Continuous Behavioral Synthesis for Adaptive Health Dashboards: An LLM-Mediated Architecture Integrating Explicit Preference, Spatial Reorganization, and Attention Allocation Signals
Pith reviewed 2026-06-26 02:51 UTC · model grok-4.3
The pith
Large language models can turn sparse user signals from clicks, drags, and hover times into coherent real-time dashboard adaptations without training data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
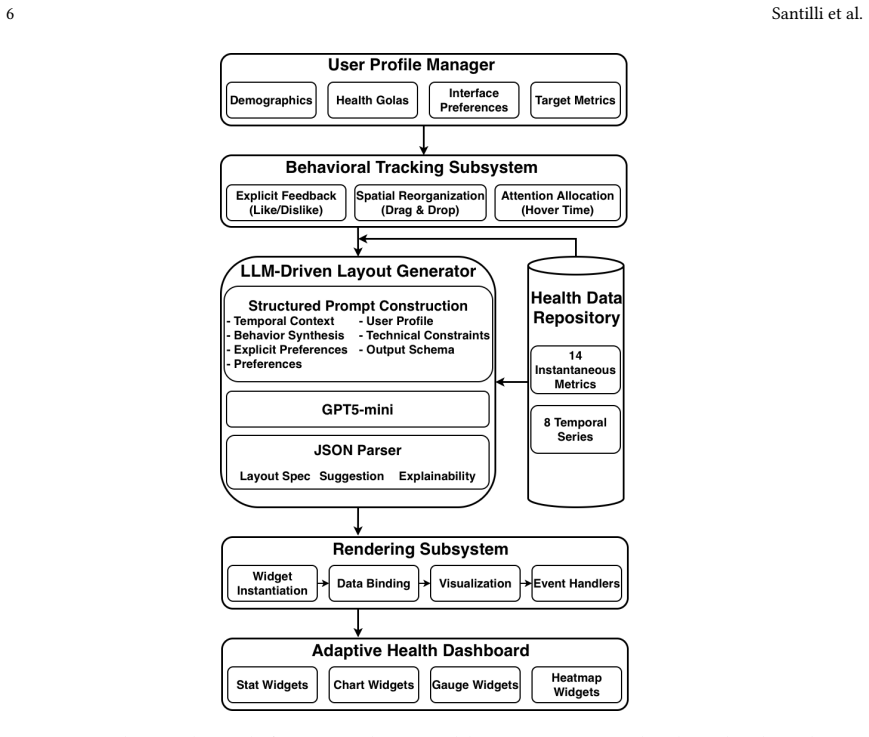
The architecture demonstrates that large language models can serve as behavioral synthesis engines, integrating three channels of user input—explicit micro-feedback on elements, spatial priority from drag-and-drop reorganization, and attentional investment from hover dwell times—within a layered prompt construction process that separates temporal context, signal extraction, preference enforcement, and profile synthesis to produce adapted dashboard layouts.
What carries the argument
The layered prompt construction methodology that separates temporal context determination, behavioral signal extraction, explicit preference enforcement, and user profile synthesis to reconcile multiple signals into design decisions.
If this is right
- Profile-driven initialization and multi-signal adaptation can be compared directly in health dashboard scenarios.
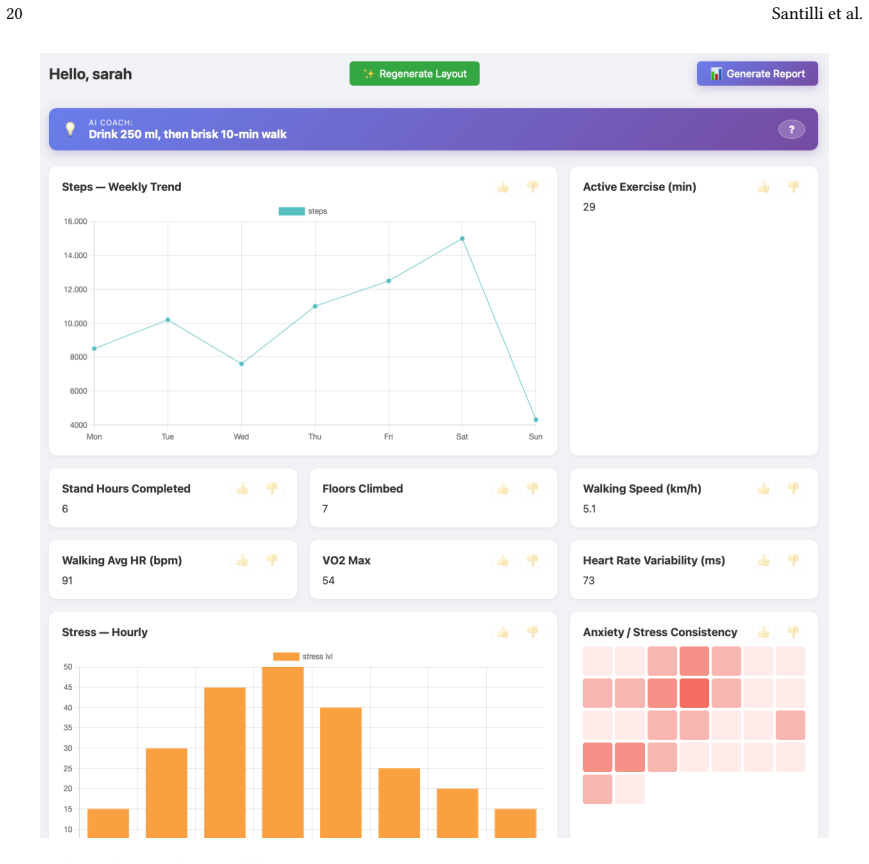
- Fourteen distinct health metrics can be managed across seven widget visualization modalities with continuous regeneration.
- Multiple simultaneous behavioral signals can be reconciled even when they would be difficult to encode in explicit rules.
- Analytical evaluation of adaptation behavior becomes possible alongside working implementations.
Where Pith is reading between the lines
- The method could extend to other interface domains where quick personalization from minimal data is needed, such as productivity or education tools.
- Long-term consistency of adaptations might require additional mechanisms to track and correct drift in LLM outputs.
- User studies measuring task completion or satisfaction before and after adaptation would provide direct evidence of practical value.
Load-bearing premise
The layered prompt construction methodology allows an LLM to reliably translate low-level interaction patterns into coherent high-level design decisions without external fine-tuning or additional safeguards.
What would settle it
A test run in which conflicting user signals (such as feedback favoring one layout while drags and hovers favor another) produce inconsistent or incoherent dashboard outputs across repeated identical sessions.
Figures

read the original abstract
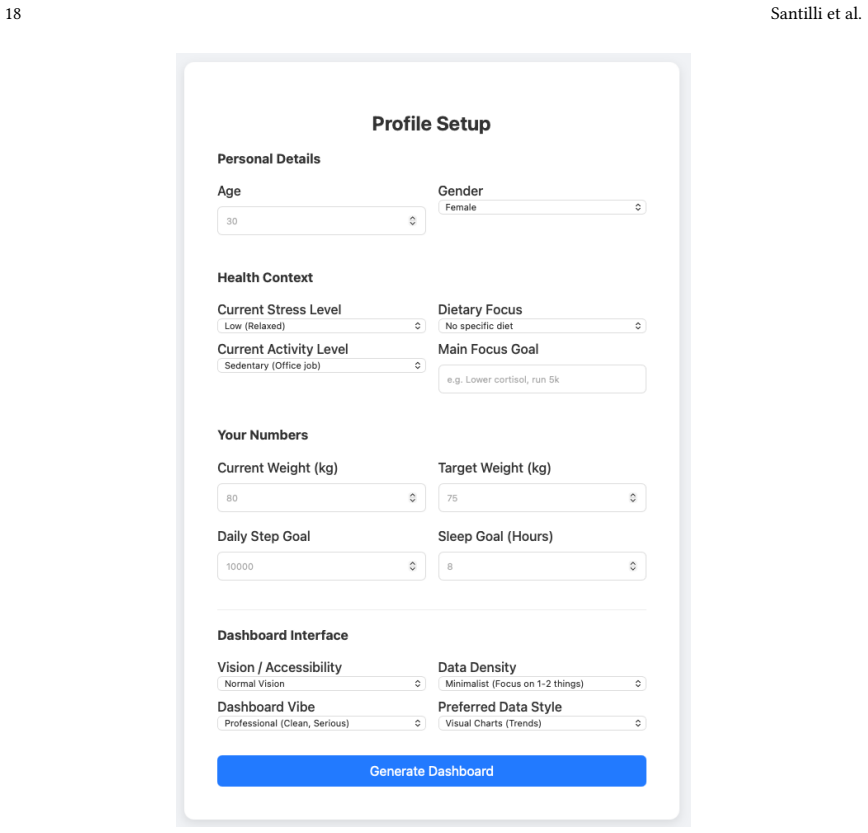
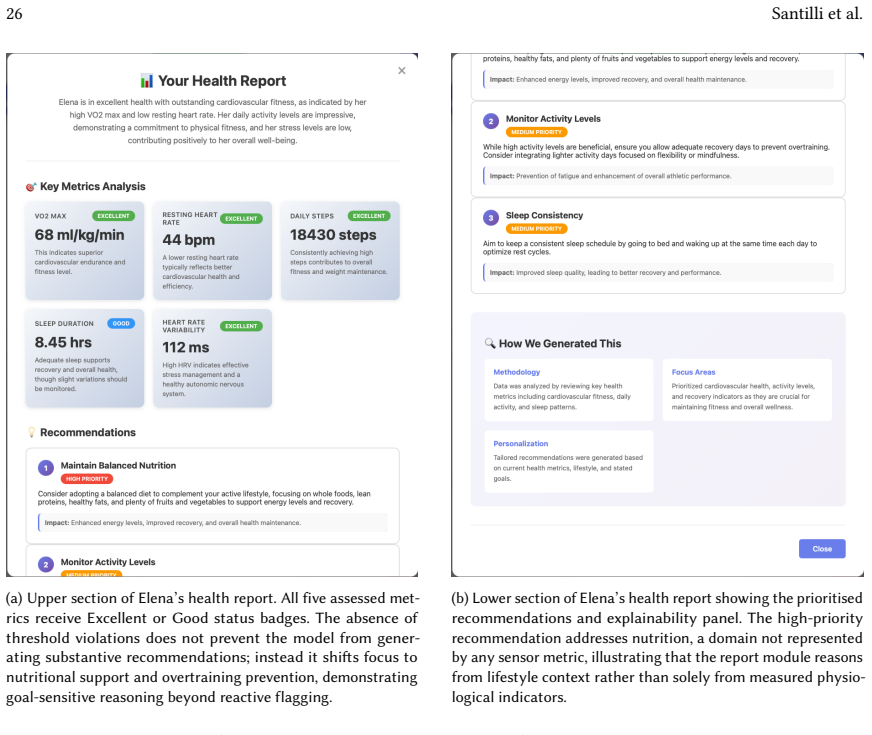
The engineering of adaptive user interfaces has traditionally relied on either rule-based systems encoding designer intuitions about user needs or machine learning approaches requiring substantial historical data before achieving effective personalization. We present a technical architecture that leverages Large Language Models as behavioral synthesis engines to enable immediate adaptation from sparse, heterogeneous user signals. Our system integrates three distinct behavioral channels, i) explicit micro-feedback on individual interface elements, ii) spatial priority inferred from manual widget reorganization through drag-and-drop interaction, iii) and attentional investment measured through dwell time during hover events, within a structured prompt engineering framework that continuously regenerates dashboard layouts while maintaining explanatory coherence. The architecture addresses the technical challenge of translating low-level interaction patterns into high-level design decisions through a layered prompt construction methodology that separates temporal context determination, behavioral signal extraction, explicit preference enforcement, and user profile synthesis. The approach combines manually specified behavioral interpretations and temporal heuristics with LLM-mediated synthesis, enabling the reconciliation of multiple simultaneous signals that would be difficult to encode through explicit rules alone. We demonstrate the system through an instantiation in the personal health monitoring domain, including an analytical evaluation of adaptation behavior across multiple scenarios and a working implementation managing fourteen distinct health metrics across seven widget visualization modalities. The evaluation compares profile-driven initialization, multi-signal behavioral adaptation, and presents the resulting interfaces through representative post-adaptation screenshots.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a technical architecture that uses LLMs as behavioral synthesis engines for continuous adaptation of health dashboards. It integrates three heterogeneous signals—explicit micro-feedback on elements, spatial priority from drag-and-drop reorganization, and attentional investment from hover dwell time—via a layered prompt construction process (temporal context determination, behavioral signal extraction, explicit preference enforcement, and user profile synthesis). The system is instantiated for personal health monitoring with 14 metrics across 7 visualization modalities, supported by an analytical evaluation across scenarios and representative screenshots of adapted interfaces.
Significance. If the prompt-layered synthesis reliably produces stable, preference-aligned layouts from sparse signals, the architecture would offer a meaningful advance in adaptive UIs by enabling immediate personalization without large datasets or hand-crafted rules, with potential value for health-monitoring applications in HCI.
major comments (2)
- [Evaluation] Evaluation section: The paper describes an 'analytical evaluation across multiple scenarios' and presents post-adaptation screenshots, but reports no quantitative metrics (e.g., output consistency across LLM runs, preference alignment scores, or usability measures), no baselines, and no error analysis. This leaves the central claim that the architecture 'enables immediate adaptation' and 'reconciles multiple simultaneous signals' without empirical support.
- [Architecture] Architecture / Prompt Engineering section: The four-stage layered prompt methodology is presented as the mechanism for translating low-level signals into coherent high-level decisions, yet the manuscript provides no concrete prompt templates, conflict-resolution rules, or safeguards against inconsistent LLM outputs. This assumption is load-bearing for the claim of reliable synthesis without fine-tuning.
minor comments (2)
- [Abstract] Abstract: The list of behavioral channels begins with 'i)' but the subsequent items are labeled 'ii)' and 'iii)'; numbering should be consistent.
- [Implementation] Implementation description: The 14-metric, 7-modality instantiation is noted, but the specific LLM model, temperature settings, or example prompt sequences are not supplied, limiting reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below with clarifications on the current manuscript and indicate planned revisions where appropriate.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: The paper describes an 'analytical evaluation across multiple scenarios' and presents post-adaptation screenshots, but reports no quantitative metrics (e.g., output consistency across LLM runs, preference alignment scores, or usability measures), no baselines, and no error analysis. This leaves the central claim that the architecture 'enables immediate adaptation' and 'reconciles multiple simultaneous signals' without empirical support.
Authors: The evaluation in the manuscript is explicitly framed as analytical, using scenario-based walkthroughs and screenshots to illustrate how the layered prompt methodology processes and reconciles the three signal types. This approach was chosen to focus on the architectural mechanisms rather than LLM benchmarking or user studies, which would require separate experimental designs. We agree that the absence of quantitative metrics such as consistency across runs or alignment scores limits the strength of claims about reliability. In revision we will expand the evaluation section to include a discussion of these limitations and outline a quantitative evaluation protocol (e.g., repeated-run consistency and simulated preference alignment) as future work, while retaining the analytical component as the core demonstration of the architecture. revision: partial
-
Referee: [Architecture] Architecture / Prompt Engineering section: The four-stage layered prompt methodology is presented as the mechanism for translating low-level signals into coherent high-level decisions, yet the manuscript provides no concrete prompt templates, conflict-resolution rules, or safeguards against inconsistent LLM outputs. This assumption is load-bearing for the claim of reliable synthesis without fine-tuning.
Authors: The manuscript presents the four-stage process (temporal context determination, behavioral signal extraction, explicit preference enforcement, and user profile synthesis) at the level of methodology and signal integration logic. Concrete prompt templates were not included to keep the focus on the overall architecture and the combination of manual heuristics with LLM synthesis. We acknowledge that explicit templates, conflict-resolution heuristics, and safeguards (such as output validation steps) would strengthen reproducibility. In the revised version we will add an appendix containing representative prompt templates for each stage, a description of how sequential layering addresses conflicts (e.g., explicit preference enforcement taking precedence), and a brief discussion of observed LLM variability as a current limitation of the approach. revision: yes
Circularity Check
No circularity: architecture paper contains no derivations, fitted parameters, or self-referential predictions
full rationale
The manuscript describes a prompt-engineering architecture for LLM-mediated dashboard adaptation. It presents no equations, no parameter fitting, no predictions derived from inputs, and no load-bearing self-citations. The central claim rests on an unverified assumption about LLM behavior rather than any closed logical loop that reduces outputs to inputs by construction. The 'analytical evaluation' is described only at the level of scenario walkthroughs and screenshots; no quantitative self-referential metrics appear. This is a standard non-finding for a systems-description paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ashraf Abdul, Jo Vermeulen, Danding Wang, Brian Y. Lim, and Mohan Kankanhalli. 2018. Trends and Trajectories for Explainable, Accountable and Intelligible Systems: An HCI Research Agenda. InProceedings of the 2018 CHI Conference on Human Factors in Computing Systems(Montreal QC, Canada)(CHI ’18). Association for Computing Machinery, New York, NY, USA, 1–1...
-
[2]
Eler, Abdulrahman Habib, and Hyunsook Do
Wajdi Aljedaani, Ahmed Aljohani, Marcelo M. Eler, Abdulrahman Habib, and Hyunsook Do. 2025. LLMs for Accessibility in Mobile Apps: Detection and Repair. InProceedings of the 22nd International Web for All Conference (W4A ’25). Association for Computing Machinery, New York, NY, USA, 172–183. doi:10.1145/3744257.3744270
-
[3]
Bennett, Kori Inkpen, Jaime Teevan, Ruth Kikin-Gil, and Eric Horvitz
Saleema Amershi, Dan Weld, Mihaela Vorvoreanu, Adam Fourney, Besmira Nushi, Penny Collisson, Jina Suh, Shamsi Iqbal, Paul N. Bennett, Kori Inkpen, Jaime Teevan, Ruth Kikin-Gil, and Eric Horvitz. 2019. Guidelines for Human-AI Interaction. InProceedings of the 2019 CHI Conference on Human Factors in Computing Systems(Glasgow, Scotland Uk)(CHI ’19). Associat...
-
[4]
Frank Bentley, Konrad Tollmar, Peter Stephenson, Laura Levy, Brian Jones, Scott Robertson, Ed Price, Richard Catrambone, and Jeff Wilson. 2013. Health Mashups: Presenting Statistical Patterns between Wellbeing Data and Context in Natural Language to Promote Behavior Change.ACM Trans. Comput.-Hum. Interact.20, 5, Article 30 (Nov. 2013), 27 pages. doi:10.11...
-
[5]
Andrea Bunt, Cristina Conati, and Joanna McGrenere. 2007. Supporting interface customization using a mixed-initiative approach. InProceedings of the 12th International Conference on Intelligent User Interfaces(Honolulu, Hawaii, USA)(IUI ’07). Association for Computing Machinery, New York, NY, USA, 92–101. doi:10.1145/1216295.1216317
-
[6]
Lee, Bongshin Lee, Wanda Pratt, and Julie A
Eun Kyoung Choe, Nicole B. Lee, Bongshin Lee, Wanda Pratt, and Julie A. Kientz. 2014. Understanding quantified-selfers’ practices in collecting and exploring personal data. InProceedings of the SIGCHI Conference on Human Factors in Computing Systems(Toronto, Ontario, Canada)(CHI ’14). Association for Computing Machinery, New York, NY, USA, 1143–1152. doi:...
-
[7]
Shaan Chopra, Katherine Juarez, James Fogarty, and Sean A Munson. 2025. Engagements with Generative AI and Personal Health Informatics: Opportunities for Planning, Tracking, Reflecting, and Acting around Personal Health Data.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies9, 3 (2025), 1–33
2025
-
[8]
Sunny Consolvo, David W. McDonald, and James A. Landay. 2009. Theory-driven design strategies for technologies that support behavior change in everyday life. InProceedings of the SIGCHI Conference on Human Factors in Computing Systems(Boston, MA, USA)(CHI ’09). Association for Computing Machinery, New York, NY, USA, 405–414. doi:10.1145/1518701.1518766
-
[9]
Finale Doshi-Velez and Been Kim. 2017. Towards A Rigorous Science of Interpretable Machine Learning.arXiv: Machine Learning(2017). https://api.semanticscholar.org/CorpusID:11319376
2017
-
[10]
Epstein, An Ping, James Fogarty, and Sean A
Daniel A. Epstein, An Ping, James Fogarty, and Sean A. Munson. 2015. A lived informatics model of personal informatics. InProceedings of the 2015 ACM International Joint Conference on Pervasive and Ubiquitous Computing(Osaka, Japan)(UbiComp ’15). Association for Computing Machinery, New York, NY, USA, 731–742. doi:10.1145/2750858.2804250
-
[11]
Leah Findlater and Joanna McGrenere. 2010. Beyond performance: Feature awareness in personalized interfaces.International Journal of Human- Computer Studies68, 3 (2010), 121–137. doi:10.1016/j.ijhcs.2009.10.002
-
[12]
BJ Fogg. 2009. A behavior model for persuasive design. InProceedings of the 4th International Conference on Persuasive Technology(Claremont, California, USA)(Persuasive ’09). Association for Computing Machinery, New York, NY, USA, Article 40, 7 pages. doi:10.1145/1541948.1541999
-
[13]
Simon Folkard and Timothy H Monk. 1980. Circadian rhythms in human memory.British journal of psychology71, 2 (1980), 295–307. Manuscript submitted to ACM Continuous Behavioral Synthesis for Adaptive Health Dashboards: An LLM-Mediated Architecture Integrating Explicit Preference, Spatial Reorganization, and Attention Allocation Signals 33
1980
-
[14]
Thomas Fritz, Elaine M. Huang, Gail C. Murphy, and Thomas Zimmermann. 2014. Persuasive technology in the real world: a study of long-term use of activity sensing devices for fitness. InProceedings of the SIGCHI Conference on Human Factors in Computing Systems(Toronto, Ontario, Canada) (CHI ’14). Association for Computing Machinery, New York, NY, USA, 487–...
-
[15]
Krzysztof Z. Gajos, Daniel S. Weld, and Jacob O. Wobbrock. 2010. Automatically generating personalized user interfaces with Supple.Artificial Intelligence174, 12 (2010), 910–950. doi:10.1016/j.artint.2010.05.005
-
[16]
Daniel Gaspar-Figueiredo, Marta Fernández-Diego, Ruben Nuredini, Silvia Abrahao, and Emilio Insfran. 2024. Reinforcement Learning-Based Framework for the Intelligent Adaptation of User Interfaces. InCompanion Proceedings of the 16th ACM SIGCHI Symposium on Engineering Interactive Computing Systems(Cagliari, Italy)(EICS ’24 Companion). Association for Comp...
-
[17]
Alexandra-Elena Gurita. 2025. Understanding and Improving Accessibility in AI-Generated Interfaces through Interactive Prompt Engineering Methods. InCompanion Proceedings of the 30th International Conference on Intelligent User Interfaces (IUI ’25 Companion). Association for Computing Machinery, New York, NY, USA, 101–104. doi:10.1145/3708557.3716347
-
[18]
Jeff Huang, Ryen W White, and Susan Dumais. 2011. No clicks, no problem: using cursor movements to understand and improve search. In Proceedings of the SIGCHI conference on human factors in computing systems. 1225–1234
2011
-
[19]
Jamil Hussain, Anees Ul Hassan, Hafiz Bilal, Rahman Ali, Muhammad Afzal, Shujaat Hussain, Jae Bang, Oresti Banos, and Sungyoung Lee
-
[20]
Model-based adaptive user interface based on context and user experience evaluation.Journal on Multimodal User Interfaces12 (02 2018). doi:10.1007/s12193-018-0258-2
-
[21]
Ellen Jiang, Kristen Olson, Edwin Toh, Alejandra Molina, Aaron Donsbach, Michael Terry, and Carrie J Cai. 2022. PromptMaker: Prompt-based Prototyping with Large;Language;Models. InExtended Abstracts of the 2022 CHI Conference on Human Factors in Computing Systems(New Orleans, LA, USA)(CHI EA ’22). Association for Computing Machinery, New York, NY, USA, Ar...
-
[22]
Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, and Sunghun Kim. 2026. A Survey on Large Language Models for Code Generation.ACM Trans. Softw. Eng. Methodol.35, 2, Article 58 (Jan. 2026), 72 pages. doi:10.1145/3747588
-
[23]
Todd Kulesza, Simone Stumpf, Margaret Burnett, Sherry Yang, Irwin Kwan, and Weng-Keen Wong. 2013. Too much, too little, or just right? Ways explanations impact end users’ mental models. In2013 IEEE Symposium on Visual Languages and Human Centric Computing. 3–10. doi:10.1109/ VLHCC.2013.6645235
arXiv 2013
-
[24]
Talia Lavie and Joachim Meyer. 2010. Benefits and costs of adaptive user interfaces.International Journal of Human-Computer Studies68, 8 (2010), 508–524. doi:10.1016/j.ijhcs.2010.01.004 Measuring the Impact of Personalization and Recommendation on User Behaviour
-
[25]
Amanda Lazar, Christian Koehler, Theresa Jean Tanenbaum, and David H. Nguyen. 2015. Why we use and abandon smart devices. InProceedings of the 2015 ACM International Joint Conference on Pervasive and Ubiquitous Computing(Osaka, Japan)(UbiComp ’15). Association for Computing Machinery, New York, NY, USA, 635–646. doi:10.1145/2750858.2804288
-
[26]
Vera Liao, Daniel Gruen, and Sarah Miller
Q. Vera Liao, Daniel Gruen, and Sarah Miller. 2020. Questioning the AI: Informing Design Practices for Explainable AI User Experiences. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems(Honolulu, HI, USA)(CHI ’20). Association for Computing Machinery, New York, NY, USA, 1–15. doi:10.1145/3313831.3376590
-
[27]
Lena Mamykina, Drashko Nakikj, and Noemie Elhadad. 2015. Collective Sensemaking in Online Health Forums. InProceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems(Seoul, Republic of Korea)(CHI ’15). Association for Computing Machinery, New York, NY, USA, 3217–3226. doi:10.1145/2702123.2702566
-
[28]
Francisco Martínez-Lasaca, Pablo Díez, Esther Guerra, and Juan de Lara. 2023. Dandelion: A scalable, cloud-based graphical language workbench for industrial low-code development.Journal of Computer Languages76 (2023), 101217. doi:10.1016/j.cola.2023.101217
-
[29]
Tim Miller. 2019. Explanation in artificial intelligence: Insights from the social sciences.Artificial Intelligence267 (2019), 1–38. doi:10.1016/j.artint. 2018.07.007
-
[30]
John Rooksby, Mattias Rost, Alistair Morrison, and Matthew Chalmers. 2014. Personal tracking as lived informatics. InProceedings of the SIGCHI Conference on Human Factors in Computing Systems(Toronto, Ontario, Canada)(CHI ’14). Association for Computing Machinery, New York, NY, USA, 1163–1172. doi:10.1145/2556288.2557039
-
[31]
Ling Rothrock, Richard Koubek, Frederic Fuchs, Michael Haas, and Gavriel Salvendy. 2002. Review and reappraisal of adaptive interfaces: Toward biologically inspired paradigms.Theoretical Issues in Ergonomics Science3, 1 (2002), 47–84. arXiv:https://doi.org/10.1080/14639220110110342 doi:10.1080/14639220110110342
-
[32]
Saul Shiffman, Arthur A Stone, and Michael R Hufford. 2008. Ecological momentary assessment.Annu. Rev. Clin. Psychol.4, 1 (2008), 1–32
2008
-
[33]
Peter West, Richard Giordano, Max Van Kleek, and Nigel Shadbolt. 2016. The Quantified Patient in the Doctor’s Office: Challenges & Opportunities. InProceedings of the 2016 CHI Conference on Human Factors in Computing Systems(San Jose, California, USA)(CHI ’16). Association for Computing Machinery, New York, NY, USA, 3066–3078. doi:10.1145/2858036.2858445
-
[34]
Tongshuang Wu, Michael Terry, and Carrie Jun Cai. 2022. AI Chains: Transparent and Controllable Human-AI Interaction by Chaining Large Language Model Prompts. InProceedings of the 2022 CHI Conference on Human Factors in Computing Systems(New Orleans, LA, USA)(CHI ’22). Association for Computing Machinery, New York, NY, USA, Article 385, 22 pages. doi:10.1...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.