In-Context Learning Operates as Concept Subspace Learning
Pith reviewed 2026-05-20 21:27 UTC · model grok-4.3
The pith
In-context learning recovers task predictions from low-dimensional concept subspaces in model activations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
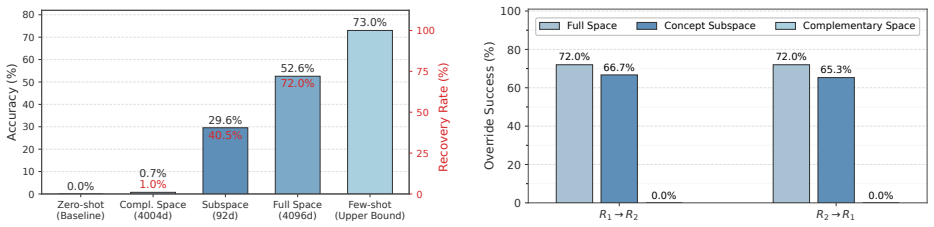
The paper claims that recoverable task information in in-context learning concentrates in a low-dimensional, task-aligned activation subspace. On CounterFact-derived multi-relation prompts with Llama-3-8B, a 68-73-dimensional subspace of the 4096-dimensional residual stream restores 78.8 percent of the clean-corrupted accuracy gap, while patching the complementary subspace restores 0 percent. Concept swaps inside this subspace redirect predictions toward the injected relations, and random or cross-task matched-rank controls do not. The same qualitative pattern appears on Qwen2.5-7B and a controlled cross-lingual rule task.
What carries the argument
The concept subspace: the low-dimensional linear directions inside the residual stream activations that align with the task's intrinsic concept coordinates and mediate the exact decomposition of ICL predictions into concept regression and off-subspace leakage.
If this is right
- ICL prediction accuracy depends primarily on the dimension of the concept subspace rather than the full ambient dimension.
- Targeted interventions inside the identified subspace can steer task behavior without touching the orthogonal complement.
- The same low-dimensional concentration pattern holds across Llama-3-8B, Qwen2.5-7B, and controlled cross-lingual tasks.
- Concept swaps inside the subspace successfully alter model outputs, confirming that the subspace encodes the relation information.
Where Pith is reading between the lines
- If the claim holds, identifying these subspaces could let practitioners steer ICL behavior with far fewer dimensions than full activation edits.
- The decomposition invites tests of whether subspace dimension grows with the number of relations or demonstrations in a task family.
- The result suggests ICL may generalize by projecting onto learned concept directions rather than relying on diffuse high-dimensional patterns.
Load-bearing premise
The covariance between concept directions and nuisance directions is block-diagonal or nearly so, which separates the scaling of estimation terms from cross-subspace effects.
What would settle it
If a random subspace of the same size or the complementary high-dimensional complement restores a comparable fraction of the accuracy gap, or if concept swaps fail to redirect predictions while random swaps succeed, the concentration claim would be falsified.
Figures












read the original abstract
Regression and Bayesian accounts of in-context learning (ICL) explain how demonstrations can induce predictors, while mechanistic analyses often identify compact activation directions that steer prompted behavior. However, it remains unclear whether structured demonstrations induce low-dimensional concept inference. We study this question through a concept-subspace view of ICL, in which tasks vary only along intrinsic concept coordinates, although inputs are observed in a high-dimensional ambient space. For ridge and least-squares ICL proxies, prediction decomposes exactly into concept-coordinate regression and off-subspace leakage. Under block-diagonal or near-block-diagonal covariance assumptions, the leading estimation and nuisance-sensitivity terms scale with the dimension of the concept subspace, while residual effects are controlled by cross-subspace coupling. This separation gives a mechanistic prediction: recoverable task information should concentrate in a low-dimensional, task-aligned activation subspace. On CounterFact-derived multi-relation prompts with Llama-3-8B, a 68--73-dimensional subspace of the 4096-dimensional residual stream restores 78.8% of the clean--corrupted accuracy gap, whereas patching the complementary subspace restores 0%. Concept swaps redirect predictions toward injected relations, while random and cross-task matched-rank controls are largely ineffective. Additional experiments on Qwen2.5-7B and a controlled cross-lingual rule task show the same qualitative pattern. These results support concept subspaces as compact, task-aligned mediators of recoverable ICL behavior in structured task families, without implying full-circuit recovery.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops a concept-subspace view of in-context learning, arguing that structured demonstrations induce low-dimensional concept inference within high-dimensional activation spaces. For ridge and least-squares ICL proxies, it derives an exact decomposition of predictions into concept-coordinate regression and off-subspace leakage. Under block-diagonal or near-block-diagonal covariance assumptions, leading estimation and nuisance terms scale with subspace dimension while residuals are controlled by cross-subspace coupling. Empirically, on CounterFact-derived multi-relation prompts with Llama-3-8B, patching a 68-73 dimensional subspace of the 4096-dimensional residual stream restores 78.8% of the clean-corrupted accuracy gap, whereas the complementary subspace restores 0%; concept swaps redirect predictions while random and cross-task controls do not. The pattern holds on Qwen2.5-7B and a controlled cross-lingual task.
Significance. If the results hold, the work bridges regression accounts of ICL with mechanistic interpretability by identifying compact, task-aligned activation subspaces as mediators of recoverable behavior. The concrete patching numbers, the 0% restoration on the complement, and the qualitative consistency across models and tasks are strengths. The paper supplies falsifiable scaling predictions from the decomposition and reproducible empirical controls, which add value even if the covariance assumptions require further checks.
major comments (3)
- [Theory section] Theoretical decomposition (around the ridge/least-squares analysis): the scaling predictions for estimation and nuisance-sensitivity terms rest on block-diagonal or near-block-diagonal covariance. The manuscript provides no direct measurement of cross-subspace coupling or verification that residual-stream activations satisfy this assumption, despite attention and MLP layers plausibly inducing dense correlations. This is load-bearing for the claim that recoverable task information must concentrate in a low-dimensional subspace.
- [Results on Llama-3-8B and CounterFact] Empirical patching results: a 68-73 dimensional subspace restores 78.8% of the gap, but the text gives no details on the method used to identify or select this specific dimension, whether it was fixed independently of the accuracy numbers, and no error bars or run-to-run variance. Without these, the result risks appearing post-hoc and weakens the mechanistic interpretation that information concentrates at this scale.
- [Discussion of assumptions] Cross-subspace coupling control: the theory states that residual effects are governed by this quantity, yet no empirical bound or estimate is reported for the actual activations. If coupling is not small, the observed concentration could arise from mechanisms outside the assumed decomposition.
minor comments (2)
- [Abstract] Abstract and results lack error bars on the 78.8% restoration figure and explicit description of the subspace identification procedure.
- [Methods] Notation for the concept subspace and its estimation from activations could be clarified with a short algorithmic outline or pseudocode.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight key areas where additional empirical support and reporting can strengthen the connection between the theoretical decomposition and the experimental results. We address each major comment below and will incorporate the suggested clarifications and analyses in the revised manuscript.
read point-by-point responses
-
Referee: [Theory section] Theoretical decomposition (around the ridge/least-squares analysis): the scaling predictions for estimation and nuisance-sensitivity terms rest on block-diagonal or near-block-diagonal covariance. The manuscript provides no direct measurement of cross-subspace coupling or verification that residual-stream activations satisfy this assumption, despite attention and MLP layers plausibly inducing dense correlations. This is load-bearing for the claim that recoverable task information must concentrate in a low-dimensional subspace.
Authors: We agree that direct empirical verification of the block-diagonal covariance assumption would strengthen the theoretical claims. In the revised manuscript we will add an analysis that computes the cross-subspace coupling directly from the residual-stream activations collected in the Llama-3-8B experiments. We will report the magnitude of off-block correlations and provide quantitative bounds on the coupling term, thereby testing whether the assumption holds sufficiently well to support the scaling predictions. revision: yes
-
Referee: [Results on Llama-3-8B and CounterFact] Empirical patching results: a 68-73 dimensional subspace restores 78.8% of the gap, but the text gives no details on the method used to identify or select this specific dimension, whether it was fixed independently of the accuracy numbers, and no error bars or run-to-run variance. Without these, the result risks appearing post-hoc and weakens the mechanistic interpretation that information concentrates at this scale.
Authors: The referee correctly identifies a reporting gap. The 68-73 dimensional range was obtained from the elbow of the cumulative explained-variance curve of task-aligned principal components computed on a held-out subset of activations, prior to any accuracy evaluation on the main test set. In revision we will describe this procedure in full, including the precise selection criterion and any hyperparameters. We will also add error bars and standard deviations computed across five independent runs that vary random seeds and prompt ordering. revision: yes
-
Referee: [Discussion of assumptions] Cross-subspace coupling control: the theory states that residual effects are governed by this quantity, yet no empirical bound or estimate is reported for the actual activations. If coupling is not small, the observed concentration could arise from mechanisms outside the assumed decomposition.
Authors: This concern is closely related to the first comment. The revised version will include the same empirical estimate of cross-subspace coupling derived from the experimental activations. By reporting a concrete bound on this quantity we will directly address whether residual effects remain controlled under the observed coupling strength, thereby reinforcing the mechanistic interpretation. revision: yes
Circularity Check
No significant circularity; theory derives testable prediction from explicit assumptions, validated by independent patching experiments
full rationale
The paper states an explicit mathematical decomposition for ridge/least-squares ICL under block-diagonal covariance assumptions, from which it derives the prediction that task information concentrates in a low-dimensional subspace. This prediction is then tested via patching experiments on Llama-3-8B activations that measure accuracy restoration with controls (concept swaps, random, cross-task). The 68-73 dimensional finding and 78.8% restoration are empirical outcomes, not forced by re-using fitted parameters or self-citations as the load-bearing step. The covariance assumption is presented as an assumption rather than derived from the target accuracy numbers, and the experiments include negative controls that would falsify the claim if the subspace were not specific. No load-bearing step reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- concept subspace dimension
axioms (2)
- domain assumption Tasks vary only along intrinsic concept coordinates although inputs are observed in a high-dimensional ambient space
- domain assumption Block-diagonal or near-block-diagonal covariance structure
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Under block-diagonal or near-block-diagonal covariance assumptions, the leading estimation and nuisance-sensitivity terms scale with the dimension of the concept subspace, while residual effects are controlled by cross-subspace coupling.
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
a 68--73-dimensional subspace of the 4096-dimensional residual stream restores 78.8% of the clean--corrupted accuracy gap
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Brown, Benjamin Mann, Nick Ryder, and et al
Tom B. Brown, Benjamin Mann, Nick Ryder, and et al. Language models are few-shot learners. InAdvances in Neural Information Processing Systems 33, pages 1877–1901, 2020
work page 1901
-
[2]
A glance at in-context learning.Frontiers of Computer Science, 18(5): 185347, 2024
Xu Yang Yongliang Wu. A glance at in-context learning.Frontiers of Computer Science, 18(5): 185347, 2024
work page 2024
-
[3]
arXiv preprint arXiv:2303.03846 , year =
Jerry Wei, Jason Wei, Yi Tay, Dustin Tran, Albert Webson, Yifeng Lu, Xinyun Chen, Hanxiao Liu, Da Huang, Denny Zhou, et al. Larger language models do in-context learning differently. arXiv preprint arXiv:2303.03846, 2023
-
[4]
Sewon Min, Xinxi Lyu, Ari Holtzman, Mikel Artetxe, Mike Lewis, Hannaneh Hajishirzi, and Luke Zettlemoyer. Rethinking the role of demonstrations: What makes in-context learning work? InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 11048–11064, 2022
work page 2022
-
[5]
Stephanie C. Y. Chan, Adam Santoro, Andrew K. Lampinen, Jane X. Wang, Aaditya K. Singh, Pierre H. Richemond, James L. McClelland, and Felix Hill. Data distributional properties drive emergent in-context learning in transformers. InAdvances in Neural Information Processing Systems 35, pages 18878–18891, 2022. 11
work page 2022
-
[6]
An explanation of in-context learning as implicit bayesian inference
Sang Michael Xie, Aditi Raghunathan, Percy Liang, and Tengyu Ma. An explanation of in-context learning as implicit bayesian inference. InProceedings of the 10th International Conference on Learning Representations, 2022
work page 2022
-
[7]
Transformers as statisticians: Provable in-context learning with in-context algorithm selection
Yu Bai, Fan Chen, Huan Wang, Caiming Xiong, and Song Mei. Transformers as statisticians: Provable in-context learning with in-context algorithm selection. InAdvances in Neural Information Processing Systems 36, pages 57125–57211, 2023
work page 2023
-
[8]
What in-context learning “learns” in-context: Disentangling task recognition and task learning
Jane Pan, Tianyu Gao, Howard Chen, and Danqi Chen. What in-context learning “learns” in-context: Disentangling task recognition and task learning. InFindings of the Association for Computational Linguistics: ACL 2023, pages 8298–8319, 2023
work page 2023
-
[9]
Latent concept disentanglement in transformer-based language models
Guan Zhe Hong, Bhavya Vasudeva, Vatsal Sharan, Cyrus Rashtchian, Prabhakar Raghavan, and Rina Panigrahy. Latent concept disentanglement in transformer-based language models. InProceedings of the 14th International Conference on Learning Representations, 2026
work page 2026
-
[10]
Clément Dumas, Chris Wendler, Veniamin Veselovsky, Giovanni Monea, and Robert West. Separating tongue from thought: Activation patching reveals language-agnostic concept repre- sentations in transformers. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics, pages 31822–31841, 2025
work page 2025
-
[11]
Sparse autoencoders find highly interpretable features in language models
Robert Huben, Hoagy Cunningham, Logan Riggs Smith, Aidan Ewart, and Lee Sharkey. Sparse autoencoders find highly interpretable features in language models. InProceedings of the 12th International Conference on Learning Representations, 2024
work page 2024
-
[12]
Independent subspace analysis for unsupervised learning of disentangled representations
Jan Stuehmer, Richard Turner, and Sebastian Nowozin. Independent subspace analysis for unsupervised learning of disentangled representations. InProceedings of the 23rd International Conference on Artificial Intelligence and Statistics, pages 1200–1210, 2020
work page 2020
-
[13]
Fast multi-instance partial-label learning
Yin-Fang Yang, Wei Tang, and Min-Ling Zhang. Fast multi-instance partial-label learning. InProceedings of the 39th AAAI Conference on Artificial Intelligence, Philadelphia, pages 22038–22046, 2025
work page 2025
-
[14]
Locating and editing factual associations in GPT
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in GPT. InAdvances in Neural Information Processing Systems 35, pages 17359– 17372, 2022
work page 2022
-
[15]
Llama Team. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Word translation without parallel data
Guillaume Lample, Alexis Conneau, Marc’Aurelio Ranzato, Ludovic Denoyer, and Hervé Jégou. Word translation without parallel data. InProceedings of the 6th International Conference on Learning Representations, 2018
work page 2018
-
[17]
Qwen2.5-Coder Technical Report
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tingyu X...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
What can transformers learn in-context? a case study of simple function classes
Shivam Garg, Dimitris Tsipras, Percy Liang, and Gregory Valiant. What can transformers learn in-context? a case study of simple function classes. InAdvances in Neural Information Processing Systems 35, pages 30583–30598, 2022
work page 2022
-
[19]
What learning algorithm is in-context learning? investigations with linear models
Ekin Akyürek, Dale Schuurmans, Jacob Andreas, Tengyu Ma, and Denny Zhou. What learning algorithm is in-context learning? investigations with linear models. InProceedings of the 11th International Conference on Learning Representations, 2023
work page 2023
-
[20]
Transformers learn in-context by gradient descent
Johannes von Oswald, Eyvind Niklasson, Ettore Randazzo, João Sacramento, Alexander Mordvintsev, Andrey Zhmoginov, and Max Vladymyrov. Transformers learn in-context by gradient descent. InProceedings of the 40th International Conference on Machine Learning, pages 35151–35174, 2023
work page 2023
-
[21]
Why can GPT learn in-context? language models secretly perform gradient descent as meta-optimizers
Damai Dai, Yutao Sun, Li Dong, Yaru Hao, Shuming Ma, Zhifang Sui, and Furu Wei. Why can GPT learn in-context? language models secretly perform gradient descent as meta-optimizers. InFindings of the 61st Annual Meeting of the Association for Computational Linguistics, pages 4005–4019, 2023
work page 2023
-
[22]
Transformers learn to implement preconditioned gradient descent for in-context learning
Kwangjun Ahn, Xiang Cheng, Hadi Daneshmand, and Suvrit Sra. Transformers learn to implement preconditioned gradient descent for in-context learning. InAdvances in Neural Information Processing Systems 36, pages 45614–45650, 2023
work page 2023
-
[23]
Pretraining task diversity and the emergence of non-bayesian in-context learning for regression
Allan Raventós, Mansheej Paul, Feng Chen, and Surya Ganguli. Pretraining task diversity and the emergence of non-bayesian in-context learning for regression. InAdvances in Neural Information Processing Systems 36, pages 14228–14246, 2023
work page 2023
-
[24]
Louis Kirsch, James Harrison, Jascha Sohl-Dickstein, and Luke Metz. General-purpose in- context learning by meta-learning transformers.arXiv preprint arXiv:2212.04458, 2022
-
[25]
The learnability of in-context learning
Noam Wies, Yoav Levine, and Amnon Shashua. The learnability of in-context learning. In Advances in Neural Information Processing Systems 36, pages 36637–36651, 2023
work page 2023
-
[26]
In-context Learning and Induction Heads
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, et al. In-context learning and induction heads.arXiv preprint arXiv:2209.11895, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[27]
Liu Yang, Ziqian Lin, Kangwook Lee, Dimitris Papailiopoulos, and Robert D. Nowak. Task vectors in in-context learning: Emergence, formation, and benefits. InProceedings of the Second Conference on Language Modeling, 2025
work page 2025
-
[28]
Pang Wei Koh, Thao Nguyen, Yew Siang Tang, Stephen Mussmann, Emma Pierson, Been Kim, and Percy Liang. Concept bottleneck models. InProceedings of the 37th International Conference on Machine Learning, pages 5338–5348, 2020
work page 2020
-
[29]
Editable concept bottleneck models
Lijie Hu, Chenyang Ren, Zhengyu Hu, Hongbin Lin, Cheng-Long Wang, Zhen Tan, Weimin Lyu, Jingfeng Zhang, Hui Xiong, and Di Wang. Editable concept bottleneck models. InProceedings of the 42nd International Conference on Machine Learning, pages 24678–24726, 2025
work page 2025
-
[30]
Semi-supervised concept bottleneck models
Lijie Hu, Tianhao Huang, Huanyi Xie, Xilin Gong, Chenyang Ren, Zhengyu Hu, Lu Yu, Ping Ma, and Di Wang. Semi-supervised concept bottleneck models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2110–2119, 2025. 13
work page 2025
-
[31]
Been Kim, Martin Wattenberg, Justin Gilmer, Carrie Cai, James Wexler, Fernanda Viégas, and Rory Sayres. Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (TCAV). InProceedings of the 35th International Conference on Machine Learning, pages 2668–2677, 2018
work page 2018
-
[32]
Concept whitening for interpretable image recognition
Zhi Chen, Yijie Bei, and Cynthia Rudin. Concept whitening for interpretable image recognition. Nature Machine Intelligence, 2(12):772–782, 2020
work page 2020
-
[33]
Concept embedding models: Beyond the accuracy- explainability trade-off
Mateo Espinosa Zarlenga, Pietro Barbiero, Gabriele Ciravegna, Giuseppe Marra, Francesco Giannini, Michelangelo Diligenti, Zohreh Shams, Frederic Precioso, Stefano Melacci, Adrian Weller, Pietro Lió, and Mateja Jamnik. Concept embedding models: Beyond the accuracy- explainability trade-off. InAdvances in Neural Information Processing Systems 35, pages 2140...
work page 2022
-
[34]
Challenging common assumptions in the unsupervised learning of disentangled representations
Francesco Locatello, Stefan Bauer, Mario Lucic, Gunnar Rätsch, Sylvain Gelly, Bernhard Schölkopf, and Olivier Bachem. Challenging common assumptions in the unsupervised learning of disentangled representations. InProceedings of the 36th International Conference on Machine Learning, pages 4114–4124, 2019
work page 2019
-
[35]
Kingma, Ricardo Pio Monti, and Aapo Hyvärinen
Ilyes Khemakhem, Diederik P. Kingma, Ricardo Pio Monti, and Aapo Hyvärinen. Variational autoencoders and nonlinear ICA: A unifying framework. InProceedings of the 23rd International Conference on Artificial Intelligence and Statistics, pages 2207–2217, 2020
work page 2020
-
[36]
There was never a bottleneck in concept bottleneck models
Antonio Almudévar, José Miguel Hernández-Lobato, and Alfonso Ortega. There was never a bottleneck in concept bottleneck models. InProceedings of the 14th International Conference on Learning Representations, 2026
work page 2026
-
[37]
Investigating gender bias in language models using causal mediation analysis
Jesse Vig, Sebastian Gehrmann, Yonatan Belinkov, Sharon Qian, Daniel Nevo, Yaron Singer, and Stuart Shieber. Investigating gender bias in language models using causal mediation analysis. InAdvances in Neural Information Processing Systems 33, pages 12388–12401, 2020
work page 2020
-
[38]
Causal abstractions of neural networks
Atticus Geiger, Hanson Lu, Thomas Icard, and Christopher Potts. Causal abstractions of neural networks. InAdvances in Neural Information Processing Systems 34, pages 9574–9586, 2021
work page 2021
-
[39]
Interpretability in the wild: A circuit for indirect object identification in GPT-2 small
Kevin Ro Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. Interpretability in the wild: A circuit for indirect object identification in GPT-2 small. In Proceedings of the 11th International Conference on Learning Representations, 2023
work page 2023
-
[40]
Mavor-Parker, Aengus Lynch, Stefan Heimersheim, and Adrià Garriga-Alonso
Arthur Conmy, Augustine N. Mavor-Parker, Aengus Lynch, Stefan Heimersheim, and Adrià Garriga-Alonso. Towards automated circuit discovery for mechanistic interpretability. In Advances in Neural Information Processing Systems 36, pages 16318–16352, 2023
work page 2023
-
[41]
Towards best practices of activation patching in language models: Metrics and methods
Fred Zhang and Neel Nanda. Towards best practices of activation patching in language models: Metrics and methods. InProceedings of the 12th International Conference on Learning Representations, 2024
work page 2024
-
[42]
Aleksandar Makelov, Georg Lange, Atticus Geiger, and Neel Nanda. Is this the subspace you are looking for? an interpretability illusion for subspace activation patching. InProceedings of the 12th International Conference on Learning Representations, 2024. 14
work page 2024
-
[43]
Tianyu Guo, Wei Hu, Song Mei, Huan Wang, Caiming Xiong, Silvio Savarese, and Yu Bai. How do transformers learn in-context beyond simple functions? a case study on learning with repre- sentations. InProceedings of the 12th International Conference on Learning Representations, 2024
work page 2024
-
[44]
Jianliang He, Xintian Pan, Siyu Chen, and Zhuoran Yang. In-context linear regression demystified: Training dynamics and mechanistic interpretability of multi-head softmax attention. InProceedings of the 42nd International Conference on Machine Learning, pages 22686–22742, 2025
work page 2025
-
[45]
Arthur E. Hoerl and Robert W. Kennard. Ridge regression: Biased estimation for nonorthogonal problems.Technometrics, 12(1):55–67, 1970
work page 1970
-
[46]
Bishop.Pattern Recognition and Machine Learning
Christopher M. Bishop.Pattern Recognition and Machine Learning. Springer, 2006
work page 2006
-
[47]
Murphy.Machine Learning: A Probabilistic Perspective
Kevin P. Murphy.Machine Learning: A Probabilistic Perspective. MIT Press, 2012
work page 2012
-
[48]
ProMIPL: A probabilistic generative model for multi-instance partial-label learning
Yin-Fang Yang, Wei Tang, and Min-Ling Zhang. ProMIPL: A probabilistic generative model for multi-instance partial-label learning. InProceedings of the 24th IEEE International Conference on Data Mining, pages 560–569, 2024
work page 2024
-
[49]
Trevor Hastie, Robert Tibshirani, and Jerome Friedman.The Elements of Statistical Learning: Data Mining, Inference, and Prediction. Springer, 2 edition, 2009
work page 2009
-
[50]
Wainwright.High-Dimensional Statistics: A Non-Asymptotic Viewpoint
Martin J. Wainwright.High-Dimensional Statistics: A Non-Asymptotic Viewpoint. Cambridge University Press, 2019
work page 2019
-
[51]
In-context learning creates task vectors
Roee Hendel, Mor Geva, and Amir Globerson. In-context learning creates task vectors. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 9318–9333, 2023
work page 2023
-
[52]
Sheng Liu, Haotian Ye, Lei Xing, and James Y. Zou. In-context vectors: Making in context learning more effective and controllable through latent space steering. InProceedings of the 41st International Conference on Machine Learning, volume 235, pages 32287–32307, 2024
work page 2024
-
[53]
Li, Arnab Sen Sharma, Aaron Mueller, Byron C
Eric Todd, Millicent L. Li, Arnab Sen Sharma, Aaron Mueller, Byron C. Wallace, and David Bau. Function vectors in large language models. InProceedings of the 12th International Conference on Learning Representations, 2024
work page 2024
-
[54]
Language models implement simple Word2Vec-style vector arithmetic
Jack Merullo, Carsten Eickhoff, and Ellie Pavlick. Language models implement simple Word2Vec-style vector arithmetic. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 5030–5047, 2024
work page 2024
-
[55]
Understanding task vectors in in-context learning: Emergence, functionality, and limitations
Yuxin Dong, Jiachen Jiang, Zhihui Zhu, and Xia Ning. Understanding task vectors in in-context learning: Emergence, functionality, and limitations. InProceedings of the 14th International Conference on Learning Representations, 2026
work page 2026
-
[56]
Dake Bu, Wei Huang, Andi Han, Atsushi Nitanda, Qingfu Zhang, Hau-San Wong, and Taiji Suzuki. Provable in-context vector arithmetic via retrieving task concepts. InProceedings of the 42nd International Conference on Machine Learning, pages 5669–5724, 2025. 15 A Additional Theory and Proofs A.1 Noisy labels in concept space We extend Equation (1) to homosce...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.