VietFashion: Benchmarking Sketch-Text Composed Image Retrieval for Cultural Outfits
Pith reviewed 2026-06-27 07:11 UTC · model grok-4.3
The pith
A new benchmark for sketch-and-text outfit retrieval exposes large gaps in how models handle fine-grained cultural details.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
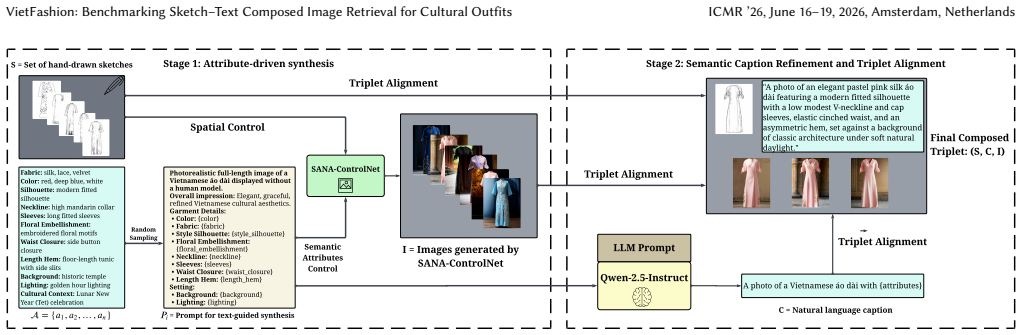
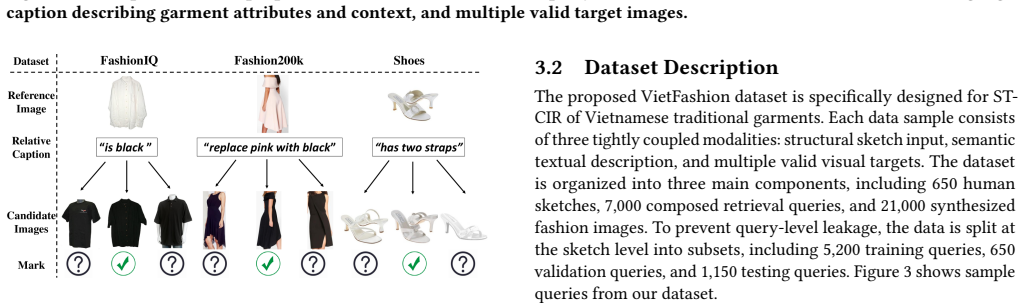
VietFashion establishes a benchmark for sketch-text composed image retrieval on traditional Vietnamese garments. The dataset supplies 650 hand-drawn sketches, over 21,000 generated photorealistic images with aligned captions extracted from fashion magazines, and a multi-target retrieval protocol that reflects design ambiguity. When state-of-the-art composed retrieval methods are evaluated under standardized protocols, they exhibit significant performance gaps in modeling fine-grained cultural semantics and multi-modal composition.
What carries the argument
The VietFashion dataset together with its multi-target retrieval protocol that accepts combined sketch and text queries.
If this is right
- Current composed image retrieval techniques cannot reliably combine structural cues from sketches with semantic cues from text when the target garments carry cultural meaning.
- Multi-target evaluation is required to measure performance fairly in design-oriented retrieval tasks.
- Standardized protocols on this dataset can track progress on fine-grained cultural semantics.
- The benchmark highlights the need for methods that handle ambiguity in matching design intent.
Where Pith is reading between the lines
- Design tools for traditional garments could improve if retrieval systems close the observed gaps.
- Parallel benchmarks for other regional garment traditions would test whether the same composition difficulties appear elsewhere.
- The multi-target protocol may apply to other retrieval settings where one query legitimately matches several outputs.
Load-bearing premise
The generated images and magazine-derived text prompts preserve the original cultural structural and symbolic details without introducing artifacts or selection biases.
What would settle it
A controlled human study that rates whether the generated images and captions retain the same cultural identity cues as the original sketches and magazine sources, or a retrieval model that reaches high accuracy on the benchmark without additional training data.
Figures


read the original abstract
Cultural garments pose a unique challenge for visual retrieval systems, as their identity often depends on subtle structural and symbolic details that are poorly captured by standard AI models. We introduce VietFashion, a new benchmark for sketch-text composed image retrieval centered on the Ao Dai, a traditional Vietnamese garment. VietFashion enables designers and researchers to retrieve culturally meaningful outfits using a combination of hand-drawn sketches, which convey garment structure, and textual descriptions, which encode cultural semantics. The dataset is initialized with 650 sketches and expanded using generative models to produce over 21,000 photorealistic images with aligned captions. Textual prompts that describe detailed outfit attributes, which are extracted from fashion magazines to ensure authenticity and diversity. To better reflect the inherent ambiguity of design intent, VietFashion adopts a multi-target retrieval setting, where a single query may correspond to multiple valid results. We establish standardized evaluation protocols and benchmark state-of-the-art composed image retrieval methods. Experimental results reveal significant performance gaps in modeling fine-grained cultural semantics and multi-modal composition, positioning VietFashion as a challenging benchmark for fine-grained fashion retrieval. The dataset is publicly available at: https://hng0303.github.io/VietFashion.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VietFashion, a benchmark for sketch-text composed image retrieval centered on the Vietnamese Ao Dai garment. Starting from 650 hand-drawn sketches, it expands the dataset to over 21,000 photorealistic images using generative models, paired with captions extracted from fashion magazines. It adopts a multi-target retrieval setting to reflect design ambiguity, establishes evaluation protocols, benchmarks state-of-the-art composed image retrieval methods, and claims that experiments reveal significant performance gaps in modeling fine-grained cultural semantics and multi-modal composition.
Significance. If the generated images and captions faithfully preserve subtle structural and symbolic cultural details of the Ao Dai without artifacts or selection biases, the benchmark could usefully expose limitations in current SOTA methods for cultural fashion retrieval and motivate improved fine-grained multi-modal composition techniques.
major comments (3)
- [Dataset expansion] Dataset expansion (abstract and § on dataset construction): the central claim that performance gaps reflect challenges in cultural semantics and multi-modal composition depends on the 21k generated images being reliable ground truth; the manuscript provides no human evaluation by cultural experts, no artifact analysis, and no quantitative fidelity metrics to rule out generative distortions (e.g., inaccurate motifs or texture artifacts) that could artificially create or inflate the observed gaps.
- [Experiments] Experiments section: the abstract asserts that 'experimental results reveal significant performance gaps' yet reports no specific metrics, tables, baseline scores, or error analysis; without these, the claim that VietFashion is a 'challenging benchmark' cannot be assessed and the multi-target setting's validity remains unverified.
- [Evaluation protocol] Multi-target retrieval protocol: the motivation for multiple valid targets per query is reasonable, but the manuscript does not specify how targets are selected or validated to avoid selection bias, which is load-bearing for interpreting retrieval difficulty in the cultural context.
minor comments (2)
- [Abstract] The public dataset link is given, but the manuscript should detail the exact generative models, prompt templates, and caption extraction process to support reproducibility.
- [Problem definition] Notation for the composed query (sketch + text) could be formalized more clearly in the problem definition section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on VietFashion. We address each major comment below and will revise the manuscript accordingly to strengthen the claims about the benchmark's reliability and evaluation.
read point-by-point responses
-
Referee: [Dataset expansion] Dataset expansion (abstract and § on dataset construction): the central claim that performance gaps reflect challenges in cultural semantics and multi-modal composition depends on the 21k generated images being reliable ground truth; the manuscript provides no human evaluation by cultural experts, no artifact analysis, and no quantitative fidelity metrics to rule out generative distortions (e.g., inaccurate motifs or texture artifacts) that could artificially create or inflate the observed gaps.
Authors: We agree that explicit validation of the generated images is necessary to support the central claims. In the revised version, we will add a human evaluation subsection involving Vietnamese cultural and fashion experts to rate fidelity of structural and symbolic details, along with quantitative metrics such as perceptual similarity scores and artifact frequency analysis. This will be incorporated into the dataset construction section. revision: yes
-
Referee: [Experiments] Experiments section: the abstract asserts that 'experimental results reveal significant performance gaps' yet reports no specific metrics, tables, baseline scores, or error analysis; without these, the claim that VietFashion is a 'challenging benchmark' cannot be assessed and the multi-target setting's validity remains unverified.
Authors: The experiments section contains tables reporting Recall@K and mAP scores for multiple SOTA composed retrieval methods on VietFashion, with comparisons to other benchmarks, plus qualitative error examples. However, we acknowledge the abstract lacks these specifics. We will revise the abstract to include key quantitative results (e.g., best method mAP of approximately 18% on VietFashion) and expand the error analysis to better verify the multi-target protocol. revision: partial
-
Referee: [Evaluation protocol] Multi-target retrieval protocol: the motivation for multiple valid targets per query is reasonable, but the manuscript does not specify how targets are selected or validated to avoid selection bias, which is load-bearing for interpreting retrieval difficulty in the cultural context.
Authors: We will expand the evaluation protocol section to detail the target selection: multiple targets per query are chosen by structural match to the sketch (via keypoint alignment) and semantic match to the text caption (via attribute overlap from magazine sources). We will also describe a validation step using independent caption review to reduce bias, making the process transparent. revision: yes
Circularity Check
No circularity: dataset benchmark with no derivations or self-referential reductions
full rationale
The paper introduces VietFashion as a new benchmark dataset for sketch-text composed image retrieval, expanded via generative models from 650 sketches to 21k images with magazine-derived captions, and evaluates existing SOTA methods under a multi-target protocol. No equations, fitted parameters, predictions, or derivation chains are present in the provided text. The central claims rest on empirical performance gaps observed on this external benchmark rather than any quantity that reduces to its own inputs by construction. This is a standard dataset paper with independent content against external benchmarks, warranting score 0.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Private Tour Asia. [n. d.]. Everything You Need to Know About Ao Dai: Viet- nam’s Traditional Costume. https://privatetourasia.com/everything-you-need- to-know-about-ao-dai-vietnams-traditional-costume. Accessed: 2026-02-13
2026
-
[2]
Alberto Baldrati, Lorenzo Agnolucci, Marco Bertini, and Alberto Del Bimbo. 2023. Zero-shot composed image retrieval with textual inversion. InProceedings of the IEEE/CVF international conference on computer vision. 15338–15347
2023
-
[3]
Alberto Baldrati, Marco Bertini, Tiberio Uricchio, and Alberto Del Bimbo. 2023. Composed image retrieval using contrastive learning and task-oriented clip- based features.ACM Transactions on Multimedia Computing, Communications and Applications20, 3 (2023), 1–24
2023
-
[4]
Sounak Dey, Pau Riba, Anjan Dutta, Josep Llados Llados, and Yi-Zhe Song. 2019. Doodle to Search: Practical Zero-Shot Sketch-Based Image Retrieval. In2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2174–2183. doi:10.1109/cvpr.2019.00228
-
[5]
Mathias Eitz, James Hays, and Marc Alexa. 2012. How do humans sketch objects? ACM Trans. Graph.31, 4, Article 44 (July 2012), 10 pages. doi:10.1145/2185520. 2185540
-
[6]
François Gardères, Shizhe Chen, Camille-Sovanneary Gauthier, and Jean Ponce
-
[7]
FACap: A Large-scale Fashion Dataset for Fine-grained Composed Image Retrieval.arXiv preprint arXiv:2507.07135(2025)
arXiv 2025
-
[8]
Prajwal Gatti, Kshitij Parikh, Dhriti Prasanna Paul, Manish Gupta, and Anand Mishra. 2024. Composite sketch+ text queries for retrieving objects with elu- sive names and complex interactions. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 1869–1877
2024
-
[9]
Venkata Rama Muni Kumar Gopu and Madhavi Dunna. 2024. Zero-Shot Sketch- Based Image Retrieval Using StyleGen and Stacked Siamese Neural Networks. Journal of Imaging10, 4 (2024). doi:10.3390/jimaging10040079
-
[10]
Hoang-Bao Le, Allie Tran, Binh T Nguyen, Liting Zhou, and Cathal Gurrin
-
[11]
InInternational Conference on Multimedia Modeling
FIGROTD: A Friendly-to-Handle Dataset for Image Guided Retrieval with Optional Text. InInternational Conference on Multimedia Modeling. Springer, 117–132
-
[12]
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. 2022. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. InInternational conference on machine learning. PMLR, 12888–12900
2022
-
[13]
Fengyin Lin, Mingkang Li, Da Li, Timothy Hospedales, Yi-Zhe Song, and Yong- gang Qi. 2023. Zero-shot everything sketch-based image retrieval, and in ex- plainable style. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 23349–23358
2023
-
[14]
Li Liu, Fumin Shen, Yuming Shen, Xianglong Liu, and Ling Shao. 2017. Deep sketch hashing: Fast free-hand sketch-based image retrieval. InProceedings of the IEEE conference on computer vision and pattern recognition. 2862–2871
2017
-
[15]
Zheyuan Liu, Cristian Rodriguez-Opazo, Damien Teney, and Stephen Gould
-
[16]
InProceedings of the IEEE/CVF international conference on computer vision
Image retrieval on real-life images with pre-trained vision-and-language models. InProceedings of the IEEE/CVF international conference on computer vision. 2125–2134
-
[17]
Francesc Net and Lluis Gomez. 2024. EUFCC-CIR: A Composed Image Re- trieval Dataset for GLAM Collections. InEuropean Conference on Computer Vision. Springer, 196–211
2024
-
[18]
Seongyeon Oh, Soyoung Lee, Hyeon Seong Jeong, Sangwoo Jo, Jin Young Kim, Yeonseo Choi, YoungJoon Yoo, and Taehoon Kim. 2025. WCCA-AK: A Multimodal Dataset of Andre Kim’s Fashion Legacy for AI-Driven Cultural Heritage Research. InProceedings of the IEEE/CVF International Conference on Computer Vision. 4495– 4500
2025
-
[19]
Saavedra, Christopher Stears, and Waldo Campos
Jose M. Saavedra, Christopher Stears, and Waldo Campos. 2025. Achieving high performance on sketch-based image retrieval without real sketches for training. Pattern Recogn. Lett.193, C (July 2025), 94–100. doi:10.1016/j.patrec.2025.04.018
-
[20]
Aneeshan Sain, Ayan Kumar Bhunia, Pinaki Nath Chowdhury, Subhadeep Koley, Tao Xiang, and Yi-Zhe Song. 2023. Clip for all things zero-shot sketch-based image retrieval, fine-grained or not. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2765–2775
2023
-
[21]
Kuniaki Saito, Kihyuk Sohn, Xiang Zhang, Chun-Liang Li, Chen-Yu Lee, Kate Saenko, and Tomas Pfister. 2023. Pic2word: Mapping pictures to words for zero- shot composed image retrieval. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 19305–19314
2023
-
[22]
Patsorn Sangkloy, Nathan Burnell, Cusuh Ham, and James Hays. 2016. The sketchy database: learning to retrieve badly drawn bunnies.ACM Trans. Graph. 35, 4, Article 119 (July 2016), 12 pages. doi:10.1145/2897824.2925954
-
[23]
Patsorn Sangkloy, Wittawat Jitkrittum, Diyi Yang, and James Hays. 2022. A Sketch Is Worth a Thousand Words: Image Retrieval with Text and Sketch. In Computer Vision – ECCV 2022: 17th European Conference, Tel A viv, Israel, October 23–27, 2022, Proceedings, Part XXXVIII(Tel Aviv, Israel). Springer-Verlag, Berlin, Heidelberg, 251–267. doi:10.1007/978-3-031-...
-
[24]
Likai Tian, Zhengwei Yang, Zechao Hu, Hao Li, Yifang Yin, and Zheng Wang. 2024. Expressiveness is Effectiveness: Self-supervised Fashion-aware CLIP for Video-to- Shop Retrieval. InProceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, IJCAI-24, Kate Larson (Ed.). International Joint Conferences on Artificial Intelligenc...
-
[25]
Nguyen, Trong- Le Do, Duy-Nam Ly, Viet-Tham Huynh, Khanh-Duy Le, Mai-Khiem Tran, and Trung-Nghia Le
Thien-Phuc Tran, Minh-Quang Nguyen, Minh-Triet Tran, Tam V. Nguyen, Trong- Le Do, Duy-Nam Ly, Viet-Tham Huynh, Khanh-Duy Le, Mai-Khiem Tran, and Trung-Nghia Le. 2025. Event-Enriched Image Analysis Grand Challenge At ACM Multimedia 2025. InProceedings of the 33rd ACM International Conference on Multimedia (MM ’25). ACM, 14244–14249. doi:10.1145/3746027.3762067
-
[26]
Viet Dream Travel. [n. d.]. Ao Dai - The Soul of Vietnamese Culture. https: //vietdreamtravel.vn/ao-dai/. Accessed: 2026-02-13
2026
-
[27]
Hanoi Voyage. [n. d.]. Ao Dai Vietnam: The Traditional Costume. https:// hanoivoyage.com/en/blog/ao-dai-vietnam-traditional-costume.html. Accessed: 2026-02-13
2026
-
[28]
Hui Wu, Yupeng Gao, Xiaoxiao Guo, Ziad Al-Halah, Steven Rennie, Kristen Grauman, and Rogerio Feris. 2021. Fashion iq: A new dataset towards retrieving images by natural language feedback. InProceedings of the IEEE/CVF Conference on computer vision and pattern recognition. 11307–11317
2021
-
[29]
Enze Xie, Junsong Chen, Junyu Chen, Han Cai, Haotian Tang, Yujun Lin, Zhekai Zhang, Muyang Li, Ligeng Zhu, Yao Lu, et al . 2024. Sana: Efficient high- resolution image synthesis with linear diffusion transformers.arXiv preprint arXiv:2410.10629(2024)
Pith/arXiv arXiv 2024
-
[30]
Xinxun Xu, Hao Wang, Leida Li, and Cheng Deng. 2019. Semantic adversarial net- work for zero-shot sketch-based image retrieval.arXiv preprint arXiv:1905.02327 (2019)
arXiv 2019
-
[31]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
Pith/arXiv arXiv 2025
-
[32]
Nan Yang and Xiaoquan Ma. 2025. Enhanced composed fashion image retrieval with a multi-hop reasoning framework.Scientific Reports15, 1 (09 2025), 32217. doi:10.1038/s41598-025-17402-6
-
[33]
Xu Zhang, Zhedong Zheng, Linchao Zhu, and Yi Yang. 2024. Collaborative group: Composed image retrieval via consensus learning from noisy annotations. Knowledge-Based Systems300 (Sept. 2024), 112135. doi:10.1016/j.knosys.2024. 112135
-
[34]
Li Zhou, Lutong Yu, Dongchu Xie, Shaohuan Cheng, Wenyan Li, and Haizhou Li
-
[35]
InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
Hanfu-Bench: A Multimodal Benchmark on Cross-Temporal Cultural Un- derstanding and Transcreation. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 24627–24649
2025
-
[36]
Shuang Zhou and Nonlabile Binti Salleh Hudin. 2025. Enhancing fashion e- commerce retrieval: A self-supervised graph-integrated framework for cross- modal image–text alignment.Alexandria Engineering Journal128 (2025), 1015–
2025
-
[37]
doi:10.1016/j.aej.2025.07.039
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.