach to ai transparency.arXiv preprint arXiv:2310.01405, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Steering llama 2 via contrastive activation addition
Nina Rimsky, Nick Gabrieli, Julian Schulz, Meg Tong, Evan Hubinger, and Alexander Turner. Steering llama 2 via contrastive activation addition. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15504–15522, 2024. 10
2024
-
[15]
Refusal in language models is mediated by a single direction.Advances in Neural Information Processing Systems, 37:136037–136083, 2024
Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Panickssery, Wes Gurnee, and Neel Nanda. Refusal in language models is mediated by a single direction.Advances in Neural Information Processing Systems, 37:136037–136083, 2024
2024
-
[16]
Detecting (un) answerability in large language models with linear directions
Maor Juliet Lavi, Tova Milo, and Mor Geva. Detecting (un) answerability in large language models with linear directions. InProceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 682–699, 2026
2026
-
[17]
Sparse neurons carry strong signals of question ambiguity in llms
Zhuoxuan Zhang, Jinhao Duan, Edward Kim, and Kaidi Xu. Sparse neurons carry strong signals of question ambiguity in llms. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 16092–16110, 2025
2025
-
[18]
Barcodes: the persistent topology of data.Bulletin of the American Mathematical Society, 45(1):61–75, 2008
Robert Ghrist. Barcodes: the persistent topology of data.Bulletin of the American Mathematical Society, 45(1):61–75, 2008
2008
-
[19]
Persistent homology: An introduction and a new text representation for natural language processing
Xiaojin Zhu. Persistent homology: An introduction and a new text representation for natural language processing. InIjcai, number 2013, pages 1953–1959, 2013
2013
-
[20]
Persistence images: A stable vector representation of persistent homology.Journal of Machine Learning Research, 18(8):1–35, 2017
Henry Adams, Tegan Emerson, Michael Kirby, Rachel Neville, Chris Peterson, Patrick Shipman, Sofya Chepushtanova, Eric Hanson, Francis Motta, and Lori Ziegelmeier. Persistence images: A stable vector representation of persistent homology.Journal of Machine Learning Research, 18(8):1–35, 2017
2017
-
[21]
Aligning language models to explicitly handle ambiguity
Hyuhng Joon Kim, Youna Kim, Cheonbok Park, Junyeob Kim, Choonghyun Park, Kang Min Yoo, Sang-goo Lee, and Taeuk Kim. Aligning language models to explicitly handle ambiguity. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 1989–2007, 2024
2024
-
[22]
The shape of word embeddings: Quantifying non-isometry with topological data analysis
Ondˇrej Draganov and Steven Skiena. The shape of word embeddings: Quantifying non-isometry with topological data analysis. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 12080–12099, 2024
2024
-
[23]
Local topology measures of contextual language model latent spaces with applications to dialogue term extraction
Benjamin Matthias Ruppik, Michael Heck, Carel van Niekerk, Renato Vukovic, Hsien-Chin Lin, Shutong Feng, Marcus Zibrowius, and Milica Gasic. Local topology measures of contextual language model latent spaces with applications to dialogue term extraction. InProceedings of the 25th Annual Meeting of the Special Interest Group on Discourse and Dialogue, page...
2024
-
[24]
Thomas Roland Barillot and Alex De Castro. Blowfish: Topological and statistical signatures for quantifying ambiguity in semantic search.arXiv preprint arXiv:2406.07990, 2024
-
[25]
Persistent topological features in large language models
Yuri Gardinazzi, Karthik Viswanathan, Giada Panerai, Alessio Ansuini, Alberto Cazzaniga, and Matteo Biagetti. Persistent topological features in large language models. InInternational Conference on Machine Learning, pages 18811–18830. PMLR, 2025
2025
-
[26]
Zuyuan Zhang, Sizhe Tang, and Tian Lan. Cochain perspectives on temporal-difference signals for learning beyond markov dynamics.arXiv preprint arXiv:2602.06939, 2026
-
[27]
Zuyuan Zhang, Zeyu Fang, and Tian Lan. Structuring value representations via geometric coherence in markov decision processes.arXiv preprint arXiv:2602.02978, 2026
-
[28]
Über den höheren zusammenhang kompakter räume und eine klasse von zusammenhangstreuen abbildungen.Mathematische Annalen, 97(1):454–472, 1927
Leopold Vietoris. Über den höheren zusammenhang kompakter räume und eine klasse von zusammenhangstreuen abbildungen.Mathematische Annalen, 97(1):454–472, 1927
1927
-
[29]
Pearson Education India, 2006
Jon Kleinberg and Eva Tardos.Algorithm design. Pearson Education India, 2006
2006
-
[30]
Gemma: Open Models Based on Gemini Research and Technology
Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivière, Mihir Sanjay Kale, Juliette Love, et al. Gemma: Open models based on gemini research and technology.arXiv preprint arXiv:2403.08295, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024. 11
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mistral 7b, 2023. URL https://arxi...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. Clam: Selective clarification for ambiguous questions with generative language models.arXiv preprint arXiv:2212.07769, 2022
-
[34]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
2022
-
[35]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025. A Dataset Details and Classification Baselines This appendix provides additional details on the datasets, splits, classification baselines, and pars...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
whether the response recognizes that the user query is ill-posed, and
-
[37]
Who won the final?
whether the response is grounded in the specific content of the query. An ill-posed query may be ambiguous, underspecified, missing a condition, missing temporal/spatial/personal/task-specific information, internally contradictory, or dependent on information not provided in the query. There are four classes of responses: GROUNDED_ACCEPTABLE: The response...
2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.