H-Adapter: Pose-Robust Hairstyle Transfer via Attention-Derived, Source-Aligned Hair Masks
Pith reviewed 2026-06-25 21:14 UTC · model grok-4.3
The pith
H-Adapter trains with a region-specific loss to produce source-aligned hair masks from disentangled cross-attention for guiding diffusion inpainting under pose differences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
H-Adapter improves pose robustness by training with a region-specific loss that disentangles hair and non-hair objectives and thereby induces spatially disentangled cross-attention, from which a source-aligned hair edit mask is derived to guide diffusion-based inpainting. Experiments on pose-agnostic and pose-different subsets demonstrate strong quantitative results, including the best FID, FID_CLIP, and CLIP-I under pose differences, while maintaining competitive non-hair preservation and improving qualitative fidelity to fine-grained reference hairstyle details.
What carries the argument
region-specific loss that disentangles hair and non-hair objectives to induce spatially disentangled cross-attention maps, from which source-aligned hair edit masks are derived
If this is right
- The method achieves the best FID, FID_CLIP, and CLIP-I scores on pose-different subsets.
- Non-hair preservation remains competitive while reference hairstyle details are transferred more faithfully.
- H-Adapter extends to text-to-image generation and auxiliary prompt-based hair color control.
- It remains compatible with an identity-preserving IP-Adapter variant.
- A VLM-as-a-judge protocol shows consistent gains in hairstyle faithfulness, non-hair preservation, and artifact quality.
Where Pith is reading between the lines
- The same attention-disentanglement approach could be tested on other localized edits such as clothing or accessory transfer.
- If the masks prove reliable, they might replace manual or segmentation-based masking in other diffusion editing pipelines.
- Extreme pose cases beyond the paper's test subsets would provide a direct check on the mask derivation step.
Load-bearing premise
The region-specific loss will reliably produce spatially disentangled cross-attention maps whose derived masks accurately isolate hair regions even under large pose discrepancies between source and reference.
What would settle it
Observe whether the attention-derived masks correctly isolate hair on source images with large pose shifts; if the masks include non-hair regions or miss hair areas and transfer quality drops sharply, the approach does not hold.
Figures















read the original abstract
Hairstyle transfer has practical applications such as virtual try-on, yet remains challenging when the source and reference exhibit large head-pose discrepancies. We propose H-Adapter, which improves pose robustness by training with a region-specific loss that disentangles hair and non-hair objectives and thereby induces spatially disentangled cross-attention, from which a source-aligned hair edit mask is derived to guide diffusion-based inpainting. Experiments on pose-agnostic and pose-different subsets demonstrate strong quantitative results, including the best FID, $\mathrm{FID}_{\mathrm{CLIP}}$, and CLIP-I under pose differences, while maintaining competitive non-hair preservation and improving qualitative fidelity to fine-grained reference hairstyle details. Beyond source-conditioned transfer, H-Adapter supports practical extensions including text-to-image generation, auxiliary prompt-based hair color control, and compatibility with an identity-preserving IP-Adapter variant. We also introduce a VLM-as-a-judge protocol and observe consistent gains in hairstyle faithfulness, non-hair preservation, and artifact quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes H-Adapter for pose-robust hairstyle transfer in diffusion models. It trains with a region-specific loss to disentangle hair and non-hair objectives, inducing spatially disentangled cross-attention maps from which a source-aligned hair edit mask is derived to guide inpainting. Experiments report the best FID, FID_CLIP, and CLIP-I on pose-different subsets while maintaining competitive non-hair preservation; the method also supports text-to-image generation, prompt-based color control, and IP-Adapter compatibility, plus a VLM-as-a-judge evaluation protocol.
Significance. If the region-specific loss reliably produces accurate source-aligned masks under large pose gaps, the approach would offer a practical advance for virtual try-on and editing tasks where pose variation is common, with the reported extensions increasing its applicability.
major comments (2)
- [Abstract] Abstract: the claim of best FID / FID_CLIP / CLIP-I on pose-different subsets is presented without any description of subset construction, data splits, or controls for post-hoc selection; this information is load-bearing for interpreting whether the reported gains demonstrate the claimed pose robustness.
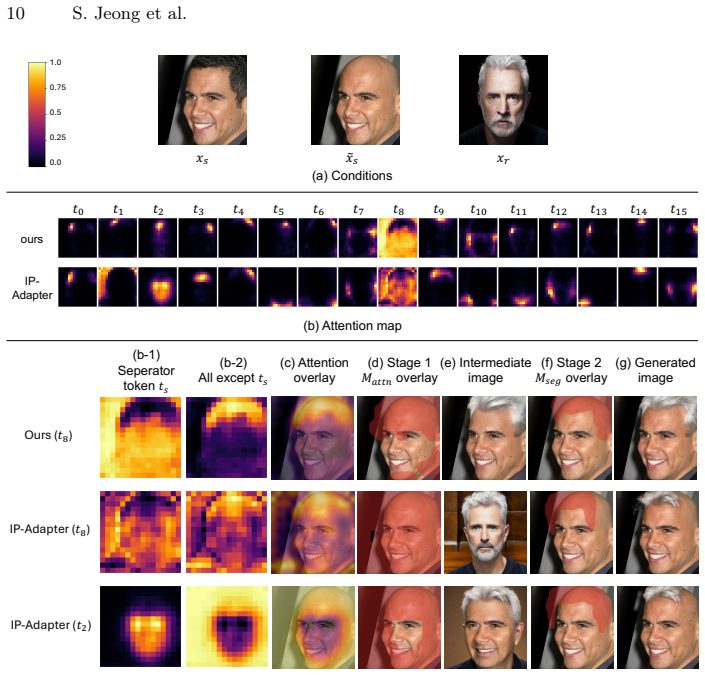
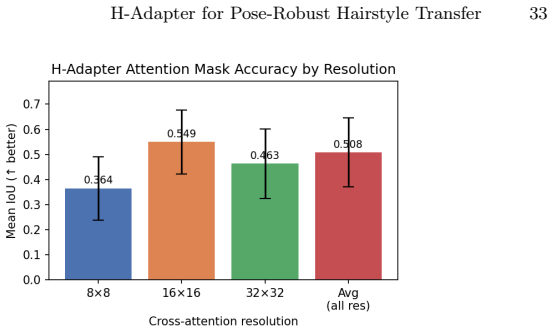
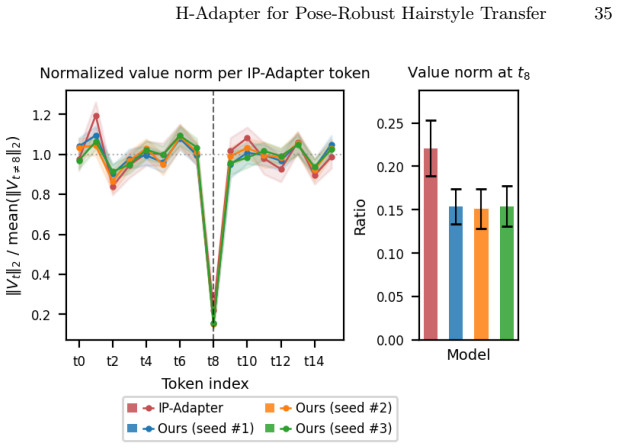
- [Method / Experiments] The central mechanistic claim—that the region-specific loss produces spatially disentangled cross-attention maps whose derived masks correctly isolate hair even under large pose discrepancies—is not accompanied by attention-map visualizations, overlap metrics with ground-truth hair regions, or an ablation that removes the region-specific loss; without these, it is impossible to confirm that the loss (rather than other diffusion components) is responsible for the observed improvements.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. The comments highlight important areas for clarification and additional evidence, which we will address through targeted revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of best FID / FID_CLIP / CLIP-I on pose-different subsets is presented without any description of subset construction, data splits, or controls for post-hoc selection; this information is load-bearing for interpreting whether the reported gains demonstrate the claimed pose robustness.
Authors: We agree that explicit details on subset construction are essential for interpreting the quantitative claims. In the revised manuscript, we will add a dedicated paragraph in the Experiments section describing the construction of the pose-agnostic and pose-different subsets, including the pose-difference thresholds used, the source of the data splits, and steps taken to avoid post-hoc selection. A brief reference to this description will also be added to the abstract. revision: yes
-
Referee: [Method / Experiments] The central mechanistic claim—that the region-specific loss produces spatially disentangled cross-attention maps whose derived masks correctly isolate hair even under large pose discrepancies—is not accompanied by attention-map visualizations, overlap metrics with ground-truth hair regions, or an ablation that removes the region-specific loss; without these, it is impossible to confirm that the loss (rather than other diffusion components) is responsible for the observed improvements.
Authors: We acknowledge that direct evidence linking the region-specific loss to the disentangled attention maps would strengthen the mechanistic argument. In the revision, we will add cross-attention map visualizations comparing models with and without the region-specific loss. We will also report quantitative overlap metrics (such as IoU) between the derived source-aligned hair masks and ground-truth hair regions on a validation set. Finally, we will include an ablation study showing results for a model variant trained without the region-specific loss. These elements will be placed in the Method and Experiments sections. revision: yes
Circularity Check
No significant circularity; derivation builds on standard diffusion components without self-referential reductions
full rationale
The paper's central mechanism is a region-specific loss applied during training of a diffusion model to encourage spatially disentangled cross-attention maps, from which a hair mask is then derived for guiding inpainting. No equations, fitted parameters, or self-citations are presented in the provided text that would make any claimed prediction or result equivalent to its inputs by construction. The approach extends existing attention-based conditioning and inpainting techniques with a new loss term whose effect on attention is an empirical outcome rather than a definitional identity. Quantitative results on pose-different subsets are reported as experimental outcomes, not as tautological consequences of the method definition itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Jeong et al
Black Forest Labs: Flux.2 [klein]: Towards interactive visual intelligence,https: 16 S. Jeong et al. //bfl.ai/blog/flux2-klein-towards-interactive-visual-intelligence
-
[2]
In: Pro- ceedings of the IEEE/CVF international conference on computer vision
Cao, M., Wang, X., Qi, Z., Shan, Y., Qie, X., Zheng, Y.: Masactrl: Tuning-free mutual self-attention control for consistent image synthesis and editing. In: Pro- ceedings of the IEEE/CVF international conference on computer vision. pp. 22560– 22570 (2023)
2023
-
[3]
In: Forty-first International Conference on Machine Learning (2024)
Chen, D., Chen, R., Zhang, S., Wang, Y., Liu, Y., Zhou, H., Zhang, Q., Wan, Y., Zhou, P., Sun, L.: Mllm-as-a-judge: Assessing multimodal llm-as-a-judge with vision-language benchmark. In: Forty-first International Conference on Machine Learning (2024)
2024
-
[4]
arXiv preprint arXiv:2206.08585 (2022)
Chung, C., Kim, T., Nam, H., Choi, S., Gu, G., Park, S., Choo, J.: Hairfit: pose- invariant hairstyle transfer via flow-based hair alignment and semantic-region- aware inpainting. arXiv preprint arXiv:2206.08585 (2022)
-
[5]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Chung, C., Park, S., Kim, J., Choo, J.: What to preserve and what to transfer: Faithful, identity-preserving diffusion-based hairstyle transfer. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 2582–2590 (2025)
2025
-
[6]
Comanici, G., et al.: Gemini 2.5: Pushing the frontier with advanced reason- ing, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
arXiv preprint arXiv:2210.11427 (2022)
Couairon, G., Verbeek, J., Schwenk, H., Cord, M.: Diffedit: Diffusion-based seman- tic image editing with mask guidance. arXiv preprint arXiv:2210.11427 (2022)
-
[8]
google/models/gemini-image/pro/
Google DeepMind: Gemini 3 pro image – nano banana pro,https://deepmind. google/models/gemini-image/pro/
-
[9]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Güler, R.A., Neverova, N., Kokkinos, I.: Densepose: Dense human pose estimation in the wild. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 7297–7306 (2018)
2018
-
[10]
h94: Ip-adapter,https://huggingface.co/h94/IP-Adapter
-
[11]
h94: Ip-adapter-faceid,https://huggingface.co/h94/IP-Adapter-FaceID
-
[12]
Prompt-to-Prompt Image Editing with Cross Attention Control
Hertz, A., Mokady, R., Tenenbaum, J., Aberman, K., Pritch, Y., Cohen-Or, D.: Prompt-to-prompt image editing with cross attention control. arXiv preprint arXiv:2208.01626 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[13]
Progressive Growing of GANs for Improved Quality, Stability, and Variation
Karras, T., Aila, T., Laine, S., Lehtinen, J.: Progressive growing of gans for im- proved quality, stability, and variation. arXiv preprint arXiv:1710.10196 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[14]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Karras, T., Laine, S., Aila, T.: A style-based generator architecture for generative adversarial networks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 4401–4410 (2019)
2019
-
[15]
In: European conference on computer vision
Kim, T., Chung, C., Kim, Y., Park, S., Kim, K., Choo, J.: Style your hair: Latent optimization for pose-invariant hairstyle transfer via local-style-aware hair align- ment. In: European conference on computer vision. pp. 188–203. Springer (2022)
2022
-
[16]
In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Ku, M., Jiang, D., Wei, C., Yue, X., Chen, W.: Viescore: Towards explainable metrics for conditional image synthesis evaluation. In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 12268–12290 (2024)
2024
-
[17]
arXiv preprint arXiv:2304.13509 (2023)
Kvanchiani, K., Petrova, E., Efremyan, K., Sautin, A., Kapitanov, A.: Easyportrait–face parsing and portrait segmentation dataset. arXiv preprint arXiv:2304.13509 (2023)
-
[18]
arXiv preprint arXiv:2203.06026 (2022)
Kynkäänniemi, T., Karras, T., Aittala, M., Aila, T., Lehtinen, J.: The role of imagenet classes in fr\’echet inception distance. arXiv preprint arXiv:2203.06026 (2022)
-
[19]
LAION: Clip-vit-h-14-laion2b-s32b-b79k,https://huggingface.co/laion/CLIP- ViT-H-14-laion2B-s32B-b79K H-Adapter for Pose-Robust Hairstyle Transfer 17
-
[20]
In: Findings of the Association for Computational Linguistics: ACL 2024
Lee, S., Kim, S., Park, S., Kim, G., Seo, M.: Prometheus-vision: Vision-language model as a judge for fine-grained evaluation. In: Findings of the Association for Computational Linguistics: ACL 2024. pp. 11286–11315 (2024)
2024
-
[21]
GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
Nichol, A., Dhariwal, P., Ramesh, A., Shyam, P., Mishkin, P., McGrew, B., Sutskever, I., Chen, M.: Glide: Towards photorealistic image generation and editing with text-guided diffusion models. arXiv preprint arXiv:2112.10741 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[22]
Advances in Neural In- formation Processing Systems37, 45600–45635 (2024)
Nikolaev, M., Kuznetsov, M., Vetrov, D., Alanov, A.: Hairfastgan: Realistic and robust hair transfer with a fast encoder-based approach. Advances in Neural In- formation Processing Systems37, 45600–45635 (2024)
2024
-
[23]
OpenAI: Gpt-4o system card. arXiv preprint arXiv:2410.21276 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
OpenAI: Openai gpt-5 system card. arXiv preprint arXiv:2601.03267 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
OpenAI: Update to gpt-5 system card: Gpt-5.2.https://openai.com/index/gpt- 5-system-card-update-gpt-5-2/(2025)
2025
-
[26]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Müller, J., Penna, J., Rombach, R.: Sdxl: Improving latent diffusion models for high-resolution image synthesis. arXiv preprint arXiv:2307.01952 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
2021
-
[28]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Ramesh, A., Dhariwal, P., Nichol, A., Chu, C., Chen, M.: Hierarchical text- conditional image generation with clip latents. arXiv preprint arXiv:2204.06125 1(2), 3 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[29]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022)
2022
-
[30]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Saha, R., Duke, B., Shkurti, F., Taylor, G.W., Aarabi, P.: Loho: Latent opti- mization of hairstyles via orthogonalization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1984–1993 (2021)
1984
-
[31]
Advances in neural information processing systems35, 36479–36494 (2022)
Saharia, C., Chan, W., Saxena, S., Li, L., Whang, J., Denton, E.L., Ghasemipour, K., Gontijo Lopes, R., Karagol Ayan, B., Salimans, T., et al.: Photorealistic text- to-image diffusion models with deep language understanding. Advances in neural information processing systems35, 36479–36494 (2022)
2022
-
[32]
co / SG161222 / Realistic_Vision_V4.0_noVAE
SG161222: Realistic vision v4.0 novae,https : / / huggingface . co / SG161222 / Realistic_Vision_V4.0_noVAE
-
[33]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Slyman, E., Tanjim, M., Kafle, K., Lee, S.: Calibrating mllm-as-a-judge via multi- modal bayesian prompt ensembles. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 17224–17234 (2025)
2025
-
[34]
Stability AI: sd-vae-ft-mse,https://huggingface.co/stabilityai/sd-vae-ft- mse
-
[35]
stabilityai: stable-diffusion-v1-5/stable-diffusion-inpainting,https : / / huggingface.co/stable-diffusion-v1-5/stable-diffusion-inpainting
-
[36]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., Wojna, Z.: Rethinking the incep- tion architecture for computer vision. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 2818–2826 (2016)
2016
- [37]
-
[38]
In: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition
Tumanyan, N., Geyer, M., Bagon, S., Dekel, T.: Plug-and-play diffusion features for text-driven image-to-image translation. In: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition. pp. 1921–1930 (2023) 18 S. Jeong et al
1921
-
[39]
IEEE transactions on image processing 13(4), 600–612 (2004)
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing 13(4), 600–612 (2004)
2004
-
[40]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wei, T., Chen, D., Zhou, W., Liao, J., Tan, Z., Yuan, L., Zhang, W., Yu, N.: Hairclip: Design your hair by text and reference image. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 18072– 18081 (2022)
2022
-
[41]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2026)
Wei, T., Chen, D., Zhou, W., Liao, J., Wang, C., Zhang, W., Hua, G., Yu, N.: Unifying multi-modal hair editing via proxy feature blending. IEEE Transactions on Pattern Analysis and Machine Intelligence (2026)
2026
-
[42]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Wei, T., Chen, D., Zhou, W., Liao, J., Zhang, W., Hua, G., Yu, N.: Hairclipv2: Unifying hair editing via proxy feature blending. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 23589–23599 (2023)
2023
-
[43]
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Ye, H., Zhang, J., Liu, S., Han, X., Yang, W.: Ip-adapter: Text compati- ble image prompt adapter for text-to-image diffusion models. arXiv preprint arXiv:2308.06721 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
In: Proceedings of the European conference on computer vision (ECCV)
Yu, C., Wang, J., Peng, C., Gao, C., Yu, G., Sang, N.: Bisenet: Bilateral segmenta- tion network for real-time semantic segmentation. In: Proceedings of the European conference on computer vision (ECCV). pp. 325–341 (2018)
2018
-
[45]
Advances in Neural Information Processing Systems37, 5048–5073 (2024)
Zeng, Y., Zhang, Y., Jiachen, L., Shen, L., Deng, K., He, W., Wang, J.: Hairdif- fusion: Vivid multi-colored hair editing via latent diffusion. Advances in Neural Information Processing Systems37, 5048–5073 (2024)
2024
-
[46]
Zhang, X., Lu, Y., Wang, W., Yan, A., Yan, J., Qin, L., Wang, H., Yan, X., Wang, W.Y., Petzold, L.R.: Gpt-4v (ision) as a generalist evaluator for vision-language tasks. arXiv preprint arXiv:2311.01361 (2023)
-
[47]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Zhang, Y., Zhang, Q., Song, Y., Zhang, J., Tang, H., Liu, J.: Stable-hair: Real- world hair transfer via diffusion model. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 10348–10356 (2025)
2025
-
[48]
Qwen-Image-2.0 Technical Report
Zhao, B., Wu, C., Li, D., Meng, H., Li, J., Zhang, J., Zhou, J., Lin, J., Gao, K., Cao, K., et al.: Qwen-image-2.0 technical report. arXiv preprint arXiv:2605.10730 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[49]
In: European conference on computer vision
Zhu, H., Wu, W., Zhu, W., Jiang, L., Tang, S., Zhang, L., Liu, Z., Loy, C.C.: Celebv-hq: A large-scale video facial attributes dataset. In: European conference on computer vision. pp. 650–667. Springer (2022)
2022
-
[50]
arXiv preprint arXiv:2106.01505 (2021)
Zhu, P., Abdal, R., Femiani, J., Wonka, P.: Barbershop: Gan-based image com- positing using segmentation masks. arXiv preprint arXiv:2106.01505 (2021)
-
[51]
In: European Conference on Computer Vision
Zhu, P., Abdal, R., Femiani, J., Wonka, P.: Hairnet: Hairstyle transfer with pose changes. In: European Conference on Computer Vision. pp. 651–667. Springer (2022)
2022
-
[52]
watercolor painting of a man, soft wash, paper texture, gentle gradients, high quality, high detail
Zou, S., Tang, J., Zhou, Y., He, J., Zhao, C., Zhang, R., Hu, Z., Sun, X.: Towards efficientdiffusion-basedimageeditingwithinstantattentionmasks.In:Proceedings of the AAAI Conference on Artificial Intelligence. vol. 38, pp. 7864–7872 (2024) H-Adapter for Pose-Robust Hairstyle Transfer 19 Supplementary Material A Step-wise Analysis of Region-specific Loss ...
2024
-
[53]
color and tone/highlights
-
[54]
texture/curl pattern
-
[55]
axis": "HFS
silhouette/volume and style identity (including bangs/part) Ignore ALL non-hair factors: - face identity - skin tone/lighting - background/clothes - general aesthetics Score mapping: - 5: Hair attributes are almost fully aligned with REFERENCE. - 4: Mostly aligned with minor inconsistency. - 3: Mixed; clear match in some attributes but clear mismatch in o...
-
[56]
Determine which hair error tags apply
-
[57]
axis": "HFS
Judge severity and assign final integer score 1..5. Allowed error tags: - silhouette_mismatch - bangs_part_mismatch - texture_mismatch - color_mismatch - hairline_mismatch - partial_transfer - style_identity_mismatch Scoring guidance from error severity: - 5: No meaningful hair errors. - 4: One minor error. - 3: One or two clear errors (moderate impact). ...
-
[58]
facial identity geometry (eyes, nose, mouth, contour)
-
[59]
skin tone and lighting/shadow
-
[60]
background consistency
-
[61]
axis": "NPS
clothing/accessories consistency Ignore hairstyle quality and hairstyle transfer quality completely. Score mapping: - 5: Preserved almost perfectly. - 4: Minor change but same identity/scene. - 3: Moderate change; still partially preserved. - 2: Major changes in multiple non-hair aspects. - 1: Non-hair preservation largely failed. Use applicable tags: - i...
-
[62]
Check boundary regions first: hairline, hair-skin, hair-background
-
[63]
Check face/skin texture and structural consistency
-
[64]
Evaluate ONLY these artifact categories:
Check global quality issues: blur, noise/compression, repetition. Evaluate ONLY these artifact categories:
-
[65]
boundary_blending_artifact
-
[66]
hairline_contour_artifact
-
[67]
unnatural_skin_texture
-
[68]
visible_patch_or_seam
-
[69]
structural_distortion
-
[70]
blur_or_focus_artifact
-
[71]
noise_or_compression_artifact
-
[72]
axis": "AQS
repetition_or_tiling_artifact Ignore all non-artifact factors: - hair-reference similarity - source identity preservation - attractiveness or style preference Score mapping: - 5: No meaningful artifact. - 4: One minor artifact. - 3: One clear artifact or several minor artifacts. - 2: Multiple major artifacts. - 1: Severe artifact failure. Tag from applica...
-
[73]
Select artifact tags that apply
-
[74]
axis": "AQS
Judge severity and assign final integer score 1..5. Allowed tags: - boundary_blending_artifact - hairline_contour_artifact - unnatural_skin_texture - visible_patch_or_seam - structural_distortion - blur_or_focus_artifact - noise_or_compression_artifact - repetition_or_tiling_artifact Scoring guidance from artifact severity: - 5: No meaningful artifacts. -...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.