LLM Zeroth-Order Fine-Tuning is an Inference Workload
Pith reviewed 2026-06-29 14:29 UTC · model grok-4.3
The pith
Zeroth-order fine-tuning of large language models is an inference workload that a serving runtime accelerates by up to 8 times.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
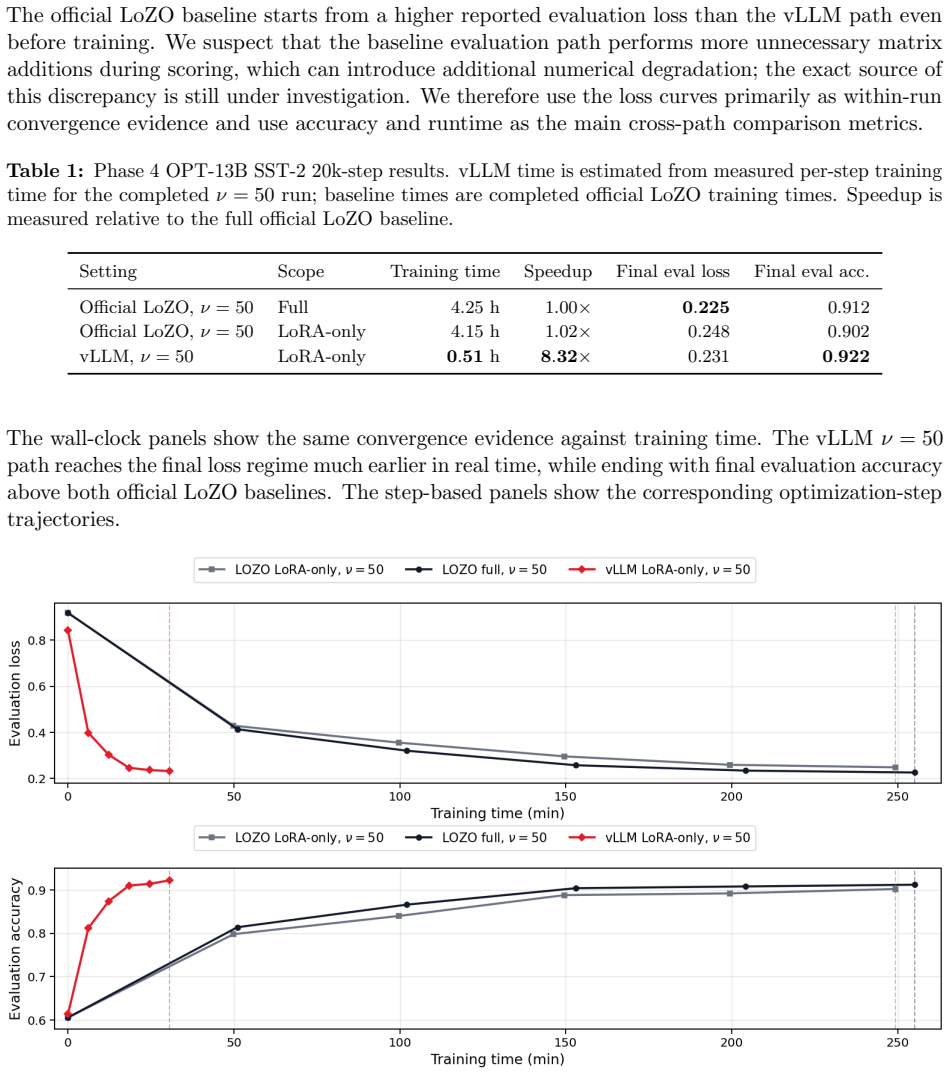
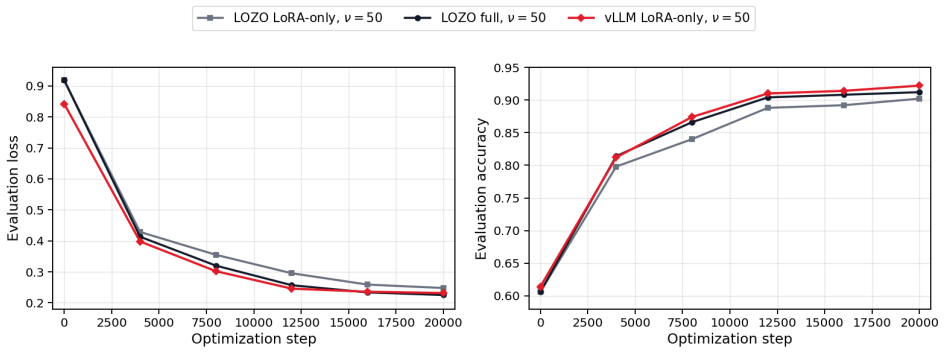
Zeroth-order fine-tuning is an inference-dominated workload whose repeated forward evaluations can be executed through a serving runtime rather than a training loop. This reorganization yields 8.13 times faster completion of the 20k-step LoZO process on OPT-13B SST-2 under matched LoRA settings while preserving 0.922 final evaluation accuracy and 0.931 full-validation accuracy, with 2.34x to 7.72x speedups observed in core-step scaling and up to 2.55x faster execution for a MeZO-style factorized variant.
What carries the argument
Reorganization of repeated forward evaluations under nearby parameter states into a serving runtime that represents ZO updates as dynamic adapter states.
If this is right
- The same runtime reorganization produces 2.34x to 7.72x speedups when scaling core steps across OPT-1.3B to OPT-13B.
- A MeZO-style high-rank factorized experiment maintains a comparable loss trajectory at up to 2.55 times faster execution.
- Lightweight adaptation can be scheduled as an inference-like workload rather than a separate training job.
Where Pith is reading between the lines
- Existing inference optimizations such as continuous batching could be applied directly to ZO fine-tuning without new algorithm changes.
- Serving engines could incorporate parameter perturbation as a native operation to support on-the-fly model adaptation.
- The boundary between training and inference phases for LLMs could narrow if adaptation is expressed entirely through forward-pass workloads.
Load-bearing premise
Reorganizing the repeated forward evaluations into a serving runtime preserves the exact optimization trajectory and numerical behavior without introducing overheads that would change final accuracy or convergence.
What would settle it
A side-by-side run on the same model, task, random seed, and step count that shows the serving runtime produces a statistically significant drop in final validation accuracy relative to the training-loop baseline would falsify the claim of preserved performance.
Figures
read the original abstract
Zeroth-order (ZO) fine-tuning is attractive for large language models because it replaces backpropagation with forward objective evaluations. Existing implementations nevertheless execute ZO algorithms inside conventional training loops, even though their dominant work is repeated scoring under nearby parameter states. This creates a workload-runtime mismatch: the algorithm asks for structured inference-style scoring, while the system exposes a sequence of fragmented training-loop steps. We show that LLM ZO fine-tuning is an inference-dominated workload and execute its repeated scoring phase through a serving runtime. On OPT-13B SST-2, the resulting vLLM execution path completes the 20k-step LoZO run in 0.51 estimated training hours versus 4.15 hours for the official LoZO baseline under the matched LoRA-only setting, an 8.13x speedup, while reaching 0.922 final evaluation accuracy and 0.931 final full-validation accuracy. In core-step scaling experiments across OPT-1.3B to OPT-13B, the same runtime reorganization gives 2.34x--7.72x speedups. A MeZO-style high-rank factorized experiment shows that the same runtime paradigm can track a MeZO-like loss trajectory while running up to 2.55x faster. More broadly, representing ZO updates as dynamic adapter states suggests a practical path toward inference-time training, where lightweight adaptation can be scheduled as an inference-like workload rather than as a separate training job.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that zeroth-order (ZO) fine-tuning of LLMs is dominated by repeated forward inference-style evaluations under perturbed parameters rather than backpropagation, creating a workload mismatch with conventional training loops. It proposes reorganizing the ZO process (specifically LoZO and MeZO-style variants) to run through an inference serving runtime such as vLLM, reporting an 8.13x wall-clock speedup on OPT-13B SST-2 (0.51 vs. 4.15 estimated hours for 20k steps under LoRA-only) while reaching final accuracies of 0.922 (eval) and 0.931 (full validation), with 2.34x–7.72x speedups in core-step scaling from OPT-1.3B to OPT-13B and up to 2.55x in a high-rank factorized setting.
Significance. If the speedup is achieved while preserving the exact ZO optimization trajectory, the work offers a practical systems insight that could make ZO methods more viable for large models by treating adaptation as a schedulable inference workload rather than a separate training job. The direct empirical comparison against the official LoZO baseline, the scaling results across model sizes, and the MeZO-style loss-trajectory experiment are concrete strengths; the dynamic-adapter-state framing also points to a broader direction for inference-time training.
major comments (1)
- [OPT-13B SST-2 experiment description and core-step scaling results] The central empirical claim (8.13x speedup on OPT-13B SST-2 with matched final accuracies) is load-bearing on the assumption that the vLLM execution path performs exactly the same sequence of perturbed forward evaluations, loss computations, and perturbation draws as the baseline training loop. The abstract and results report only final accuracies and estimated hours; no loss curves, per-step objective values, or random-seed comparisons for perturbations are provided to confirm trajectory equivalence. Without this, differences in continuous batching, adapter-state handling, or numerical execution could produce a different optimization path whose final accuracy match is coincidental.
minor comments (2)
- [Abstract and experimental setup] The training times are reported as 'estimated'; the methods or experimental section should explicitly state the estimation procedure, hardware configuration, batch-size matching, and any caching or warm-up assumptions used for both the vLLM and baseline runs.
- [Results on OPT-13B SST-2 and scaling experiments] Reported accuracies and speedups lack error bars, standard deviations, or results from multiple random seeds, which is important for stochastic ZO methods where perturbation sampling can affect convergence.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for highlighting the potential systems insight of the work. We address the major comment on trajectory equivalence below.
read point-by-point responses
-
Referee: [OPT-13B SST-2 experiment description and core-step scaling results] The central empirical claim (8.13x speedup on OPT-13B SST-2 with matched final accuracies) is load-bearing on the assumption that the vLLM execution path performs exactly the same sequence of perturbed forward evaluations, loss computations, and perturbation draws as the baseline training loop. The abstract and results report only final accuracies and estimated hours; no loss curves, per-step objective values, or random-seed comparisons for perturbations are provided to confirm trajectory equivalence. Without this, differences in continuous batching, adapter-state handling, or numerical execution could produce a different optimization path whose final accuracy match is coincidental.
Authors: We agree that reporting only final accuracies leaves open the possibility of coincidental matches and that explicit trajectory verification would strengthen the central claim. The vLLM reorganization is constructed to issue exactly the same sequence of perturbed forward passes, loss evaluations, and random perturbation draws as the baseline LoZO loop (the only change is the execution engine for the forward scoring phase). Nevertheless, to directly address the concern we will add, in the revised manuscript, (i) training loss curves for both paths on the OPT-13B SST-2 run and (ii) per-step objective values for a representative window of steps under identical random seeds. These additions will allow readers to verify numerical equivalence of the optimization trajectories. revision: yes
Circularity Check
No circularity; empirical runtime comparison stands on its own
full rationale
The paper's central result is an empirical measurement: vLLM-based execution of repeated ZO forward passes yields measured wall-clock speedups (8.13x on OPT-13B SST-2) and matched final accuracies versus an explicit baseline implementation. No equations, fitted parameters, or self-citations are invoked to derive the speedup; the claim is a direct timing comparison under a matched LoRA-only setting. The text contains no self-definitional loops, no 'prediction' that reduces to a fitted input, and no load-bearing uniqueness theorems. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2305.17333 , year=
Sadhika Malladi, Tianyu Gao, Eshaan Nichani, Alex Damian, Jason D. Lee, Danqi Chen, and Sanjeev Arora. Fine-Tuning Language Models with Just Forward Passes.arXiv preprint arXiv:2305.17333, 2023
-
[2]
Enhancing Zeroth-Order Fine-Tuning for Language Models with Low-Rank Structures
Yiming Chen, Yuan Zhang, Liyuan Cao, Kun Yuan, and Zaiwen Wen. Enhancing Zeroth-Order Fine-Tuning for Language Models with Low-Rank Structures. InInternational Conference on Learning Representations, 2025
2025
-
[3]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient Memory Management for Large Language Model Serving with PagedAttention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
2023
-
[4]
MobiZO: Enabling Efficient LLM Fine-Tuning at the Edge via Inference Engines
Lei Gao, Amir Ziashahabi, Yue Niu, Salman Avestimehr, and Murali Annavaram. MobiZO: Enabling Efficient LLM Fine-Tuning at the Edge via Inference Engines. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025. 12
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.