Self-Improving CAD Generation Agents with Finite Element Analysis as Feedback
Pith reviewed 2026-05-19 22:36 UTC · model grok-4.3
The pith
CAD agents improve designs when finite element analysis and blueprint feedback close the loop between generation and engineering checks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that finite element analysis on generated STEP files, paired with a novel text-only blueprint schema and 21-view image renderer, supplies usable feedback that lets Codex and Claude Code agents self-improve, lifting geometric reconstruction from 0.444 to 0.592 Box-IoU on S2O and from 0.397 to 0.505 on Fusion360 while moving toward higher rates of meeting typed engineering requirements.
What carries the argument
The closed-loop agent that feeds finite element analysis results plus blueprint and multi-view image signals back into the next generation step to produce assembled multi-part STEP files.
If this is right
- No first-attempt agent run meets all strict requirements, but the added signals measurably raise the fraction of satisfied constraints.
- Geometric reconstruction improves on both S2O and Fusion360 without changing the base model.
- CAD generation becomes an iterative process checked against physical and structural criteria rather than reference proximity alone.
- The same feedback loop can be applied to any agent that outputs STEP files for engineering review.
Where Pith is reading between the lines
- The method could be tested on additional simulation domains such as thermal or fluid analysis to see if the same loop generalizes.
- Combining the blueprint and image signals with constraint solvers might further reduce the gap between generated files and production-ready parts.
- Similar self-correction patterns may appear in other generative tasks that currently lack quantitative physical feedback.
Load-bearing premise
Finite element analysis performed on the generated STEP files gives a reliable enough signal of real engineering fitness.
What would settle it
Compare FEA-passing designs against either physical prototypes or higher-fidelity simulations to see whether the reported compliance gains disappear.
Figures












read the original abstract
Computer-aided design (CAD) is the backbone of modern industrial design, yet learned CAD generators still fall short of real engineering pipelines: they neither iterate like engineers nor evaluate what engineering requires. Prior work has treated CAD generation as two disjoint steps, part synthesis and assembly, where the former is graded by proximity to a gold reference and the latter, when handled at all, is reduced to a separate constraint solving step. In this work, we introduce a more industry-native task formulation that requires a model to produce a fully assembled multi-part STEP file from a free-form engineering brief, which is then validated via finite element analysis (FEA). FEA validation reveals that Codex (GPT-5.5) and Claude Code (Opus-4.7) agents do not produce a single strict-passing artifact in the main first-attempt sweep, with the best configuration meeting only about 20% of typed requirements on average. Moreover, we introduce two additional supervision signals, a novel text-only blueprint schema and a 21-view image renderer that aids the agent's visual inspection, that better align the generation loop with how engineers iterate in practice. On S2O and Fusion360, the same feedback tools improve geometric reconstruction, with GPT-5.5/xhigh rising from 0.444 to 0.592 Box-IoU on S2O and from 0.397 to 0.505 on Fusion360. Together these signals move CAD programs toward artifacts that are not only visually plausible but also checked against physical and structural requirements.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formulates CAD generation as producing fully assembled multi-part STEP files from free-form engineering briefs, with validation via finite element analysis (FEA). It reports that Codex (GPT-5.5) and Claude Code (Opus-4.7) agents produce no strict-passing artifacts in a first-attempt sweep, satisfying only ~20% of typed requirements on average. The authors introduce a text-only blueprint schema and 21-view image renderer as additional feedback signals; these yield Box-IoU gains from 0.444 to 0.592 on S2O and from 0.397 to 0.505 on Fusion360 for the GPT-5.5/xhigh configuration. The central thesis is that these signals, combined with FEA feedback, move outputs toward artifacts that satisfy real engineering requirements.
Significance. If the core premise holds, the work could meaningfully advance self-improving CAD agents by closing the gap between geometric plausibility and physical/structural validity. The task reformulation and explicit use of FEA as a feedback loop represent a concrete step beyond reference-based metrics; the reported agent failure rates and the two new supervision signals are useful empirical anchors for the field.
major comments (2)
- [Abstract / Results] Abstract and results: the claim that the blueprint schema and 21-view renderer improve engineering fidelity rests on an untested correlation. Geometric Box-IoU lifts are quantified, yet no before/after FEA scores, constraint-violation counts, or change in the fraction of artifacts meeting typed requirements are reported; without these, the causal link between the new signals and satisfaction of physical requirements cannot be assessed.
- [Evaluation] Evaluation protocol: the manuscript states that FEA validation reveals zero strict-passing artifacts and ~20% average requirement satisfaction, but provides no table or section detailing how FEA outputs are mapped to the typed requirements or how the feedback loop uses FEA scores to drive self-improvement iterations.
minor comments (1)
- [Abstract] The abstract would benefit from a concise definition or example of the 'typed requirements' used in the 20% figure.
Simulated Author's Rebuttal
Thank you for the constructive feedback. The points raised highlight opportunities to strengthen the empirical support for our claims and to clarify the evaluation protocol. We address each major comment below and commit to revisions that directly respond to the concerns.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and results: the claim that the blueprint schema and 21-view renderer improve engineering fidelity rests on an untested correlation. Geometric Box-IoU lifts are quantified, yet no before/after FEA scores, constraint-violation counts, or change in the fraction of artifacts meeting typed requirements are reported; without these, the causal link between the new signals and satisfaction of physical requirements cannot be assessed.
Authors: We agree that the manuscript would benefit from direct before-and-after metrics on FEA outcomes and requirement satisfaction to substantiate the link to physical validity. The reported Box-IoU gains demonstrate improved geometric fidelity, which we view as a prerequisite for engineering requirements, but we did not quantify the corresponding changes in FEA pass rates or typed-requirement compliance for the blueprint and multi-view configurations. In the revised version we will re-evaluate the GPT-5.5/xhigh and Claude configurations with and without the new signals, reporting delta values for FEA scores, constraint-violation counts, and the fraction of artifacts meeting typed requirements. These additions will make the causal contribution of the supervision signals explicit. revision: yes
-
Referee: [Evaluation] Evaluation protocol: the manuscript states that FEA validation reveals zero strict-passing artifacts and ~20% average requirement satisfaction, but provides no table or section detailing how FEA outputs are mapped to the typed requirements or how the feedback loop uses FEA scores to drive self-improvement iterations.
Authors: We acknowledge that the current text describes the FEA integration at a high level without a dedicated mapping table or explicit iteration diagram. The manuscript does define the typed requirements and states that FEA is used for validation and feedback, yet the precise translation from FEA quantities (e.g., von Mises stress thresholds, displacement limits) to requirement satisfaction and the prompt-update mechanism for self-improvement are not tabulated. In revision we will insert a new subsection (with accompanying table and pseudocode) that (1) lists the FEA-derived criteria for each typed requirement and (2) details how the scalar FEA scores are injected into the agent’s next-turn prompt to close the self-improvement loop. revision: yes
Circularity Check
No circularity: empirical IoU gains reported from added feedback signals without any derivation or fit reducing to inputs.
full rationale
The paper describes an empirical task formulation for CAD generation from engineering briefs, followed by FEA validation and introduction of blueprint and 21-view image feedback. Reported results consist of direct measurements: zero strict-passing artifacts in baseline sweeps, ~20% requirement compliance, and specific Box-IoU lifts (0.444 to 0.592 on S2O; 0.397 to 0.505 on Fusion360) when the new signals are added. No equations, parameter fittings, self-definitional loops, or load-bearing self-citations appear in the provided text that would make any claimed improvement equivalent to its own inputs by construction. The evaluation chain relies on external geometric and FEA metrics that remain independent of the generation process.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
FEA validation reveals that Codex ... do not produce a single strict-passing artifact ... 21-view image renderer ... improve geometric reconstruction, with GPT-5.5/xhigh rising from 0.444 to 0.592 Box-IoU
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
rich-view image judge renders the STEP from 21 calibrated views ... finite-element feedback from CalculiX
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
gpt-oss-120b & gpt-oss-20b Model Card
Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K Arora, Yu Bai, Bowen Baker, Haiming Bao, et al. gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Generating CAD code with vision-language models for 3d designs.arXiv preprint arXiv:2410.05340, 2024
Kamel Alrashedy, Pradyumna Tambwekar, Zulfiqar Zaidi, Megan Langwasser, Wei Xu, and Matthew Gombolay. Generating cad code with vision-language models for 3d designs.arXiv preprint arXiv:2410.05340, 2024
-
[3]
Developing a computer use model
Anthropic. Developing a computer use model. https://www.anthropic.com/news/ 3-5-models-and-computer-use , 2024. Introduces Claude 3.5 Sonnet computer use ca- pability
work page 2024
-
[4]
Jesse Barkley, Rumi Loghmani, and Amir Barati Farimani. Cadsmith: Multi-agent cad genera- tion with programmatic geometric validation.arXiv preprint arXiv:2603.26512, 2026
-
[5]
Geoffrey Boothroyd, Peter Dewhurst, and Winston A Knight.Product design for manufacture and assembly. CRC press, 2010
work page 2010
-
[6]
Videollm-online: Online video large language model for streaming video
Joya Chen, Zhaoyang Lv, Shiwei Wu, Kevin Qinghong Lin, Chenan Song, Difei Gao, Jia-Wei Liu, Ziteng Gao, Dongxing Mao, and Mike Zheng Shou. Videollm-online: Online video large language model for streaming video. InCVPR, 2024
work page 2024
-
[7]
Guido Dhondt and Klaus Wittig. CalculiX: A free software three-dimensional structural finite element program.http://www.calculix.de/, 2024. Version 2.22
work page 2024
-
[8]
Anna C Doris, Ferdous Alam, Amin Heyrani Nobari, and Faez Ahmed. Cad-coder: An open-source vision-language model for computer-aided design code generation.Journal of Mechanical Design, 148(7):071702, 2026
work page 2026
-
[9]
CADDesigner: Conceptual CAD Model Generation with a General-Purpose Agent
Fengxiao Fan, Jingzhe Ni, Xiaolong Yin, Sirui Wang, Xingyu Lu, Qiang Zou, Ruofeng Tong, Min Tang, and Peng Du. Caddesigner: Conceptual design of cad models based on general- purpose agent.arXiv preprint arXiv:2508.01031, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
A point set generation network for 3d object reconstruction from a single image
Haoqiang Fan, Hao Su, and Leonidas J Guibas. A point set generation network for 3d object reconstruction from a single image. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 605–613, 2017
work page 2017
-
[11]
Gemini 3 pro image (Nano Banana Pro)
Google DeepMind. Gemini 3 pro image (Nano Banana Pro). https://deepmind.google/ models/gemini-image/pro/, 2025. Image generation and editing model built on Gemini 3 Pro
work page 2025
-
[12]
doi:10.48550/arXiv.2507.09792 , urldate =
Prashant Govindarajan, Davide Baldelli, Jay Pathak, Quentin Fournier, and Sarath Chandar. Cadmium: Fine-tuning code language models for text-driven sequential cad design.arXiv preprint arXiv:2507.09792, 2025
-
[13]
From kmmlu-redux to kmmlu-pro: A professional korean benchmark suite for llm evaluation
Seokhee Hong, Sunkyoung Kim, Guijin Son, Soyeon Kim, Yeonjung Hong, and Jinsik Lee. From kmmlu-redux to kmmlu-pro: A professional korean benchmark suite for llm evaluation. arXiv preprint arXiv:2507.08924, 2025
-
[14]
S2o: Static to openable enhancement for articulated 3d objects
Denys Iliash, Hanxiao Jiang, Yiming Zhang, Manolis Savva, and Angel X Chang. S2o: Static to openable enhancement for articulated 3d objects. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 6785–6795, 2026
work page 2026
-
[15]
Automate: A dataset and learning approach for automatic mating of cad assemblies
Benjamin Jones, Dalton Hildreth, Duowen Chen, Ilya Baran, Vladimir G Kim, and Adriana Schulz. Automate: A dataset and learning approach for automatic mating of cad assemblies. ACM Transactions on Graphics (TOG), 40(6):1–18, 2021
work page 2021
-
[16]
Mohammad S Khan, Sankalp Sinha, Talha U Sheikh, Didier Stricker, Sk A Ali, and Muham- mad Z Afzal. Text2cad: Generating sequential cad designs from beginner-to-expert level text prompts.Advances in Neural Information Processing Systems, 37:7552–7579, 2024. 10
work page 2024
-
[17]
Mohammad Sadil Khan, Elona Dupont, Sk Aziz Ali, Kseniya Cherenkova, Anis Kacem, and Djamila Aouada. Cad-signet: Cad language inference from point clouds using layer-wise sketch instance guided attention. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4713–4722, 2024
work page 2024
-
[18]
cadrille: Multi-modal cad reconstruction with reinforcement learning
Maksim Kolodiazhnyi, Denis Tarasov, Dmitrii Zhemchuzhnikov, Alexander Nikulin, Ilya Zisman, Anna V orontsova, Anton Konushin, Vladislav Kurenkov, and Danila Rukhovich. cadrille: Multi-modal cad reconstruction with reinforcement learning. InThe Fourteenth International Conference on Learning Representations, 2025
work page 2025
-
[19]
Cad-llama: leveraging large language models for computer-aided design parametric 3d model generation
Jiahao Li, Weijian Ma, Xueyang Li, Yunzhong Lou, Guichun Zhou, and Xiangdong Zhou. Cad-llama: leveraging large language models for computer-aided design parametric 3d model generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18563–18573, 2025
work page 2025
-
[20]
Xueyang Li, Jiahao Li, Yu Song, Yunzhong Lou, and Xiangdong Zhou. Seek-cad: A self-refined generative modeling for 3d parametric cad using local inference via deepseek.arXiv preprint arXiv:2505.17702, 2025
-
[21]
Cad-assistant: tool- augmented vllms as generic cad task solvers
Dimitrios Mallis, Ahmet Serda Karadeniz, Sebastian Cavada, Danila Rukhovich, Niki Foteinopoulou, Kseniya Cherenkova, Anis Kacem, and Djamila Aouada. Cad-assistant: tool- augmented vllms as generic cad task solvers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 7284–7294, 2025
work page 2025
-
[22]
Evocad: Evolutionary cad code generation with vision language models
Tobias Preintner, Weixuan Yuan, Adrian König, Thomas Bäck, Elena Raponi, and Niki Van Stein. Evocad: Evolutionary cad code generation with vision language models. In2025 IEEE 37th International Conference on Tools with Artificial Intelligence (ICTAI), pages 504–511. IEEE, 2025
work page 2025
-
[23]
Draw- ing2cad: Sequence-to-sequence learning for cad generation from vector drawings
Feiwei Qin, Shichao Lu, Junhao Hou, Changmiao Wang, Meie Fang, and Ligang Liu. Draw- ing2cad: Sequence-to-sequence learning for cad generation from vector drawings. InProceed- ings of the 33rd ACM International Conference on Multimedia, pages 10573–10582, 2025
work page 2025
-
[24]
Cad-recode: Reverse engineering cad code from point clouds
Danila Rukhovich, Elona Dupont, Dimitrios Mallis, Kseniya Cherenkova, Anis Kacem, and Djamila Aouada. Cad-recode: Reverse engineering cad code from point clouds. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9801–9811, 2025
work page 2025
-
[25]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
3d-gpt: Procedural 3d modeling with large language models
Chunyi Sun, Junlin Han, Weijian Deng, Xinlong Wang, Zishan Qin, and Stephen Gould. 3d-gpt: Procedural 3d modeling with large language models. In2025 International Conference on 3D Vision (3DV), pages 1253–1263. IEEE, 2025
work page 2025
-
[27]
Maxim Tatarchenko, Stephan R Richter, René Ranftl, Zhuwen Li, Vladlen Koltun, and Thomas Brox. What do single-view 3d reconstruction networks learn? InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3405–3414, 2019
work page 2019
-
[28]
Oxford university press New York, 2004
Daniel E Whitney.Mechanical assemblies: their design, manufacture, and role in product development, volume 1. Oxford university press New York, 2004
work page 2004
-
[29]
Karl DD Willis, Yewen Pu, Jieliang Luo, Hang Chu, Tao Du, Joseph G Lambourne, Armando Solar-Lezama, and Wojciech Matusik. Fusion 360 gallery: A dataset and environment for programmatic cad construction from human design sequences.ACM Transactions on Graphics (TOG), 40(4):1–24, 2021
work page 2021
-
[30]
Joinable: Learning bottom-up assembly of parametric cad joints
Karl DD Willis, Pradeep Kumar Jayaraman, Hang Chu, Yunsheng Tian, Yifei Li, Daniele Grandi, Aditya Sanghi, Linh Tran, Joseph G Lambourne, Armando Solar-Lezama, et al. Joinable: Learning bottom-up assembly of parametric cad joints. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15849–15860, 2022. 11
work page 2022
-
[31]
Deepcad: A deep generative network for computer- aided design models
Rundi Wu, Chang Xiao, and Changxi Zheng. Deepcad: A deep generative network for computer- aided design models. InProceedings of the IEEE/CVF international conference on computer vision, pages 6772–6782, 2021
work page 2021
-
[32]
Text-to-CadQuery: A New Paradigm for CADgenerationwithscalablelargemodelcapabilities
Haoyang Xie and Feng Ju. Text-to-cadquery: A new paradigm for cad generation with scalable large model capabilities.arXiv preprint arXiv:2505.06507, 2025. 12 A Additional model baseline results Table 5:Additional OpenCode baseline results on Hephaestus-CCX. These rows use no FEA-retry round and are reported here to keep Table 2 focused on the main Codex a...
-
[33]
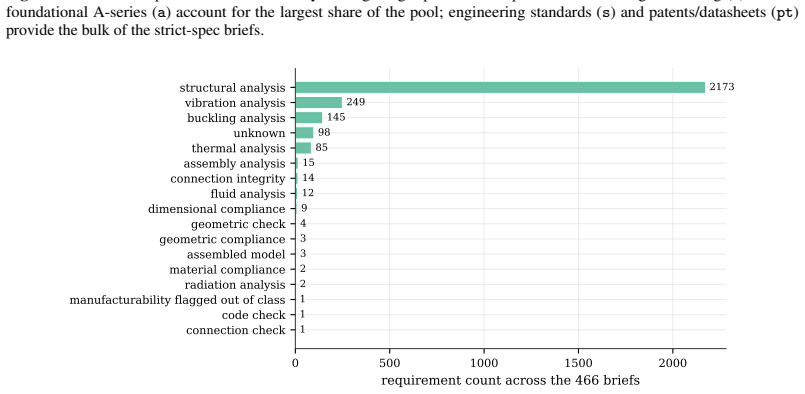
Catalog identification.A new catalog (e.g., a standards body, a supplier datasheet family, or a regional industrial archive) is added to the candidate pool, and each prospective case is assigned a difficulty tier (A+, A, B, C) reflecting how completely the underlying source already specifies the FEA pass/fail criteria
-
[34]
Brief drafting.The narrative engineering brief is written from the source material, with all numeric limits (load magnitudes, material strengths, dimensional tolerances, safety factors) resolved inline at authoring time so the brief carries no dangling references to external documents
-
[35]
Rn), each one tied to a load case and a numeric threshold
Requirement expansion.The brief’s pass/fail criteria are decomposed into an explicitly typed list of requirements (R1. . . Rn), each one tied to a load case and a numeric threshold
-
[36]
The brief is only kept if every requirement parses, evaluates, and binds without skipping
Checker validation.Every candidate brief is run through the CalculiX harness against a hand-built reference geometry. The brief is only kept if every requirement parses, evaluates, and binds without skipping
-
[37]
collegiate formula-class racecar benchmark
Scrub pass before release.A final pass strips identifying metadata and external dependen- cies; details follow. The scrub enforced two invariants. (i)No source identity: we removed every metadata field that could attribute a brief to a specific organization, competition, or human author, and rewrote the prompt text of 49 files whose narratives named speci...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.