PASTA: A Paraphrasing And Self-Training Approach for Knowledge Updating in LLMs
Pith reviewed 2026-06-30 09:40 UTC · model grok-4.3
The pith
PASTA updates LLMs with post-cutoff news facts through paraphrasing, QA generation, and self-learning DPO, raising accuracy from 0.02 to 0.82 while preserving general capabilities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
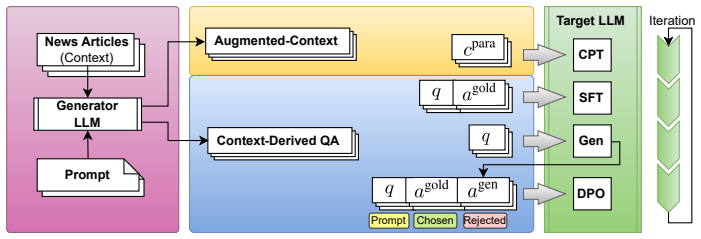
PASTA integrates detailed factual information from news articles as new knowledge into LLMs by combining paraphrasing-based data augmentation, question-answering generation, and a novel self-learning DPO process that simultaneously enables knowledge overwriting and hallucination suppression, achieving accuracy improvements from 0.02 to 0.82 on web articles published after the base model's knowledge cutoff while maintaining general language capabilities.
What carries the argument
The PASTA framework, which chains paraphrasing for data augmentation, QA-pair creation, and self-learning DPO to drive knowledge overwriting without broad capability loss.
If this is right
- Specialized LLMs can be created for narrow domains by feeding in recent articles rather than retraining from scratch.
- Knowledge from new sources can be added efficiently using only synthetic data derived from the source articles themselves.
- The self-learning DPO step suppresses hallucinations that would otherwise appear when the model tries to answer questions about the new material.
- Systematic variation of learning rate, data volume, and augmentation strength reveals configurations that balance updating strength against capability retention.
- The same pipeline can be repeated on successive batches of articles to keep a model current over time.
Where Pith is reading between the lines
- The approach may extend to updating LLMs with other structured factual sources such as scientific papers or legal documents rather than only news.
- If the method scales, it could reduce dependence on retrieval systems for time-sensitive facts by baking the facts directly into the weights.
- Testing whether the updated model retains the new knowledge after further general fine-tuning would clarify how durable the overwrite is.
Load-bearing premise
The combination of paraphrasing-based augmentation, QA generation, and self-learning DPO produces targeted knowledge overwriting without side effects on unrelated capabilities.
What would settle it
Apply PASTA to a different base model with a documented cutoff date, then test accuracy on a fresh set of post-cutoff articles while also measuring scores on standard general benchmarks to check for any drop.
Figures


read the original abstract
Knowledge updating in pre-trained Large Language Models (LLMs) remains an important challenge. While continual training provides a potential avenue for knowledge updating, it continues to present substantial technical difficulties. Furthermore, LLMs often struggle with accurately answering questions about specific factual information, such as news articles - a capability limitation widely recognized in the research community. This paper proposes PASTA, a simple yet powerful framework for integrating detailed factual information from news articles as new knowledge into LLMs, with the primary goal of building specialized models that accurately answer questions about this knowledge. Our framework combines data augmentation, question-answering generation, and a novel self-learning DPO process that simultaneously enables knowledge overwriting and hallucination suppression. We provide insights into effective knowledge updating through systematic analysis of learning parameters and data configurations. In our experimental evaluation with web articles published after the base model's knowledge cutoff, PASTA achieved remarkable improvement from 0.02 to 0.82 accuracy while maintaining general language capabilities, demonstrating its effectiveness for creating domain-specialized LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PASTA, a framework that combines paraphrasing-based data augmentation, QA pair generation, and a novel self-learning DPO process to update LLMs with new factual knowledge from post-cutoff web articles. It claims this enables accurate question answering on the new knowledge (accuracy rising from 0.02 to 0.82) while preserving general language capabilities, supported by analysis of learning parameters and data configurations.
Significance. If the experimental claims hold after proper validation, the work would be significant for practical knowledge updating in LLMs, offering a targeted method to create domain-specialized models without full retraining or catastrophic forgetting. The combination of augmentation and self-training DPO could address a recognized limitation in handling post-training factual updates.
major comments (3)
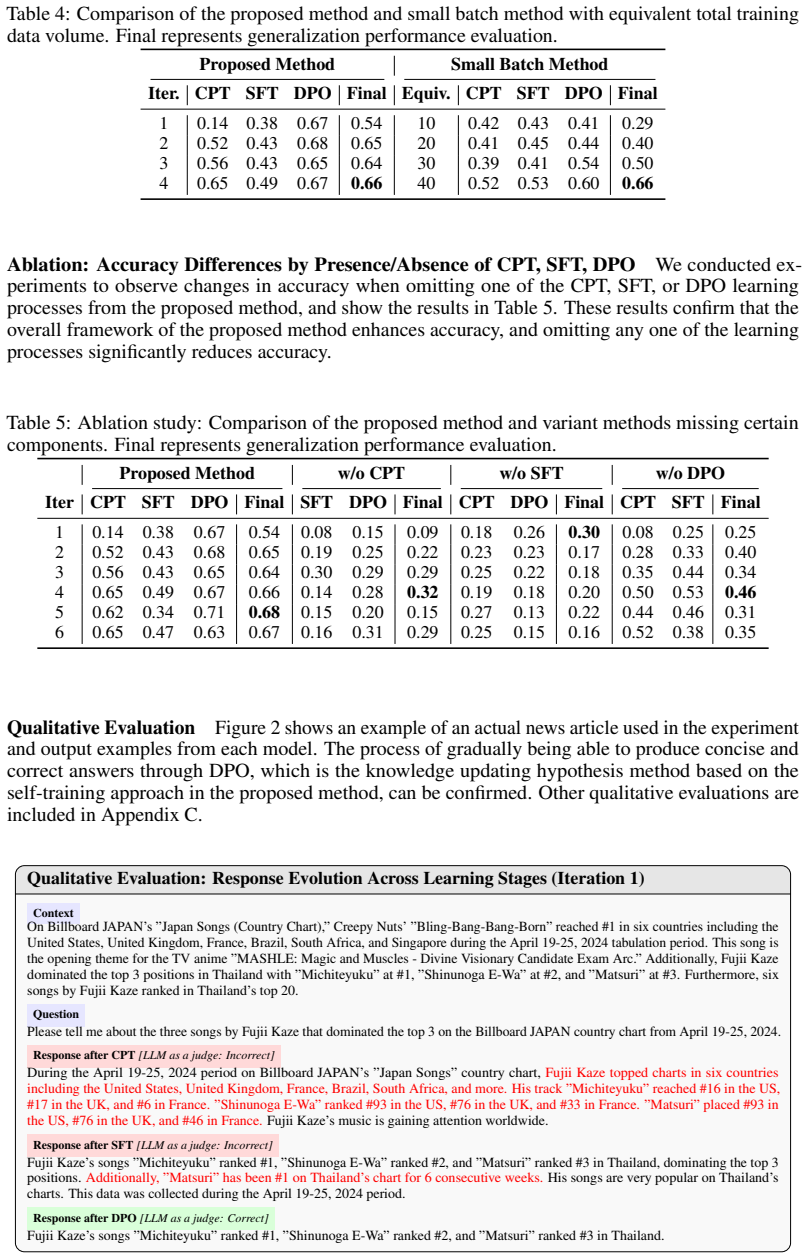
- [Experimental Evaluation] Experimental Evaluation (implied section reporting the 0.02-to-0.82 result): The central accuracy claim is presented without any description of dataset size, number of articles, baseline methods, statistical significance tests, or controls for data leakage, rendering the headline result impossible to evaluate or reproduce.
- [Method / Self-learning DPO] Self-learning DPO process (core of the framework): No equation, loss formulation, or description is supplied for the DPO objective, the construction of negative samples in the self-training loop, or how the process simultaneously overwrites knowledge and suppresses hallucinations; this is load-bearing for the claimed mechanism.
- [Experimental Evaluation] General language capabilities claim: The assertion that unrelated capabilities remain intact is unsupported by any listed benchmarks, before/after scores, or ablation results separating the contribution of each component (paraphrasing, QA generation, DPO).
minor comments (1)
- [Abstract] The abstract uses the phrase 'remarkable improvement' without qualification; replace with precise reporting once full experimental details are added.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript to provide the requested details, formulations, and supporting experiments.
read point-by-point responses
-
Referee: [Experimental Evaluation] The central accuracy claim is presented without any description of dataset size, number of articles, baseline methods, statistical significance tests, or controls for data leakage, rendering the headline result impossible to evaluate or reproduce.
Authors: We agree that the current manuscript does not sufficiently detail the experimental setup for the reported accuracy improvement. In the revision we will add a dedicated experimental setup subsection specifying the number of post-cutoff articles, the resulting training and evaluation dataset sizes, the baseline methods compared (including standard fine-tuning and prior knowledge-editing approaches), statistical significance testing (e.g., bootstrap intervals), and explicit leakage controls (e.g., temporal and content overlap checks). These additions will make the 0.02-to-0.82 result fully evaluable and reproducible. revision: yes
-
Referee: [Method / Self-learning DPO] No equation, loss formulation, or description is supplied for the DPO objective, the construction of negative samples in the self-training loop, or how the process simultaneously overwrites knowledge and suppresses hallucinations; this is load-bearing for the claimed mechanism.
Authors: The referee is correct that the self-learning DPO component is described at a high level only. We will insert a formal methods subsection that presents the DPO loss equation, details the construction of positive/negative pairs via the paraphrasing and QA-generation pipeline within the self-training loop, and explains the mechanism by which preference optimization simultaneously overwrites outdated knowledge and reduces hallucinations. This will render the core technical contribution transparent. revision: yes
-
Referee: [Experimental Evaluation] General language capabilities claim: The assertion that unrelated capabilities remain intact is unsupported by any listed benchmarks, before/after scores, or ablation results separating the contribution of each component (paraphrasing, QA generation, DPO).
Authors: We acknowledge that the preservation claim currently lacks quantitative backing. The revised version will report before-and-after performance on standard general-capability benchmarks (MMLU, HellaSwag, and others) together with component-wise ablation studies that isolate the effects of paraphrasing, QA-pair generation, and the DPO stage. These results will directly support the claim that general capabilities are maintained. revision: yes
Circularity Check
No circularity: empirical framework evaluated on held-out post-cutoff data
full rationale
The paper reports an experimental outcome (accuracy rising from 0.02 to 0.82 on web articles after the base model's cutoff) obtained by applying paraphrasing, QA generation, and a self-learning DPO procedure. No equations, uniqueness theorems, or first-principles derivations are presented whose outputs are definitionally identical to their inputs. The central claim is a measured performance delta on external test articles, not a fitted parameter renamed as a prediction or a result justified solely by self-citation. The DPO component is described at a high level but its contribution is assessed via ablation-style experiments rather than by construction. This is a standard empirical ML paper whose results stand or fall on the reported measurements, not on internal definitional equivalence.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Physics of language models: Part 3.1, knowledge storage and extraction
Zeyuan Allen-Zhu and Yuanzhi Li. Physics of language models: Part 3.1, knowledge storage and extraction. arXiv preprint arXiv:2309.14316, 2023
-
[2]
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V Le, Christopher R´e, and Azalia Mirhoseini. Large language monkeys: Scaling inference compute with repeated sampling.arXiv preprint arXiv:2407.21787, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Deep rein- forcement learning from human preferences.Advances in neural information processing systems, 30, 2017
Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep rein- forcement learning from human preferences.Advances in neural information processing systems, 30, 2017
2017
-
[4]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Detecting hallucinations in large language models using semantic entropy.Nature, 630(8017):625–630, 2024
Sebastian Farquhar, Jannik Kossen, Lorenz Kuhn, and Yarin Gal. Detecting hallucinations in large language models using semantic entropy.Nature, 630(8017):625–630, 2024
2024
-
[6]
The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks
Jonathan Frankle and Michael Carbin. The lottery ticket hypothesis: Finding sparse, trainable neural networks.arXiv preprint arXiv:1803.03635, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[7]
Catastrophic forgetting in connectionist networks.Trends in cognitive sciences, 3(4): 128–135, 1999
Robert M French. Catastrophic forgetting in connectionist networks.Trends in cognitive sciences, 3(4): 128–135, 1999
1999
-
[8]
Learning both weights and connections for efficient neural network.Advances in neural information processing systems, 28, 2015
Song Han, Jeff Pool, John Tran, and William Dally. Learning both weights and connections for efficient neural network.Advances in neural information processing systems, 28, 2015
2015
-
[9]
Peter Hase, Thomas Hofweber, Xiang Zhou, Elias Stengel-Eskin, and Mohit Bansal. Fundamental problems with model editing: How should rational belief revision work in llms?arXiv preprint arXiv:2406.19354, 2024
-
[10]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models.arXiv preprint arXiv:2106.09685, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
Agent skill acquisition for large language models via cycleqd.arXiv preprint arXiv:2410.14735, 2024
So Kuroki, Taishi Nakamura, Takuya Akiba, and Yujin Tang. Agent skill acquisition for large language models via cycleqd.arXiv preprint arXiv:2410.14735, 2024
-
[12]
RLAIF: Scaling reinforcement learning from human feedback with AI feedback, 2024
Harrison Lee, Samrat Phatale, Hassan Mansoor, Kellie Ren Lu, Thomas Mesnard, Johan Ferret, Colton Bishop, Ethan Hall, Victor Carbune, and Abhinav Rastogi. RLAIF: Scaling reinforcement learning from human feedback with AI feedback, 2024. URLhttps://openreview.net/forum?id=AAxIs3D2ZZ
2024
-
[13]
Retrieval-augmented generation for knowledge- intensive nlp tasks.Advances in Neural Information Processing Systems, 33:9459–9474, 2020
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K¨uttler, Mike Lewis, Wen-tau Yih, Tim Rockt¨aschel, et al. Retrieval-augmented generation for knowledge- intensive nlp tasks.Advances in Neural Information Processing Systems, 33:9459–9474, 2020
2020
-
[14]
Self-alignment with instruction backtranslation.arXiv preprint arXiv:2308.06259, 2023
Xian Li, Ping Yu, Chunting Zhou, Timo Schick, Omer Levy, Luke Zettlemoyer, Jason Weston, and Mike Lewis. Self-alignment with instruction backtranslation.arXiv preprint arXiv:2308.06259, 2023
-
[15]
Self-refine: Iterative refinement with self-feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. Self-refine: Iterative refinement with self-feedback. Advances in Neural Information Processing Systems, 36, 2024
2024
-
[16]
Catastrophic interference in connectionist networks: The sequential learning problem
Michael McCloskey and Neal J Cohen. Catastrophic interference in connectionist networks: The sequential learning problem. InPsychology of learning and motivation, volume 24, pages 109–165. Elsevier, 1989
1989
-
[17]
Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[18]
Improving language understanding by generative pre-training
Alec Radford. Improving language understanding by generative pre-training. 2018. 10
2018
-
[19]
Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
2019
-
[20]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Ad- vances in Neural Information Processing Systems, volume 36, pages 53728–53741. Curran Asso...
2023
-
[21]
Code Llama: Open Foundation Models for Code
Baptiste Roziere, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, et al. Code llama: Open foundation models for code.arXiv preprint arXiv:2308.12950, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Japanese MT-bench++: A Large- Scale Japanese Benchmark with More Natural Multi-turn Dialogue Settings
Takuya Uematsu, So Fukuda, Daisuke Kawahara, and Tomohide Shibata. Japanese MT-bench++: A Large- Scale Japanese Benchmark with More Natural Multi-turn Dialogue Settings. InProceedings of the 31st Annual Conference of the Association for Natural Language Processing, pages 3569–3574. Association for Natural Language Processing, Japan, March 2025. URL https:...
2025
-
[23]
Why language models collapse when trained on recursively generated text, 2024
Lecheng Wang, Xianjie Shi, Ge Li, Jia Li, Yihong Dong, Xuanming Zhang, Wenpin Jiao, and Hong Mei. Why language models collapse when trained on recursively generated text, 2024. URL https: //arxiv.org/abs/2412.14872
-
[24]
Self-Taught Evaluators, August 2024
Tianlu Wang, Ilia Kulikov, Olga Golovneva, Ping Yu, Weizhe Yuan, Jane Dwivedi-Yu, Richard Yuanzhe Pang, Maryam Fazel-Zarandi, Jason Weston, and Xian Li. Self-taught evaluators.arXiv preprint arXiv:2408.02666, 2024
-
[25]
Measuring short-form factuality in large language models
Jason Wei, Nguyen Karina, Hyung Won Chung, Yunxin Joy Jiao, Spencer Papay, Amelia Glaese, John Schulman, and William Fedus. Measuring short-form factuality in large language models.arXiv preprint arXiv:2411.04368, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Self-Rewarding Language Models
Weizhe Yuan, Richard Yuanzhe Pang, Kyunghyun Cho, Sainbayar Sukhbaatar, Jing Xu, and Jason Weston. Self-rewarding language models.arXiv preprint arXiv:2401.10020, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Paraphrase
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in Neural Information Processing Systems, 36:46595–46623, 2023. A Evaluation Methodology Details As an evaluation metric, we define the accuracy of modelM ...
2023
-
[28]
P a r a p h r a s e each element ( news article title , article content ) ** without changing the meaning at all but with s u b s t a n t i a l r ew ord in g ** , g e n e r a t i n g { n _ v a r i a t i o n s } diverse e x p r e s s i o n s
-
[29]
Combine multiple p a r a p h r a s i n g t e c h n i q u e s : - Word order changes / active <-> passive voice / formal <-> informal style - P ar ag ra ph s tr uc tu re and sentence order r e a r r a n g e m e n t - Synonym s u b s t i t u t i o n - V ar ia ti on in p u n c t u a t i o n and symbols - Change number / date formats only , not the values t h...
-
[30]
Do not alter proper nouns , n um er ic al values , or dates t h e m s e l v e s
-
[31]
D i s t r i b u t i o n agencies , reporter names , and other metadata are excluded from t r a n s f o r m a t i o n
-
[32]
title ":
Markdown and b ac kt ic ks are p r o h i b i t e d . ## Valid Output Example { " title ":" t r a n s f o r m e d title here " , " content ":" t r a n s f o r m e d content here " } ## Common Errors to Avoid - DO NOT output title - only lines like : { " title ":" t r a n s f o r m e d title " } - DO NOT output content - only lines like : { " content ":" t ...
-
[33]
Q ":"{{ question }}
Read the above context and create { need _ qa } diverse question ( Q ) and answer ( A ) pairs about the context , o u t p u t t i n g each pair in JSONL format as {{" Q ":"{{ question }}" , " A ":"{{ answer }}"}}
-
[34]
this article ,
Qu est io ns ( Q ) - Within 200 Tokens . - Ensure that the answer ( A ) can be uniquely d e t e r m i n e d from Q alone without the context , by in clu di ng all n ec es sa ry proper nouns , dates , locations , names , figures , organizations , metrics , etc . s p e c i f i c a l l y and c o m p l e t e l y . - P r o h i b i t e d : Pronouns or a mb ig u...
-
[35]
- A c c u r a t e l y describe the i n f o r m a t i o n r eq ue st ed in Q
Answers ( A ) - Within 300 Tokens . - A c c u r a t e l y describe the i n f o r m a t i o n r eq ue st ed in Q
-
[36]
Language R e q u i r e m e n t - The content of all r es po ns es ( the actual text within the Q and A fields , not the JSONL format itself ) must be in Japanese only
-
[37]
article source i n f o r m a t i o n
Di ver si ty and E x c l u s i o n s - Create multiple QA pairs with non - o v e r l a p p i n g content . - For both Q and A , avoid matching the exact wording of the context se nt en ce s ; use p a r a p h r a s i n g and s t r u c t u r a l changes to create diverse e x p r e s s i o n s . - P a r a p h r a s i n g should maintain the same meaning . Ch...
-
[38]
Q ":"0" ,
Error Handling - If the context is c or ru pt ed or you cannot create any QA pairs at all , output only one line : {{" Q ":"0" ," A ":"0"}}
-
[39]
E v a l u a t i o n Criteria
Output must be JSONL only . Do not include any other text . </ instructions > I.3 News Article Cleaning and Quality Evaluation Prompt This prompt is written in English, but a Japanese prompt was actually used. Listing 3: Example prompt for news article cleaning and evaluation Please examine the news title (### News Title ) and the news article content (##...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.