MS-Resampler: Multi-Scope Visual Resampling for Efficient Multimodal LLMs
Pith reviewed 2026-07-01 05:39 UTC · model grok-4.3
The pith
MS-Resampler improves visual understanding in multimodal LLMs by resampling features across multiple spatial scopes and fusing the results adaptively.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
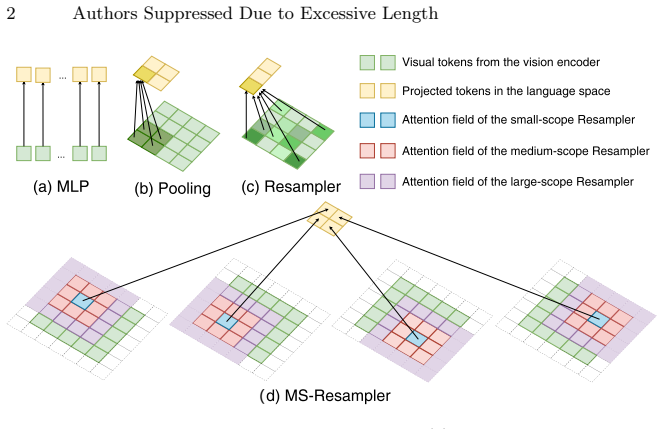
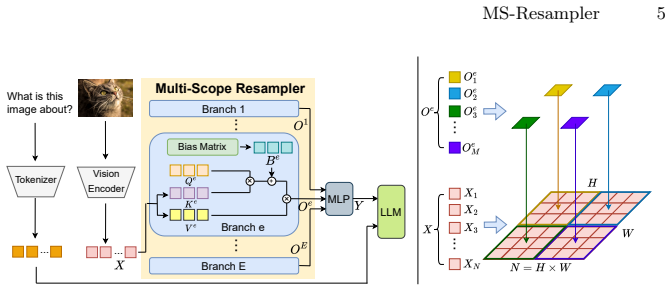
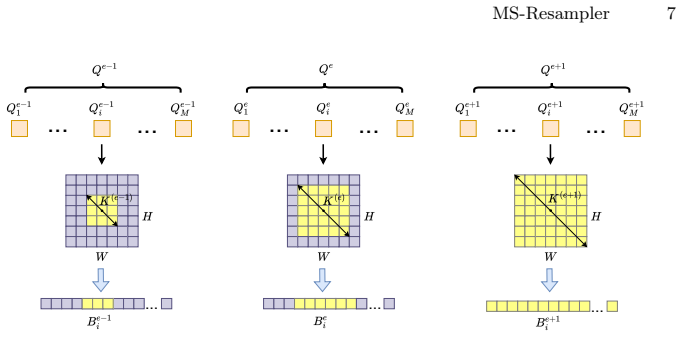
MS-Resampler instantiates multiple scope-specific resamplers by injecting explicit spatial scope priors into the resampling attention, enabling each branch to aggregate visual information at a particular granularity from local to global. The outputs of these scope-specific resamplers are then adaptively fused to produce the final visual representations for language modeling.
What carries the argument
Multiple parallel scope-specific resampling attentions, each conditioned on a distinct spatial scope prior, whose outputs are combined by adaptive fusion.
If this is right
- Better scores on visual understanding and multimodal reasoning benchmarks
- Improved ability to keep both fine local evidence and overall scene context inside a fixed token budget
- Only minimal extra computation compared with conventional single-scope resamplers
- Consistent gains across multiple public multimodal evaluation sets
Where Pith is reading between the lines
- The same multi-scope idea could be tested on video or audio inputs to see whether scope-specific branches help there as well
- If the adaptive fusion learns to down-weight certain scopes on particular tasks, that pattern might guide future fixed-scope designs
- Higher-resolution input images might become usable without raising the token count, because local-scope branches already focus on detail
Load-bearing premise
That giving separate branches explicit spatial scope priors and then fusing their outputs will extract complementary local and global information that a single fixed-scope global attention cannot capture under the same token limit.
What would settle it
A controlled experiment on the same ten benchmarks in which a single-scope resampler, given the same token budget and training regime, matches or exceeds MS-Resampler accuracy on every task with equal or lower compute.
Figures
read the original abstract
Multimodal large language models (MLLMs) typically employ resampling-based projectors to transform dense visual features into a compact token sequence for language modeling. Most existing resamplers adopt a single, fixed aggregation scope via global cross-attention, which can blur fine-grained local evidence and limit the ability to capture both local details and global context within a fixed token budget. In this work, we propose MS-Resampler, a multi-scope visual resampling framework for MLLMs. MS-Resampler instantiates multiple scope-specific resamplers by injecting explicit spatial scope priors into the resampling attention, enabling each branch to aggregate visual information at a particular granularity from local to global. The outputs of these scope-specific resamplers are then adaptively fused to produce the final visual representations for language modeling. Extensive experiments on ten public multimodal benchmarks show that MS-Resampler consistently improves visual understanding and multimodal reasoning over conventional single-scope resamplers, while introducing only minimal computational overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MS-Resampler, a multi-scope visual resampling framework for multimodal large language models (MLLMs). It replaces conventional single-scope global cross-attention resamplers with multiple parallel branches, each receiving an explicit spatial scope prior to aggregate visual features at different granularities (local to global). Branch outputs are adaptively fused to produce the final visual token sequence under a fixed token budget. Experiments across ten public multimodal benchmarks are reported to show consistent gains in visual understanding and multimodal reasoning with only minimal computational overhead.
Significance. If the empirical improvements are robust, the work offers a practical architectural refinement for efficient MLLMs by explicitly addressing the trade-off between local detail and global context within a constrained token budget. The multi-branch design with injected spatial priors and adaptive fusion is a coherent extension of existing resampling projectors, and the fixed-budget framing supports the minimal-overhead claim. The approach could be adopted in resource-constrained multimodal settings if the gains generalize beyond the reported benchmarks.
major comments (1)
- Abstract: the central claim that MS-Resampler 'consistently improves visual understanding and multimodal reasoning' rests entirely on unreported empirical results from ten benchmarks; no quantitative deltas, baseline comparisons, ablation tables, error bars, or statistical significance tests are supplied, so the load-bearing performance assertion cannot be evaluated for soundness or reproducibility.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for quantitative support in the abstract. We address this point directly below and will revise accordingly.
read point-by-point responses
-
Referee: Abstract: the central claim that MS-Resampler 'consistently improves visual understanding and multimodal reasoning' rests entirely on unreported empirical results from ten benchmarks; no quantitative deltas, baseline comparisons, ablation tables, error bars, or statistical significance tests are supplied, so the load-bearing performance assertion cannot be evaluated for soundness or reproducibility.
Authors: We agree that the abstract would be stronger with explicit quantitative backing. In the revised manuscript we will add concise performance deltas (e.g., average improvement over single-scope baselines across the ten benchmarks) and a pointer to the detailed tables, ablations, and multi-run statistics already present in the Experiments section. This makes the central claim directly evaluable from the abstract while preserving its brevity. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents MS-Resampler as an architectural proposal: multiple parallel resampling branches each conditioned on a distinct explicit spatial scope prior, with adaptive fusion of outputs under fixed token budget. The central claim is an empirical performance gain on external benchmarks, not a first-principles derivation or prediction. No equations, fitted parameters, or self-citations are shown that reduce the claimed improvement to a re-expression of the inputs by construction. The design is presented as a novel construction whose validity rests on experimental results rather than internal definitional equivalence.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard cross-attention can be modified by explicit spatial scope priors to produce scope-specific aggregations
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023) 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Advances in neural information processing systems35, 23716– 23736 (2022) 3
Alayrac, J.B., Donahue, J., Luc, P., Miech, A., Barr, I., Hasson, Y., Lenc, K., Men- sch, A., Millican, K., Reynolds, M., et al.: Flamingo: a visual language model for few-shot learning. Advances in neural information processing systems35, 23716– 23736 (2022) 3
2022
-
[3]
Alvar, S.R., Singh, G., Akbari, M., Zhang, Y.: Divprune: Diversity-based visual tokenpruningforlargemultimodalmodels.In:ProceedingsoftheComputerVision and Pattern Recognition Conference. pp. 9392–9401 (2025) 4
2025
-
[4]
In: Proceedings of the AAAI Conference on Artificial In- telligence
Arif, K.H.I., Yoon, J., Nikolopoulos, D.S., Vandierendonck, H., John, D., Ji, B.: Hired: Attention-guided token dropping for efficient inference of high-resolution vision-language models. In: Proceedings of the AAAI Conference on Artificial In- telligence. vol. 39, pp. 1773–1781 (2025) 10
2025
-
[5]
Bai, J., Bai, S., Chu, Y., Cui, Z., Dang, K., Deng, X., Fan, Y., Ge, W., Han, Y., Huang, F., et al.: Qwen technical report. arXiv preprint arXiv:2309.16609 (2023) 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Bai, J., Bai, S., Yang, S., Wang, S., Tan, S., Wang, P., Lin, J., Zhou, C., Zhou, J.: Qwen-vl: A frontier large vision-language model with versatile abilities. arXiv preprint arXiv:2308.129661(2), 3 (2023) 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Cha, J., Kang, W., Mun, J., Roh, B.: Honeybee: Locality-enhanced projector for multimodal llm. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13817–13827 (2024) 2, 4, 9, 10, 11
2024
-
[8]
In: European Conference on Computer Vision
Chen, L., Zhao, H., Liu, T., Bai, S., Lin, J., Zhou, C., Chang, B.: An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models. In: European Conference on Computer Vision. pp. 19–35. Springer (2024) 10
2024
-
[9]
Chen, Z., Wang, W., Tian, H., Ye, S., Gao, Z., Cui, E., Tong, W., Hu, K., Luo, J., Ma, Z., et al.: How far are we to gpt-4v? closing the gap to commercial multimodal modelswith open-source suites.Science China InformationSciences67(12),220101 (2024) 9, 10, 11
2024
-
[10]
See https://vicuna
Chiang, W.L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023)2(3), 6 (2023) 9
2023
-
[11]
MobileVLM V2: Faster and Stronger Baseline for Vision Language Model
Chu, X., Qiao, L., Zhang, X., Xu, S., Wei, F., Yang, Y., Sun, X., Hu, Y., Lin, X., Zhang, B., et al.: Mobilevlm v2: Faster and stronger baseline for vision language model. arXiv preprint arXiv:2402.03766 (2024) 2, 4, 9, 10, 11
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Advances in Neural Information Pro- cessing Systems37, 50168–50188 (2024) 2, 9, 10
Hu, W., Dou, Z.Y., Li, L., Kamath, A., Peng, N., Chang, K.W.: Matryoshka query transformer for large vision-language models. Advances in Neural Information Pro- cessing Systems37, 50168–50188 (2024) 2, 9, 10
2024
-
[13]
Qwen2.5-Coder Technical Report
Hui, B., Yang, J., Cui, Z., Yang, J., Liu, D., Zhang, L., Liu, T., Zhang, J., Yu, B., Lu, K., et al.: Qwen2. 5-coder technical report. arXiv preprint arXiv:2409.12186 (2024) 9, 11
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Microsoft Research Blog1(3), 3 (2023) 4 16 Authors Suppressed Due to Excessive Length
Javaheripi, M., Bubeck, S., Abdin, M., Aneja, J., Bubeck, S., Mendes, C.C.T., Chen, W., Del Giorno, A., Eldan, R., Gopi, S., et al.: Phi-2: The surprising power of small language models. Microsoft Research Blog1(3), 3 (2023) 4 16 Authors Suppressed Due to Excessive Length
2023
-
[15]
In: International conference on machine learning
Jia, C., Yang, Y., Xia, Y., Chen, Y.T., Parekh, Z., Pham, H., Le, Q., Sung, Y.H., Li, Z., Duerig, T.: Scaling up visual and vision-language representation learning with noisy text supervision. In: International conference on machine learning. pp. 4904–4916. PMLR (2021) 3
2021
-
[16]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Lee, Y., Kim, J., Willette, J., Hwang, S.J.: Mpvit: Multi-path vision transformer for dense prediction. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 7287–7296 (2022) 4
2022
-
[17]
arXiv e-prints pp
Li, H., Zhang, J., Liao, W., Peng, D., Ding, K., Jin, L.: Beyond token compression: A training-free reduction framework for efficient visual processing in mllms. arXiv e-prints pp. arXiv–2501 (2025) 4
2025
-
[18]
In: International conference on machine learning
Li, J., Li, D., Savarese, S., Hoi, S.: Blip-2: Bootstrapping language-image pre- training with frozen image encoders and large language models. In: International conference on machine learning. pp. 19730–19742. PMLR (2023) 2, 3
2023
-
[19]
arXiv preprint arXiv:2407.02392 (2024) 2, 4, 9, 10, 11
Li, W., Yuan, Y., Liu, J., Tang, D., Wang, S., Qin, J., Zhu, J., Zhang, L.: Tokenpacker: Efficient visual projector for multimodal llm. arXiv preprint arXiv:2407.02392 (2024) 2, 4, 9, 10, 11
-
[20]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Liu, H., Li, C., Li, Y., Lee, Y.J.: Improved baselines with visual instruction tuning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 26296–26306 (2024) 2, 3, 4, 9
2024
-
[21]
Advances in neural information processing systems36, 34892–34916 (2023) 2, 3
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. Advances in neural information processing systems36, 34892–34916 (2023) 2, 3
2023
-
[22]
arXiv preprint arXiv:2411.10803 (2024) 10
Liu, T., Shi, L., Hong, R., Hu, Y., Yin, Q., Zhang, L.: Multi-stage vision to- ken dropping: Towards efficient multimodal large language model. arXiv preprint arXiv:2411.10803 (2024) 10
-
[23]
Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., Guo, B.: Swin transformer:Hierarchicalvisiontransformerusingshiftedwindows.In:Proceedings of the IEEE/CVF international conference on computer vision. pp. 10012–10022 (2021) 4
2021
-
[24]
Pattern Recognition153, 110470 (2024) 5
Nie, X., Jin, H., Yan, Y., Chen, X., Zhu, Z., Qi, D.: Scopevit: Scale-aware vision transformer. Pattern Recognition153, 110470 (2024) 5
2024
-
[25]
arXiv preprint arXiv:2410.10319 (2024) 4, 9, 10
Qian, S., Liu, B., Sun, C., Xu, Z., Wang, B.: Spatial-aware efficient projector for mllms via multi-layer feature aggregation. arXiv preprint arXiv:2410.10319 (2024) 4, 9, 10
-
[26]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021) 1, 3, 4, 9
2021
-
[27]
arXiv preprint arXiv:2403.15388 (2024) 10
Shang, Y., Cai, M., Xu, B., Lee, Y.J., Yan, Y.: Llava-prumerge: Adaptive token reduction for efficient large multimodal models. arXiv preprint arXiv:2403.15388 (2024) 10
-
[28]
LLaMA: Open and Efficient Foundation Language Models
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) 4
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
In: European conference on computer vision
Tu, Z., Talebi, H., Zhang, H., Yang, F., Milanfar, P., Bovik, A., Li, Y.: Maxvit: Multi-axis vision transformer. In: European conference on computer vision. pp. 459–479. Springer (2022) 5
2022
-
[30]
arXiv preprint arXiv:2502.11494 (2025) 10 MS-Resampler 17
Wen, Z., Gao, Y., Wang, S., Zhang, J., Zhang, Q., Li, W., He, C., Zhang, L.: Stop looking for important tokens in multimodal language models: Duplication matters more. arXiv preprint arXiv:2502.11494 (2025) 10 MS-Resampler 17
-
[31]
PyramidDrop: Accelerating Your Large Vision-Language Models via Pyramid Visual Redundancy Reduction
Xing, L., Huang, Q., Dong, X., Lu, J., Zhang, P., Zang, Y., Cao, Y., He, C., Wang, J., Wu, F., et al.: Pyramiddrop: Accelerating your large vision-language models via pyramid visual redundancy reduction. arXiv preprint arXiv:2410.17247 (2024) 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
arXiv preprint arXiv:2409.10197 (2024) 10
Ye, W., Wu, Q., Lin, W., Zhou, Y.: Fit and prune: Fast and training-free visual token pruning for multi-modal large language models. arXiv preprint arXiv:2409.10197 (2024) 10
-
[33]
arXiv preprint arXiv:2512.18910 (2025) 4
Zamini, M., Shukla, D.: Delta-llava: Base-then-specialize alignment for token- efficient vision-language models. arXiv preprint arXiv:2512.18910 (2025) 4
-
[34]
In: Proceedings of the IEEE/CVF international conference on computer vision
Zhai, X., Mustafa, B., Kolesnikov, A., Beyer, L.: Sigmoid loss for language im- age pre-training. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 11975–11986 (2023) 1, 4
2023
-
[35]
arXiv preprint arXiv:2412.01818 (2024) 9, 10
Zhang, Q., Cheng, A., Lu, M., Zhuo, Z., Wang, M., Cao, J., Guo, S., She, Q., Zhang, S.: [cls] attention is all you need for training-free visual token pruning: Make vlm inference faster. arXiv preprint arXiv:2412.01818 (2024) 9, 10
-
[36]
arXiv preprint arXiv:2501.03895 (2025) 4
Zhang, S., Fang, Q., Yang, Z., Feng, Y.: Llava-mini: Efficient image and video large multimodal models with one vision token. arXiv preprint arXiv:2501.03895 (2025) 4
-
[37]
SparseVLM: Visual Token Sparsification for Efficient Vision-Language Model Inference
Zhang, Y., Fan, C.K., Ma, J., Zheng, W., Huang, T., Cheng, K., Gudovskiy, D., Okuno, T., Nakata, Y., Keutzer, K., et al.: Sparsevlm: Visual token sparsifica- tion for efficient vision-language model inference. arXiv preprint arXiv:2410.04417 (2024) 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Zhao, S., Wang, Z., Juefei-Xu, F., Xia, X., Liu, M., Wang, X., Liang, M., Zhang, N., Metaxas, D.N., Yu, L.: Accelerating multimodal large language models by search- ing optimal vision token reduction. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 29869–29879 (2025) 4
2025
-
[39]
arXiv preprint arXiv:2510.16598 (2025) 4
Zhu, J., Zhu, Y., Lu, X., Yan, W., Li, D., Liu, K., Fu, X., Zha, Z.J.: Visionselector: End-to-end learnable visual token compression for efficient multimodal llms. arXiv preprint arXiv:2510.16598 (2025) 4
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.