Wavelet-Guided Semantic Signal Compensation for Inversion-Free Image Editing
Pith reviewed 2026-07-03 15:06 UTC · model grok-4.3
The pith
A wavelet-guided compensation strategy strengthens early semantic signals to enable stronger global edits in inversion-free text-guided image editing while preserving background fidelity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
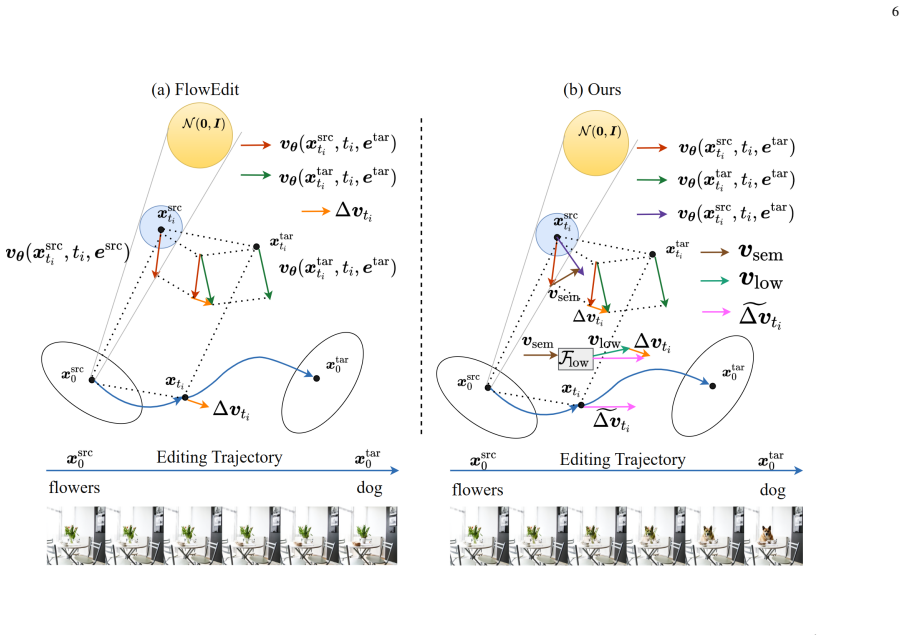
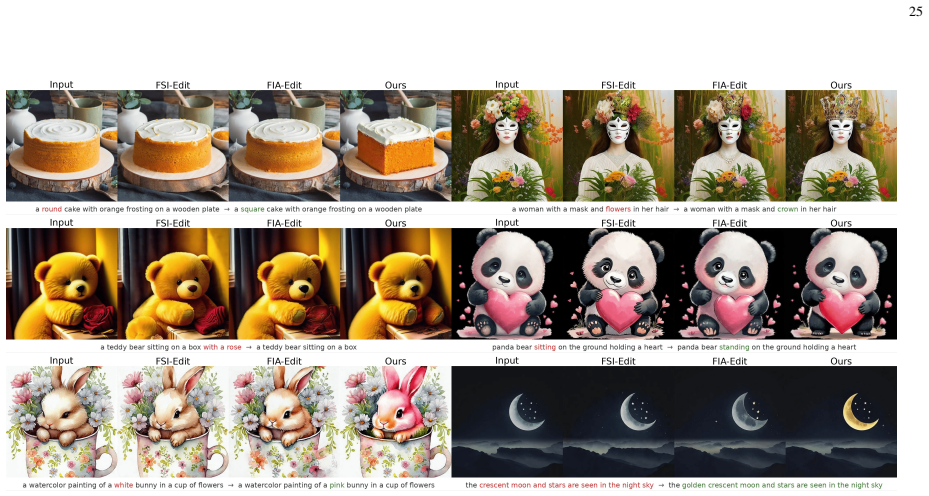
The paper proposes an inversion-free frequency-aware semantic compensation strategy that strengthens the effective signal in the early stage of generation by leveraging wavelet decomposition, leading to improved global editing capacity without sacrificing background fidelity in text-guided image editing.
What carries the argument
Wavelet-guided semantic signal compensation, a frequency-aware mechanism that selectively enhances text-conditioned directions in early timesteps while maintaining structural consistency.
If this is right
- Global attribute shifts become feasible in inversion-free pipelines without extra inversion steps.
- Background fidelity remains comparable to or exceeds that of prior inversion-free methods.
- The compensation integrates into flow-based editing frameworks such as FlowEdit.
- Editing trajectories can deviate farther from the source distribution in early timesteps.
Where Pith is reading between the lines
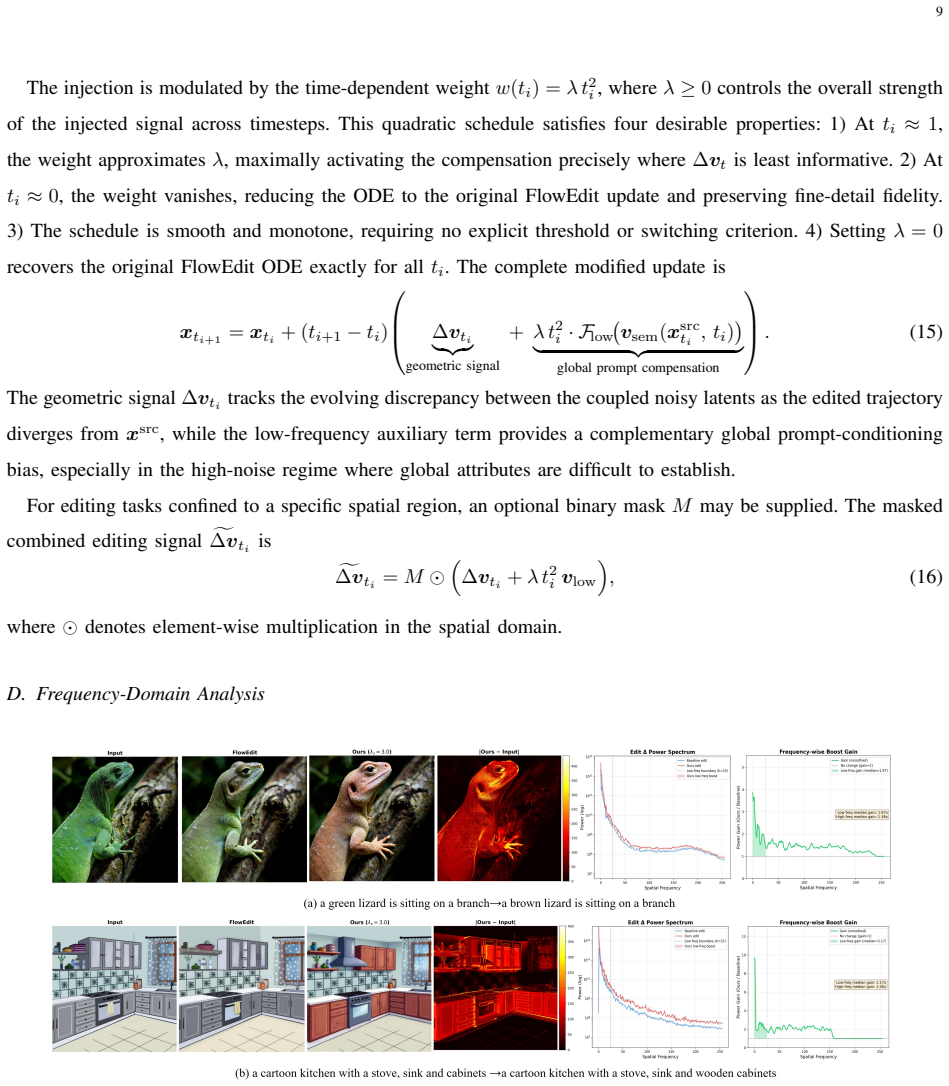
- Similar frequency compensation could be tested in video or 3D diffusion editing to handle temporal or volumetric consistency.
- The observation about manifold dominance may apply to other guidance-based generative tasks beyond images.
- Wavelet decomposition might offer a general tool for balancing guidance strength and fidelity in diffusion sampling.
Load-bearing premise
In the high-noise regime the manifold-seeking flow overpowers the text-conditioned direction and thereby limits global modification.
What would settle it
An ablation experiment showing that removing the wavelet compensation restores the limited global edit performance of the baseline while background preservation stays unchanged.
Figures











read the original abstract
Text-guided image editing aims to modify visual content according to a target prompt while preserving the background. Recent inversion-free image editing frameworks such as FlowEdit have demonstrated strong editing capability without requiring inversion. Empirically, FlowEdit can achieve substantial semantic changes under appropriate hyperparameter settings. However, we observe that under certain global attribute shifts, the editing trajectory may not effectively move away from the source distribution in the early timesteps. Our analysis suggests that in the high-noise regime, the dominant manifold-seeking flow toward the data manifold can reduce the influence of the text-conditioned direction, leading to limited global modification while background structures remain only moderately preserved. Inspired by this observation, we propose an inversion-free, frequency-aware semantic compensation strategy that strengthens the effective signal in the early stage of generation, while maintaining structural consistency in the background. The proposed method improves global editing capacity without sacrificing background fidelity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that inversion-free editing methods such as FlowEdit exhibit limited global semantic modification under certain attribute shifts because, in the high-noise regime, the manifold-seeking component of the flow dominates and attenuates the text-conditioned editing direction. Building on this empirical observation, the authors introduce a wavelet-guided semantic signal compensation strategy that augments the effective editing signal during early timesteps while preserving background structural consistency, asserting that the approach increases global editing capacity without degrading background fidelity.
Significance. If the frequency-aware compensation mechanism is shown to produce measurable gains in global edit strength across multiple prompts and datasets while maintaining comparable background metrics, the work would provide a practical, analysis-driven enhancement to inversion-free diffusion editing pipelines. The explicit linkage between high-noise flow dynamics and frequency-domain compensation offers a targeted remedy that could be adopted in other flow-based or score-based editing frameworks.
minor comments (2)
- [Abstract] Abstract: the description of the proposed strategy would benefit from a brief indication of the specific wavelet transform (e.g., Haar, Daubechies) and the precise frequency bands targeted for compensation.
- [Method] The manuscript should include a short ablation isolating the contribution of the wavelet-based compensation versus a simple amplitude scaling baseline to confirm that the frequency decomposition is load-bearing for the reported improvement.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our work and the recommendation for minor revision. The referee's description accurately captures our analysis of high-noise flow dynamics in inversion-free editing and the proposed wavelet-guided compensation strategy. No major comments were provided in the report.
Circularity Check
No significant circularity; derivation is observation-driven
full rationale
The provided abstract and description articulate an empirical observation on high-noise manifold-seeking behavior in inversion-free flows (e.g., FlowEdit), followed by a frequency-aware compensation proposal. No equations, fitted parameters, self-citations as load-bearing premises, or renamings appear in the text. The chain is observation → diagnosis → mitigation with independent content; no step reduces by construction to its inputs. This matches the default expectation of non-circular papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Score-based generative modeling through stochastic differential equations,
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole, “Score-based generative modeling through stochastic differential equations,”ICLR, 2021
2021
-
[2]
Denoising diffusion implicit models,
J. Song, C. Meng, and S. Ermon, “Denoising diffusion implicit models,” inICLR, 2021
2021
-
[3]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” inNeurIPS, 2020
2020
-
[4]
Flow matching for generative modeling,
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow matching for generative modeling,” inICLR, 2023
2023
-
[5]
Rectified Flow: A Marginal Preserving Approach to Optimal Transport
Q. Liu, “Rectified flow: A marginal preserving approach to optimal transport,”arXiv preprint arXiv:2209.14577, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
Effective real image editing with accelerated iterative diffusion inversion,
Z. Pan, R. Gherardi, X. Xie, and S. Huang, “Effective real image editing with accelerated iterative diffusion inversion,” inICCV, 2023
2023
-
[7]
ReNoise: Real image inversion through iterative noising,
D. Garibi, O. Patashnik, A. V oynov, H. Averbuch-Elor, and D. Cohen-Or, “ReNoise: Real image inversion through iterative noising,” in ECCV, 2024
2024
-
[8]
EDICT: Exact diffusion inversion via coupled transformations,
B. Wallace, A. Gokul, and N. Naik, “EDICT: Exact diffusion inversion via coupled transformations,” inCVPR, 2023
2023
-
[9]
Exact diffusion inversion via bidirectional integration approximation,
G. Zhang, J. P. Lewis, and W. B. Kleijn, “Exact diffusion inversion via bidirectional integration approximation,” inECCV, 2024
2024
-
[10]
ProxEdit: Improving tuning-free real image editing with proximal guidance,
L. Han, S. Wen, Q. Chen, Z. Zhang, K. Song, M. Ren, R. Gao, A. Stathopoulos, X. He, Y . Chenet al., “ProxEdit: Improving tuning-free real image editing with proximal guidance,” inWACV, 2024
2024
-
[11]
FlowEdit: Inversion-free text-based editing using pre-trained flow models,
V . Kulikov, M. Kleiner, I. Huberman-Spiegelglas, and T. Michaeli, “FlowEdit: Inversion-free text-based editing using pre-trained flow models,” inICCV, 2025
2025
-
[12]
TweezeEdit: Consistent and efficient image editing with path regularization,
J. Mao, K. Wang, Y . Xiang, and K. Chen, “TweezeEdit: Consistent and efficient image editing with path regularization,”arXiv preprint arXiv:2508.10498, 2025
-
[13]
Delta Rectified Flow Sampling for Text-to-Image Editing
G. Beaudouin, M. Li, J. Kim, S. Yoon, and M. Wang, “Delta velocity rectified flow for text-to-image editing,”arXiv preprint arXiv:2509.05342, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
FlowAlign: Trajectory-regularized, inversion-free flow-based image editing,
J. Kim, Y . Hong, J. Park, and J. C. Ye, “FlowAlign: Trajectory-regularized, inversion-free flow-based image editing,”arXiv preprint arXiv:2505.23145, 2025
-
[15]
On exact editing of flow-based diffusion models,
Z. Li, Y . Song, J. Peng, T. Liu, J. Huang, X. Qu, L. Liu, W. Wang, Y . Zhao, and Y . Wei, “On exact editing of flow-based diffusion models,” arXiv preprint arXiv:2512.24015, 2025
-
[16]
A theory for multiresolution signal decomposition: The wavelet representation,
S. G. Mallat, “A theory for multiresolution signal decomposition: The wavelet representation,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2002
2002
-
[17]
Prompt-to-Prompt image editing with cross attention control,
A. Hertz, R. Mokady, J. Tenenbaum, K. Aberman, Y . Pritch, and D. Cohen-Or, “Prompt-to-Prompt image editing with cross attention control,” inICLR, 2023
2023
-
[18]
DiffusionCLIP: Text-guided diffusion models for robust image manipulation,
G. Kim, T. Kwon, and J. C. Ye, “DiffusionCLIP: Text-guided diffusion models for robust image manipulation,” inCVPR, 2022
2022
-
[19]
Negative-prompt inversion: Fast image inversion for editing with text-guided diffusion models,
D. Miyake, A. Iohara, Y . Saito, and T. Tanaka, “Negative-prompt inversion: Fast image inversion for editing with text-guided diffusion models,” inWACV, 2025
2025
-
[20]
Null-text guidance in diffusion models is secretly a cartoon-style creator,
J. Zhao, H. Zheng, C. Wang, L. Lan, W. Huang, and W. Yang, “Null-text guidance in diffusion models is secretly a cartoon-style creator,” inACM MM, 2023
2023
-
[21]
On exact inversion of DPM-Solvers,
S. Hong, K. Lee, S. Y . Jeon, H. Bae, and S. Y . Chun, “On exact inversion of DPM-Solvers,” inCVPR, 2024
2024
-
[22]
LEDITS++: Limitless image editing using text-to-image models,
M. Brack, F. Friedrich, K. Kornmeier, L. Tsaban, P. Schramowski, K. Kersting, and A. Passos, “LEDITS++: Limitless image editing using text-to-image models,” inCVPR, 2024
2024
-
[23]
DiT4Edit: Diffusion transformer for image editing,
K. Feng, Y . Ma, B. Wang, C. Qi, H. Chen, Q. Chen, and Z. Wang, “DiT4Edit: Diffusion transformer for image editing,” inAAAI, 2025
2025
-
[24]
Plug-and-play diffusion features for text-driven image-to-image translation,
N. Tumanyan, M. Geyer, S. Bagon, and T. Dekel, “Plug-and-play diffusion features for text-driven image-to-image translation,” inCVPR, 2023
2023
-
[25]
MasaCtrl: Tuning-free mutual self-attention control for consistent image synthesis and editing,
M. Cao, X. Wang, Z. Qi, Y . Shan, X. Qie, and Y . Zheng, “MasaCtrl: Tuning-free mutual self-attention control for consistent image synthesis and editing,” inICCV, 2023
2023
-
[26]
Inversion-free image editing with language-guided diffusion models,
S. Xu, Y . Huang, J. Pan, Z. Ma, and J. Chai, “Inversion-free image editing with language-guided diffusion models,” inCVPR, 2024
2024
-
[27]
FreeDiff: Progressive frequency truncation for image editing with diffusion models,
W. Wu, Q. Fan, S. Qin, H. Gu, R. Zhao, and A. B. Chan, “FreeDiff: Progressive frequency truncation for image editing with diffusion models,” inECCV, 2024
2024
-
[28]
An algorithm for the machine calculation of complex fourier series,
J. W. Cooley and J. W. Tukey, “An algorithm for the machine calculation of complex fourier series,”Mathematics of Computation, 1965
1965
-
[29]
Taming rectified flow for inversion and editing,
J. Wang, J. Pu, Z. Qi, J. Guo, Y . Ma, N. Huang, Y . Chen, X. Li, and Y . Shan, “Taming rectified flow for inversion and editing,” inICML, 2025. July 3, 2026 DRAFT 40
2025
-
[30]
Semantic image inversion and editing using rectified stochastic differential equations,
L. Rout, Y . Chen, N. Ruiz, C. Caramanis, S. Shakkottai, and W. Chu, “Semantic image inversion and editing using rectified stochastic differential equations,” inICLR, 2025
2025
-
[31]
FireFlow: Fast inversion of rectified flow for image semantic editing,
Y . Deng, X. He, C. Mei, P. Wang, and F. Tang, “FireFlow: Fast inversion of rectified flow for image semantic editing,” inICML, 2025
2025
-
[32]
Adams Bashforth Moulton solver for inversion and editing in rectified flow,
Y . Ma, D. Di, X. Liu, X. Chen, L. Fan, T. Su, and Y . Gao, “Adams Bashforth Moulton solver for inversion and editing in rectified flow,” arXiv preprint arXiv:2503.16522, 2025
-
[33]
DNAEdit: Direct noise alignment for text-guided rectified flow editing,
C. Xie, M. Li, S. Li, Y . Wu, Q. Yi, and L. Zhang, “DNAEdit: Direct noise alignment for text-guided rectified flow editing,” inNeurIPS, 2025
2025
-
[34]
FSI-Edit: Frequency and stochasticity injection for flexible diffusion-based image editing,
K. Yang, X. Li, Y . Li, Q. Li, and Z. Wang, “FSI-Edit: Frequency and stochasticity injection for flexible diffusion-based image editing,” in NeurIPS, 2025
2025
-
[35]
FIA-Edit: Frequency-interactive attention for efficient and high-fidelity inversion-free text-guided image editing,
K. Yang, B. Shen, X. Li, Y . Dai, Y . Luo, Y . Ma, W. Fang, Q. Li, and Z. Wang, “FIA-Edit: Frequency-interactive attention for efficient and high-fidelity inversion-free text-guided image editing,” inAAAI, 2026
2026
-
[36]
W-EDIT: A wavelet-based frequency-aware framework for text-driven image editing,
J. Sun, W. Wang, M. Sun, P. Wang, X. Zhu, and J. Liu, “W-EDIT: A wavelet-based frequency-aware framework for text-driven image editing,” inICLR, 2026
2026
-
[37]
PnP-Flow: Plug-and-play image restoration with flow matching,
S. T. Martin, A. Gagneux, P. Hagemann, and G. Steidl, “PnP-Flow: Plug-and-play image restoration with flow matching,” inICLR, 2025
2025
-
[38]
B. F. Labs, “Flux,” https://github.com/black-forest-labs/flux, 2024
2024
-
[39]
Scaling rectified flow transformers for high-resolution image synthesis,
P. Esser, S. Kulal, A. Blattmann, R. Entezari, J. Müller, H. Saini, Y . Levi, D. Lorenz, A. Sauer, F. Boeselet al., “Scaling rectified flow transformers for high-resolution image synthesis,” inICML, 2024
2024
-
[40]
PnP Inversion: Boosting diffusion-based editing with 3 lines of code,
X. Ju, A. Zeng, Y . Bian, S. Liu, and Q. Xu, “PnP Inversion: Boosting diffusion-based editing with 3 lines of code,” inICLR, 2023
2023
-
[41]
Schedule your edit: A simple yet effective diffusion noise schedule for image editing,
H. Lin, Y . Chen, J. Wang, W. An, M. Wang, F. Tian, Y . Liu, G. Dai, J. Wang, and Q. Wang, “Schedule your edit: A simple yet effective diffusion noise schedule for image editing,” inNeurIPS, 2024
2024
-
[42]
Stable Flow: Vital layers for training- free image editing,
O. Avrahami, O. Patashnik, O. Fried, E. Nemchinov, K. Aberman, D. Lischinski, and D. Cohen-Or, “Stable Flow: Vital layers for training- free image editing,” inCVPR, 2025
2025
-
[43]
Emerging properties in self-supervised vision transformers,
M. Caron, H. Touvron, I. Misra, H. Jégou, J. Mairal, P. Bojanowski, and A. Joulin, “Emerging properties in self-supervised vision transformers,” inICCV, 2021
2021
-
[44]
Scope of validity of PSNR in image/video quality assessment,
Q. Huynh-Thu and M. Ghanbari, “Scope of validity of PSNR in image/video quality assessment,”Electronics Letters, 2008
2008
-
[45]
Image quality assessment: from error visibility to structural similarity,
Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli, “Image quality assessment: from error visibility to structural similarity,”IEEE Transactions on Image Processing, 2004
2004
-
[46]
The unreasonable effectiveness of deep features as a perceptual metric,
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep features as a perceptual metric,” in CVPR, 2018
2018
-
[47]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inICML, 2021
2021
-
[48]
Jähne,Digital image processing
B. Jähne,Digital image processing. Springer, 2005
2005
-
[49]
Notes on discrete gaussian scale space,
M. Tschirsich and A. Kuijper, “Notes on discrete gaussian scale space,”Journal of Mathematical Imaging and Vision, 2015
2015
-
[50]
On the theory of filter amplifiers,
S. Butterworthet al., “On the theory of filter amplifiers,”Wireless Engineer, 1930. July 3, 2026 DRAFT
1930
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.