From Forecasting Leaderboards to Deployment Decisions: A Fail-Closed Certification Protocol
Pith reviewed 2026-06-26 00:16 UTC · model grok-4.3
The pith
A fail-closed certification protocol determines when forecasting leaderboard winners can be treated as deployment-actionable after accounting for decision friction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
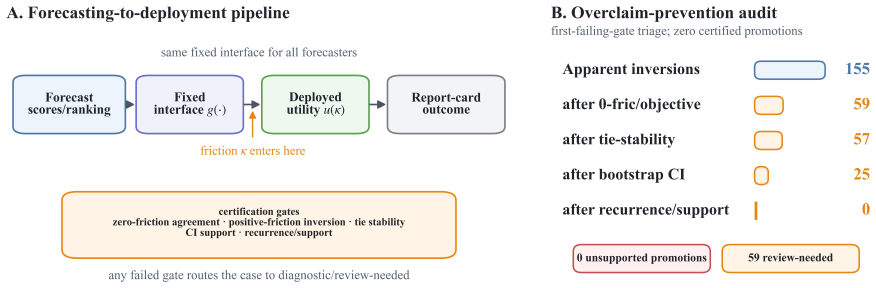
The central claim is that a locked native audit can enforce sufficient evidential conditions for a friction-caused, non-tie, statistically supported, and recurrent deployment-side reversal; when those conditions are absent across the full grid of 22 candidates and 362 cells, the leaderboard winner may be certified as deployment-actionable for the specified interface.
What carries the argument
The fail-closed certification protocol, whose gates test for overclaiming by checking whether positive switching friction produces a deployment reversal that the forecast ranking misses.
If this is right
- When all gates pass, the forecast winner can be read as deployment-actionable top-1 advice for that interface.
- Positive switching friction is sufficient to make the leaderboard winner deployed-suboptimal even when predictive quality ranks it first.
- The protocol blocks certification in any cell where an apparent inversion survives the audit.
- The same gates apply to any fixed interface such as an alert threshold or top-k budget.
Where Pith is reading between the lines
- Organizations could adopt the protocol as a pre-deployment filter to avoid acting on leaderboard ranks that will reverse under realistic costs.
- The approach separates leaderboard evaluation from deployment evaluation without requiring a new utility function or forecaster.
- Repeated application across multiple domains would quantify how often friction reversals occur in practice.
Load-bearing premise
The decision interface is fixed and known in advance, and the locked audit can detect and block every instance of overclaiming without missing valid reversals.
What would settle it
A single observed case in which the protocol certifies a winner yet a friction-induced reversal still appears in deployment would falsify the claim that the gates are sufficient.
Figures
read the original abstract
Forecasting leaderboards rank models by predictive quality, but their winners are often read as deployment-ready top-1 advice. That reading can fail when forecasts are passed through a fixed decision interface, such as an alert threshold, a top-k budget, or a switching-cost policy. We study when a forecast-side winner can be certified as deployment-actionable for a specified interface and deployed utility. We introduce a fail-closed certification protocol whose gates are sufficient evidential conditions for a strong claim: a friction-caused, non-tie, statistically supported, and recurrent deployment-side reversal. Traffic-Hourly provides a certified anchor: winners agree at zero friction, but positive switching friction makes the forecast winner deployed-suboptimal. A locked native audit tests overclaiming: across 22 verified candidates and 362 full-grid cells, 155 apparent forecast/deployment winner inversions are blocked before certification. The contribution is not a new forecaster, metric, or universal utility, but a conservative protocol for deciding when forecasting leaderboard winners should be read as deployment-actionable top-1 advice.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a fail-closed certification protocol whose gates supply sufficient evidential conditions for certifying that a forecasting leaderboard winner is deployment-actionable under a fixed decision interface. Using the Traffic-Hourly dataset as anchor, it reports that forecast winners agree with deployment winners at zero friction but become suboptimal once positive switching friction is introduced; a locked native audit then blocks 155 apparent inversions across 22 candidates and 362 cells before any certification is issued. The central claim is therefore not a new forecaster or metric but a conservative, audit-enforced procedure for deciding when leaderboard rankings may safely be read as top-1 deployment advice.
Significance. If the protocol’s evidential gates hold, the work supplies a practical safeguard against over-interpreting predictive rankings as deployment prescriptions when decision interfaces incorporate thresholds, budgets, or switching costs. The explicit numerical illustration (22 candidates, 362 cells, 155 blocked inversions) and the emphasis on recurrence and external statistical support constitute concrete, falsifiable elements that distinguish the contribution from purely conceptual proposals.
major comments (2)
- [Abstract and methods description of the audit] The locked native audit is load-bearing for the certified-anchor claim, yet the manuscript supplies no formal decision rule, coverage argument, or completeness proof that the procedure detects every friction-induced reversal (and only those) across the full 22×362 grid. Without this, the statement that 155 inversions were blocked cannot be verified as sufficient to underwrite the fail-closed guarantee.
- [Protocol definition and Traffic-Hourly anchor] The claim that the protocol yields “sufficient evidential conditions” for a friction-caused, non-tie, statistically supported, and recurrent reversal rests on the assumption that the decision interface is fixed and known in advance; the manuscript does not demonstrate how the protocol would behave if the interface itself were misspecified or learned from the same data used for certification.
minor comments (2)
- [Abstract] Notation for the switching-friction parameter and the “full-grid cells” should be introduced with explicit definitions and units before the numerical example is presented.
- [Protocol section] The manuscript would benefit from a small table or diagram enumerating the four gates of the protocol and the exact statistical test used for each.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Abstract and methods description of the audit] The locked native audit is load-bearing for the certified-anchor claim, yet the manuscript supplies no formal decision rule, coverage argument, or completeness proof that the procedure detects every friction-induced reversal (and only those) across the full 22×362 grid. Without this, the statement that 155 inversions were blocked cannot be verified as sufficient to underwrite the fail-closed guarantee.
Authors: We agree that an explicit decision rule and coverage discussion would strengthen verifiability. The audit applies a deterministic conjunction of the four gates (friction-caused, non-tie, statistically supported, recurrent) to every cell in the enumerated 22×362 grid; the 155 blocked cases are exactly those failing at least one gate. In revision we will insert pseudocode for the rule and note that exhaustive enumeration on this fixed grid supplies complete coverage for the reported anchor experiment. We do not supply a general completeness theorem for arbitrary interfaces, as the protocol is defined relative to a known fixed interface and the Traffic-Hourly anchor. revision: yes
-
Referee: [Protocol definition and Traffic-Hourly anchor] The claim that the protocol yields “sufficient evidential conditions” for a friction-caused, non-tie, statistically supported, and recurrent reversal rests on the assumption that the decision interface is fixed and known in advance; the manuscript does not demonstrate how the protocol would behave if the interface itself were misspecified or learned from the same data used for certification.
Authors: The protocol is explicitly conditioned on a fixed, known decision interface; the sufficient-evidential-conditions claim holds only under that precondition. When the interface is misspecified or learned from the certification data, the gates are not satisfied and certification is withheld. We will revise the protocol section and abstract to state this assumption more prominently. The manuscript does not analyze behavior under misspecification, because the contribution is a conservative certification procedure for the stated setting rather than a robustness result for interface uncertainty. revision: partial
Circularity Check
No circularity: protocol relies on external audit and statistical checks rather than self-referential definitions
full rationale
The paper's central claim is that a fail-closed protocol with a locked native audit supplies sufficient conditions for certifying deployment reversals. No derivation step reduces by construction to its own inputs: the audit is presented as an independent, fixed mechanism that blocks 155 inversions across a 22×362 grid, the zero-friction agreement is stated as an empirical observation, and recurrence/statistical support are external conditions. No self-citations, fitted parameters renamed as predictions, or ansatzes smuggled via prior work appear in the provided text. The protocol is self-contained against the stated external benchmarks (audit completeness, recurrence checks) and does not equate its target claim to its inputs by definition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The decision interface (threshold, budget, or switching policy) is fixed and specified in advance.
Reference graph
Works this paper leans on
-
[1]
arXiv:2409.19839. Q. Yang, S. Mahns, S. Li, A. Gu, J. Wu, and H. Xu. LLM-as-a-Prophet: Understanding Predictive Intelligence with Prophet Arena. InICLR,
-
[2]
arXiv:2510.17638. T. Aksu, G. Woo, J. Liu, X. Liu, C. Liu, S. Savarese, C. Xiong, and D. Sahoo. GIFT-Eval: A Benchmark for General Time Series Forecasting Model Evaluation. NeurIPS Workshop on Time Series in the Age of Large Models,
-
[3]
Extended version: arXiv:2410.10393. R. Godahewa, C. Bergmeir, G. I. Webb, R. J. Hyndman, and P. Montero-Manso. Monash Time Series Forecasting Archive. InNeurIPS Datasets and Benchmarks,
-
[4]
arXiv:2105.06643. A. Das, W. Kong, R. Sen, and Y. Zhou. A decoder-only foundation model for time-series forecasting. InICML,
-
[5]
arXiv:2310.10688. A. F. Ansari et al. Chronos: Learning the language of time series. arXiv:2403.07815,
- [6]
-
[7]
doi:10.1145/3711896.3737442; arXiv:2410.11802. D. Goktas, G. Riano-Briceno, A. Abdullah, A. Nair, C. Shen, B. de Lucio, A. Magnusson, F. Mashrur, A. Abdulla, S. Sen, M. Thippireddy, G. Schwartz, and A. Greenwald. TempusBench: An Evaluation Framework for Time-Series Forecasting. arXiv:2604.11529,
-
[8]
Z. Zhao, J. Ni, S. Xu, H. Liu, W. Jin, and B. A. Prakash. TimeRecipe: A Time-Series Forecasting Recipe via Benchmarking Module Level Effectiveness. arXiv:2506.06482,
-
[9]
arXiv:2103.03098. R. Longjohn, G. Gopalan, and E. Casleton. Statistical Uncertainty Quantification for Aggregate Performance Metrics in Machine Learning Benchmarks. arXiv:2501.04234,
- [10]
-
[11]
L. Brigato, R. Morand, K. J. Strommen, M. Panagiotou, M. Schmidt, and S. Mougiakakou. Position: There are no Champions in Long-Term Time Series Forecasting. arXiv:2502.14045,
-
[12]
B. Neuhof and Y. Benjamini. Rank Intervals for Leaderboards: A Hierarchical Framework for Model Evaluation. arXiv:2606.08679,
-
[13]
K. Raeth and N. Ludwig. Evaluating Weather Forecasts from a Decision Maker’s Perspective. arXiv:2512.14779,
-
[14]
R. Berlinghieri, D. R. Burt, P. Giani, A. M. Fiore, and T. Broderick. A Framework for Evaluating PM2.5 Forecasts from the Perspective of Individual Decision Making. arXiv:2409.05866,
-
[15]
arXiv:1703.04529. A. N. Elmachtoub and P. Grigas. Smart “Predict, then Optimize”.Management Science, 68(1):9–26,
-
[16]
Earlier version: arXiv:1710.08005. J. Mandi, J. Kotary, S. Berden, M. Mulamba, V. Bucarey, T. Guns, and F. Fioretto. Decision-Focused Learning: Foundations, State of the Art, Benchmark and Future Opportunities.Journal of Artificial Intelligence Research, 80:1623–1701,
-
[17]
Journal of Artificial Intelligence Research , author =
Earlier version: arXiv:2307.13565. doi:10.1613/jair.1.15320. 8 A Report-Card Output and Gate Procedure Appendix roadmap.Appendix A formalizes the report-card labels and first-failing-gate rule used by the fail-closed certification protocol. Appendix B fixes the evidence roles used in the paper. Appendix C reports positive-anchor robustness, Appendix D rep...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.